一种基于神经网络及运动信息的黑白视频着色方法
1.本发明涉及一种基于神经网络及运动信息的黑白视频着色方法,属于图像处理技术领域。
背景技术:
[0002]“着色”一词早在1970年就被提出,在电影、胶片相机刚开始出现的时候,由于当时技术条件的限制,电影、照片都是黑白的,随着市场需求的不断发展,黑白电影、照片渐渐满足不了人们的需求,而具有丰富色彩的彩色电影、照片却大受欢迎,如何将这些黑白视频和照片重新着色是一个值得研究的问题。着色不仅仅在电影艺术领域有所应用,在很多领域,比如:医学领域,对x光透视成像的黑白影像着色,能够帮助医生诊断病情;在军事航空领域,将卫星遥感图像进行着色处理之后,能够将目标与背景形成区分,增加卫星图像的可读性等等。在着色技术发展的初期,主要是通过聘请专业人员手动为视频着色或者是用媒体制作工具逐帧地为视频着色,这样做不仅耗费人力而且成本昂贵。随着深度学习的发展,卷积神经网络与图像领域的结合拓宽了解决问题的思路,出现了一系列基于卷积网络的图像着色方法,这些方法取得了不错的着色效果,并且大大节省了人力和时间。
[0003]
视频着色是一个具有挑战性的问题,相比较于图像着色,由于视频是由多个视频帧组合而成的,在为视频着色的时候不仅需要保证着色的合理性,还需要保持帧与帧之间的空间一致性和时间连续性。在视频着色中,视频中的运动往往会影响视频着色的结果,一个视频中运动的物体越多,运动的速度越快,着色就越困难。如果使用图像着色的方法为视频着色,将黑白视频中的每一帧视为一个图像,针对黑白视频中的每一帧选择对应的彩色参考图像进行匹配,生成彩色视频帧,最终将着色完成的每一帧视频帧进行连接,完成整个着色过程。然而,对每一帧图像单独着色没有考虑到视频帧之间的联系,最终往往会由于帧与帧之间的着色差异而导致视频播放时有视觉上的闪烁。
技术实现要素:
[0004]
现有技术视频着色中,对于视频中的运动物体着色困难、着色结果不准确,甚至导致着色结果出现伪影的缺点,本发明提出了基于自注意力机制及运动信息的视频着色方法。
[0005]
术语解释:
[0006]
源与参考注意力模块,本质上与自注意力机制相同,不同点在于自注意力机制只有源特征一个输入,自注意力机制只关注自身内部的联系。而源与参考注意力模块以两个不同特征作为输入,一个对应于源特征,另一个对应于参考特征,源与参考注意力模块能够挖掘源特征与参考特征之间的非局部相似性,让网络能够找到参考特征中与源特征相似的区域并作用于源特征。
[0007]
自注意力机制,最早在2017年由谷歌团队提出,一开始用于transformer语言模型中,相比较于注意力机制,自注意力机制关注的是内部的联系。将输入的原始数据看作《
key,value》键值对的形式,根据给定的任务目标中的查询值query,计算key与query之间的相似系数,可以得到value值对应的权重系数,之后再用权重系数对value值进行加权求和,即可得到输出。使用q、k、v分别表示query、key和value。自注意力机制的q、k、v都来自同一个数据源,如式()所示,其中是缩放因子,用于防止内积数值过大而影响网络学习。
[0008][0009]
本发明的技术方案为:
[0010]
一种基于神经网络及运动信息的黑白视频着色方法,包括:将待着色黑白视频帧即目标黑白视频帧和参考视频帧输入至训练好的视频着色模型,从参考视频帧的亮度分量与目标黑白视频帧的亮度分量之间提取两者之间的运动信息,运动信息与所得到的参考帧之间亮度和色度的转换关系结合后,得到目标黑白视频帧之间的亮度和色度的转换关系,得到转换关系后作用于目标黑白视频帧上,就得到目标黑白视频帧的色度分量,即完成了黑白视频着色。
[0011]
根据本发明优选的,训练好的视频着色模型的训练过程如下:
[0012]
获取数据集,对数据集进行预处理,分割为训练集和测试集;
[0013]
构建视频着色模型,并将得到的训练集输入至视频着色模型进行训练,将测试集输入至训练好的黑白视频上色模型进行测试,得到训练好的视频着色模型。
[0014]
根据本发明优选的,视频着色模型包括运动信息提取网络、参考特征提取网络、着色网络;运动信息提取网络分别对黑白视频帧以及参考帧的亮度分量提取特征,将黑白视频帧的特征与参考帧的亮度分量的特征进行结合,获得参考帧与黑白视频帧之间的运动信息;
[0015]
参考特征提取网络提取参考帧中亮度分量与色度分量的特征,将提取到的特征和运动信息融合在一起,送入着色网络中;
[0016]
着色网络将提取到的特征和运动信息进行融合并将特征恢复到原尺寸,预测出待着色黑白视频帧的色度分量,即实现了对黑白视频帧的着色。
[0017]
根据本发明优选的,运动信息提取网络包括输入端特征提取模块、参考端亮度分量特征提取模块、源与参考注意力模块;通过输入端特征提取模块提取输入的待着色黑白视频帧的特征,通过参考端亮度分量特征提取模块提取参考帧亮度分量的特征,并通过源与参考注意力机制模块将待着色黑白视频帧的特征与参考帧亮度分量的特征进行融合,获取参考帧与黑白视频帧之间的运动信息。
[0018]
进一步优选的,输入端特征提取模块、参考端亮度分量特征提取模块均包括输入层、卷积层、bn层、激活函数层;
[0019]
卷积层用于对输入视频帧进行特征提取,得到视频帧的特征,并减小视频帧的特征的尺寸大小;bn层用于归一化;激活层用于实现视频帧的特征的非线性映射。
[0020]
进一步优选的,卷积层使用3d卷积,卷积核大小为1
×3×
3。
[0021]
进一步优选的,输入端特征提取模块如式(i)所示:
[0022]yin
=σ1(w1×yinput
)(i)
[0023]
式(i)中,w1表示权重,y
in
表示提取到的待上色黑白视频帧的特征,σ1表示激活函
数,w1通过反向传播更新,通过反向传播更新,表示输入的第i帧黑白视频帧,i表示输入黑白视频帧的帧数。
[0024]
进一步优选的,参考端亮度分量特征提取模块如式(ii)所示:
[0025]yref
=σ1(w2×yreference
)(ii)
[0026]
式(ii)中,w2表示权重,y
ref
表示提取到的参考帧的特征,σ1表示激活函数,w2通过反向传播更新,反向传播更新,表示输入的第x帧参考帧,x表示参考帧的帧数。
[0027]
根据本发明优选的,运动信息提取网络的最终输出如式(iii)所示:
[0028]
m=a1(y
in
,y
ref
)(iii)
[0029]
式(iii)中,m表示提取到的运动信息,a1(
·
,
·
)表示源与参考注意力模块。
[0030]
根据本发明优选的,参考特征提取网络包括输入层、卷积层、bn层、激活函数层;
[0031]
包括两条特征提取支路,第一条支路提取的是参考帧1/8原尺寸大小的特征,之后与运动信息通过源与参考注意力模块结合,第二条支路提取的是参考帧1/16原尺寸大小的特征,之后将运动信息进行一次下采样至与参考帧特征相匹配的尺寸,经过自注意力机制,注意力集中在更有效的信息上,第一条支路和第二条支路结合后得出参考帧提取网络的最终输出。
[0032]
进一步优选的,第一条支路如式(iv)所示:
[0033][0034]
式(iv)中,w3表示权重,表示提取到的参考帧1/8原尺寸大小的特征,σ1表示激活函数,w3通过反向传播更新,
[0035]
x表示参考帧的帧数,是指第x个参考帧;
[0036]
参考帧1/8原尺寸大小的特征与运动信息结合如式(v)所示:
[0037][0038]
式(v)中,a1表示第一条支路输出的特征,a1(
·
,
·
)表示源与参考注意力模块。
[0039]
进一步优选的,第二条支路如式(vi)所示:
[0040][0041]
式(vi)中,w4表示权重,表示提取到的参考帧1/16原尺寸大小的特征,σ1表示激活函数,w4通过反向传播更新;
[0042]
将运动信息进行一次下采样至与参考帧特征相匹配的尺寸如式(vii)所示:
[0043]mdown
=σ1(w5×
m)(vii)
[0044]
式(vii)中,w5表示权重,m
down
表示运动信息经过下采样至1/16尺寸的特征,σ1表示激活函数,w5通过反向传播更新;
[0045]
参考帧1/16原尺寸大小的特征与运动信息结合如式(viii)所示:
[0046]
[0047]
式(viii)中,b表示第二条支路提取到的特征,a1(
·
,
·
)表示源与参考注意力模块。
[0048]
第二条支路所提取到的特征通过自注意力机制后如式(ix)所示:
[0049]
a2=s1(b,b)(ix)
[0050]
式(ix)中,a2表示第二条支路输出的特征,s1(
·
,
·
)表示自注意力机制;
[0051]
第一条支路和第二条支路结合后得出参考帧提取网络的最终输出o(yuv
reference
),如式(x)所示:
[0052]
o(yuv
reference
)=a1+a2(x)。
[0053]
根据本发明优选的,着色网络包括上采样层、卷积层、bn层、激活函数层以及自注意力机制;
[0054]
上采样层将特征恢复到原视频帧尺寸,卷积层用于预测出黑白视频帧的色度分量;bn层用于归一化,加速训练过程;激活函数层用于实现特征的非线性映射;自注意力机制用于获取更有效的信息。
[0055]
根据本发明优选的,着色网络如式(xi)、式(xii)所示:
[0056]buv
=s1(o(yuv
reference
),o(yuv
reference
))(xi)
[0057]ouv
=σ1(w6×buv
)(xii)
[0058]
式(xi)、式(xii)中,w6表示权重,o(yuv
reference
)表示参考特征提取网络提取到的特征,σ1表示激活函数,w6通过反向传播更新,s1表示自注意力机制,o
uv
表示最终预测出的待着色黑白视频帧的色度分量,b
uv
表示特征通过自注意力模块后得到的带有权重的特征。o
uv
为通过着色网络后得到的目标色度分量。
[0059]
一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现基于神经网络及运动信息的黑白视频着色方法的步骤。
[0060]
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现基于神经网络及运动信息的黑白视频着色方法的步骤。
[0061]
本发明的有益效果是:
[0062]
本发明提出了一种基于卷积神经网络并结合自注意力机制和运动信息的视频着色方法,该方法将输入的黑白视频帧以及参考帧的亮度分量之间提取运动信息,能够帮助着色网络对运动物体的着色,同时使用多支路的特征提取,以获得细节方面更准确的着色效果,还使用自注意力机制以及源与参考注意力机制,以帮助网络获得更为有效的特征信息,提高着色的准确度。
附图说明
[0063]
图1为本发明基于卷积神经网络并结合自注意力机制和运动信息的视频着色方法的流程示意图;
[0064]
图2为本发明视频着色模型的网络结构示意图。
具体实施方式
[0065]
下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
[0066]
实施例1
[0067]
一种基于神经网络及运动信息的黑白视频着色方法,包括:将待着色黑白视频帧即目标黑白视频帧和参考视频帧输入至训练好的视频着色模型,从参考视频帧的亮度分量与目标黑白视频帧的亮度分量之间提取两者之间的运动信息,运动信息与所得到的参考帧之间亮度和色度的转换关系结合后,得到目标黑白视频帧之间的亮度和色度的转换关系,得到转换关系后作用于目标黑白视频帧上,就得到目标黑白视频帧的色度分量,即完成了黑白视频着色。
[0068]
视频中亮度分量与色度分量之间存在转换关系,由于参考视频帧中具备完整的亮度分量与色度分量,希望能从参考视频帧中拟合出亮度分量与色度分量之间的转换关系,但是由于参考视频帧与目标黑白视频帧之间不是完全相同的,所以参考帧与目标帧的转换关系也不是完全相同的,而这种不同往往是由于运动导致的。本发明从参考视频帧的亮度分量与目标黑白视频帧的亮度分量之间提取两者之间的运动信息,运动信息与所得到的参考帧之间亮度和色度的转换关系结合后,得到目标黑白视频帧之间的亮度和色度的转换关系,得到转换关系后作用于目标黑白视频帧上就能得到目标黑白视频帧的色度分量。原理用公式表示如下:
[0069]
f∶y
input
→uoutput
[0070]freference
∶y
reference
→ureference
[0071]
motion=m(y
input
,y
referemce
)
[0072][0073][0074]
其中,y
input
表示目标黑白视频帧的亮度分量,u
output
表示目标黑白视频帧的色度分量,f表示目标黑白视频帧亮度分量与色度分量之间的转换关系。y
reference
表示参考帧的亮度分量,u
reference
表示参考帧的色度分量,f
reference
表示参考帧亮度分量与色度分量之间的转换关系。motion表示视频帧中的运动信息,m(
·
,
·
)表示提取运动信息的操作。
[0075]
实施例2
[0076]
根据实施例1所述的一种基于神经网络及运动信息的黑白视频着色方法,其区别在于:
[0077]
训练好的视频着色模型的训练过程如下:
[0078]
获取数据集,对数据集进行预处理,分割为训练集和测试集;
[0079]
构建视频着色模型,并将得到的训练集输入至视频着色模型进行训练,将测试集输入至训练好的黑白视频上色模型进行测试,得到训练好的视频着色模型。训练好的视频着色模型的训练过程具体包括:
[0080]
将数据集大小缩放至256
×
256大小;去除色度分量后的灰度视频帧作为输入,参考帧为待着色视频帧所在视频的第一帧以及从数据集中随机选择1~5帧;采用端对端的训练方式,设置批处理大小为5,使用l1损失函数,在训练时,利用梯度下降对网络中的权重进行不断地更新优化,采用adadelta优化算法,可根据梯度自适应调整学习率,代替了手动更改学习率参数的过程。
[0081]
如图1所示,视频着色模型包括运动信息提取网络、参考特征提取网络、着色网络;如图2所示,运动信息提取网络通过卷积层分别对黑白视频帧以及参考帧的亮度分量提取
特征,其中目标黑白视频帧以及参考帧是多帧输入。在运动信息提取的过程中,特征的尺寸不断减小,以降低训练过程中所占有的内存。通过卷积层之后通过源与参考注意力机制将黑白视频帧的特征与参考帧的亮度分量的特征进行结合,获得参考帧与黑白视频帧之间的运动信息;
[0082]
参考特征提取网络通过卷积层提取参考帧中亮度分量与色度分量的特征,提取过程中分了两条支路,一条支路将参考特征缩小到原本尺寸大小的1/8,另一条支路将参考特征继续缩小至原本尺寸大小的1/16,之后通过源与参考注意力机制将提取到的特征和运动信息融合在一起,送入着色网络中;
[0083]
着色网络是由自注意力机制模块和卷积层组成,着色网络将提取到的特征和运动信息进行融合并将特征恢复到原尺寸,由于提取到的特征数量很多,自注意力机制能够帮助网络在众多特征中关注更为重要的信息,最终预测出待着色黑白视频帧的色度分量,即实现了对黑白视频帧的着色。
[0084]
运动信息提取网络包括输入端特征提取模块、参考端亮度分量特征提取模块、源与参考注意力模块;通过输入端特征提取模块提取输入的待着色黑白视频帧的特征,通过参考端亮度分量特征提取模块提取参考帧亮度分量的特征,并通过源与参考注意力机制模块将待着色黑白视频帧的特征与参考帧亮度分量的特征进行融合,获取参考帧与黑白视频帧之间的运动信息。
[0085]
输入端特征提取模块、参考端亮度分量特征提取模块均包括输入层、卷积层、bn(batch normalization)层、激活函数层;
[0086]
输入端特征提取模块的输入层用于输入黑白视频帧其中,t表示黑白视频帧y
input
的帧数,h表示黑白视频帧y
input
的长度,w表示黑白视频帧y
input
的宽度,1表示单通道(即灰度图)。卷积层用于对输入视频帧进行特征提取,得到视频帧的特征,并减小视频帧的特征的尺寸大小;能够适应不同的输入尺寸和帧数。卷积操作的关键是卷积核(kernel size)和步长(stride),本实施例中,由于输入是多帧,所以,卷积层使用3d卷积,卷积层的卷积核为1
×3×
3,步长为1
×1×
1或1
×2×
2,其中,步长1
×2×
2是为了减小特征的尺寸,小尺寸能够减轻网络计算的复杂度。
[0087]
类似的,参考端亮度分量特征提取模块的输入层用于输入参考视频帧参考端亮度分量特征提取模块的输入层用于输入参考视频帧其中,t表示参考视频帧y
reference
的帧数,h表示参考视频帧y
reference
的长度,w表示参考视频帧y
reference
的宽度,3表示3通道(即彩色图)。卷积层用于对所述参考视频帧的特征进行提取,得到参考视频帧的特征。具体的,卷积层进行卷积操作的主要目的是对参考视频帧的特征进行提取和映射。本实施例中,卷积层的卷积核为1
×3×
3,步长为1
×1×
1或1
×2×
2,其中,步长1
×2×
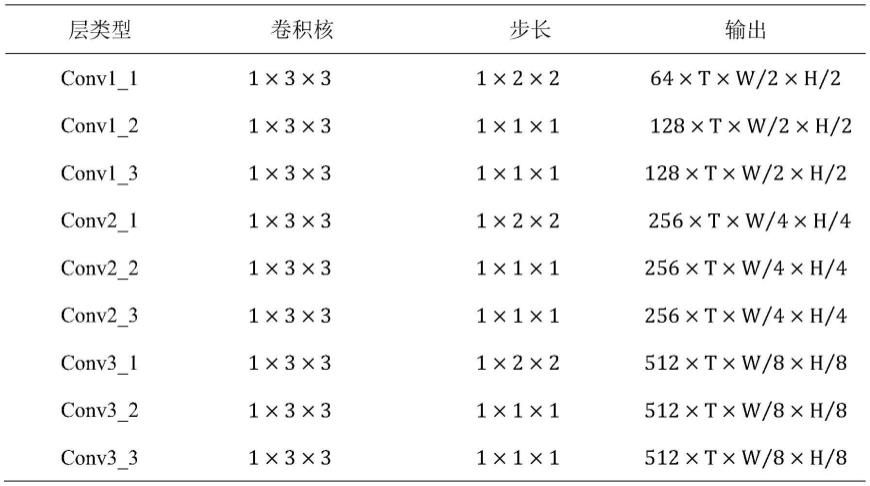
2是为了减小特征的尺寸。在本实施例中,采用8组卷积操作来提取黑白视频特征,参数细节设置如表1所示。
[0088]
表1
[0089][0090]
由于在神经网络训练过程中,训练数据和测试数据的分布不同会导致网络泛化性能下降,所以,为了增加网络的泛化性并提高训练速度,在特征提取网络中设置了bn层,bn层对特征做归一化处理,能防止梯度爆炸。
[0091]
激活层用于实现视频帧的特征的非线性映射。本实施例中采用elu函数作为激活函数:
[0092][0093]
elu函数可以将激活函数的输出均值向0靠近,使梯度更加接近于自然梯度,也提升了对噪声的鲁棒性。
[0094]
输入端特征提取模块如式(i)所示:
[0095]yin
=σ1(w1×yinput
)(i)
[0096]
式(i)中,w1表示权重,y
in
表示提取到的待上色黑白视频帧的特征,σ1表示激活函数,w1通过反向传播更新,w1是一个矩阵,一一对应每个输入特征,代表每个特征的重要程度,权重通过反向传播更新,在卷积层的训练过程中,梯度下降算法为了让损失函数的输出值更小,会逐步改变w1的值,从而逐步使得预测更加精准。从而逐步使得预测更加精准。表示输入的第i帧黑白视频帧,i表示输入黑白视频帧的帧数。
[0097]
参考端亮度分量特征提取模块如式(ii)所示:
[0098]yref
=σ1(w2×yreference
)(ii)
[0099]
式(ii)中,w2表示权重,y
ref
表示提取到的参考帧的特征,σ1表示激活函数,w2通过反向传播更新,反向传播更新,表示输入的第x帧参考帧,x表示参考帧的帧数。
[0100]
自注意力机制是注意力机制中的一种。源与参考注意力模块本质上与自注意力机制相同,不同在于自注意力机制的只有源特征一个输入,只关注自身内部的联系,源与参考注意力模块以两个特征作为输入,一个对应于源特征,另一个对应于参考特征,源与参考注意力模块能够挖掘源特征与参考特征之间的非局部相似性,让网络能够使用参考特征中与
源特征相似的区域作用于源特征。
[0101]
输入端亮度分量的特征和参考端亮度分量的特征通过源与参考注意力模块连接,用a
sr
(
·
,
·
)代表源与参考注意力操作,对于c
×
t
×h×
w的特征s和r来说,c代表通道数,t代表帧数,h和w分别代表长度和宽度。源与参考注意力机制用公式表示为:
[0102]asr
(s,r)=s+γd(e
t
(r)softmak(er(r)
tes
(s)))
[0103]
其中,γ是学习率,代表将特征映的维度减少,代表将特征映的维度减少,代表将特征的维度增加。
[0104]
用a1(
·
,
·
)表示源与参考注意力模块,则输入端亮度分量的特征与参考端亮度分量的特征通过源与参考注意力模块结合得到运动信息,运动信息提取网络的最终输出如式(iii)所示:
[0105]
m=a1(y
in
,y
ref
)(iii)
[0106]
式(iii)中,m表示提取到的运动信息,a1(
·
,
·
)表示源与参考注意力模块。
[0107]
参考特征提取网络包括输入层、卷积层、bn(batchnormalization)层、激活函数层;
[0108]
包括两条特征提取支路,第一条支路提取的是参考帧1/8原尺寸大小的特征,之后与运动信息通过源与参考注意力模块结合,第二条支路提取的是参考帧1/16原尺寸大小的特征,之后将运动信息进行一次下采样至与参考帧特征相匹配的尺寸,经过自注意力机制,注意力集中在更有效的信息上,通过源与参考注意力模块结合后,由于该条支路所提取到的特征比较多,所以在该条支路上加上了自注意力机制,有助于网络将注意力集中在更有效的信息上。运用两条支路并行提取特征的结构有助于利用参考帧的细节特征。参数细节如表2所示。
[0109]
表2
[0110][0111]
第一条支路和第二条支路结合后得出参考帧提取网络的最终输出。
[0112]
第一条支路如式(iv)所示:
[0113][0114]
式(iv)中,w3表示权重,表示提取到的参考帧1/8原尺寸大小的特征,σ1表示激活函数,w3通过反向传播更新,
[0115]
x表示参考帧的帧数,是指第x个参考帧;
[0116]
参考帧1/8原尺寸大小的特征与运动信息结合如式(v)所示:
[0117][0118]
式(v)中,a1表示第一条支路输出的特征,a1(
·
,
·
)表示源与参考注意力模块。
[0119]
第二条支路如式(vi)所示:
[0120][0121]
式(vi)中,w4表示权重,表示提取到的参考帧1/16原尺寸大小的特征,σ1表示激活函数,w4通过反向传播更新;
[0122]
将运动信息进行一次下采样至与参考帧特征相匹配的尺寸如式(vii)所示:
[0123]mdown
=σ1(w5×
m)(vii)
[0124]
式(vii)中,w5表示权重,m
down
表示运动信息经过下采样至1/16尺寸的特征,σ1表示激活函数,w5通过反向传播更新;
[0125]
参考帧1/16原尺寸大小的特征与运动信息结合如式(viii)所示:
[0126][0127]
式(viii)中,b表示第二条支路提取到的特征,a1(
·
,
·
)表示源与参考注意力模块。
[0128]
第二条支路所提取到的特征通过自注意力机制后如式(ix)所示:
[0129]
a2=s1(b,b)(ix)
[0130]
式(ix)中,a2表示第二条支路输出的特征,s1(
·
,
·
)表示自注意力机制;
[0131]
第一条支路和第二条支路结合后得出参考帧提取网络的最终输出o(yuv
reference
),如式(x)所示:
[0132]
o(yuv
reference
)=a1+a2(x)。
[0133]
着色网络包括上采样层、卷积层、bn(batchnormalization)层、激活函数层以及自注意力机制;
[0134]
上采样层使用三线性插值函数,将特征恢复到原视频帧的色度分量的尺寸大小,由于实例中所使用的是yuv4:2:0格式的视频帧,所以色度分量尺寸为输入亮度分量尺寸的一半。卷积层用于预测出黑白视频帧的色度分量。bn层用于归一化,加速训练过程。激活函数层用于实现特征的非线性映射。自注意力机制帮助网络获取更有效的信息。着色网络将输入特征预测为黑白视频的色度分量(uv分量),最终将分别与对应黑白视频帧结合生成多个彩色视频帧。在本实施例中,采用10组卷积操作来将黑白视频帧特征与参考彩色帧特征进行特征融合并最终预测出黑白视频帧的色度分量,参数细节设置如表3所示。
[0135]
表3
[0136][0137][0138]
着色网络如式(xi)、式(xii)所示:
[0139]buv
=s1(o(yuv
reference
),o(yuv
reference
))(xi)
[0140]ouv
=σ1(w6×buv
)(xii)
[0141]
式(xi)、式(xii)中,w6表示权重,o(yuv
reference
)表示参考特征提取网络提取到的特征,σ1表示激活函数,w6通过反向传播更新,s1表示自注意力机制,o
uv
表示最终预测出的待着色黑白视频帧的色度分量,b
uv
表示特征通过自注意力模块后得到的带有权重的特征。o
uv
为通过着色网络后得到的目标色度分量。
[0142]
视频着色模型的损失函数采用最小绝对值误差函数l1:
[0143][0144]
k,分别表示色度分量的真实值和网络输出的预测值。
[0145]
下面通过实验对本发明的效果进行说明。
[0146]
本实验采用youku-vesr和videvo两部分作为训练集。其中youku-vesr包括998个视频,每个视频都取前90帧,videvo是从videvo视频网站中选取50个视频,两部分都转为yuv4:2:0视频格式,总共1343个视频,119,527帧用于训练。测试集采用davis数据集和videvo视频网站中的自然属性分类中选取的30个视频。在实验过程中每次选取5个的连续视频帧的亮度分量作为输入,在训练过程中,选取5个视频帧作为参考,每个视频的第一帧真实值、当前帧的前一帧作为其中两个参考帧,剩下三个参考帧从数据集中随机选择。
[0147]
本发明黑白视频着色效果在视觉观察上合理,并且着色后的视频能保持很好的时间连续性和空间一致性,在运动物体上能保持更好的着色效果,减少了闪烁情况的出现。此外,将本发明的方法得到的结果和目前先进的视频着色方法相比较:iizuka等人的方法(zhang b,he m,j liao,et al.deep exemplar-based video colorization[c]//2019 ieee/cvf conference on computer vision and pattern recognition(cvpr).ieee,2019.)和zhang等人的方法(iizuka s,simo-serra e.deepremaster:temporal source-reference attention networks for comprehensive video enhancement[j].acm transactions on graphics,2019,38(6):176.1-176.13.)对比,测试时每次选取5个的连续视频帧的亮度分量作为输入,选取每个视频的第一帧真实值作为参考,在相同的条件下进行测试,结果显示,iizuka等人的方法和zhang等人的方法有背景模糊的问题,在长序列视频帧上会出现运动物体色彩丢失,而本发明的方法得到的着色结果在视觉上与真实值更接近,同时能够在长视频序列的运动物体上更好的保持着色效果,着色效果清晰没有模糊现象,色彩合理。
[0148]
本发明还使用定量指标psnr和ssim与其它方法进行比较,如表4所示:
[0149]
表4
[0150][0151]
表4中,zhang et al.是指zhang等人的方法,iizuka是指iizuka等人的方法;由表4可知,本发明的psnr和ssim结果优于其他两个方法。这也说明了本发明的着色效果更具有稳定性。
[0152]
实施例3
[0153]
一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现实施例1或2基于神经网络及运动信息的黑白视频着色方法的步骤。
[0154]
实施例4
[0155]
一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现实施例1或2基于神经网络及运动信息的黑白视频着色方法的步骤。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1