一种基于人工神经网络算法的油墨预置方法与流程
1.本发明涉及印刷领域,具体来说,涉及一种基于人工神经网络算法的油墨预置方法。
背景技术:
2.在胶版印刷工艺中,通过控制胶印机的墨牙开度来调节最终印刷品的图文深浅,达到精确复制和印刷效果。因此根据被印刷图文的深浅分布,调节印刷机每个墨牙的开度是印刷工艺中很关键的一环。墨牙开度大小直接影响印刷品质量。
3.传统的方式是靠印刷机机长凭借自己的经验调节一个自己觉得相对合理的开度,开机测试,然后根据测试结果进行迭代优化,直至印出的效果达到预期或样张效果。这个过程叫印刷机调机校色过程,是印刷开机量产之前最费时和费纸张的环节。
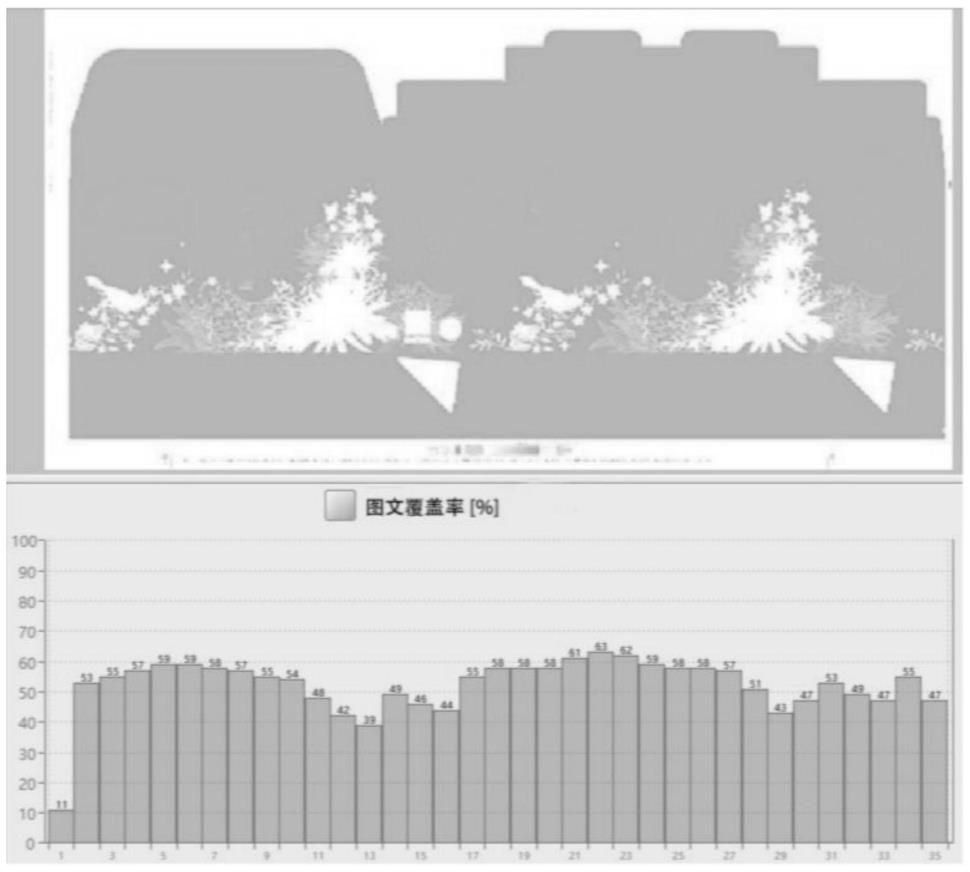
4.请参考图1-2为了辅助印刷机长快速找到最优化的墨牙开度,缩短调机时间,减少调机纸张浪费,降低对人为经验的依赖,本领域出现了一种通过油墨预置曲线进行油墨预置的方法。该方法是通过获取印刷图文在印张上的分布,即图文覆盖率,然后建立起图文覆盖率与墨牙开度之间的映射关系。这种映射关系现即为油墨预置曲线。
5.印品在印张上的图文覆盖率数据在印前计算机直接制版(ctp)过程中即可方便地获取。因此油墨预置的关键就是如何根据已知的图文覆盖率预测该印品在某台印刷机上印刷出预期效果所对应的墨牙开度组合。
6.现有的技术假设最终印品效果只与印品图文覆盖率有关系,并且假设二者是一种线性映射关系,用一根线性曲线即“油墨预置曲线”来通过图文覆盖率预测活件对应的墨牙开度。而实际生产过程中,印品效果与印品图文覆盖率之间的关系并不能用简单的线性对应关系进行充分描述。一个印刷作品的最终效果还受诸如油墨特性、印刷机本身的机械和电气性能、承印物表面光泽度等很多因素的影响。因此用一根经验曲线描述图文覆盖率与某台印刷机的墨牙开度之间的关系,与实际有一定的差距。这会导致油墨预置效果大打折扣,仍然需要进行多次迭代调节才能追上目标效果。
7.再加上实际生产过程中,同一台印刷机通常在不同活件之间切换,使用不同的油墨,机电性能也会随着时间的推移而变化,会加大这种线性油墨预置曲线映射效果的不准确度。有时预置结果甚至与真实结果背道而驰,相差甚远。
8.针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现要素:
9.本发明的目的在于提供一种基于人工神经网络算法的油墨预置方法,以解决上述背景技术中提出的问题。
10.为实现上述目的,本发明提供如下技术方案:
11.一种基于人工神经网络算法的油墨预置方法,包括以下步骤:
12.s1、建立输入层、隐藏层和输出层,三层神经网络油墨预置模型;
13.s2、输入层的内容包括每色印版上对应墨区的平均油墨覆盖率x1,和印刷用油墨的粘度和流动性x2以及描述承印物表面光泽度x3;
14.s3、隐藏层是输入层的全连接层,包括数量为三个的神经元;
15.s4、输出层的输入来源于隐藏层通过激活函数g(z)的计算结果;
16.s5、用经验数据初始化模型参数;
17.s6、按步骤s2的说明,整理模型训练数据集;
18.s7、将整理好的训练数据代入本技术建立的三层神经网络油墨预置模型,计算出训练数据对应的模型输出y值;
19.s8、采用误差逆传播(bp)算法,根据模型输出y值与真实值y之间的误差对八个模型参数进行优化;
20.s9、将新活件对应的三个参数:油墨覆盖率(x1)、印刷油墨特性(x2)和承印物表面光泽度(x3)带入优化后的步骤s8的模型,即可计算出对应的墨牙开度。
21.进一步的,所述步骤s2中,每色印版上对应墨区的平均油墨覆盖率x1的取值范围为[0,1],印刷用油墨的粘度和流动性x2取值范围为[0,1],值越大,油墨粘度越高,描述承印物表面光泽度x3取值范围为[0,1],值越大,承印物表面越光滑。
[0022]
进一步的,所述步骤s3中,隐藏层神经元的计算公式为:zi=wix+bi,其中wi为权重系数,bi为偏倚数,引入选择sigmoid函数为激活函数g(z),对线性输出结果zi进行计算,增加模型的非线性表征能力,从输入层至隐藏层的完整计算过程如下:
[0023]z11
=w1x1[0024]z12
=w1x2[0025]z13
=w1x3[0026]
隐藏层第一个神经元的计算公式为:z1=g(z
11
+z
12
+z
13
+b1)=g(w1x1+w1x2+w1x3+b1);
[0027]z21
=w2x1[0028]z22
=w2x2[0029]z23
=w2x3[0030]
隐藏层第二个神经元的计算公式为:z2=g(z
21
+z
22
+z
23
+b2)=g(w2x1+w2x2+w2x3+b2);
[0031]z31
=w3x1[0032]z32
=w3x2[0033]z33
=w3x3[0034]
隐藏层第三个神经元的计算公式为:z3=g(z
31
+z
32
+z
33
+b3)=g(w3x1+w3x2+w3x3+b3)。
[0035]
进一步的,所述步骤s4中,输出层神经元的计算公式为:z=wx+b,然后再将计算出的结果代入激活函数中,得到最终输出y,即墨牙开度,从隐藏层至输出层的完整计算过程如下:
[0036]
y=g(wz1+wz2+wz3+b)。
[0037]
进一步的,所述步骤s8中采用误差逆传播(bp)算法,根据模型输出y值与真实值y之间的误差对八个模型参数进行优化包括以下步骤:
[0038]
s81、前向传播:从输入层到输出层逐层计算出每个功能神经元的激励函数输出,并缓存;
[0039]
s82、反向传播:从输出层到输入层逐层计算出每个神经元的计算误差,从而计算出梯度,需要使用在前向传播中缓存的激励函数输出值;
[0040]
s83、权值更新:按照更新规则更新权重。
[0041]
进一步的,重复步骤s8,用新产生的印刷生产数据对模型进行动态优化和调整,提高油墨预置模型的逼真程度和预测能力。
[0042]
与现有技术相比,本发明具有以下有益效果:
[0043]
本技术旨在基于深度神经网络算法建立起影响印品效果与多种可变印刷工艺参数之间的多层深度神经网络模型。通过该模型可以充分地描述多种印刷可变参数对最终印品效果的影响,相比目前只用线性转换曲线去描述本是多维复杂映射的关系更加充分和逼近真实世界。通过建立多层深度神经网络油墨预置模型,可以将影响最终印品效果的多种因素纳入进预测和预置过程,可大大提高油墨预置的准确度,减少追样和调机的时间和纸张浪费,提高印刷质量和效率。同时,通过动态迭代和闭环学习,还可以让所建立的多层深度神经网络油墨预置模型在生产过程中不断优化,进一步提升该模型的预置和预测准确度。
附图说明
[0044]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0045]
图1是根据本发明背景技术中一个印张在每个墨区上的图文覆盖率数据;
[0046]
图2是根据本发明背景技术中将图文覆盖率(横轴)转换为墨牙开度(纵轴)的油墨预置曲线;
[0047]
图3是根据本发明实施例的神经网络油墨预置模型;
[0048]
图4是根据本发明实施例的一种基于人工神经网络算法的油墨预置方法流程图。
具体实施方式
[0049]
下面,结合附图以及具体实施方式,对发明做出进一步的描述:
[0050]
请参阅图3-4,根据本发明实施例的一种基于人工神经网络算法的油墨预置方法,包括以下步骤:
[0051]
步骤s1:建立三层神经网络油墨预置模型;
[0052]
步骤s2:输入层x1为每色印版上对应墨区的平均油墨覆盖率,取值范围为[0,1];x2描述印刷用油墨的粘度和流动性,取值范围为[0,1],值越大,油墨粘度越高;x3描述承印物表面光泽度,取值范围为[0,1],承印物表面越光滑,值越大。
[0053]
步骤s3:隐藏层是输入层的全连接层。隐藏层神经元的计算公式为:zi=wix+bi,其中wi为权重系数,bi为偏倚数。g(z)为激活函数。本发明中,选择sigmoid函数为激活函数,函数表达式如下图所示:
[0054][0055]
zi=wix+bi是一个线性计算函数,通过wi来表示输入层三大类别变量:油墨覆盖率、油墨粘度和流动性以及承印物表面特性对输出结果的权重影响。通过引入激活函数g(z),对线性输出结果zi进行计算,增加模型的非线性表征能力。从输入层至隐藏层的完整计算过程如下:
[0056]z11
=w1x1[0057]z12
=w1x2[0058]z13
=w1x3[0059]
隐藏层第一个神经元的计算公式为:z1=g(z
11
+z
12
+z
13
+b1)=g(w1x1+w1x2+w1x3+b1)
[0060]z21
=w2x1[0061]z22
=w2x2[0062]z23
=w2x3[0063]
隐藏层第二个神经元的计算公式为:z2=g(z
21
+z
22
+z
23
+b2)=g(w2x1+w2x2+w2x3+b2)
[0064]z31
=w3x1[0065]z32
=w3x2[0066]z33
=w3x3[0067]
隐藏层第三个神经元的计算公式为:z3=g(z
31
+z
32
+z
33
+b3)=g(w3x1+w3x2+w3x3+b3)
[0068]
步骤s4:输出层的输入来源于隐藏层的的计算结果。输出层神经元的计算公式为:z=wx+b,然后再将计算出的结果代入激活函数中,得到最终输出y,即墨牙开度。从隐藏层至输出层的完整计算过程如下:
[0069]
y=g(wz1+wz2+wz3+b)
[0070]
步骤s5:用经验数据初始化八个模型参数w1,w2,w3,b1,b2,b3,w,b。建议可将w1初始化为7,w2初始化为2,w3初始化为1,b1,b2,b3分别初始化为0.5,w初始化为10。也可以初始化为其它随机值。
[0071]
步骤s6:按步骤s2的说明,整理模型训练数据集,例如(0.62,0.5,0.3-》0.6),其中0.62为某个墨区的平均油墨覆盖率,0.5为所使用油墨的粘度和流动性特性,0.3为所使用纸质表面光泽度,0.6为能达到预期印刷效果的实际墨牙开度;
[0072]
步骤s7:将整理好的训练数据代入本发明建立的三层神经网络油墨预置模型,计算出训练数据对应的模型输出y值;
[0073]
步骤s8:采用误差逆传播(bp)算法,根据模型输出y值与真实值y之间的误差对八个模型参数进行优化。
[0074]
s81、前向传播:从输入层到输出层逐层计算出每个功能神经元的激励函数输出,并缓存。用vi表示在前向传播计算过程中缓存的第i层的值。wi表示第i层和第i+1层之间的权值矩阵。h(vi*wi)为激活函数。后一层的值由前一层的值和权值计算得到:
[0075]vi+1
=h(viwi)
[0076]
s82、反向传播:从输出层到输入层逐层计算出每个神经元的计算误差,从而计算出梯度,这一过程需要使用在前向传播中缓存的激励函数输出值。采用均方差作为神经网络的代价函数,对于训练数据集k,假设输出层为i+1层,则有:
[0077][0078]
计算第i层神经元的梯度:
[0079][0080]
输出层的误差δi=v
i-y即激活函数输出值和真实标记的差;
[0081]
隐藏层的误差δi=g
i+1
wi[0082]
s83、权值更新:按照如下更新规则更新权重:
[0083][0084]
步骤s9:将新活件对应的三个参数:油墨覆盖率(x1)、印刷油墨特性(x2)和承印物表面光泽度(x3)带入步骤s8优化后的模型,即可计算出对应的墨牙开度。
[0085]
对于所述步骤s8来说,可重复步骤s8,用新产生的印刷生产数据对本发明的模型进行动态优化和调整,提高油墨预置模型的逼真程度和预测能力。
[0086]
另外,与本技术方案类似的思路还包括使用其它机器学习方法建立油墨预置模型,包括但不限于支持向量机(svm),决策树学习,遗传算法。这些方案的实质都是利用更加先进的算法和技术更加逼近现实地进行墨牙开度的预测和油墨预置。
[0087]
综上所述,本技术,通过建立非线性的深度神经网络模型,通过该模型进行油墨预置和预测,旨在基于深度神经网络算法建立起影响印品效果与多种可变印刷工艺参数之间的多层深度神经网络模型。通过该模型可以充分地描述多种印刷可变参数对最终印品效果的影响,相比目前只用线性转换曲线去描述本是多维复杂映射的关系更加充分和逼近真实世界。通过建立多层深度神经网络油墨预置模型,可以将影响最终印品效果的多种因素纳入进预测和预置过程,可大大提高油墨预置的准确度,减少追样和调机的时间和纸张浪费,提高印刷质量和效率。
[0088]
同时,通过动态迭代和闭环学习,还可以让所建立的多层深度神经网络油墨预置模型在生产过程中不断优化,进一步提升该模型的预置和预测准确度。
[0089]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1