基于多通道融合的图像识别方法、装置和存储介质与流程
1.本发明涉及计算机视觉相关技术领域,更具体地,涉及一种基于多通道融合的图像识别方法、装置和存储介质。
背景技术:
2.随着机器视觉与人工智能技术的发展,基于机器视觉的人工智能应用已广泛应用于各行各业,如人脸检测、行人追踪、目标检测等。然而定制化的人工智能在智慧工地应用中仍然存在一定困难:一方面,视觉应用相关的人工智能场景往往需要gpu服务器计算资源予以算力支撑,在部署端实施需要现场机房提供部署条件;另一方面,不同应用场景的定制化需求(如保安识别、着装识别)需要对算法模型进行定制化的开发。
3.目前,边缘端的机器视觉人工智能应用如图像分类、目标定位、目标识别等,为了达到较高的可应用性,需要在应用边缘端部署服务器+gpu显卡进行业务处理及模型应用。其缺点是:1、成本高,一台服务器加显卡价格往往达到几万元;2、部署要求高,需要将服务器部署于机房机柜并保证散热条件。经过检索,中国专利公开号cn214846751u公开了一种基于边缘计算的移动人脸布控装置和系统,具体公开了:通过设置远程通讯模块和远程定位模块能够实现远程通讯,传递位置信息和传递智能处理系统的数据信息,通过设置智能处理系统对图片进行预处理、识别以及利用边缘计算模块对图像信息进行特征提取、比对。但是,该专利仅涉及边缘计算的方法,并未涉及使用机器模型识别算法方面的内容。
4.然而,通常使用传统机器学习方法和深度学习方法进行气道类型预测,但是存在识别精度低、可靠性低等问题,并且对于科研、教学的价值非常有限。现有气道预测相关文献还存在数据集规模过小、模型泛化能力太差、识别准确率不高等问题,并且最主要原因在于所使用的图像太过单一,仅凭单张图像来判断是否属于困难气道,可信度不高。另外,在图像分类应用场景下的图像特征提取、图像识别精度等方面仍存在很大改进空间。
5.因此,有必要提供一种改进了的图像识别方法。
技术实现要素:
6.因此,鉴于现有技术中存在的上述问题,而提出本发明。
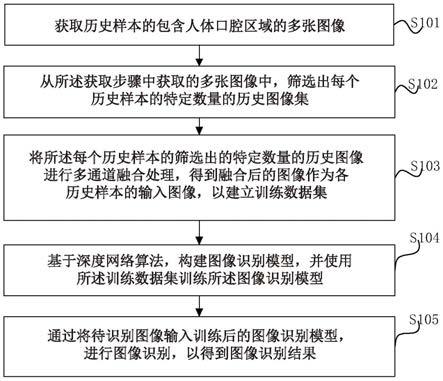
7.根据本发明的第一方面,提供了一种基于多通道融合的图像识别方法,该图像识别方法包括:获取步骤,获取历史样本的包含人体口腔区域的多张图像;筛选步骤,从所述获取步骤中获取的多张图像中,筛选出每个历史样本的特定数量的历史图像;融合步骤,将所述每个历史样本的筛选出的特定数量的历史图像进行多通道融合处理,得到融合后的图像作为各历史样本的输入图像,以建立训练数据集;构建步骤,基于深度网络算法,构建图像识别模型,并使用所述训练数据集训练所述图像识别模型;识别步骤,通过将待识别图像输入训练后的图像识别模型,进行图像识别,以得到图像识别结果。
8.根据优选实施方式,在所述筛选步骤中根据预设筛选参数和筛选规则,从所述获取步骤中获取的多张图像中,筛选出每个历史样本的特定数量的图像;所述预设筛选参数
包括张口度、气道分级、颈长、颈围、头颈活动度和甲颏间距,所述筛选规则包括张口度是否小于指定值,气道分级是否大于指定级别,颈长是否小于设定值或者颈围是否小于设定值,头颈活动度是否小于特定角度,甲颏间距是否小于指定距离。
9.根据优选实施方式,在所述融合步骤中,按照红绿蓝三通道,将所述每个历史样本的筛选出的特定数量的历史图像中各图像拆分成三个通道,并将拆分后的各图像按通道进行图像拼接,以得到融合后的图像。
10.根据优选实施方式,在所述融合步骤中,所述建立训练数据集包括:通过使用气道分级大于等于指定级别、张口度是否小于预定值、颈长是否小于设定值或者颈围是否小于设定值、头颈活动度是否小于特定角度以及甲颏间距是否小于指定距离,定义目标气道的类别标签,来定义正样本和负样本,以确定目标气道和非目标气道,并使用标注有气道类别的通道融合后的图像,建立训练数据集。
11.根据优选实施方式,在所述构建步骤中,包括:通过利用设定的卷积核对特定数量的历史图像进行卷积计算,来完成一次特征提取,得到底层特征信息,并得到第一特征图、第二特征图、第三特征图、第四特征图和第五特征图,第一特征图为包含张口度信息的特征图,第二特征图为包含气道分级信息的特征图,第三特征图为包含颈长信息的特征图,第四特征图为包含颈围信息的特征图,第五特征图为包含甲颏间距信息的特征图;对所得到的第一特征图、第二特征图、第三特征图、第四特征图和第五特征图进行后续的多次特征提取,得高层特征信息,该高层特征信息用于表征目标气道相关的抽象特征信息。
12.根据优选实施方式,在所述构建步骤中,在模型训练过程中,通过最小化网络在训练数据集上的交叉熵损失函数来不断优化网络,使其拟合出用于进行气道分类的判断曲线;根据正样本与负样本的数量比例,设置目标气道和非目标气道的类权重。
13.根据优选实施方式,所述图像识别方法还包括:预处理步骤,在进行多通道融合处理之前,对筛选出的特定数量的历史图像进行数据预处理,所述数据预处理包括去背景、边缘提取、口腔区域截取、数据增强处理;其中所述数据增强处理包括对样本图像进行水平翻转,在指定角度范围内随机旋转、缩放、调整亮度、对比饱和度和色调,并在所述数据增强处理之后进行归一化处理。
14.根据优选实施方式,利用densenet算法,构建图像识别模型。
15.根据优选实施方式,在所述识别步骤中,通过筛选出被检体的多张图像,并将所述被检体的多张图像经多通道信息融合后获得的图像作为待识别图像,输入训练后的图像识别模型,来输出是否为目标气道的图像识别结果。
16.根据本发明的第二方面,提供了一种图像识别装置,该图像识别装置包括:数据获取模块,用于获取历史样本的包含人体口腔区域的多张图像;数据筛选模块,用于从获取的多张图像中,筛选出每个历史样本的特定数量的历史图像;融合处理模块,用于将所述每个历史样本的筛选出的特定数量的历史图像进行多通道融合处理,得到融合后的图像作为各历史样本的输入图像以建立训练数据集;模型构建模块,用于基于深度网络算法,构建图像识别模型,并使用所述训练数据集训练所述图像识别模型;图像识别模块,用于通过将待识别图像输入训练后的图像识别模型,进行图像识别,以得到图像识别结果。
17.根据优选实施方式,所述数据筛选模块根据预设筛选参数和筛选规则,从获取的多张图像中,筛选出每个历史样本的特定数量的图像;所述预设筛选参数包括张口度、气道
分级、颈长、颈围、头颈活动度和甲颏间距,所述筛选规则包括张口度是否小于指定值,气道分级是否大于指定级别,颈长是否小于设定值或者颈围是否小于设定值,头颈活动度是否小于特定角度,甲颏间距是否小于指定距离。
18.根据优选实施方式,所述融合处理模块按照红绿蓝三通道,将所筛选出的特定数量的历史图像中各图像拆分成三个通道,并将拆分后的各图像按通道进行图像拼接,以得到融合后的图像。
19.根据本发明的第三方面,提供了一种暂时性计算机可读存储介质,其用于存储程序,当所述程序被计算机执行时,实现本发明的第一方面所述的图像识别方法。
20.与现有技术相比,本发明的图像识别方法通过对图像进行多通道融合,能够充分利用多维特征信息,从而提高识别气道类型的准确性;通过在所有的样本数据输入网络完成一次向前计算及反向传播过程中对学习率进行调整,能够优化模型参数;通过在模型训练过程中进行特征提取,能够更精确地提取与目标气道相关的特征信息,能够保证模型更好地收敛,能够提高实验效率,还能够降低过拟合,从而能够更有效地提高模型识别精度;通过为样本量少的气道类别设置更高的类权重且同时为样本量多的气道类别降低权重的方法,以避免样本量少的类别中的错误分类,由此,能够有效缓解训练数据中正负样本不均衡的问题;通过所述模型测试进一步优化模型性能。
21.通过以下参照附图的描述,本发明的其他特征及优点将变得清楚。
附图说明
22.包含在说明书中并构成说明书的一部分的附图,例示了本发明的实施例,并且与文字描述一起用于说明本发明的原理。
23.图1是示意性示出了本发明的基于多通道融合的图像识别方法的一示例的流程图。
24.图2是示意性示出了本发明的图像识别方法中筛选出的特定数量的历史图像的一示例的示意图。
25.图3是示意性示出了本发明的基于多通道融合的图像识别方法的另一示例的流程图。
26.图4是本发明的基于多通道融合的图像识别装置的一示例的结构框图。
27.图5是本发明的基于多通道融合的图像识别装置的另一示例的结构框图。
28.图6例示了根据本发明的计算机设备的一示例的示意图。
29.图7例示了根据本发明的计算机可读存储介质的一示例的示意图。
具体实施方式
30.下面,将参照附图来详细描述本发明的示例性实施例。应当指出,以下的描述实质上仅是说明性和示例性的,并且决不旨在限制本发明及其应用或用途。在实施例中陈述的构成要素及步骤的相对布置、数值表达式以及数值并不限制本发明的范围,除非另外特别指明。此外,本领域的技术人员公知的技术、方法及设备可能不被详细讨论,但在适当的情况下旨在作为本说明书的一部分。
31.注意,类似的附图标记和字母在整个附图中是指类似项目,由此一旦在一个图中
定义了项目,则在后面的图中不需要讨论该项目。
32.实施例1
33.图1是示意性示出了本发明的基于多通道融合的图像识别方法的一示例的流程图。
34.如图1所示,本发明的图像识别方法包括如下步骤:
35.步骤s101,获取步骤,获取历史样本的包含人体口腔区域的多张图像;
36.步骤s102,筛选步骤,从所述获取步骤中获取的多张图像中,筛选出每个历史样本的特定数量的历史图像;
37.步骤s103,融合步骤,将每个历史样本的筛选出的特定数量的历史图像进行多通道融合处理,得到融合后的图像作为各历史样本的输入图像,以建立训练数据集;
38.步骤s104,构建步骤,基于深度网络算法,构建图像识别模型,并使用所述训练数据集训练所述图像识别模型;
39.步骤s105,识别步骤,通过将待识别图像输入训练后的图像识别模型,进行图像识别,以得到图像识别结果。
40.以下将结合面罩通气场景下的气道类型识别的具体应用示例,对上述步骤进行具体说明。
41.首先,在步骤s101,即在获取步骤中,获取历史样本的包含人体口腔区域的多张图像,并从中筛选出特定数量的历史图像。
42.例如,从第三方平台或其他医疗机构所公开的数据库中,获取历史样本数据的多张图像,具体获取不同拍摄角度且包含不同人体部位的多张图像,例如9张图像。
43.需要说明的是,上述仅作为示例进行说明,不能理解成对本发明的限制。在其他示例中,还可获取9张以上,例如10张、11张、20张或更多张历史图像,由此对应不同的特定数量n。此外,在本发明中,所述的人体部位包括身体颈部、面部、口部等部位以及形体等。此外,所述历史样本是指历史用户样本数据,有时也称为用户样本数据。
44.接下来,将描述步骤s102(即筛选步骤)。在步骤s102中,即在筛选步骤中,从所述获取步骤中获取的多张图像中,筛选出每个历史样本的特定数量的历史图像。
45.可选地,根据预设筛选参数和筛选规则,筛选出特定数量n的图像,n为小于在获取步骤中获取的历史样本的图像张数的整数,例如4~8。
46.可选地,所述预设筛选参数包括张口度、气道(mallampati)分级、颈长、颈围、头颈活动度和甲颏间距。
47.需要说明的是,在本发明中,所述气道分级包括四级气道,一级气道是指可以看到软腭、咽腭弓、悬雍垂、硬腭,二级气道可以是指可以看到软腭、悬雍垂、硬腭,三级气道是指可以看到软腭和硬腭,四级气道是指只能看到硬腭。所述张口度信息是指最大张口时上下门齿间的距离,正常为3.5-5.6cm(约3指),平均4.5cm。颈长或颈围是指脖子的长度以及粗细程度。所述头颈活动度是指仰卧位下作最大限度仰颈,上门齿前端至枕骨粗隆的连线与身体纵轴线相交的角度,正常值》90
°
。所述甲颏间距是指颈部完全伸展时甲状软骨切迹至颏凸的距离,正常》6.5cm。
48.具体地,除了上述的预设筛选参数,所述预设筛选参数还包括以下信息中一个或多个作为预设筛选参数:上门齿和下门齿的对齐信息、上门齿的长度、下颌骨的水平长度。
49.进一步地,所述筛选规则包括自然咬合状态下上门齿和下门齿能否正常对齐,上门齿的长度是否大于指定长度,张口度是否小于指定值,气道分级是否大于指定级别,颈长是否小于设定值或者颈围是否小于设定值,头颈活动度是否小于特定角度(例如80度),甲颏间距是否小于指定距离,下颌骨的水平长度是否小于设置值,下切牙前伸能否咬到上嘴唇等。
50.例如,根据上述预设筛选参数,从所述获取步骤中所获取的9张图像中,筛选出每个历史样本(即用户样本)的如图2所示的5张图像。
51.可选地,对于特定数量(即筛选数量)的确定,例如根据筛选参数的数量和/或大于等于所获取的图像数量的1/2。
52.需要说明的是,上述仅作为示例进行说明,不能理解成对本发明的限制。
53.图3是示意性示出了本发明的基于多通道融合的图像识别方法的另一示例的流程图。
54.如图3所示,在另一实施方式中,所述图像识别方法还包括预处理步骤s201。
55.在步骤s201中,即在预处理步骤中,在进行多通道融合处理之前,对每个历史样本的筛选出的特定数量的历史图像进行数据预处理。
56.需要说明的是,由于图3中的步骤s101、s102、s103和s104与图1中的步骤s101、s102、s103和s104大致相同,因此省略了对步骤s101、s102、s103和s104的具体说明。
57.具体地,所述数据预处理包括去背景、边缘提取、口腔区域截取、数据增强处理。
58.例如,使用现有的语义分割库paddleseg中的人像分割模型或其他现有模型,对每个历史样本的筛选出的5张图像中的背景与人像图像进行分割,分割出人体图像的区域,并将除人体图像以外的其他区域设置为例如黑色。由此,通过进行去背景处理,能够排除背景图像所带来的干扰影响。
59.此外,还包括对图2中第一个图像(即纸面左侧的第一个图像)进行裁剪处理,即将口腔区域裁剪出来,以得到图2中的第五个图像(即纸面右侧的第一个图像),由此,能够去除图像中的其他特征(例如戴眼镜与否、眼睛睁开与否、鼻子的大小等),能够进一步提高图像数据质量。
60.可选地,对包含颈长颈围、头颈活动度、甲颏距离信息的图像,通过canny边缘检测算法获取图像中下颌脖颈的轮廓、线条等多种边缘轮廓信息,以得到图2中间的三张图像。
61.在另一实施方式中,还包括使用人脸识别模型进行脸部关键点标注,例如,生成如468个点的3d脸部界标,由此,能够更准确地裁剪出口腔区域。
62.需要说明的是,对于人脸识别模型,可以使用现有的机器学习模型,使用深度神经网络,xgboost算法、逻辑回归算法等构建人脸识别模型,上述仅作为示例,进行说明,不能理解成对本发明的限制。
63.由于获取图像时不同图像所使用的手机型号不同,所拍摄的图像的像素尺寸会有所差异,因此,所获取的数据集中图像数据包含多种尺寸类型的图片,例如2976
×
3968、1080
×
2327、3024
×
4032、1080
×
1440、3000
×
4000、600
×
800等。但是,由于模型输入图像的尺寸存在一定的要求,例如输入图像是224
×
224的rgb图像,所以在数据预处理的时候需要将宽高不等的图像尺寸调整为宽高相等的224
×
224。例如采取将图像按长边做等比缩放、剩余区域用0像素值进行填充的缩放策略将图像尺寸调整为224
×
224,因此,能够保证
在调整图像尺寸时,图像宽高比相等、图像不会发生形变。
64.此外,对上述5张图像还进行了数据增强处理。具体地,所述数据增强处理包括对样本图像进行水平翻转,在指定角度范围内(例如指定角度为10度)随机旋转、缩放、调整亮度、对比饱和度和色调,并在所述数据增强处理之后进行归一化处理。因此,能够进一步增加数据量,并能够提高模型的泛化能力。
65.接下来,将描述步骤s103(即融合步骤)。在步骤s103中,即在融合步骤中,将所述每个历史样本的筛选出的特定数量的历史图像进行多通道融合处理,得到融合后的图像作为各历史样本的输入图像,以建立训练数据集。
66.为了进一步提高网络输入数据的数据质量,本发明对用于建立训练数据集的样本数据进行多通道信息融合处理,以使用户样本数据包含多维特征信息,由此,进一步提高模型识别精度。
67.具体地,所筛选出的图像例如为rgb图像。
68.更具体地,按照红绿蓝三通道,将所述特定数量的历史图像(例如上述5张图像)中各图像拆分成三个通道,并将拆分后的各图像进行图像拼接,以得到融合后的图像。
69.在一具体实施方式中,例如将上述5张图像分别拆成三个通道,即3*5=15个通道,例如图像尺寸为224
×
224
×
3,其中,3表示图像的通道数,224
×
224表示每个通道图像的宽与高,将5张图像在通道维度叠加起来,就可以得到224
×
224
×
15的多通道图像。5个格式为224
×
224
×
3的图像转变成一个格式为224
×
224
×
15的图像,即得到融合后的图像,并将该融合后的图像,作为模型的输入图像。
70.在一具体实施方式中,对于用来对目标气道与非目标气道分类的气道分类标签,可使用多种参数,例如气道分级大于等于指定级别(例如气道三级,该气道三级是指可以看到软腭和硬腭)、张口度是否小于预定值(例如,小于3cm)、颈长是否小于设定值或者颈围是否小于设定值、头颈活动度是否小于特定角度(例如80度)以及甲颏间距是否小于指定距离,定义目标气道的类别标签,即定义正样本和负样本,以确定目标气道(对应正样本、即困难气道)和非目标气道(对应负样本,即非困难气道),并对融合后的图像进行目标气道的类别标注。
71.例如,在气道分级大于等于三级气道、张口度小于3cm、颈长小于设定值或者颈围小于设定值、头颈活动度小于80度,以及甲颏间距小于3cm时,定义为目标气道(对应正样本、即困难气道),而在气道分级小于三级气道、张口度大于等于3cm、颈长大于等于设定值或者颈围大于等于设定值、头颈活动度大于等于80度,以及甲颏间距大于等于3cm时,定义为非目标气道(对应负样本,即非困难气道)。
72.接着,使用标注有气道类型的通道融合后的历史样本(历史用户样本数据),建立训练数据集,以用于训练数据模型。
73.例如,所述训练数据集包括标注有气道类型的历史样本。
74.需要说明的是,上述仅作为示例进行说明,不能理解成对本发明的限制。在其他示例,还可以使用下颌骨的水平长度(从下颌角至颏凸的距离)、下切牙前伸能否咬到上嘴唇、上门齿的长度等表征气道分类标签(即y标签)。
75.接下来,在步骤s104中,即在构建步骤中,基于深度网络算法,构建图像识别模型,并使用所述训练数据集训练所述图像识别模型。
76.优选地,利用densenet(密集连接卷积网络),构建图像识别模型。
77.具体地,例如使用1000分类问题所对应的数据集,对所述图像识别模型的imagenet数据集上进行预训练处理。
78.进一步地,使用步骤s102所建立的训练数据集对预训练好的图像识别模型进行重新训练(即迁移学习)。
79.因此,通过上述模型训练的过程,能够保证模型更好地收敛,能够提高实验效率,还能够降低过拟合。
80.在一具体实施方式中,将神经网络中epoch设置为60~120,优选为80。使用交叉熵损失函数,采用adam优化算法,batchsize(批大小)的大小受gpu内存限制例如设置为20。
81.需要说明的是,所述epoch可以解释为1代,一个epoch指的是将所有的样本数据输入模型网络完成一次向前计算及反向传播的过程。
82.对于学习率,采用动态调整的方式,例如,模型训练的初始时刻设为0.001,且在2/3epoch将学习率调整为0.001。例如,所述在2/3个epoch调整学习率。具体是指在epoch设为90时,则当epoch值为60时调整学习率。
83.通过在所有的样本数据输入网络完成一次向前计算及反向传播过程中对学习率进行调整,能够优化模型参数。
84.在该实施方式中,所述构建步骤还包括特征提取过程。
85.下面将进一步说明模型训练过程中的特征提取过程。
86.具体地,通过利用设定的卷积核对特定数量的历史图像进行卷积计算,来完成一次特征提取。
87.更具体地,设定卷积核,使用特定数量的历史图像进行卷积计算,以完成一次特征提取,得到底层特征信息,并得到第一特征图、第二特征图、第三特征图、第四特征图和第五特征图,第一特征图为包含张口度信息的特征图,第二特征图为包含气道分级信息的特征图,第三特征图为包含颈长信息的特征图,第四特征图为包含颈围信息的特征图,第五特征图为包含甲颏间距信息的特征图。例如,所述底层特征信息包括与张口度、气道(mallampati)分级、颈长、颈围、头颈活动度和甲颏间距等相关的信息。
88.例如,使用densenet-121,该网络包括1个核尺寸为7
×
7的卷积层、1个3
×
3的最大池化层、4个dense block(密集块)结构、3个transition layer(过滤层)结构、1个7
×
7的平均池化层和1个全连接层。其中,模型输入是经过数据预处理和多通道信息融合后形成的图像,输出的是目标气道或非目标气道的确定结果。
89.需要说明的是,densenet-121的卷积池化结构是特征提取模块,即负责从输入(即所输入的图像)中提取特征,最后的全连接层是分类模块,负责对提取到的特征进行分类。此外,在其他示例中,还可以直接输出目标气道或非目标气道。进一步地,对所得到的第一特征图、第二特征图、第三特征图、第四特征图和第五特征图进行后续的多次特征提取,得高层特征信息,该高层特征信息用于表征目标气道相关的抽象特征信息。例如,抽象特征信息包括底层特征之间的关联信息、各底层特征与气道类型的关联信息。
90.在本实施方式中,所述训练数据集包括标注有气道类型的历史图像、高层特征信息和底层特征信息。
91.因此,通过在模型训练过程中进行特征提取,能够更精确地提取与目标气道相关
的特征信息,能够更有效地提高模型识别精度。
92.接下来,将说明步骤s105(即识别步骤)。在步骤s105中,即在识别步骤中,通过将待识别图像输入训练后的图像识别模型,进行图像识别,以得到图像识别结果。
93.具体地,通过筛选出被检体的多张图像,并将所述被检体的多张图像经多通道信息融合后的图像作为待识别图像,输入训练后的图像识别模型,来输出是否为目标气道的图像识别结果。
94.因此,通过上述识别步骤,能够更精确识别出被检体的气道类型。
95.在另一实施方式中,在模型训练过程中,通过最小化网络在训练数据集上的交叉熵损失函数来不断优化网络,使模型拟合出用于进行气道分类的判断曲线,其中,模型对待识别图像提取特征,如果提取到的特征符合判断曲线上目标气道类型的特征,则属于目标气道类型。具体地,所提取的特征转换成判断曲线的曲线参数。
96.具体地,所述判断曲线用于表征待识别图像与气道类型的关系,用于识别待识别图像是否为目标气道。
97.更具体地,交叉熵损失的计算公式如下。
[0098][0099]
其中l是指交叉熵损失的损失值;yi是指气道类型的标签值;pi=m
cl
(fi),pi指的是样本xi所对应的softmax函数的输出,m
cl
是指模型的分类模块,fi指的是提取到的特征信息,fi=m
ex
(xi),其中xi是指第i个样本,i=1,从1到n个。
[0100]
在又一实施方式中,根据正样本与负样本的数量比例,设置目标气道和非目标气道的类权重。
[0101]
例如非目标气道的样本数量是目标气道的样本数据的3倍,目标气道的气道类别的类权重设置为非目标气道的气道类型的3倍,通过为样本量少的气道类别设置更高的类权重且同时为样本量多的气道类别降低权重的方法,以避免样本量少的类别中的错误分类,由此,能够有效解决训练数据中正负样本不均衡的问题。
[0102]
在又一实施方式中,还包括进行模型测试,通过所述模型测试进一步优化模型性能。
[0103]
具体地,模型训练结束后进行模型测试。
[0104]
相应地,还包括建立与模型测试相对应的测试集。
[0105]
具体地,使用测试集中的样本数据,对所述图像识别模型进行图像识别测试,并将模型的预测结果与实际结果进行比较,看模型预测得正确与否,以调整模型的模型参数。
[0106]
为了验证本发明的图像识别模型的模型预测精度,使用敏感度(sensitivity)、召回率(recall)、特异度(specificity)、roc曲线、auc值、精确度(precision)和准确率(accuracy)中的至少两个参数,对模型预测精度进行验证。
[0107]
使用同样的方法在相同的训练数据和测试集上,对本发明的图像识别模型、以使用resnet(残差神经网络)101、inceptionv3作为参照,进行对比。可得到表1的模型测试结果。
[0108]
表1模型测试结果对比
[0109][0110]
从表1中可知,本发明的图像识别模型(对应densenet-121)在测试集上达到了87.10%的分类准确率,而resnet101和inceptionv3分别只有64.52%和72.58%的分类准确率,densenet-121的auc值比resnet101高27%,比inceptionv3高16%。敏感度与特异度指标能反映出模型的漏判率(即1-敏感度)和误判率(即1-特异度),敏感度与特异度越高,则漏判率和误判率越低,说明模型识别效果越好(即识别精度越高)。对于densenet-121来说,其敏感度与特异度达到了一个相对均衡且较高的水平,模型的敏感度达到了88.89%。
[0111]
需要说明的是,在本发明中,所述敏感度表示模型对真目标做出阳性反应的程度,敏感性越高,则越容易鉴定出目标,即越灵敏。特异度表示模型对假目标做出阴性反应的程度,特异性越高,则越不容易误报,模型的筛选能力或者说针对能力强。因此敏感度与特异度越高,说明模型识别效果越好。
[0112]
通过上述说明可知,相对于其他算法,本发明的图像识别模型的分类准确率、识别精度、敏感度和特异度更高。此外,本发明的图像识别模型应用广泛,还适用于气管插管应用场景或其他需要识别气道类型的应用场景。
[0113]
与现有技术相比,本发明的图像识别方法通过对图像进行多通道融合,能够充分利用多维特征信息,能够提高识别气道类型的准确性;通过在所有的样本数据输入网络完成一次向前计算及反向传播过程中对学习率进行调整,能够优化模型参数;通过在模型训练过程中进行特征提取,能够更精确地提取与目标气道相关的特征信息,能够保证模型更好地收敛,能够提高实验效率,还能够降低过拟合,能够更有效地提高模型识别精度;通过为样本量少的气道类别设置更高的类权重且同时为样本量多的气道类别降低权重的方法,以避免样本量少的类别中的错误分类,由此,能够有效缓解训练数据中正负样本不均衡的问题;通过所述模型测试进一步优化模型性能。
[0114]
实施例2
[0115]
参照图4和图5,本发明还提供了一种基于多通道融合的图像识别装置400,其中,所述图像识别装置400包括:数据获取模块401,用于获取历史样本的包含人体口腔区域的多张图像;数据筛选模块402,用于从获取的多张图像中,筛选出每个历史样本的特定数量的历史图像;融合处理模块403,用于将所述每个历史样本的筛选出的特定数量的历史图像进行多通道融合处理,得到融合后的图像作为各历史样本的输入图像,以建立训练数据集;模型构建模块404,用于基于深度网络算法,构建图像识别模型,并使用所述训练数据集训练所述图像识别模型;图像识别模块405,用于通过将待识别图像输入训练后的图像识别模型,进行图像识别,以得到图像识别结果。
[0116]
在另一实施方式中,数据获取模块401被整合在数据筛选模块402中,即数据筛选模块402还具有数据获取模块的功能。
[0117]
具体地,所述数据筛选模块根据预设筛选参数和筛选规则,从获取的多张图像中,
筛选出每个历史样本的特定数量n的图像,n为4~8。
[0118]
可选地,所述预设筛选参数包括张口度、气道分级、颈长、颈围、头颈活动度和甲颏间距,所述筛选规则包括张口度是否小于指定值,气道分级是否大于指定级别,颈长是否小于设定值或者颈围是否小于设定值,头颈活动度是否小于特定角度,甲颏间距是否小于指定距离。
[0119]
可选地,所述融合处理模块403按照红绿蓝三通道,将所筛选出的特定数量的历史图像中各图像拆分成三个通道,并将拆分后的各图像按通道进行图像拼接,以得到融合后的图像。
[0120]
对于训练数据集的建立,例如通过使用气道(mallampati)分级大于等于指定级别、张口度是否小于预定值、颈长是否小于设定值或者颈围是否小于设定值、头颈活动度是否小于特定角度以及甲颏间距是否小于指定距离,定义目标气道的类别标签,来定义正样本和负样本,以确定目标气道和非目标气道,并使用标注有气道类型的通道融合后的图像,建立训练数据集。
[0121]
对于模型特征提取,通过利用设定的卷积核对特定数量的历史图像进行卷积计算,来完成一次特征提取,得到底层特征信息,并得到第一特征图、第二特征图、第三特征图、第四特征图和第五特征图,第一特征图为包含张口度信息的特征图,第二特征图为包含气道分级信息的特征图,第三特征图为包含颈长信息的特征图,第四特征图为包含颈围信息的特征图,第五特征图为包含甲颏间距信息的特征图。
[0122]
进一步地,对所得到的第一特征图、第二特征图、第三特征图、第四特征图喝第五特征图进行后续的多次特征提取,得高层特征信息,该高层特征信息用于表征目标气道相关的抽象特征信息。
[0123]
在另一实施方式中,在模型训练过程中,通过最小化网络在训练数据集上的交叉熵损失函数来不断优化网络,使其拟合出用于进行气道分类的判断曲线。
[0124]
可选地,根据正样本与负样本的数量比例,设置目标气道和非目标气道的类权重。
[0125]
图5是本发明的基于多通道融合的图像识别装置的另一示例的结构框图。
[0126]
在又一实施方式中,所述图像识别装置还包括预处理模块501,所述预处理模块501用于对所述每个历史样本的筛选出的特定数量的历史图像进行数据预处理。
[0127]
具体地,所述预处理模块501在进行多通道融合处理之前,对所述每个历史样本的筛选出的特定数量的历史图像进行数据预处理,所述数据预处理包括去背景、边缘提取、口腔区域截取、数据增强处理;其中所述数据增强处理包括对样本图像进行水平翻转,在指定角度范围内随机旋转、缩放、调整亮度、对比饱和度和色调,并在所述数据增强处理之后进行归一化处理。
[0128]
对于模型构建,利用densenet(密集连接卷积网络)算法,构建图像识别模型。
[0129]
具体地,通过筛选出被检体的多张图像,并将所述被检体的多张图像经多通道信息融合后的图像作为待识别图像,输入训练后的图像识别模型,来输出是否为目标气道的图像识别结果。
[0130]
需要说明的是,在实施例2中,省略了与实施例1相同的部分的说明。
[0131]
与现有技术相比,本发明的图像识别装置通过对图像进行多通道融合,能够充分利用多维特征信息,能够提高识别气道类型的准确性;通过在所有的样本数据输入网络完
成一次向前计算及反向传播过程中对学习率进行调整,能够优化模型参数;通过在模型训练过程中进行特征提取,能够更精确地提取与目标气道相关的特征信息,能够保证模型更好地收敛,能够提高实验效率,还能够降低过拟合,能够更有效地提高模型识别精度;通过为样本量少的气道类别设置更高的类权重且同时为样本量多的气道类别降低权重的方法,以避免样本量少的类别中的错误分类,由此,能够有效缓解训练数据中正负样本不均衡的问题;通过所述模型测试进一步优化模型性能。
[0132]
实施例3
[0133]
下面描述本发明的计算机设备实施例,该计算机设备可以视为对于上述本发明的方法和装置实施例的具体实体实施方式。对于本发明计算机设备实施例中描述的细节,应视为对于上述方法或装置实施例的补充;对于在本发明计算机设备实施例中未披露的细节,可以参照上述方法或装置实施例来实现。
[0134]
图6是本发明的一个实施例的计算机设备的结构示意图,该计算机设备包括处理器和存储器,所述存储器用于存储计算机可执行程序,当所述计算机程序被所述处理器执行时,所述处理器执行图1的方法。
[0135]
如图6所示,计算机设备以通用计算设备的形式表现。其中处理器可以是一个,也可以是多个并且协同工作。本发明也不排除进行分布式处理,即处理器可以分散在不同的实体设备中。本发明的计算机设备并不限于单一实体,也可以是多个实体设备的总和。
[0136]
所述存储器存储有计算机可执行程序,通常是机器可读的代码。所述计算机可读程序可以被所述处理器执行,以使得计算机设备能够执行本发明的方法,或者方法中的至少部分步骤。
[0137]
所述存储器包括易失性存储器,例如随机存取存储单元(ram)和/或高速缓存存储单元,还可以是非易失性存储器,如只读存储单元(rom)。
[0138]
可选地,该实施例中,计算机设备还包括有i/o接口,其用于计算机设备与外部的设备进行数据交换。i/o接口可以为表示几类总线结构中的一种或多种,包括存储单元总线或者存储单元控制器、外围总线、图形加速端口、处理单元或者使用多种总线结构中的任意总线结构的局域总线。
[0139]
应当理解,图6显示的计算机设备仅仅是本发明的一个示例,本发明的计算机设备中还可以包括上述示例中未示出的元件或组件。例如,有些计算机设备中还包括有显示屏等显示单元,有些计算机设备还包括人机交互元件,例如按扭、键盘等。只要该计算机设备能够执行存储器中的计算机可读程序以实现本发明方法或方法的至少部分步骤,均可认为是本发明所涵盖的计算机设备。
[0140]
图7是本发明的一个实施例的暂时性计算机可读存储介质的示意图。如图7所示,暂时性计算机可读存储介质中存储有计算机可执行程序,所述计算机可执行程序被执行时,实现本发明上述方法。所述计算机可读存储介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。所述计算机可读存储介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。所述计算机可读存储介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、有线、光缆、rf等等,或者上述的任意合适的组合。
[0141]
可以以一种或多种程序设计语言的任意组合来编写用于执行本发明操作的程序代码,所述程序设计语言包括面向对象的程序设计语言—诸如java、c++等,还包括常规的过程式程序设计语言—诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任意种类的网络,包括局域网(lan)或广域网(wan),连接到用户计算设备,或者,可以连接到外部计算设备(例如利用因特网服务提供商来通过因特网连接)。
[0142]
通过以上对实施方式的描述,本领域的技术人员易于理解,本发明可以由能够执行特定计算机程序的硬件来实现,例如本发明的系统,以及系统中包含的电子处理单元、服务器、客户端、手机、控制单元、处理器等。本发明也可以由执行本发明的方法的计算机软件来实现,例如由微处理器、电子控制单元,客户端、服务器端等执行的控制软件来实现。但需要说明的是,执行本发明的方法的计算机软件并不限于由一个或特定个的硬件实体中执行,其也可以是由不特定具体硬件的以分布式的方式来实现。对于计算机软件,软件产品可以存储在一个计算机可读的存储介质(可以是cd-rom,u盘,移动硬盘等)中,也可以分布式存储于网络上,只要其能使得计算机设备执行根据本发明的方法。
[0143]
虽然已利用示例详细说明了本发明的一些具体实施例,但是本领域技术人员应当理解,以上示例仅旨在举例说明,并非限制本发明的范围。本领域技术人员应当理解,在不背离本发明的范围和精神的情况下,可以对以上实施例进行修改。本发明的范围由所附权利要求限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1