一种基于深度学习的柔性压力传感阵列图的识别方法
1.本发明涉及图像识别技术领域,尤其是涉及一种基于深度学习的柔性压力传感阵列图的识别方法。
背景技术:
2.物体与物体间相互接触而产生的作用力在许多工业领域具有非常重要的作用。与一般类型的传感器不同的是,柔性压力传感阵列可以检测出柔性—柔性以及柔性—刚性相接触的作用力。柔性压力传感阵列不但拥有普通传感器的特点,而且具有轻薄、柔软、可弯曲等特点。柔性压力传感阵列可以在弯曲状态下检测出接触作用力的大小与分布信息,尤其是在一些曲面或者非平面形状的接触力检测中,具有较好的效果,并且已广泛应用在很多领域。
3.目前现有的柔性压力阵列信息的采集与检测方面的研究,大多是基于足底压力或者握力压力的,这种类型压力的信息数值一般较大,如果在感知、采集或者预测压力信息时存在误差,则误差对整体信息的处理影响不大,作用不明显。而服装对人体产生的压力属于微小的压力信息,也称为微力,因为服装和人体都是柔性体曲面,两个柔性体相互接触时,产生的是轻微的压力信息,这种类型的压力信息数值较小;在处理微小的压力信息的时候,感知、重构或者预测压力信息产生的误差,对整体信息的获取影响很大,作用非常明显,这就导致了柔性压力阵列处理人体服装这种数值微小的压力信息时,感知、重构和预测的难度远远高于足底或者握力这种数值较大的压力信息。
4.惠文珊等人(惠文珊,李会军,陈萌,等.基于cnn-lstm的机器人触觉识别与自适应抓取控制[j].仪器仪表学报,2019,40(1):211-218.)通过对深度学习算法的研究学习,提出了在基于触觉识别领域使用卷积神经网络和长短期记忆网络的融合模型进行分类。其方法的主要步骤如下:首先利用cnn模型对抓取时采集的触觉信息进行特征降维,然后通过lstm模型来捕获相应时间特征,最后使用softmax分类器完成对物体的识别工作。这种方法虽然能够通过机械手抓取物体并识别,但是存在识别准确率不高并且在样本差异较大时无法准确识别的缺陷,因此其泛化能力较差。
[0005]
所以,现有的关于柔性压力传感阵列图的识别方法存在一定的局限性,主要表现在:
[0006]
(1)、在训练过程中对物体进行识别时,如果样本之间的差异性较小,对物体的识别准确度将下降,泛化能力也较差;
[0007]
(2)、机械手抓取物体采用的方式不同和抓取的物体位置不同等问题都会对物体的识别结果产生影响,无法满足大多数的场景需求;
[0008]
(3)、在机械手抓取物体时,对于抓取物体的识别效率将影响其使用的场景,从而对其实用性带来影响。
技术实现要素:
[0009]
本发明所要解决的技术问题是提供一种识别准确度高、识别效率高、泛化能力强,并且能满足大量应用场景需求的基于深度学习的柔性压力传感阵列图的识别方法。
[0010]
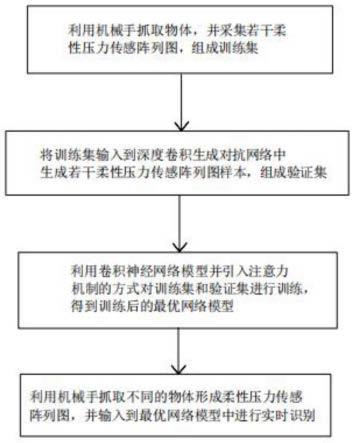
本发明所采用的技术方案是,一种基于深度学习的柔性压力传感阵列图的识别方法,该方法包括下列步骤:
[0011]
(1)、将柔性压力传感器贴合于机械手的各个关节点上,利用机械手抓取物体,并采集若干柔性压力传感阵列图,若干柔性压力传感阵列图组成训练集;
[0012]
(2)、根据步骤(1)得到的训练集,将训练集输入到深度卷积生成对抗网络中生成若干柔性压力传感阵列图样本,由若干柔性压力传感阵列图样本组成验证集;
[0013]
(3)、利用卷积神经网络模型并引入注意力机制的方式对步骤(1)中得到的训练集和步骤(2)中得到的验证集进行训练,得到训练后的最优网络模型;其具体过程为:
[0014]
(3-1)、采用vgg16网络模型和resnet152网络模型,将步骤(1)中形成的训练集分别输入到vgg16网络模型和resnet152网络模型中,对vgg16网络模型和resnet152网络模型进行预训练,得到预训练后的vgg16神经网络模型和预训练后的resnet152神经网络模型;
[0015]
(3-2)、将步骤(2)中的验证集分别导入到步骤(3-1)中得到的预训练后的vgg16神经网络模型和预训练后的resnet152神经网络模型中进行模型特征融合;
[0016]
(3-3)、经过特征融合后再引入注意力机制,得到引入注意力机制后的深度学习网络模型;
[0017]
(3-4)、将步骤(3-1)形成的训练集和步骤(3-2)形成的验证集均输入到步骤(3-3)中得到的引入注意力机制后的深度学习网络模型中进行训练,得到训练后的最优网络模型;
[0018]
(4)、利用机械手抓取不同的物体形成柔性压力传感阵列图,将形成的柔性压力传感阵列图输入到最优网络模型中进行实时识别。
[0019]
本发明的有益效果是:采用上述一种基于深度学习的柔性压力传感阵列图的识别方法,利用传感器贴合于机械手上的各个节点,使得机械手在抓取物体时能够触摸到物体的各个部位并得到有效的柔性压力传感阵列图,然后通过对卷积神经网络结构进行改进和引入注意力机制的方式对实时采集的柔性压力传感阵列进行识别,该方法提高了识别准确度以及识别效率高,并且泛化能力强,能满足大量应用场景需求,具有十分重要的意义和使用场景。
[0020]
作为优选,在步骤(1)中,利用机械手抓取物体,并采集若干柔性压力传感阵列图的具体过程为:选取若干类日常可见的物体,采用机械手对每一个物体进行抓取,针对同类物体,采用机械手抓取同类物体不同的部位,从而形成若干柔性压力传感阵列图。
[0021]
在步骤(1)中,在采集若干柔性压力传感阵列图之后,还包括:按照相同物体归属于同一类的方式对形成的柔性压力传感阵列图进行分类并打上标签,标签为各类物体的名称,带有标签的若干柔性压力传感阵列图组成训练集。
[0022]
作为优选,在步骤(2)中,在生成若干柔性压力传感阵列图样本之后,还包括:对已生成的若干柔性压力传感阵列图样本打上标签,标签为各类物体的名称,由若干打上标签的柔性压力传感阵列图样本组成验证集。
[0023]
作为优选,在步骤(2)中,所述深度卷积生成对抗网络包括生成器和判别器,利用
所述深度卷积生成对抗网络来生成若干柔性压力传感阵列图样本的具体方法包括下列步骤:
[0024]
(2-1)、将训练集中的若干柔性压力传感阵列图作为真实图像数据输入到生成器,生成器抓取若干柔性压力传感阵列图的特征分布;
[0025]
(2-2)、往生成器中添加噪声数据,生成器结合抓取到的特征分布来生成若干与真实图像数据对应的虚假图像数据;
[0026]
(2-3)、对真实图像数据进行采样,将采样到的柔性压力传感阵列图输入进判别器中,同时,对若干虚假图像数据进行采样,将采样到的虚假图像数据也输入进判别器中,判别器会对输入判别器的图片进行真假判断,即判断输入判别器的图片是真实图像数据还是虚假图像数据,生成器再根据判断结果来生成近似真实图像数据的虚假图像数据供判别器判断,直到当生成器生成的虚假图像数据被视为像来自于真实图像数据时,判别器判断数据为真的概率接近0.5为止。
[0027]
作为优选,在步骤(3)中,将形成的测试样本集输入到最优网络模型中进行识别时,当出现误识别的情况,那么就根据抓取物体的部位、抓取物体的动作和抓取物体的时间来判断是否存在区别于训练集中的柔性压力传感阵列图,如果存在,那么就对训练集进行拓展,再利用摄像机拍摄物体并通过目标检测的方式对拍摄的物体进行识别。
[0028]
作为优选,在步骤(3)中,利用摄像机拍摄物体并通过目标检测的方式对拍摄的物体进行识别的具体过程包括下列步骤:
[0029]
(3-11)、利用摄像机拍摄机械手抓取的物体,从而生成需要检测的目标图像;
[0030]
(3-12)、提取目标图像中的感兴趣区域,通过为每个像素分配不同尺寸的滑动窗口从而产生多个感兴趣区域;
[0031]
(3-13)、在步骤(3-12)中获得若干个感兴趣区域,利用cnn的分类回归方法区分这些感兴趣区域的正负样本,并提取特征;
[0032]
(3-14)、通过非极大值抑制的方法对提取的特征进行筛选重组,即根据步骤(3-13)的特征将步骤(3-12)获得感兴趣区域的数量减少到图片的真实目标的数目,所述的真实目标的数目为真实区域的目标总和,使得每个目标由单一的边界框住;
[0033]
(3-15)、利用svm分类器识别出机械手抓取物体的种类。
附图说明
[0034]
图1为本发明一种基于深度学习的柔性压力传感阵列图的识别方法的流程图;
[0035]
图2为本发明中利用深度卷积生成对抗网络生成若干柔性压力传感阵列图样本的流程图。
具体实施方式
[0036]
以下参照附图并结合具体实施方式来进一步描述发明,以令本领域技术人员参照说明书文字能够据以实施,本发明保护范围并不受限于该具体实施方式。
[0037]
本领域技术人员应理解的是,在本发明的公开中,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系是基于附图所示的方位或位置关系,其仅是为了便于描述本发明和简化描述,而不是指
示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此上述术语不能理解为对本发明的限制。
[0038]
本发明申请实施例涉及一种基于深度学习的柔性压力传感阵列图的识别方法,该方法包括下列步骤:
[0039]
(1)、将柔性压力传感器贴合于机械手的各个关节点上,随着机械手的相关动作,如握、抓、放和伸直等工作而不会影响传感器的脱落、松动等意外情况;选取了20类日常可见的物体,这些物体包括剪刀、杯子、手套、网球、手表等;利用机械手抓取物体,在抓取物体的过程中,针对同类物体,采用机械手抓取同类物体不同的部位,比如抓物体的头部、抓物体的中部、抓物体的尾部,形成多种不同姿势的柔性压力传感阵列图,采集到若干柔性压力传感阵列图,若干柔性压力传感阵列图组成训练集;
[0040]
(2)、根据步骤(1)得到的训练集,将训练集输入到深度卷积生成对抗网络中生成若干柔性压力传感阵列图样本,由若干柔性压力传感阵列图样本组成验证集;该步骤形成庞大的样本供后续步骤训练;
[0041]
(3)、利用卷积神经网络模型并引入注意力机制的方式对步骤(1)中得到的训练集和验证集进行训练,得到训练后的最优网络模型;其具体过程为:
[0042]
(3-1)、采用vgg16网络模型和resnet152网络模型,将步骤(1)中形成的训练集分别输入到vgg16网络模型和resnet152网络模型中,对vgg16网络模型和resnet152网络模型进行预训练,得到预训练后的vgg16神经网络模型和预训练后的resnet152神经网络模型;
[0043]
(3-2)、将步骤(2)中的验证集分别导入到步骤(3-1)中得到的预训练后的vgg16神经网络模型和预训练后的resnet152神经网络模型中进行模型特征融合,即将两个网络训练得到的特征进行拼接,通过预训练后的网络模型来探索柔性压力传感阵列分类的转移学习策略,此方法中的神经元信息可以替换最终的分类器层,并保留相同的条件;此方法中的激活函数为sigmoid函数,为了防止训练过拟合的现象,添加bn层,设置dropout为0.5;
[0044]
(3-3)、经过特征融合后再引入注意力机制,得到引入注意力机制后的深度学习网络模型;在网络模型的特征融合之后对网络进行微调并引入注意力机制,通过注意力机制可以为图像特征添加一定的权重信息,从而在图像识别的过程中能更好的为图像所处特征加以识别,提高图像识别的准确率;
[0045]
(3-4)、将步骤(1)形成的训练集和步骤(2)形成的验证集均输入到步骤(3-3)中得到的引入注意力机制后的深度学习网络模型中进行训练,在训练过程中可以根据迭代次数和每一代的识别效果为模型的参数进行调整,例如激活函数、dropout、卷积层层数、迭代数目和样本数量等问题,得到训练后的最优网络模型;
[0046]
(3-5)、利用机械手抓取不同的物体形成柔性压力传感阵列图,将形成的柔性压力传感阵列图输入到最优网络模型中进行实时识别。
[0047]
采用上述一种基于深度学习的柔性压力传感阵列图的识别方法,利用传感器贴合于机械手上的各个节点,使得机械手在抓取物体时能够触摸到物体的各个部位并得到有效的柔性压力传感阵列图,然后通过对卷积神经网络结构进行改进和引入注意力机制的方式对实时采集的柔性压力传感阵列进行识别,该方法提高了识别准确度以及识别效率高,并且泛化能力强,能满足大量应用场景需求,具有十分重要的意义和使用场景。
[0048]
在步骤(1)中,在采集若干柔性压力传感阵列图之后,还包括:按照相同物体归属
于同一类的方式对形成的柔性压力传感阵列图进行分类并打上标签,标签为各类物体的名称,带有标签的若干柔性压力传感阵列图组成训练集。
[0049]
在步骤(2)中,在生成若干柔性压力传感阵列图样本之后,还包括:对已生成的若干柔性压力传感阵列图样本打上标签,标签为各类物体的名称,由若干打上标签的柔性压力传感阵列图样本组成验证集。
[0050]
在步骤(2)中,所述深度卷积生成对抗网络包括生成器和判别器,利用所述深度卷积生成对抗网络来生成若干柔性压力传感阵列图样本的具体方法包括下列步骤:
[0051]
(2-1)、将训练集中的若干柔性压力传感阵列图作为真实图像数据输入到生成器,生成器抓取若干柔性压力传感阵列图的特征分布;
[0052]
(2-2)、往生成器中添加噪声数据,生成器结合抓取到的特征分布来生成若干与真实图像数据对应的虚假图像数据;
[0053]
(2-3)、对真实图像数据进行采样,将采样到的柔性压力传感阵列图输入进判别器中,同时,对若干虚假图像数据进行采样,将采样到的虚假图像数据也输入进判别器中,判别器会对输入判别器的图片进行真假判断,即判断输入判别器的图片是真实图像数据还是虚假图像数据,生成器再根据判断结果来生成近似真实图像数据的虚假图像数据供判别器判断,直到当生成器生成的虚假图像数据被视为像来自于真实图像数据时,判别器判断数据为真的概率接近0.5为止。
[0054]
在步骤(3)中,将形成的测试样本集输入到最优网络模型中进行识别时,当出现误识别的情况,那么就根据抓取物体的部位、抓取物体的动作和抓取物体的时间来判断是否存在区别于训练集中的柔性压力传感阵列图,如果存在,那么就对训练集进行拓展,再利用摄像机拍摄物体并通过目标检测的方式对拍摄的物体进行识别。
[0055]
在步骤(3)中,利用摄像机拍摄物体并通过目标检测的方式对拍摄的物体进行识别的具体过程包括下列步骤:
[0056]
(3-11)、利用摄像机拍摄机械手抓取的物体,从而生成需要检测的目标图像;
[0057]
(3-12)、提取目标图像中的感兴趣区域,通过为每个像素分配不同尺寸的滑动窗口从而产生多个感兴趣区域;
[0058]
(3-13)、在步骤(3-12)中获得若干个感兴趣区域,利用cnn的分类回归方法区分这些感兴趣区域的正负样本,并提取特征;
[0059]
(3-14)、通过非极大值抑制的方法对提取的特征进行筛选重组,即根据步骤(3-13)的特征将步骤(3-12)获得感兴趣区域的数量减少到图片在真实目标的数目,所述的真实目标数目为训练集中真实区域的目标总和,使得每个目标由单一的边界框住;
[0060]
(3-15)、利用svm分类器识别识别出机械手抓取物体的种类。
[0061]
在步骤(2)中,所述的深度卷积生成对抗网络,英文名称为:deep convolution generative adversarial networks,简称dcgan,dcgan是将cnn和gan相结合的网络,其中gan是一个深度学习模型历来捕获训练数据的布局的框架。dcgan技术主要包括两个部分,即生成器(generator)和判别器(discriminator)。生成器表示生成类似预训练的数据,它通过接收一个随机噪声来生成图片;判别器的工作是判断一个图片是真实的训练数据还是生成器生成的虚假数据。在训练过程中生成器会不断的尝试生成越来越好的假数据来蒙混判别器,同样地判别器也会不断的提升判别的能力,而这是一个博弈的过程,其平衡点是当
生成器生成的虚假数据被视为像来自于训练集数据时,判别器判断数据为真的概率基本接近0.5。
[0062]
假设输入一张图片,设置其图像的数据特征为x,d(x)表示通过判别器输出的判断x是来自真实训练数据的可能性,即当x来自真实训练集时,该值就会偏大,当x来自于生成器生成的虚假数据时,该值就会偏小,即可以视为一个二分类问题;z表示从标准的正态分布中抽样的隐向量空间,g(z)表示生成器从隐向量空间z映射到数据空间的函数,表示生成的虚假数据样本的分布情况;d(g(z))是判断生成器g的输出是一个真实图像的概率,生成样本的结构图示如图2所示,其损失函数的计算公式如下:
[0063]
mingmaxdv(d,g)=e
x~pdata(x)
[logd(x)]+e
z~pz(z)
[log(1-d(g(z)))];通过上述方式可以获得所需的样本数据集,便于后续的模型训练过程。
[0064]
在步骤(3-1)中,vgg16网络模型由13层卷积层和3层全连接层组成,卷积表示的是使用一个卷积核,在每层像素矩阵上不断按步长扫描下去,每次扫到的数值会和卷积核上对应位置的数进行相乘,然后相加求和从而得到新的矩阵。卷积核相当于卷积操作的一个过滤器,用于对图像的特征进行提取,在特征提取完成之后将会得到特征图,一般卷积核采用的是3
×
3和5
×
5,其中卷积核中的每一个值为训练模型过程中的神经元参数,在预训练之前卷积核中的数字均为随机的初始值,在模型的训练过程中网络会通过后向传播的方式不断更新参数值,直到最佳的结果。全连接层是相当于对最后一层的节点数据输出,而最后一层的节点值均来源于前一层节点经过激活函数进行加权求得的。同样地,resnet152表示的是由152层网络组成的神经网络模型。
[0065]
在步骤(3-1)中,针对resnet152模型,如果设置输入为x,学习到的特征为h(x),则残差单元就可以表示为:yj=h(xj)+f(xj,wj);相应学习到的特征就可以表示为:
[0066][0067]
将最优网络模型应用到机械手的实时抓取过程中,需要在检测到机械手在抓取物体形成柔性压力图之后再对图像进行识别,并验证识别的结果与识别物体是否存在差异以及花费的时间和相关评价指标的结果,用到的准确度和损失函数的计算公式分别如下:其中,m表示的是样本数量,a表示神经元经过函数的非线性输出,i表示条件判断函数,f(xi)为模型的预测结果。
[0068]
将最优网络模型应用到机械手上,即机械手的抓取并生成柔性压力传感阵列图和对图像的识别属于一个流程中,先通过机械手抓取物体,在机械手的抓取过程中会生成抓取物体的柔性压力传感阵列图,将该柔性压力传感阵列图送入到训练好的最优网络模型中进行测试,通过人工的方式判别识别物体的准确度,即进一步验证本发明的算法模型识别的准确度,在测试的过程中可以进一步判断识别物体花费的时间,从而为实时识别提供支撑。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1