基于日志的面向回归测试的黑盒测试用例排序方法与流程
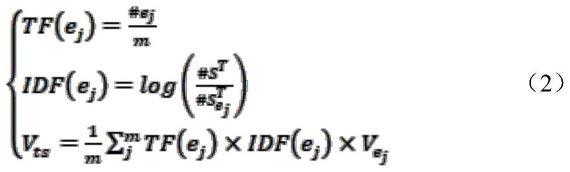
1.本发明涉及软件测试领域,特别是涉及一种测试用例排序方法。
背景技术:
2.关于回归测试:回归测试是将已有的测试用例应用在更改后的代码上,从而保证代 码的更改并不影响原功能的实现。为了保证整个系统的质量,在实际应用中通常执行全 部的测试用例。但是,当被测系统复杂而庞大时,回归测试的测试用例数目繁多,执行 过程耗时。因此,为了尽早地暴露出更多的缺陷,研究人员进行了各种探索,比如:根 据代码的变化选择相关的测试用例、测试用例最小化、测试用例排序、通过已有的测试 用例生成新测试用例等技术。其中,测试用例排序方法会保留原有的测试用例,因此成 为最主流的方法。
3.关于测试用例排序:测试用例排序旨在通过改变测试用例的执行顺序,尽早地发现 出更多的软件缺陷。测试用例排序的方法根据是否已知被测系统的源代码以及相关的信 息,分为白盒与黑盒两个大类:
4.1)白盒的测试用例排序方法:测试人员对被测系统的源代码进行静态或动态的分 析。在众多白盒测试用例排序方法中,基于覆盖的方法最为主流,测试人员利用测试用 例覆盖的具体路径范围实现排序。基于覆盖的白盒测试用例排序按照覆盖的粒度可分为 以下三种:基于语句覆盖的测试用例排序、基于条件覆盖的测试用例排序以及基于方法 覆盖的测试用例排序。其中,基于语句的测试用例排序方法的粒度最细,因此成为三者 中最主流的白盒测试用例排序方法。另外,基于覆盖的白盒测试用例排序方法常常通过 贪婪算法,使用动态的覆盖信息进行排序,分为全局的测试用例排序和增量的测试用例 排序。其中,全局的测试用例排序方法旨在按照测试用例的覆盖对象的数量由多到少排 序,而增量的测试用例排序方法旨在按照未被覆盖的对象的数量对测试用例进行排序。 另外,一些方法把在执行测试用例后才能获取的信息考虑进来,以助力测试用例排序, 例如测试用例的执行成本、发现的故障的级别等等。尽管这类白盒方法可以直接获得内 部的代码逻辑并达到很好的效果,但是它们的实现代价相当昂贵。通常,测试人员通过 源代码插桩的方式获得测试覆盖信息,即解析源代码的语法结构后,插入特定代码,运 行测试用例,最后对得到的测试结果进行分析,得到测试覆盖信息。这一获取动态信息 的过程工作量巨大,因此目前主流的研究方向是从静态信息入手,对白盒测试用例排序 方法进行更多的探索,比如通过被测代码的调用关系来模拟测试用例的覆盖信息。但实 际上,在工业实践中受限于测试规模和有限的资源,因此白盒测试并不实用。
5.2)黑盒的测试用例排序方法:测试人员无需已知被测代码,仅仅通过测试用例的 输入输出或者测试用例的代码进行排序。经过不断探索,研究人员发现:相似的测试用 例能发现相似的故障。因此,在黑盒测试用例排序中,通常利用测试用例的相似性使测 试用例的多样性最大化。比如,基于主题的测试用例排序方法利用测试代码中的语言信 息进行主题建模,为每个测试用例生成一个基于主题的向量,并通过每次找到与已排序 的测试用
例的平均欧氏距离最大的一个测试用例,最终得到测试用例排序结果。另外, 基于字符串的编辑距离的测试用例排序方法则是将测试代码视为字符串,并得到每两个 测试用例之间的文本欧氏距离,在每次迭代时选择与已排序的测试用例集具有最大欧氏 距离的测试用例,使多样性最大化。还有一些黑盒的测试用例排序方法需要利用需求文 档、代码更改等信息进行辅助,而在实际应用场景中,测试人员通常难以获得这些信息, 所以这类方法并没有成为主流的黑盒测试用例排序方法。另外,由于黑盒测试用例排序 方法没有接触到被测代码内部逻辑,因此黑盒方法通常不如白盒有效。但是,由于黑盒 的方法摆脱了深入理解待测程序源代码的限制,因此它在实际生产生活中得到非常广泛 的应用。
6.为了弥合黑盒与白盒两种测试用例排序之间的差距,需要借助其他的信息构建测试 用例,这些信息应具有以下两点特征:
7.特征一、尽可能多地包含程序源代码的相关信息,如代码位置、执行顺序和执行逻 辑等;
8.特征二、获取难度较低,相对容易理解,并且能够使用自动化的手段进行分析。
9.而系统日志恰恰符合上述两点条件:日志记录了系统运行信息,易于获取与理解, 因此日志被广泛用于各种可靠性保证任务。
10.系统在运行时通常会产生大量日志信息,日志通常由代码中的日志生成语句输出得 到,如print()和logger.info()。生成的日志通常包含时间戳、日志级别(即info、 debug、warning、error等)、日志内容等运行信息。其中,日志内容包含模板 和参数两部分,日志模板为固定的文本,用来描述系统运行状态,也称为日志事件;而 日志参数是向模板里添加的实时内容,比如内存使用量、进程的id和网络速度等信息。 开发人员可以自行设置日志模板和日志参数,并通过输出的日志得知系统当时的状态与 活动,例如系统当时正在调用某个进程、从某个ip地址接收到某段数据包、与某个数 据库进行某种交互等等。因此,日志被广泛应用于众多可靠性保证任务中,比如:通过 检查日志理解系统的运行状态、检测系统异常和定位系统故障的根因。
11.由于在回归测试中需要把已执行过的测试用例应用在更改后的代码上重新测试,因 此可以获得之前执行测试用例时产生的日志。因此,如何利用日志信息弥合黑盒与白盒 两种测试用例排序之间的差距、进而提高测试用例排序方法的效果,是本发明亟待解决 的技术问题。
技术实现要素:
12.本发明旨在弥合黑盒与白盒两种测试用例排序之间的差距,而提出一种基于日志的 面向回归测试的黑盒测试用例排序方法,通过分析测试用例生成的日志,充分利用日志 丰富的自然语言语义信息以及输出日志的语句在源代码中的位置信息,实现了在回归测 试中辅助黑盒测试用例排序。
13.本发明利用以下技术方案实现:
14.一种基于日志的面向回归测试的黑盒测试用例排序方法,该方法具体包括以下步 骤:
15.步骤1、进行日志解析,即在收集测试用例生成的日志内容后,通过日志解析得到 每个测试用例在系统执行过程所对应的日志事件序列;
而得到应该从未排序的测试用例中选择放入已排序测试用例的序列中的第next_index 个测试用例,即得到已排序的测试用例集合具有最大欧氏距离的测试用例为 ts
next_index
,如公式(4)所示:
[0029][0030]
其中,d(x)表示未排序的测试用例ts
x
与已排序测试用例的最小欧氏距离, 表示求在1≤x≤f范围内使d(x)值最大的x;
[0031]
重复步骤3,每次从未排序的测试用例中选择一个测试用例加入排序结果序列,直 到所有测试用例都被排序完,得到基于日志事件的自适应测试用例排序的排序结果 r
event
。
[0032]
与现有技术相比,本发明能够达成以下有益的技术效果:
[0033]
1)充分利用日志丰富的自然语言语义信息以及输出日志的语句在源代码中的位置 信息,提升黑盒测试用例排序方法的排序效果,弥补传统黑盒测试用例排序方法无法获 得被测系统内部信息的不足,缩小黑盒与白盒两种测试用例排序之间的差距;
[0034]
2)适用性广泛,可应用于所有能产生日志的被测系统,特别适用于测试人员无法 获得被测系统源码以及测试用例源码的情况,提升传统黑盒测试用例排序方法的健壮 性。
附图说明
[0035]
图1为本发明的一种基于日志的面向回归测试的黑盒测试用例排序方法整体流程 图;
[0036]
图2为日志信息示例图;
[0037]
图3为经过日志解析得到的日志事件示例图;
[0038]
图4为本发明的一种基于日志的面向回归测试的黑盒测试用例排序方法的具体实 施过程示意图。
具体实施方式
[0039]
以下结合附图和具体实施例对本发明的技术方案进行详细说明。
[0040]
本发明的基于日志的面向回归测试的黑盒测试用例排序方法采用python语言实现, 主要步骤包括:1)将日志进行解析,得到测试用例的日志事件2)将测试用例的日志 事件数据进行向量化处理;3)基于日志事件进行自适应测试用例排序。
[0041]
如图1所示,为本发明的一种基于日志的面向回归测试的黑盒测试用例排序方法的 整体流程图,该流程具体包括以下步骤:
[0042]
步骤1、进行日志解析,即在收集测试用例生成的日志内容后,通过日志解析提取 出去除参数后的日志模板作为日志事件;具体操作过程为:采用日志解析工具drain, 利用固定深度的解析树,通过设计多个解析规则指导日志解析;每个测试用例都生成一 系列日志信息,从日志信息中提取日志模板,通过日志解析得到每个测试用例在系统执 行过程所对应的日志事件序列;
[0043]
如图2所示,日志信息示例图。其中,每一行表示一条日志信息,其中包括了固定 的日志结构模板,也就是日志事件,以及日志参数。
[0044]
如图3所示,为经过日志解析得到的日志事件示例图。不同的日志事件、甚至是不 同的日志事件排列方式都代表着不同的系统运行状态。*代表日志参数,日志参数常常 记录了系统的参数,比如数值。
[0045]
步骤2、将测试用例的日志事件数据进行向量化处理,具体包括:从单词的语义向 量得到日志事件的向量表示,以及从日志事件的向量表示到测试用例的向量表示:
[0046]
日志事件是一段用自然语言描述系统运行状态的语句,为了得到每个日志事件语句 的向量,本发明通过“词频-逆文档频率”(tf-idf)评估日志事件语句中每个单词对于 整个日志事件语句的重要程度,依此对每个单词进行加权。tf-idf原本在自然语言处 理领域中用于挖掘文本特征,旨在衡量每个单词对区分不同文档的贡献。tf-idf的中 心思想是:一个单词若在单个文件中出现的次数越多则越重要,但与此同时如果它在整 个语料库中出现次数越多则越无关紧要。受到tf-idf的思想为启发,将“词频-逆文档 频率”的思想应用于日志事件向量化的过程中,并考虑自然语言语义信息对测试用例排 序的帮助。具体而言,tf表示单词在该日志事件语句中出现的频率,tf越大表示该单 词对于该日志事件语句越重要;idf表示逆文档频率,描述的是某个单词的普遍性,用 日志语句总数除以包含该单词的日志语句的数量,再取对数。如果idf很小,说明该单 词很常见;如果idf很大,说明该单词能够有效代表该日志事件语句。对于日志事件 e=[w1,w2,...,wi,...,wn],wi表示这句日志事件中的第i个单词。wi在这句日志事件中 的权重由该单词在该日志事件中出现的频率tf(wi)与该单词在所有不重复的日志事件 中出现的逆文档频率idf(wi)共同决定。通过对日志事件中所有单词加权求平均,便得 到日志事件的向量ve,如公式(1)所示。
[0047][0048]
其中,#wi表示该单词wi在这句日志事件出现的次数,n表示该日志事件中单词的总 个数,#se表示所有不重复的日志事件的个数,表示在#se中包含单词wi的日志事 件的个数,表示该单词的语义向量;
[0049]
每个测试用例生成的日志事件序列中包含了多条日志事件,为了得到每个测试用例 日志的向量化表示,本发明同样借助tf-idf的思想,对“词频-逆文档频率”加以改进, 并应用于测试用例日志的向量化过程。具体而言,tf表示日志事件在该日志事件序列 中出现的频率,tf越大表示该日志事件对于该日志事件序列越重要;idf用来描述某 个日志事件的普遍性,用总日志事件除以包含该日志事件的测试用例日志事件序列的数 量,再取对数。如果idf很小,说明该日志事件很常见,是一个普遍的日志输出;如果 idf很大,说明该日志事件能够有效代表该测试用例。假设一个测试用例得到的日志事 件序列为l=[e1,e2,...,ej,...,em],ej表示该测试用例的日志序列中的第j个日志事件。与 日志事件的向量ve同理,ej在该日志序列中的权重由该日志事件在该日志序列中出现的 频率tf(ej)与该日志事件在所有不重复的日志事件序列中出现的逆文档频率idf(ej)共 同决定。得到测试用例的向量v
ts
如公式(2)所示。
[0050][0051]
其中,#ej表示日志事件ej在该测试用例的日志序列中出现的次数,m表示该测试用 例中日志序列的总个数,#s
t
表示所有不重复的测试用例日志序列的个数,表示在 #s
t
中包含日志事件ej的测试用例日志序列的个数,表示该日志事件的向量表示;
[0052]
进而得到测试用例的向量矩阵
[0053]
步骤3、基于日志事件进行自适应测试用例排序:
[0054]
如果两个测试用例的向量表示的欧氏距离很小,那么说明这两个测试用例是相似 的。当执行一个测试用例后,再执行一个相似的测试用例是很不明智的。因此,在测试 用例排序中,每次选择与已排序的测试用例集合具有最大欧氏距离的测试用例,尽可能 快地覆盖测试空间。
[0055]
但是,与传统的自适应随机排序算法随机选择某个测试用例作为第一个排序结果不 同的是,本步骤统计每个测试用例产生的日志的生成位置,覆盖位置个数最多的测试用 例作为排序结果中的第一个。这是因为日志的生成位置反映出测试用例执行时经过的位 置,因此把覆盖位置个数最多的测试用例放在排序结果中的第一个,减少了随机性给排 序结果带来的影响。具体而言,假设需要排序的测试用例为ts=[ts1,ts2,...,tsu]:
[0056]
首先,选择输出日志的位置最多的测试用例作为第一个测试用例,从剩余未排序的 测试用例中选择与已排序的测试用例具有最大欧氏距离的测试用例,顺序放入排序结果 序列,并以此类推。设有f个未排序的测试用例[ts1,ts2,...,tsf]与g个已排序的测试用例 [ts
′1,ts
′2,...,ts
′g],未排序的测试用例ts
x
与当前已排序的g个测试用例的最小欧氏距离 d(x)如公式(3)所示。
[0057][0058]
其中,euclidean表示欧几里得距离函数,ts
x
表示在f个未排序的测试用例中的第 x个测试用例,表示ts
x
的向量,tsy表示已排序的g个测试用例中的第y个测试用例, 其中1≤y≤g,min表示最小值函数;
[0059]
接下来,分别计算f个未排序的测试用例与g个已排序的测试用例的欧氏距离,得 到已排序的测试用例集合具有最大欧氏距离的测试用例为ts
next_index
,其中,应该从未 排序的测试用例中选择放入已排序测试用例的序列中的第next_index个测试用例如公 式(4)所示:
[0060][0061]
其中,d(x)表示未排序的测试用例ts
x
与已排序测试用例的最小欧氏距离, 表示求在1≤x≤f范围内使d(x)值最大的x;
[0062]
重复步骤3,每次从未排序的测试用例中选择一个测试用例加入排序结果序列,直 到所有测试用例都被排序完,得到基于日志事件的自适应测试用例排序的排序结果 r
event
。
[0063]
本发明采用广泛使用的变异方法pit所提供的所有变异算子来生成变异缺陷,并依 据变异缺陷研究的结论过滤掉重复的变异缺陷,以降低重复变异缺陷对测试用例排序方 法有效性的夸大影响。另外,实验中删除了不能被任何测试用例杀死的变异缺陷。
[0064]
为了验证本发明有效性和对现有的黑盒测试用例排序方法的提升,本发明与黑盒测 试用例排序领域中最先进的2个方法进行效果对比,分别是thomas等人提出的基于测 试用例文本的主题的测试用例排序方法,和ledru等人提出的基于测试用例字符串的编 辑距离的测试用例排序方法。其中,基于测试用例文本主题的测试用例排序方法利用测 试代码中的语言信息进行主题建模,为每个测试用例生成一个基于主题的向量,并通过 比较它们之间的欧氏距离,每次找到与已排序的测试用例的平均欧氏距离最大的一个测 试用例,最终得到测试用例排序结果;而基于测试用例字符串的编辑距离的测试用例排 序方法是将测试用例视为字符串,用字符串的编辑距离代表测试用例之间的距离,并得 到测试用例排序结果。之所以选择这两种方法作对比,是因为这两种方法都是黑盒的测 试用例排序方法,而且和本发明相比还利用了测试用例的源码信息,因此和这两种方法 进行对比,能够充分地证明本发明在提升黑盒测试用例排序效果的有效性。另外,本发 明也对比了白盒的两种测试用例排序方法,分别是全局测试用例排序和增量的测试用例 排序,旨在证明本发明旨在证明本发明是否能够有效地弥合白盒与黑盒之间的效果差 异。其中,白盒方法的覆盖信息是通过openclover2进行收集。在实验中,本发明方法 在10个实验对象上进行了对比实验,它们分别来自10种涉及不同领域的开源java项目, 分别是:基于java的多协议的代理工具activemq、基于分布式计算资源的软件库康 佳airavata、大型的高速数据库blueflood、具有智能容错与负载均衡功能的开源服务框 架dubbo、用于高效收集、聚合和移动大量日志数据的flume、分布式的分析型数据仓 库kylin,用于识别学术作者和贡献者的orcid、java安全框架shiro,用于对seleniumwebdriver所需的驱动程序的开源java库webdrivermanager以及基于java的web开 发框架wicket。这些实验对象都基于maven框架构建,并通过junit框架管理测试用例。 在本实验中将每个测试类作为排序对象。
[0065]
如图4所示,为本发明的一种基于日志的面向回归测试的黑盒测试用例排序方法的 具体实施过程示意图。本发明应用于回归测试,新版本的代码在上一版本的代码的基础 上增加了部分修改,为了保证修改没有引入新的错误,新版本的代码需要通过上一版本 的测试用例。因此,本发明需要收集测试用例在上个版本运行产生的日志,作为本发明 的测试用例排序方法的输入,方法的输出是已经排序的测试用例序列。此时,将已排序 的测试用例应用于新版本的代码,可以尽早地发现出更多的软件缺陷,达到测试用例排 序的目的。为了模拟含有缺陷的新版本代码,本发明在对比时,利用pit得变异体作为 新版本的代码。为了提高变异体的质量,在实验中分析出测试用例与其杀死变异体的对 应信息,并删除了效果重复的变异体。
[0066]
在度量指标方面,本发明沿用了两种评测指标:apfd和rauc-s,以评估测试用 例排序技术的效果。
[0067]
apfd:平均故障检测率(average percentage of fault detection)被广泛应用于对测 试用例排序算法的评估,其计算方法如公式(6)所示:
[0068][0069]
其中,n表示测试用例的数量,m为被测系统中缺陷的总数量,tfi表示在排序后的 测试用例序列中,首次检测到缺陷i的测试用例所在的次序。若排在前面的测试用例能 检测出更多的缺陷,则apfd的值就会越高。因此,apfd可以度量测试用例排序结果 检测缺陷的能力,它的值域为[0,1]。
[0070]
rauc-s:由于在实际生产实践中有限的测试执行时间,通常不会完整地执行所有 测试用例。因此,从整体进行评估的apfd指标具有一定的局限性,在实际场景中我们 希望通过排序结果中前几个测试用例,就能检测出所有已知缺陷。所以,本实验沿用已 有工作中的评估方法,将排序结果转化为二维坐标曲线。其中,x轴表示测试用例的数 量,y轴表示测试用例检测出来的缺陷的数量。对于前s个测试用例,该曲线下的面积 与理想排序结果的曲线下的面积的比率称为rauc-s,用来衡量排序方法得到的排序结 果与理想排序结果的接近程度。其中,理想测试用例排序在每次排序时,首先统计没有 被已排序的测试用例检测到的变异缺陷,并从未排序的测试用例中,选择一个能检测出 最多的未检测的变异缺陷的测试用例。在本实验中,s分别取值为所有测试用例数量的 25%,50%,75%以及100%,并将这些评价指标分别称为rauc-25%,rauc-50%, rauc-75%以及rauc-100%。rauc-s值越大,说明排序结果越好。首先,将本发明 与黑盒方法进行对比。
[0071]
如表1所示,为本发明方法与两种现有的黑盒测试用例排序方法(基于字符串与基 于主题)在10个实验对象上的apfd值的对比。
[0072]
表1
[0073][0074][0075]
其中,用加粗的方式标出了每个实验对象最好的apfd结果,最后一行表示在10 个实验对象上的平均值。从表1中可以看出,本发明方法的apfd值全部优于其他两种 黑盒的对比方法。具体而言,在10个实验对象上,本发明方法的平均apfd值达到了 0.7969,比基于字符串的黑盒排序方法提高了17.49%,比基于主题的黑盒排序方法提高 了17.38%。这些apfd结果彰显了本发明方法的显著优势。
[0076]
如表2所示,为本发明方法与两种现有的黑盒测试用例排序方法(基于字符串与基 于主题)在10个实验对象上的rauc-s值(包括rauc-25%,rauc-50%,rauc-75%, 以及rauc-100%四个指标)的对比。
[0077]
表2
[0078][0079]
其中用加粗的方式标出了每个实验对象在每个指标上最好的rauc-s结果,最后一 行表示每种方法在10个实验对象上的平均rauc-s值。从表2可以看出,在所有实验 对象上,本发明方法始终具有最好的rauc-s值。因此在实际应用中,在有限的测试时 间里,如果仅执行排在前面的测试用例,本方法得到的排序结果可以比其他黑盒对比方 法检测出更多的缺陷。
[0080]
表1和表2示出本发明方法能够极大地提高黑盒测试用例排序方法的有效性。正是 因为本方法利用日志丰富的自然语言语义信息,能够提升黑盒测试用例排序方法的排序 效果。更值得一提的是,实验中所对比的两种黑盒排序方法需要获取测试用例的代码, 而本发明中的排序方法只需要测试用例在上一版本运行时生成的日志,因此本方法适用 性广泛,尤其适用于测试人员无法获得被测系统源码以及测试用例源码的情况,可以大 大提升黑盒测试用例排序方法的健壮性。
[0081]
如表3所示,为本发明方法与两种现有白盒测试用例排序方法(增量和全局)在10 个项目上的apfd值的对比。
[0082]
表3
[0083][0084]
其中用加粗的方式标出了每个最好的apfd结果。
[0085]
表3中的数据表明,本发明方法在10个实验对象上的平均apfd值高于两种对比 的白盒测试方法。具体而言,本发明方法在4个实验对象上得到最高的apfd值,而对 比的白盒测试方法在其他6个实验对象上获得最高的apfd值。
[0086]
如表4所示,为本发明方法与两种现有的白盒测试用例排序方法(增量方法和全局 方法)在10个实验对象上的rauc-s值(rauc-25%,rauc-50%,rauc-75%,以 及rauc-100%四个指标。)的对比。其中用加粗的方式标出了每个实验对象在每个指 标上最好的rauc-s结果,最后一行表示每种方法在10个实验对象上的平均rauc-s 值。从表4可以看出,在平均rauc-25%和平均rauc-50%方面,本发明方法优于两 种白盒测试方法。而对于rauc-75%和rauc-100%,本发明方法只是分别比最好的白 盒测试方法稍逊了0.0004和0.0028。
[0087]
表4
[0088]
[0089]
表3、表4表明本发明方法可以缩小黑盒测试用例排序方法与白盒排序方法之间的 差异,在一些实验对象上甚至略微优于最好的白盒方法。这也说明,本方法可以不依赖 于源代码信息便可达到和白盒方法不相上下的结果,因此本方法作为黑盒排序方法更具 实用价值。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1