一种用于3D场景理解的点云多模态特征融合网络方法
一种用于3d场景理解的点云多模态特征融合网络方法
技术领域
1.本发明属于人工智能领域,涉及一种用于3d场景理解的点云多模态特征融合网络方法。
背景技术:
2.近些年来,语义分割和场景理解在自动驾驶、无人机、定位与建图(slam)、机器人等相关的人工智能领域得到广泛的应用。同时,3d点云数据正在迅速增长,无论是源于cad模型还是来自lidar传感器或rgbd相机的扫描点云,无处不在。 另外,大多数系统直接获取3d点云而不是拍摄图像并进行处理。因此,点云的场景理解逐步变得至关重要。然而,由于实际环境的复杂性和深度图像的不准确性,点云数据的场景理解仍然存在许多挑战。点云的模型可以初步提取全局特征和部分局部特征,而二维图像可以很好的提取多尺度的不同视图中的特征。图像作为点云的二维表现形式,因此,采用一种新颖的互补的特征融合方式至关重要。
3.
技术实现要素:
由于利用图像相关信息可以帮助提升点云语义分割精度与效果,目前的大多数的语义分割方法都使用了图像进行提取特征或有监督训练。
4.本方法提出了一种用于3d场景理解的点云多模态特征融合网络方法,旨在处理点云特征和图像特征的多模态融合进行监督训练,最终得到一个精度更高且更加鲁棒的点云语义分割模型。
5.本发明提出一种用于3d场景理解的点云多模态特征融合网络方法,包括以下步骤:步骤1:收集现有的点云数据集,其中数据集包括s3dis数据集和modelnet40数据集,数据集中的数据包括含颜色信息的点云数据;步骤2:根据点云数据从前视图、后视图、顶视图、底视图、右侧视图、左侧视图生成其对应的多视图的点云投影图像和点频图像;步骤3:使用pointnet++提取点云的全局特征和部分局部特征;步骤4:使用vgg16分别提取不同的视图图像特征并聚合成一个全局特征;步骤5:将点云分支和图像分支的特征进行拼接合并;步骤6:将拼接后的特征通过两个1x1的卷积层融合点云特征和图像特征;步骤7:将步骤6得到的融合特征和拼接特征进行逐位加操作;步骤8:将图像特征和步骤7得到的特征进行拼接合并;步骤9:重复步骤6、7、8两次后得到最后的融合特征;步骤10:对于步骤9输出的特征使用语义分割网络预测点云语义信息,使用标注信息进行监督训练;步骤11:对于步骤9输出的特征使用分类预测点云类别信息,使用标注信息进行监督训练;
步骤12:显示点云的3d场景理解效果图。
6.进一步地,步骤1包括如下步骤:步骤1-1:下载现有的s3dis数据集和modelnet40数据集;步骤1-2:处理获取点云数据。
7.进一步地,步骤2包括如下步骤:步骤2-1:从前视图、后视图、顶视图、底视图、右侧视图、左侧视图分别投影点云数据;步骤2-2:生成其对应的多视图图像。
8.进一步地,步骤3包括以下步骤:步骤3-1:构造pointnet++图像特征提取网络并输入原始点云数据提取点云特征,并加载在预训练模型参数;步骤3-2:pointnet++网络首部主要分为sample&grouping和pointnet组成的set abstraction对点云进行局部的全局特征提取。
9.进一步地,步骤4包括以下步骤:步骤4-1:构造vgg16图像特征提取网络并加载在预训练模型参数,输入不同的视图图像提取特征;步骤4-2:vgg16网络首部由连续2次的两个3x3的卷积层一个2x2的池化层,在加上连续三次的两个3x3的卷积层、一个1x1的卷积层和一个2x2的池化层组成。
10.进一步地,步骤5方法如下:将点云分支得到的点云特征和投影视图的rgb图像和点频图像的特征进行拼接合并。
11.进一步地,步骤6方法包括:将拼接点云特征和图像特征通过两个1x1的卷积层进行融合,再通过relu激活层。
12.进一步地,步骤7方法包括以下步骤:将融合特征和拼接得到的特征进行逐位加操作。
13.进一步地,步骤8方法包括:再将图像特征和步骤7得到的特征进行拼接合并。
14.进一步地,步骤9方法如下:在重复步骤6、步骤7和步骤8两次后,经过1x1的卷积层改变通道数深度融合了二维图像和三维点云的特诊。
15.进一步地,步骤10方法包含:将步骤9得到的特征使用语义分割网络预测点云的语义信息,使用标注信息进行监督训练。
16.进一步地,步骤11方法如下:步骤11-1:将步骤9得到的特征使用分类网络预测点云的类别信息,使用标注信息进行监督训练;步骤11-2:分类网络由若各干个全连接层组成。
17.进一步地,步骤12方法如下:最后将得到的点云语义分割和语义类别进行显示。
18.本发明的有益效果:探索了室内场景下多任务之间的关联性和互补性;提出一种3d场景理解的点云多模态特征融合网络方法,可以处理融合点云特征和图像特征并互补语义信息进行监督训练;最终可以得到一个精度更高且更加鲁棒的点云语义分割模型,可用于绝大多数的室内场景理解任务中。
19.本方法在室内场景理解任务上取得了极高的精度,而且适用性广泛,可适配多种不同任务组合。
20.附图说明:下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述或其他方面的优点将会变得更加清楚。
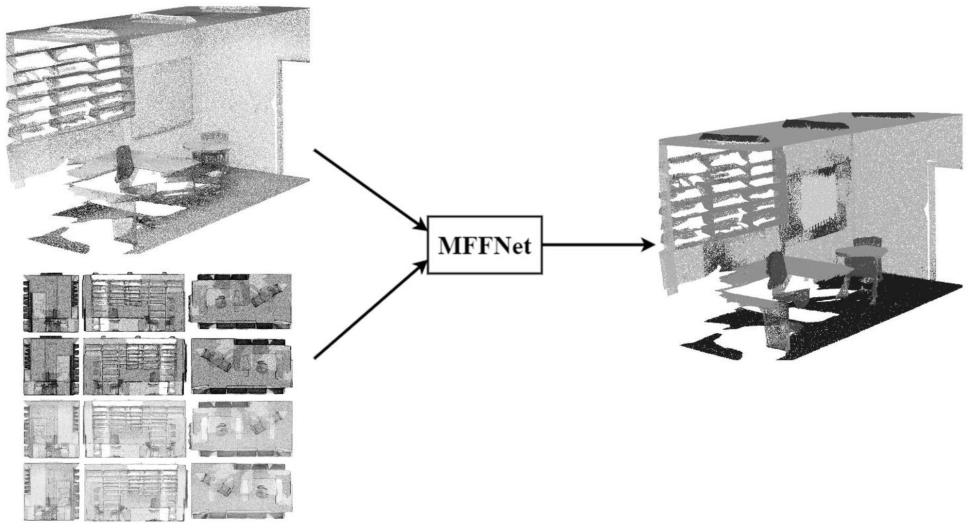
21.图1为本算法的整体流程图,对应步骤3到步骤11;图2为3d场景理解的点云多模态特征融合网络方法框架图;图3为最终的语义分割效果示意图。
22.具体实施方式:下面将结合附图和实施例对本发明作详细说明。
23.本算法总体包括以下步骤:如图1-2所示,一种用于3d场景理解的点云多模态特征融合网络方法,包括以下步骤:步骤1:收集现有的点云数据集,其中数据集包括s3dis数据集和modelnet40数据集,数据集中的数据包括含颜色信息的点云数据;步骤2:根据点云数据从前视图、后视图、顶视图、底视图、右侧视图、左侧视图生成其对应的多视图的点云投影图像和点频图像;步骤3:使用pointnet++提取点云的全局特征和部分局部特征;步骤4:使用vgg16分别提取不同的视图图像特征并聚合成一个全局特征;步骤5:将点云分支和图像分支的特征进行拼接合并;步骤6:将拼接后的特征通过两个1x1的卷积层融合点云特征和图像特征;步骤7:将步骤6得到的融合特征和拼接特征进行逐位加操作;步骤8:将图像特征和步骤7得到的特征进行拼接合并;步骤9:重复步骤6、7、8两次后得到最后的融合特征;步骤10:对于步骤9输出的特征使用语义分割网络预测点云语义信息,使用标注信息进行监督训练;步骤11:对于步骤9输出的特征使用分类预测点云类别信息,使用标注信息进行监督训练;步骤12:显示点云的3d场景理解效果图。
24.进一步地,步骤1包括如下步骤:步骤1-1:下载现有的s3dis数据集和modelnet40数据集;步骤1-2:处理获取点云数据。
25.进一步地,步骤2包括如下步骤:步骤2-1:从前视图、后视图、顶视图、底视图、右侧视图、左侧视图分别投影点云数
据;步骤2-2:生成其对应的多视图图像。
26.进一步地,步骤3包括以下步骤:步骤3-1:构造pointnet++图像特征提取网络并输入原始点云数据提取点云特征,并加载在预训练模型参数;步骤3-2:pointnet++网络首部主要分为sample&grouping和pointnet组成的set abstraction对点云进行局部的全局特征提取。
27.进一步地,步骤4包括以下步骤:步骤4-1:构造vgg16图像特征提取网络并加载在预训练模型参数,输入不同的视图图像提取特征;步骤4-2:vgg16网络首部由连续2次的两个3x3的卷积层一个2x2的池化层,在加上连续三次的两个3x3的卷积层、一个1x1的卷积层和一个2x2的池化层组成。
28.进一步地,步骤5方法如下:将点云分支得到的点云特征和投影视图的rgb图像和点频图像的特征进行拼接合并。
29.进一步地,步骤6方法包括:将拼接点云特征和图像特征通过两个1x1的卷积层进行融合,再通过relu激活层。
30.进一步地,步骤7方法包括以下步骤:将融合特征和拼接得到的特征进行逐位加操作。
31.进一步地,步骤8方法包括:再将图像特征和步骤7得到的特征进行拼接合并。
32.进一步地,步骤9方法如下:在重复步骤6、步骤7和步骤8两次后,经过1x1的卷积层改变通道数深度融合了二维图像和三维点云的特诊。
33.进一步地,步骤10方法包含:将步骤9得到的特征使用语义分割网络预测点云的语义信息,使用标注信息进行监督训练。
34.进一步地,步骤11方法如下:步骤11-1:将步骤9得到的特征使用分类网络预测点云的类别信息,使用标注信息进行监督训练;步骤11-2:分类网络由若各干个全连接层组成。
35.进一步地,步骤12方法如下:最后将得到的点云语义分割和语义类别进行显示。
36.图3为最终的语义分割效果示意图,左边一列代表原始点云,中间一列代表语义分割的真实值,右边一列为我们的最终语义分割效果。
37.本发明具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1