一种低资源场景下的文本生成方法、装置及系统
1.本发明涉及人工智能领域,主要涉及一种低资源场景下的文本生成方法、装置及系统。
背景技术:
2.随着互联网技术的发展,万维网上大量的文本信息飞速增长,在现有的信息爆炸的场景下,对于新闻等内容的阅读而言,亟需一种能够进行自动凝练并生成简单文本生成的方法,如自动生成标题,自动生成新闻的摘要或者自动生成新闻的时间线叙事文档。并且随着移动互联网设备的普及,移动设备端的屏幕也要求新闻的内容和展示以概要的形式呈现。自动文本生成方法是解决对海量新闻等大规模信息进行核心内容摘取与生成的唯一途径。
3.实现这一方法的传统模式是利用海量的人工标注数据训练文本生成模型,让训练好的模型去对新的新闻数据进行文本的自动生成。然而在现实的很多场景中,标注海量的目标文本数据需要大量的人力物力,耗时且低效。比如生成中文新闻标题的lcsts数据的标注规模达到210多万条,中文新闻摘要thucnews数据的标注规模达到83多万条。现有方法并未讨论在少标注样本低资源场景下如何训练一个文本生成模型。其次现有的预训练模型在文本生成任务上表现优异,但预训练模型由于本身海量的模型参数量,带来了较大的训练开销(比如gpu显存开销大,模型训练时间久)。如何降低模型训练的开销,在轻量级也是一个亟待解决的问题。本发明涉及一种低资源场景下的文本生成方法、装置及系统。适应于抽取式文本生成比如抽取关键词进行生成,还有生成式文本生成比如逐词生成目标文本需求。本发明利用了一致性半监督学习来解决少标注样本场景,可以将210万的lcsts中文新闻标题生成数据集的标注样本数量降低到10%,并保证其10%的有标签数据与大量无标签数据下的模型性能持平到50%左右的有标签数据的文本生成性能,本发明还利用了适配器微调的预训练参数冻结方法,如冻结预训练bert模型可以降低110m左右的参数不参与梯度反向计算,降低文本生成模型的训练开销。
技术实现要素:
4.针对目前文本生成方法低资源场景需求,本发明进行深入研究与实践,实现对少标注场景下的文本自动生成,极大地减少了文本生成方法对海量的人工标注数据的依赖,并且保持较好的文本生成性能。
5.为达到上述目的,本发明采用了下列技术方案,
6.包括三个步骤:
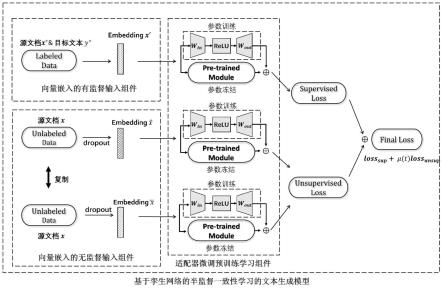
7.步骤一,为有监督网络输入少量的有监督训练样本,对应输入文档的嵌入向量,同时为无监督网络输入大量的无监督训练样本,即为开放式语料中获取的大量的不包含人工标注源文档数据,并对无监督文档复制两份,再分别对其对应的嵌入向量行了进行dropout,得到两组嵌入向量;
8.步骤二,为大型预训练文本生成网络(pre-trained model)并行集成适配器的小型神经模块(adapter),组成适配器微调预训练学习组件。在有监督网络t,和两个一致性的无监督网络a和b中,采用同样的网络架构的适配器微调预训练学习组件。在适配器微调预训练学习组件中,外加的小型适配器神经模块参与模型训练,而原来的大型的预训练文本生成模块需要保持参数冻结。具体而言,
9.其中,在有监督网络t中进行有监督训练,训练过程的输入为有监督源文档-目标文本对(x
*
,y
*
),在无监督网络a和b中进行所述的无监督一致性学习,训练过程的输入为x,a和b输出为其预测标签,一致性学习则是使得他们的预测标签一致。
10.其中,在基于适配器微调的预训练学习组件中,该网络的输入为嵌入向量为:h
input
,输出为对于有监督网络t,h
input
为x
*
的嵌入向量,对于无监督网络a,h
input
为x对应dropout的嵌入向量,对于无监督网络b,h
input
为x复制后进行另外一次dropout的嵌入向量。h
input
将同时输入到大型的预训练文本生成网络与小型的适配器网络中,在训练过程中该组件保持大型预训练文本生成模型部分的参数冻结,即参数不参与反向传播的参数学习与更新过程,只有小型的adapter网络的参数参与更新计算,从而达到降低模型训练开销的目的。
11.其中,在基于适配器微调的预训练学习组件中,采用的适配器小型神经网络(adapter),其前向部分的更新参数为w
in
,通过一个非线性激活函数relu函数对嵌入向量进行非线性优化,再输入适配器的后项部分,利用其更新参数w
out
对适配器进行训练,适配器的输出表示向量为
[0012][0013]
其中,在基于适配器微调的预训练学习组件中,结合大型预训练文本生成模型的输出与其线性相加后得到适配器微调预训练学习组件最后的输出表示向量
[0014][0015]
步骤三,基于无监督网络的一致性学习,并结合有监督网络的有监督学习进行文本生成模型的训练与优化。
[0016]
其中,无监督网络a和b,进行所述的无监督一致性学习,让两个所述无监督的预训练文本生成神经网络的预测目标一致,无监督损失函数为:
[0017][0018]
其中,sa和sb分别表示具体的无监督网络a与无监督网络b,是一对孪生网络,在抽取式文本生成中为bert并行集成adapter,在生成式文本生成中为bart并行集成adapter,xu为输入的无监督文本生成数据集,和表示经过增强数据增强后的输入值,在本发明中即为分别经过dropout后得到的两组不同的嵌入向量表示;
[0019]
同时,联合优化有监督网络的有监督学习,进行有监督文本生成模型的训练,有监督损失函数为;
[0020][0021]
其中,t(x
*
)表示有监督网络,与所述sa和sb的孪生网络,在抽取式文本生成中为bert并行集成adapter;在生成式文本生成中为bart并行集成adapter。x
l
为输入的有人工标注的文本生成数据集,x
*
和y
*
分别表示源文档和其对应的人工标注生成目标文本:
[0022]
最后,联合无监督网络的一致性学习与有监督网络的有监督学习,得到最终的损失函数l
final
,用于模型的训练与优化:
[0023]
l
final
(θ,x)=λl
unsup
(θ,xu)+l
sup
(θ,x
l
),x=xu+x
l
[0024][0025][0026][0027]
其中,λ为超参数,代表无监督一致性学习的训练部分在整个模型训练过程中的重要程度,θa为适配器的小型神经模块的参数,θb为大型预训练文本生成模型(bert或者bart)的参数,θ为整个模型的参数,m为epoch数;可见,在梯度反向计算时,θb在每个epoch没有跟更新即不参与梯度反向计算。而θa会随着训练过程在每个epoch里更新学习参数;
[0028]
最后利用优化好的模型进行文本生成预测。
[0029]
一种低资源场景下的文本生成装置,包括:
[0030]
源文档输入模块,用于输入少量的有标注源文档与文本生成的目标文本,以及输入大量的无标注的源文档;
[0031]
低资源场景下的文本生成模块,应用所述一种低资源场景下的文本生成方法;
[0032]
目标输出模块,将自动生成的目标文本通过接口程序输出。
[0033]
一种低资源场景下的文本生成系统,所述系统包括至少一台服务器,以及与服务器连接的低资源场景下的文本生成装置,所述服务器执行生成目标文本过程时,通过所述装置执行上述的低资源场景下的文本生成方法。
[0034]
本发明相对于现有技术的优点在于:
[0035]
1、本发明提出一套针对低资源场景下的文本生成方法,利用一致性学习,来提升无标注标签数据下的无监督学习的神经网络的鲁棒性,进而提升少标注样本下的整体网络的文本生成预测性能。极大地减少了文本自动生成方法对海量的人工标注数据的依赖,如针对210万的lcsts中文新闻标题生成数据集的标注样本数量降低到10%,并保证其10%的有标签数据与大量无标签数据下的模型性能持平到50%左右的有标签数据的文本生成性能。
[0036]
2、本发明利用基于适配器的预训练方法,将基于大型的预训练的文本生成神经网络的参数冻结,而更新小型的适配器神经网络模块模块,缓解模型训练的开销。如采用bert-base作为文本生成的模型基础框架需要110m参数量,这部分参数被冻结,不参与梯度反向计算时,可以很大程度降低模型计算效率。
附图说明
[0037]
图1为本发明的整体流程图(模型框架图);
具体实施方式
[0038]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0039]
本发明提出了一种低资源场景下的生成文本生成方法,针对目前文本生成方法少标注样本的场景需求,本发明进行深入研究与实践,实现对少标注样本场景下的源文本进行自动目标文本生成,极大地减少了文本生成方法对海量的人工标注数据的依赖。其次针对目前基于预训练的文本生成模型的训练开销大的问题,采用适配器预训练方法,降低训练开销。具体技术方案包括:
[0040]
步骤一,为有监督网络输入少量的有监督训练样本,即对应的源文的嵌入向量与生成目标文本标签,同时为无监督网络输入大量的无监督训练样本,并对无监督文档复制两份,再分别对其对应的嵌入行了进行dropout,得到两组嵌入向量;
[0041]
(1)从标注语料中摘取少量有人工标注的文本生成数据,即少量的源文档与对应的人工标注的目标文本;
[0042]
(2)从开放式语料中获取大量无监督的源文档数据,即大量的不包含人工标注的源文档;
[0043]
(3)复制同一无标签数据两份,再分别进行dropout得到两组嵌入向量表示;
[0044]
步骤二,为大型预训练文本生成网络(pre-trained model)并行集成适配器的小型神经模块(adapter),组成适配器微调预训练学习组件。在有监督网络t,和两个一致性的无监督网络a和b中,采用同样的网络架构的适配器微调预训练学习组件。在适配器微调预训练学习组件中,外加的小型适配器神经模块参与模型训练,而原来的大型的预训练文本生成模块需要保持参数冻结。具体而言,
[0045]
(1)输入为有监督源文档-目标文本对(x
*
,y
*
)到有监督网络,输入无监督文档x到无监督网络a和b中,a和b输出为其预测标签,一致性学习则是使得他们的预测标签一致。
[0046]
(2)在基于适配器微调的预训练学习组件中,输入嵌入向量为:h
input
,输出表示向量为对于有监督网络t,h
input
为x
*
的嵌入向量,对于无监督网络a,h
input
为x对应dropout的嵌入向量,对于无监督网络b,h
input
为x复制后进行另外一次dropout的嵌入向量。h
input
将被同时输入到大型的预训练文本生成网络与小型的适配器网络中,在训练过程中该组件保持大型预训练文本生成模型部分的参数冻结,即参数不参与反向传播的参数学习与更新过程,只有小型的adapter网络的参数参与更新计算,从而达到降低模型训练开销的目的。
[0047]
首先,在基于适配器微调的预训练学习组件中,采用的适配器小型神经网络(adapter),其前向部分的更新参数为w
in
,通过一个非线性激活函数relu函数对嵌入向量进行非线性优化,再输入适配器的后项部分,利用其更新参数w
out
对适配器进行训练,适配器
的输出表示向量为公式:
[0048]
其次,在基于适配器微调的预训练学习组件中,结合大型预训练文本生成模型的输出表示向量与其线性相加后得到适配器微调预训练学习组件最后的输出表示向量公式:
[0049]
步骤三,基于无监督网络的一致性学习,并结合有监督网络的有监督学习进行文本生成模型的训练与优化。
[0050]
(1)对于无监督网络a和b,进行所述的无监督一致性学习,让两个所述无监督的预训练文本生成神经网络的预测目标一致,优化损失函数为:
[0051]
公式:
[0052]
其中,sa和sb分别表示具体的无监督网络a与无监督网络b,是一对孪生网络,在抽取式文本生成中为bert并行集成adapter,在生成式文本生成中为bart并行集成adapter,xu为输入的无监督文本生成数据集,和表示经过增强数据增强后的输入值,在本发明中即为分别经过dropout后得到的两组不同的嵌入向量表示;
[0053]
(2)联合优化有监督网络的有监督学习,进行有监督文本生成模型的训练,优化损失函数为:
[0054]
公式:
[0055]
其中,t(x
*
)表示有监督网络,是所述无监督网络sa和sb的孪生网络,在抽取式文本生成中为bert并行集成adapter,在生成式文本生成中为bart并行集成adapter,x
l
为输入的有人工标注的源文档数据集,其中的x
*
和y
*
分别表示源文档和其对应的人工标注目标文档:
[0056]
(3)联合无监督网络的一致性学习与有监督网络的有监督学习,得到最终的损失函数l
final
,用于模型的训练与优化:
[0057]
公式:l
final
(θ,x)=λl
unsup
(θ,xu)+l
sup
(θ,x
l
),x=xu+x
l
[0058][0059][0060][0061]
其中,λ为超参数,代表无监督一致性学习的训练部分在整个模型训练过程中的重要程度,θa为适配器的小型神经模块(adapter)的参数,θb为大型预训练文本生成模块(bert或者bart)的参数,θ为整个模型的参数,m为epoch数;可见,在梯度反向计算时,θb在每个epoch一直不参与更新过程即不参与梯度反向计算。而θa会随着训练过程在每个epoch里更新学习参数。
[0062]
(4)最后利用优化好的模型进行文本生成预测。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1