一种融合字符信息的知识驱动文本分类方法
1.本发明涉及文本分类与深度学习技术领域,具体涉及一种融合字符信息的知识驱动文本分类方法。
背景技术:
2.随着互联网的不断发展,媒体通常使用网站和微信公众号等来发布信息,人们也经常通过博客、论坛等来表达自己的观点,互联网文本数据的规模急速增长。文本分类是管理和组织这些网络文本信息的关键技术之一,可以用来过滤垃圾邮件和短信、分析人类的情感,以及学习人们阅读新闻的偏好从而实现新闻推荐等重要任务。
3.随着机器学习的快速发展,目前已有许多利用机器学习实现文本分类的方法,如使用word2vec将文本中每个词向量化,输入到卷积神经网络、循环神经网络、支持向量机、随机森林或者k近邻等算法或模型中,从而得到文本分类的结果。然而,这些方法一般仅从文本的词语层面进行表示学习,没有考虑文本隐含的外部知识,未充分挖掘文本在知识层面的联系。典型的例子是在处理新闻分类任务时,新闻语言通常由大量的知识实体组成,比如训练集中有一条标题为“特斯拉在高速公路自动驾驶,司机乘客在车里呼呼大睡”的汽车类新闻,测试集中有一条标题为“福特领界领衔福特家族,成都展览备受瞩目”的新闻,这两句标题分别包含“特斯拉”和“福特”这两个知识实体,都代表了汽车品牌,这两条新闻有一定知识层面的关联。然而仅从文本的词语层面进行表示学习的模型只能根据词语所处的上、下文语境来判断词语的关联性,很难挖掘出像“特斯拉”与“福特”这两个词语在知识层面的关联性,从而可能导致测试集中的有关“福特”的新闻没有被分到“汽车”类新闻中,使得分类不准确。
4.除了词语和知识信息以外,很多文本分类方法还忽略了字符信息,字符信息对文本分类的结果也有重要影响。例如,测试集中有一句文本为“你很明智”,而“明智”对于知识库和通过训练集预先训练的词向量集合而言是一个新词语。若文本分类方法没有考虑字符信息,则“明智”无法被识别。若文本分类方法考虑了字符信息,虽然训练集的文本中没有“明智”这个词,但却有词语“智慧”,文本分类方法可以通过“智”这个字符在“智慧”与“明智”这两个词的文本之间建立联系,从而改善文本分类效果。
技术实现要素:
5.本发明的目的是针对现有技术的不足而设计的一种融合字符信息的知识驱动文本分类方法,采用知识图谱作为外部知识的载体,利用外部知识辅助文本分类任务,并考虑文本的字符信息,将文本内容中的每个词与知识图谱中的相关实体以及其上下文相关联,融入知识层面的表示,同时使用文本的字符特征捕获更细粒度的语义信息,充分考虑了文本中隐含的外部知识和字符信息,从而使该方法具有更高的文本分类性能,方法简便,可进一步提高了文本分类的准确率。
6.本发明的目的是这样实现的:一种融合字符信息的知识驱动文本分类方法,其特
点是该方法以知识图谱作为外部知识的载体,将文本内容中的每个词与知识图谱中的相关实体以及其上下文相关联,融入知识层面的表示,从而使文本分类方法能够更好地理解文本内容,给出更准确的分类结果,具体包括以下步骤:
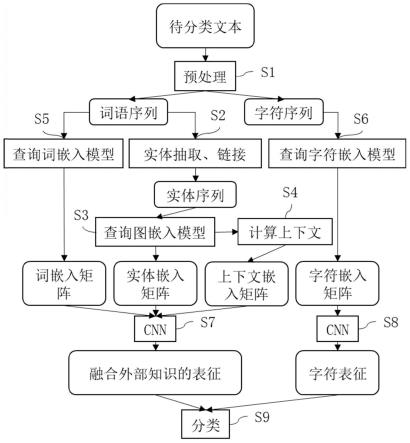
7.s1:对文本进行预处理,获取待分类文本的词语序列和字符序列;
8.s2:提取文本中词语所对应的实体,并与知识图谱中的实体相关联,获取实体序列;
9.s3:查询通过知识子图预训练的知识图谱嵌入模型,获取实体序列的实体嵌入矩阵,矩阵的每一行为各实体的嵌入向量;
10.s4:搜索每个实体的上下文实体集来计算实体的上下文向量,得到实体序列的上下文嵌入矩阵;
11.s5:查询预训练的词嵌入模型,获取词语序列的词嵌入矩阵;
12.s6:查询预训练的字符嵌入模型,获取字符序列的字符嵌入矩阵;
13.s7:将文本的词嵌入矩阵、实体嵌入矩阵、上下文嵌入矩阵输入到卷积神经网络得到融合外部知识的表征向量;
14.s8:将字符嵌入矩阵输入到另一个卷积神经网络获取字符表征向量;
15.s9:使用融合外部知识的表征向量和字符表征向量进行文本分类。
16.所述步骤s1中待分类文本中的词语序列中的每个词由分词器对文本进行分词处理后所得,字符序列由文本中的每个字符所构成。将包含n个词语的待分类文本t的词语序列定义为w
1:n
=[w1,w2,...,wn],其中wi表示文本中第i个词语。
[0017]
所述步骤s2具体包括:利用命名实体识别技术识别出待分类文本中词语是否指代实体,并通过实体链接技术将文本中的实体指称(指代实体的词语)链接其在知识图谱中的目标实体,由这些目标实体构成实体序列。
[0018]
所述步骤s3具体包括:从知识图谱中获取语料库中的词语所指代的实体的三元组知识,用来构建知识子图。使用知识子图与知识图谱嵌入方法训练知识图谱嵌入模型,通过知识图谱嵌入模型映射可获得词语wi对应实体ei的实体向量ei∈rk×1,其中,k是实体向量的维度。实体嵌入矩阵则由知识图谱嵌入模型映射获得,其中实体嵌入矩阵的每一行为实体序列中每一个实体对应的实体向量。
[0019]
所述步骤s4具体包括:搜索并使用实体序列中每个实体的上下文实体集(即实体在知识子图中的近邻实体)来计算实体的上下文向量,以得到更多互补和有意义的信息。实体e的上下文实体集由下述(a)式定义:
[0020]
context(e)={ei|(e,r,ei)∈g or(ei,r,e)∈g}(a);
[0021]
其中:r代表一个关系;g代表知识子图。
[0022]
在获得了实体的上下文实体集后,实体的上下文向量可通过下述(b)式进行计算:
[0023][0024]
其中:ei是实体ei的向量。
[0025]
所述实体序列的上下文嵌入矩阵由实体的上下文向量构成,矩阵的每一行为实体序列中每一个实体对应的上下文向量。
[0026]
所述步骤s5中词语序列的词嵌入矩阵是通过预训练或随机初始化的词嵌入模型
映射获得的,其中词嵌入矩阵的每一行为词语序列中每一个词语对应的词嵌入向量。文本t的词嵌入矩阵由下述(c)式表示为:
[0027]w1:n
=[w1,w2,...,wn]∈rd×nꢀꢀꢀ
(c);
[0028]
其中:wi∈rd×1是文本中第i个词语wi的词向量;d是词向量的维度。
[0029]
所述步骤s6中字符序列的字符嵌入矩阵是通过预训练或随机初始化的字符嵌入模型映射获得的,其中字符嵌入矩阵的每一行为字符序列中每一个字符对应的字符嵌入向量。
[0030]
所述步骤s7具体包括:通过下述非线性公式(d)~(e)转换词语wi对应实体ei的实体向量ei和实体上下文向量使其维度与词向量一致:
[0031]
g(ei)=tanh(mei+b)
ꢀꢀꢀ
(d);
[0032][0033]
其中:m∈rd×k是可训练的转换矩阵;b∈rd×1是可训练的偏置项。
[0034]
然后,将词嵌入矩阵、实体嵌入矩阵和上下文嵌入矩阵中每个词语的词向量、实体向量与实体上下文向量分别输入cnn卷积层的三个通道并对齐,其形式如下述(f)式所示:
[0035][0036]
将文本中所有词语按上述形式输入卷积神经网络(convolutional neural network,cnn)中,在经过卷积、池化层后,得到一个融合文本t外部知识的表征向量。
[0037]
所述步骤s8具体包括:将字符序列的字符嵌入矩阵输入cnn,经过卷积、池化操作后,得到字符表征向量。
[0038]
所述步骤s9具体包括:将融合外部知识的表征向量和字符表征向量拼接为一个向量v(假设v∈ry×1),若类别个数为c,则对向量v进行下述(g)式操作:
[0039]
q=hv+b
ꢀꢀꢀ
(g);
[0040]
其中:h∈rc×y,为可训练矩阵;b∈rc×1,为可训练的偏置项参数。
[0041]
然后,使用softmax函数构建分类器,得到由下述(h)式计算的每个类别的概率分布:
[0042][0043]
其中:scorej表示文本属于第j类的概率。
[0044]
在得到每个类别的概率分布后,选出概率值最高的类别作为文本分类结果。
[0045]
本发明与现有技术相比具有更高的文本分类性能,充分考虑文本中隐含的外部知识和字符信息,将文本的词级、知识级表示与字符级表示融合起来形成新的表示,从而使文本分类能够更好地理解文本内容,给出更准确的分类结果,方法简便,可进一步提高文本分类的准确率。
附图说明
[0046]
图1为本发明的流程图。
[0047]
图2为实施例的知识子图示例。
具体实施方式
[0048]
为了使本发明的技术方案被理解透彻,下面结合具体实施例和附图,对本发明作详细说明。实施本发明的过程、条件、实验方法等,除以下专门提及的内容之外,均为本领域的普遍知识和公识常识,本发明没有特别限制内容。
[0049]
参阅图1,本发明所提出的文本分类方法融合了文本的词、知识和字符信息,将文本的词级、知识级表示与字符级表示融合起来形成新的表示,进行文本分类,提高了文本分类的准确性。
[0050]
下面以体育类新闻“小明和小红是运动会的王炸组合”作为待分类文本为例对本发明作进一步的详细说明。
[0051]
实施例1
[0052]
步骤s1:对待分类文本进行分词,得到词语序列为:[“小明”,“和”,“小红”,“是”,“运动会”,“的”,“王炸”,“组合”]。然后,获取文本的字符序列:[“小”,“明”,“和”,“小”,“红”,“是”,“运”,“动”,“会”,“的”,“王”,“炸”,“组”,“合”]。
[0053]
步骤s2:利用命名实体识别技术从文本中提取出“小明”、“小红”、“运动会”和“王炸”这四个实体指称。通过实体链接技术将这四个实体指称链接到中文知识图谱cn-dbpedia中的目标实体“小明”、“小红”、“2022年某国际运动会”和“王炸(扑克牌型)”(这四个实体皆为虚设实体,仅作为示例用)。由这些目标实体构成实体序列:[“小明”、“《unknown》”、“小红”,“《unknown》”,“2022年某国际运动会”,“《unknown》”,“王炸(扑克牌型)”,“《unknown》”],待分类文本中不指代实体的词语在实体序列中的对应目标实体为“《unknown》”标识符。
[0054]
步骤s3:从cn-dbpedia中获取语料库中全部文本的词语所指代的实体的三元组知识,用来构建知识子图。
[0055]
参阅图2,以“小明和小红是运动会的王炸组合”单句话所构建的知识子图,使用知识子图与知识图谱嵌入方法transe训练知识图谱嵌入模型。通过知识图谱嵌入模型将实体序列中每一个实体映射为一个128维的向量(“《unknown》”实体的向量通过随机初始化获得),实体序列的长度为8,则实体序列被转换为8
×
128的实体嵌入矩阵。
[0056]
步骤s4:通过公式1和2搜索并使用实体序列中每个实体的上下文实体集来计算实体的上下文向量。每一个上下文向量的维度为128,实体序列的长度为8,则得到一个8
×
128的上下文嵌入矩阵。
[0057]
步骤s5:通过预训练的word2vec词嵌入模型,将步骤s1中得到的词语序列中的每一个词转换成128维的向量,词语序列包含8个词语,被转换为8
×
128的词嵌入矩阵。
[0058]
步骤s6:通过预训练的word2vec字符嵌入模型,将步骤s1中得到的字符序列中的每一个字符转换为128维的向量,字符序列包含14个字符,则字符序列被转换为14
×
128的字符嵌入矩阵。
[0059]
步骤s7:将步骤s3、s4、s5处理后获得的词嵌入矩阵、实体嵌入矩阵、上下文嵌入矩阵分别输入到卷积神经网络的三个不同的通道中,得到一个融合了文本外部知识的表征向量。
[0060]
步骤s8:将字符序列的字符嵌入矩阵输入卷积神经网络,经过卷积、池化操作后,得到一个字符表征向量。
[0061]
步骤s9:将在步骤s7中得到的融合外部知识的表征向量和在步骤s8中得到的字符表征向量拼接为一个向量,通过公式(g)~(h)得到每个类别的概率分布后,选出概率值最高的类别作为文本分类结果。
[0062]
以上实施例只是对本发明做进一步说明,并非用以限制本发明,凡为本发明的等效实施,均应包含于本发明的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1