一种考虑人脸欺诈的车载系统安全认证管理方法
1.本发明属于计算机视觉技术领域,涉及车载系统,具体涉及一种考虑人脸欺诈的车载系统安全认证管理方法。
背景技术:
2.近年来,智能检测车逐渐成为智能交通技术领域的研究热点。与此同时,人脸识别技术也被应用在智能汽车,在用户身份验证、驾驶员行驶访问控制、系统数据安全等方面都采用人脸识别系统进行登录认证。
3.由于检测车系统内的用户信息、系统数据是高度保密的,人脸识别的认证是获取数据的唯一途径,人脸信息也就成为保障车载系统安全的关键部分,所以针对人脸识别系统的欺诈攻击也逐渐出现。为了提高系统的安全性,很有必要对这种表示攻击进行检测。许多项目中使用的典型类人脸抗欺骗(fas)方法是基于姿态识别的,通常需要用户协同完成一系列动作来确认真假,准确率高但不适合被动识别。对于传统的基于静态纹理的方法是利用手工制作的描述符从面部图像中提取欺骗模式来区分皮肤、照片和视频在纹理上的差异。然而,人脸区域的模式在不同光照、不同捕获设备或不同攻击欺诈情况下存在明显的类内差异。之后人们提出了多帧pad方法,根据深度卷积神经网络在二维图像中生成的深度图像或rppg技术提取的反映面部区域血流的信号来检测假人脸。尽管多帧方法在许多数据集上的性能更好,但其缺点是计算比其他方法复杂,可能不适合需要快速决策或具有少量计算能力的开发平台的条件。
4.目前大多数人脸抗欺骗方法都采用神经网络作为骨干,如vgg、resnet和densenet,并采用二元交叉熵损失或三态焦点损失进行训练。然而,深度神经网络倾向于关注语义信息,如身份特征,而不是对pad有用的纹理特征,而且简单的丢失函数不能很好地监督模型学习。因此,有许多著作采用了深度地图监督学习。但设计的新型损耗函数增加了收敛的难度,在一定程度上不利于移动设备运行复杂而深刻的模型。
技术实现要素:
5.针对现有技术存在的不足,本发明的目的在于,提供一种考虑人脸欺诈的车载系统安全认证管理方法,以解决现有技术中的安全认证管理方法在复杂环境中的应用的鲁棒性有待进一步提升的技术问题。
6.为了解决上述技术问题,本发明采用如下技术方案予以实现:
7.一种考虑人脸欺诈的车载系统安全认证管理方法,该方法包括以下步骤:
8.步骤1,输入采集的连续两帧人脸视频,通过基于深度学习的运动放大方法对捕捉到的视频帧图像进行预处理,对视频帧图像中的反映人体呼吸信号的目标频段在0.04hz~0.4hz之间的人的运动进行增强,获得增强后的rgb图像;
9.步骤2,采用逐像素稠密光流方法,追踪在步骤1中放大后的相邻两帧视频帧图像中的所有点,提取相邻两帧视频帧图像的稠密光流动态特征,生成光流场图;
10.步骤3,采用hog算法对步骤1中所输入的视频帧图像中的人脸区域进行定位,裁剪出经过步骤1增强后的rgb图像中的人脸区域;之后同样对步骤2中所获得的光流场图中的人脸区域进行定位,裁剪出光流场图中的人脸区域;
11.步骤4,构建车载系统安全认证管理卷积神经网络,所述的构建包括:所述的卷积神经网络包括纹理呈现子网络、光学呈现子网络和特征融合子网络;所述的车载系统安全认证管理卷积神经网络以mobilenet-v2为骨干;
12.将步骤3所获得的增强后的rgb图像的人脸区域图像和光流场图的人脸区域图像分别作为纹理呈现子网络和光学呈现子网络的输入,采用车载系统安全认证管理卷积神经网络进行训练,通过纹理呈现子网络和光学呈现子网络的训练进行纹理特征和光流特征的提取,在特征融合子网络中获得特征融合,最后,基于光流特征和纹理特征,进行真人脸和假人脸的分类,输出最终结果。
13.本发明还具有如下技术特征:
14.步骤1中,包括如下子步骤:
15.步骤101,利用一个基于残差网络的运动视觉编码器编码器作为一个空间分解过滤器提取输入的单个视频帧图像的形状表示信号和纹理表示信号;
16.步骤102,将视频视作连续视频帧图像,
17.视频中某处的像素值变化能够视为一种时域信号,用一个时域滤波器从得到的动作表示中提取目标频段进行动作放大,得到放大后的运动信号;
18.步骤103,利用解码器将形状表示信号和纹理表示信号与放大后的运动信号相结合,重构出增强后的rgb图像。
19.步骤2中,具体包括如下子步骤:
20.步骤201,将步骤1中获得的增强后的rgb图像视为一个二维变量函数,并通过二项式展开进行近似估计;
21.步骤202,对于每帧视频帧图像中的每个像素点,将像素点在(2n+1)
×
(2n+1)的邻域内的全部像素点作为样本点,通过最小二乘法拟合得到中心像素点的六维系数,对于视频帧图像中的每个像素点都能得到一个六维向量;
22.其中,n为正整数;
23.步骤203,将每个六维向量作为系数,代入不同像素点的位置,求出视频前后帧的视频帧图像中每个像素点的参数向量;
24.步骤204,利用参数向量计算人脸视频的帧间位移,将帧间位移转换为极坐标系形式的位移并映射到hsv色彩空间,生成光流场图。
25.步骤3中,采用hog算法定位的过程具体包括如下子步骤:
26.步骤301,将步骤1中获得的增强后的rgb图像和步骤2中生成的光流场图分别划分为多个块,每个块中分为多个单元,计算每个单元中每个像素的梯度,并根据梯度的分布生成单元的hog;
27.步骤302,对每个块中的所有单元的hog进行向量运算,得到每个块对应的块空间hog;
28.步骤303,对块空间的hog进行归一化处理,最终将所有块的块空间hog组合在一起,形成该检测窗口的hog特征向量;利用滑动窗口,采用机器学习算法来判断当前窗口中
的hog特征向量是否与人脸区域相匹配,从而根据窗口坐标定位人脸。
29.步骤4中,所述的构建还包括:
30.步骤401,对纹理呈现子网络和光学呈现子网络构建了由n个子块组成的动态卷积块,子块包含k个大小相同的动态卷积滤波器;
31.步骤402,在纹理特征子网络中设置了中间层特征提取块和多级特征融合块作为网络主干进行纹理特征提取。
32.本发明与现有技术相比,具有如下技术效果:
33.(ⅰ)本发明的方法提出了一种以mobilenet-v2为骨干的pad网络结构,用于从rgb图像和光流图中提取人脸活动特征,并在重放攻击数据集上评估了该方法的有效性。
34.(ⅱ)本发明的方法分析了mobilenet-v2在人脸反欺骗中的多层次特征,提出了多层次特征融合模块,提取并融合多层次特征,将深层和阴影输出结合起来,提高轻量级模型对pad任务的表示能力。
35.(ⅲ)本发明的方法设计了一种改进的动态卷积块(dcb),将多个滤波器的不同输出集成到权值中,而不是在卷积计算之前计算权值,将参数更新过程与senet统一起来,简化了动态卷积块的训练难度,对复杂环境中的应用具有更强的鲁棒性。
36.(ⅳ)本发明的方法提出了中间层特征提取块和多层特征融合块来降低中层特征的维数,并利用注意力模块融合中层特征。
附图说明
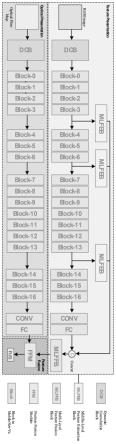
37.图1是本发明设计的车载系统安全认证管理卷积神经网络的网络结构图。
38.图2是本发明的考虑人脸欺诈的车载系统安全认证管理方法的流程图。
39.图3是本发明设计的动态卷积块结构图。
40.图4是本发明设计的动态卷积块中se-block结构图。
41.图5是本发明设计的网络中中间层特征提取块的提取过程图。
42.图6是本发明设计的网络中多层特征融合块的结构图。
43.图7是本发明的实例1中对基于欧拉和基于深度学习的运动放大方法的和结果比较图。
44.图8是本发明的应用例1中所有样本在仅用表示子网络或融合子网络计算的比较图。
45.图9是本发明的应用例1中提出的不同子网络的roc曲线图。
46.图10是本发明的应用例3中提出的多级特征融合块中注意力权重的热图。
47.以下结合实施例对本发明的具体内容作进一步详细解释说明。
具体实施方式
48.需要说明的是,本发明中的所有算法和方法,如无特殊说明,全部均采用现有技术中已知的算法和方法。例如,基于深度学习的运动放大方法、逐像素稠密光流方法均属于现有技术中已知的方法。
49.需要说明的是,本发明中:
50.mobilenet-v2:mobilenet-v2的主要思想就是在v1的基础上引入了线性瓶颈
(linear bottleneck)和逆残差(inverted residual)来提高网络的表征能力,同样也是一种轻量级的卷积神经网络。
51.本发明使用mobilenet-v2作为骨干提出了一种轻量级网络,结构如图1所示。包括纹理呈现子网络、光学呈现子网络和特征融合子网络三部分。
52.rgb图像指的是基于红、绿、蓝三个通道的颜色的图像。
53.hsv色彩空间指的是指的是hue saturation value色彩空间(hue-色调、saturation-饱和度、value-值),其中,极角作为色调,极径作为亮度,饱和度为1。
54.fas方法指的是典型类人脸抗欺骗方法。
55.pad方法指的是呈现攻击检测方法。
56.rppg技术指的是通过高清摄像头采集人脸数据并分析,从而检测心率的超感知的心率检测技术。
57.vgg指的是牛津大学计算机视觉组和google deepmind公司的研究员仪器研发的深度卷积神经网络。
58.resnet指的是深度残差网络(deep residual network,resnet)。
59.densenet指的是由gao huang等人于2017年在论文名为:《densely connected convolutional networks》提出一种卷积神经网络,。
60.senet指的是一种复杂度低,新增参数和计算量小的卷积神经网络,是imagenet 2017(imagenet收官赛)的冠军模型。
61.idiap指的是idiap研究所,研究领域包括语音和视觉识别、机器学习、人机交互、机器人技术、语言分析或生物成像;并参与地方、国家和国际层面的研究项目。
62.hog算法指的是方向梯度直方图算法。
63.se-block结构图指的是卷积神经网络中压缩与激励块(squeeze-and-excitation block)结构图。
64.dcb指的是动态卷积块。
65.mlfeb指的是中间层特征提取块。
66.mlffb指的是多级特征融合块。
67.ffm指的是特征融合子网络。
68.需要说明的是,本发明中,车载系统安全认证管理卷积神经网络为用于呈现攻击检测的轻量级网络。
69.遵从上述技术方案,以下给出本发明的具体实施例,需要说明的是本发明并不局限于以下具体实施例,凡在本技术技术方案基础上做的等同变换均落入本发明的保护范围。
70.实施例:
71.本实施例给出一种考虑人脸欺诈的车载系统安全认证管理方法,如图2所示,该方法包括以下步骤:
72.步骤1,输入采集的连续两帧人脸视频,通过基于深度学习的运动放大方法对捕捉到的视频帧图像进行预处理,对视频帧图像中的反映人体呼吸信号的目标频段在0.04hz~0.4hz之间的人的运动进行增强,获得增强后的rgb图像。
73.具体的,所述步骤1,采用基于深度学习的运动放大方法对视频帧进行处理,该方
法下采用一个基于残差网络的运动视觉编码器来表示视频中的动作和纹理信号。
74.步骤1中,包括如下子步骤:
75.步骤101,利用一个基于残差网络的运动视觉编码器编码器作为一个空间分解过滤器提取输入的单个视频帧图像的形状表示信号和纹理表示信号;
76.步骤102,将视频视作连续视频帧图像,
77.视频中某处的像素值变化能够视为一种时域信号,用一个时域滤波器从得到的动作表示中提取目标频段进行动作放大,得到放大后的运动信号;
78.步骤103,利用解码器将形状表示信号和纹理表示信号与放大后的运动信号相结合,重构出增强后的rgb图像。
79.步骤2,采用逐像素稠密光流方法,追踪在步骤1中放大后的相邻两帧视频帧图像中的所有点,提取相邻两帧视频帧图像的稠密光流动态特征,生成光流场图。
80.具体的,所述步骤2中使用了farneback提出的基于梯度的稠密光流计算方法,利用图像序列中的像素在时间域上的变化、相邻帧之间的相关性来找到的上一帧跟当前帧间存在的对应关系。算法的总体思想就是通过多项展开变换逼近两帧图像的像素,并观察每个多项式如何在平移下精确变换,最终在多项式展开系数中推导出位移场。
81.步骤2中,具体包括如下子步骤:
82.步骤201,将步骤1中获得的增强后的rgb图像视为一个二维变量函数,并通过二项式展开进行近似估计;
83.步骤202,对于每帧视频帧图像中的每个像素点,将像素点在(2n+1)
×
(2n+1)的邻域内的全部像素点作为样本点,通过最小二乘法拟合得到中心像素点的六维系数,对于视频帧图像中的每个像素点都能得到一个六维向量;
84.其中,n为正整数;
85.步骤203,将每个六维向量作为系数,代入不同像素点的位置,求出视频前后帧的视频帧图像中每个像素点的参数向量;
86.步骤204,利用参数向量计算人脸视频的帧间位移,将帧间位移转换为极坐标系形式的位移并映射到hsv色彩空间,生成光流场图。
87.步骤3,采用hog算法对步骤1中所输入的视频帧图像中的人脸区域进行定位,裁剪出经过步骤1增强后的rgb图像中的人脸区域;之后同样对步骤2中所获得的光流场图中的人脸区域进行定位,裁剪出光流场图中的人脸区域。
88.具体的,为了消除背景对活体检测的影响,本发明采用了方向梯度直方图算法的人脸检测算法定位图像中的人脸区域,通过计算并统计图像局部的方向梯度直方图构成图像特征。
89.步骤3中,采用hog算法定位的过程具体包括如下子步骤:
90.步骤301,将步骤1中获得的增强后的rgb图像和步骤2中生成的光流场图分别划分为多个块,每个块中分为多个单元,计算每个单元中每个像素的梯度,并根据梯度的分布生成单元的hog;
91.步骤302,对每个块中的所有单元的hog进行向量运算,得到每个块对应的块空间hog;
92.步骤303,对块空间的hog进行归一化处理,最终将所有块的块空间hog组合在一
起,形成该检测窗口的hog特征向量;利用滑动窗口,采用机器学习算法来判断当前窗口中的hog特征向量是否与人脸区域相匹配,从而根据窗口坐标定位人脸。
93.步骤4,构建车载系统安全认证管理卷积神经网络,如图1所示,所述的构建包括:所述的卷积神经网络包括纹理呈现子网络、光学呈现子网络和特征融合子网络;所述的车载系统安全认证管理卷积神经网络以mobilenet-v2为骨干;
94.本发明在两个呈现子网络中设计并构建了一个动态卷积块(dcb)来替换原有第一层卷积,结构如图3所示。dcb由n个子块组成,子块包含k个大小相同的动态卷积滤波器,使用3
×
3微型卷积滤波器来进行有效的计算。对于一个维数为h*w*c的输入特征映射,每个含有k核的子块的输出通道为k。se-block代替通道来计算每个核的关注程度,se-block的基本架构如图4所示。将k个卷积核的输出加权求和作为一个子块的输出,并将n个子块的n个输出特征串接起来得到dcb的输出。
95.步骤4中,所述的构建还包括:
96.步骤401,对纹理呈现子网络和光学呈现子网络构建了由n个子块组成的动态卷积块,子块包含k个大小相同的动态卷积滤波器;
97.步骤402,在纹理特征子网络中设置了中间层特征提取块和多级特征融合块作为网络主干进行纹理特征提取。
98.具体的,中间层特征提取块的提取过程如图5所示。由基于注意力机制的多级特征融合块将这些块的输出与一维纹理特征转化为二维纹理表示。在光学呈现子网络中继续训练来提取图像的光学特征表示。
99.具体的,多层特征融合块的结构如图6所示,每个通道按列添加4个维度为4
×1×
2的中间层特征提取块的串联特征,通过激活层和全连接层组成的一组函数计算注意力。
100.将步骤3所获得的增强后的rgb图像的人脸区域图像和光流场图的人脸区域图像分别作为纹理呈现子网络和光学呈现子网络的输入,采用车载系统安全认证管理卷积神经网络进行训练,通过纹理呈现子网络和光学呈现子网络的训练进行纹理特征和光流特征的提取,在特征融合子网络中获得特征融合,最后,基于光流特征和纹理特征,进行真人脸和假人脸的分类,输出最终结果。
101.应用例1:
102.本应用例给出了一种基于上述实施例的考虑人脸欺诈的车载系统安全认证管理方法,在本应用例中公开了一种考虑人脸欺诈的车载系统安全认证管理方法,在本应用例中,使用来自idiap的人脸活动检测数据库的重放攻击数据集进行模型训练和测试。这个数据集包含了从50名志愿者那里收集的1300个面部视频,分辨率为320*240,每秒约25帧。具体拍摄场景包括:自然环境是否受控、视频/照片分辨率不同、通过视频或照片进行攻击、采集相机是手持的或固定的等。忽略上述因素,将所有视频分为两种类型:真实人脸和假人脸。在对视频中0.04hz~0.4hz频段进行处理时,比较了基于欧拉和基于深度学习的两种运动放大方法,如图7所示。与欧拉算法相比,深度学习方法产生的干扰和模糊较少。因此,本应用例采用基于深度学习的运动放大方法,对反映人体呼吸信号的0.04~0.4hz之间的运动进行增强。
103.使用已知的由farneback(学者)提出的稠密光流方法对增强后的相邻两个视频帧图像进行计算,通过计算前一帧图像的每个像素点在后一帧图像中的位移来找到对应位
置,近似得到不能直接得到的运动场。光流场是运动场在二维图像平面上(人的眼睛或者摄像头)的投影。为了更直观地表达光流场,将位移转换为极坐标系并映射到hsv色彩空间(极角作为色调,极径作为亮度,饱和度为1),并获得rgb图像。
104.使用方向梯度直方图(hog)的人脸检测算法分别定位增强后的rgb图像中的人脸区域和生成的光流特征图中人脸区域。具体的,将图像划分为小的单元,计算单元中每个像素的梯度,并根据梯度的分布生成单元的hog。然后,在一个较大的块空间上计算每个单元的hog分布,生成块空间hog。将多个块空间hog进行拼接,形成整个图像的hog来描述纹理信息。为了减少不同人脸图像的光照和背景差异导致振幅值范围较大,需要对每个块空间的hog进行归一化处理。利用滑动窗口,采用机器学习算法来判断当前窗口中的hog特征向量是否与人脸区域相匹配,从而根据窗口坐标定位人脸。之后对定位到的人脸区域分别进行裁剪,作为神经网络的输入。
105.本实例所用数据集分别生成由人脸区域纹理图像和光流图组成的454553、44943和59767元组,分别用于训练、验证和测试。本文提出的网络是用pytorch实现的,模型在tesla v100 gpu上进行了训练和测试。本应用例使用交叉熵损失来分别训练纹理特征表现子网络和光流特征表现子网络,然后以表现子网络的输出作为输入数据来训练特征融合模块。所有的训练都由sgd优化器驱动,权重衰减为1e-4
,学习率初始化为0.012,在训练过程中每10个epochs减半。在测试阶段,通过softmax函数将本发明提出的轻量级网络输出细化为0和1之间的值,生成真实人脸和假人脸的可能性,本应用例选择真实的可能性值作为验证的证据,忽略假可能性。本应用例遵循一般评价pad方法的指标,即错误接受率(far),错误拒绝率(frr),定义式为:
106.far=nf/nf
107.frr=nrf/nr
108.其中n
fr
为识别假人脸为真人脸的时间,n
rf
为识别真人脸为假人脸的时间,nf和nr分别表示识别中使用的假人脸和真人脸的数量。通过计算不同阈值下的far和frr,绘制出far接收受试者操作特性(roc)曲线来衡量二元分类模型的非平衡性。如果在某一阈值内,验证数据集的平均误差率与frr相等,则该条件下的平均误差率(eer)和平均总误差率(hter)分别评价验证数据集和测试数据集的平均误差率和frr。
109.为了平衡网络计算成本和性能,本应用例在光流表示子网络中使用k=8的动态卷积块,在纹理表示子网络中使用k=4的动态卷积块,因为多级特征融合也会增强表示能力。如步骤4所述,这3个子网络被分别训练,它们的所有输出都可以用来对真假人脸进行分类。3个子网络的评估结果如表1和表2所示,纹理和光流表现子网络分别达到了hter=2.58%@eer=2.02%和hter=2.18%@eer=4.50%,特征融合子网络达到hter=0.66%@eer=1.26%,这证实了纹理和光学特征融合是表现攻击检测的一个好选择。详细来说,融合方法正确识别了14840个活体人脸和44381个假人脸,错误分类了519个假样本和27个真实样本,准确率为99.08%,明显优于仅使用纹理或光流子网络时的分类结果。
110.表1本文针对重放攻击提出了不同子网络的分类评价评估结果
[0111][0112]
*t:纹理表示子网络,o:光流表示子网络,f:特征融合子网络
[0113]
表2本文针对重放攻击提出的体系结构中各子网络的分类精度和混淆矩阵
[0114][0115]
*t:纹理表示子网络,o:光流表示子网络,f:特征融合子网络
[0116]
本应用例提出的网络的输出是一个2维向量,分别表示真实人脸和假人脸的可能性。如图8所示,本应用例直观地显示了所有样本在仅用表示子网络或融合子网络计算可能性时的有效性,对所有样本的活人脸可能性进行可视化处理,真实样本和假样本分别用蓝色和橙色标记。很明显,与纹理或光流表现子网络相比,特征融合模型对大多数真实样本预测的真实面孔的可能性更接近于1,而融合模型对攻击样本预测的远程可能性也是如此。同时,融合模型对攻击样本的真实面孔的可能性也比较大。本应用例还通过roc曲线对这三个子网络的二值分类性能进行了评价,如图9所示。其中,纹理表示、光流表示和特征融合子网络获得的auc分别为0.998、0.991和0.999。其中,融合模型取得了最佳效果。
[0117]
表3在重放攻击数据集上与其他基于纹理和动态特征的pad方法性能比较
[0118][0119]
本应用例提出的方法在重放攻击数集上的性能很好,与其他基于纹理或动态特征类别的方法相比,具有竞争力。如表3所示。基于融合光流和纹理特征的方法的eer值为1.26%,hter值为0.66%。
[0120]
应用例2:
[0121]
本应用例给出了一种基于上述实施例的考虑人脸欺诈的车载系统安全认证管理方法,本应用例中,为了探讨超参数k(dcb的聚合核数),并证明所提方法的dcb和mlffb的积极性。本发明所有的消融研究都是在不同的光照条件和高分辨率的照片打印的重放攻击上进行的。动态卷积块中卷积核的数量控制着模型的复杂度,所提出的动态卷积块根据不同的输入,在其输出的基础上动态调整k卷积核的权重,并可适用于任何cnn结构。
[0122]
表4动态卷积块中不同卷积核数(k)对人脸抗欺骗的影响
[0123][0124]
如表4所示,不同k的动态卷积的分类性能不同。本应用例比较了第一个卷积层被dcb置换的mobilenetv2和dy-mobilenetv2。即使在k=2较小的情况下,动态卷积也表现出
更突出的表现能力,实现了hter=2.31%
[0125]
@eer=5.09%,与mobilenetv2相比分别减少了7.6%和16.1%,这表明了本应用例方法的有效性和优越性。此外,随着内核数的增加,错误率继续降低,例如,当k=8时,本应用例得到的hter=1.88%@eer=3.24%。这是因为动态卷积块聚集了更多的内核,使模型更加复杂,这对表示有帮助,但同时也增加了内存和计算成本。
[0126]
应用例3:
[0127]
本应用例给出了一种基于上述实施例的考虑人脸欺诈的车载系统安全认证管理方法,本应用例中,本发明在mobilenetv2的block3,6,13之后使用了中间层特征提取块,为了显示mobilenetv2与多级特征融合的分类性能的差异,将中间层特征提取块的输出和mobilenetv2的fc通过多层次特征融合块进行融合,生成最终的纹理特征。表5显示了mobilenetv2与多级特征融合的分类性能的比较。很明显,与mobilenetv2相比,mlffmobilenetv2得到了显著的结果。详细来说,利用多级特征融合的网络获得了ter=0.83%@eer=1.65%,far=0.06%,frr=1.61%,进一步低于原网络的度量值。如图10所示,显示了多级特征融合区块中注意力权重的热图,直观地表明mobilenetv2中从区块6,13的输出中提取的中间特征在活泼性特征呈现和攻击检测过程中发挥了更重要的作用。
[0128]
表5 mobilenetv2与多级特征融合的分类性能的比较
[0129]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1