基于零代词补齐的汉越数据增强方法
1.本发明涉及基于零代词补齐的汉越数据增强方法,属于自然语言处理技术领域。
背景技术:
2.神经机器翻译是典型的数据驱动模型,平行语料库的规模和质量对机器翻译的性能会产生重要的影响。然而现阶段汉语-越南语公开数据集极少,往往只能通过网络爬取的方式获取,并且还需要专业人士的专业知识对其进行筛选、标注等预处理工作。其规模提升所需要的成本很高。因此研究针对汉越平行语料库的汉越数据增强方法具有很高的价值。
3.汉语和越南语都属于代词脱落语言,这种语言的特性就是当代词的身份可以从上下文中推断出来时,它会省略这些代词,以使句子紧凑而易于理解。我们把这些省略的代词称为零代词。这些省略对人类而言不是问题,因为我们可以很容易的从全局的角度来推测省略的主语。但是对于机器翻译而言,这种代词的缺失,会使得句法成分不完整,给nmt机器翻译带来很大的问题,甚至会造成一些错误的学习训练。
4.针对训练数据含有非正式用语的汉越平行语料,常出现省略代词的现象。因此可以通过对低质量语句的缺失代词进行补齐操作,得到一些高质量的汉越双语平行语料。前人在零代词补齐问题上已经做了一些相关的研究。或是通过手动标注,将缺失代词补齐,又或是尝试使用规则的方法恢复省略的代词。还有利用平行语料库的对齐信息自动标注出省略代词。虽然transformer可以利用多头注意力机制来捕获更多的语义信息,然后对于省略了的代词,也往往只能翻译出简单的部分内容。对于复杂句子中的省略代词翻译往往不如人意。
技术实现要素:
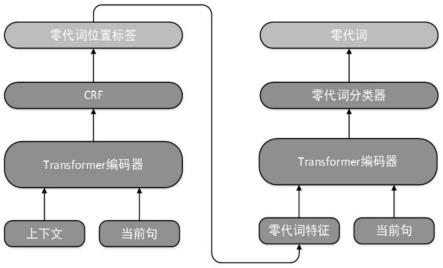
5.本发明提供了基于零代词补齐的汉越数据增强方法,将零代词的补齐工作主要分为零代词位置预测和零代词预测。第一步先确实零代词位置信息,第二步再预测缺失的是哪个代词。零代词位置预测任务使用transformer+crf的模型结构来标注出缺失位置。零代词预测任务使用transformer的编码端来表征输入,同时融合语法、句法和上下文信息来提升代词信息表征,增强零代词预测准确率。
6.本发明的技术方案是:基于零代词补齐的汉越数据增强方法,所述方法的具体步骤如下:
7.step1、数据收集处理:通过网络爬虫技术爬取收集并构建英汉、英越双语平行数据,利用矩阵对齐方法找出汉语、越南语中缺失的代词,并利用英语平行语料中的对应代词,将汉语、越南语中缺失的代词标注补齐,得到零代词信息标注的汉语、越南语单语数据集;缺失的代词即为零代词;
8.step2、进行零代词补齐,零代词补齐包括零代词位置预测、零代词特征集生成和零代词预测,把预测出的零代词放入源句子进行零代词补齐从而对汉越数据进行增强:
9.零代词位置预测通过词嵌入和位置嵌入分别对正文和上下文进行特征编码,利用
transformer编码器提取特征,其中正文和上下文共享编码端以减少参数;利用上下文注意力机制对正文表征约束,将transformer编码器得到隐状态输入crf模型中进行标注,得到零代词位置信息;
10.零代词特征集生成是利用零代词位置信息生成与零代词相关的词汇、句法、上下文特征集合;
11.零代词预测是重新利用transformer编码端对正文进行编码,同时与零代词特征集做注意力计算,以提升零代词信息表征,最后将注意力计算后的输入表征通过一个多分类器模块,经过线性变换和归一个处理得到分类结果,即零代词预测结果。
12.作为本发明的进一步方案,所述step1的具体步骤为:
13.step1.1、通过网络爬虫技术爬取英汉、英越双语字幕文件,解析字幕文件,对语料初步预处理,构建英汉、英越双语平行数据;
14.step1.2、利用英语不省略代词的特性,采用有监督的代词补齐方法;通过词矩阵对齐找出汉语、越南语中缺失的代词,并利用英语平行语料中的对应代词,将汉语、越南语中缺失的代词补齐;
15.step1.3、采用人工标注的方法,对补齐了代词的汉语、越南语打上标签;单词的标签一共只有两种l={d,n},分别表示缺失代词和没有缺失代词,将代词缺失的后一个单词位置标注为d,其他单词都标注为n。
16.作为本发明的进一步方案,所述step2中,零代词位置预测包括:
17.step2.1、零代词位置预测的任务是找到句子中是否缺失代词,并将代词缺失位置标注出来;
18.设x=x
(1)
,..,x
(k)
,..,x
(k)
表示k个源句子组成的源语言文档,表示k个源句子组成的源语言文档,表示第k个源句子包含i个词;使用transformer编码模块对正文的特征嵌入进行编码;为了能够利用序列的顺序,在编码模块中将位置编码添加到词嵌入表征中,位置编码与词嵌入表征具有相同的维数,编码模块核心是自注意力机制,多头注意力模块计算时需要将输入表征分别处理成q、k、v,具体如下:
19.e=e(x1,x2,...,xi)
ꢀꢀꢀ
(1)
20.e=q=k=v
ꢀꢀꢀ
(2)
[0021][0022]
其中,e为正文中当前句的词嵌入表征,d表示正文中当前句的词向量维度,q,k,v∈ri×d分别为查询向量、键向量、值向量,为缩放因子;
[0023]
多头注意力通过不同的线性投影将q、k、v进行h次线性投影,然后h次投影并行执行缩放点积注意,最后将这些注意结果串联起来再次获得新的表示;
[0024]
headi=attention(qw
iq
,kw
ik
,vw
iv
)
ꢀꢀꢀ
(4)
[0025]
h=multihead(q,k,v)=concat(head1,head2,
…
,headh)woꢀꢀꢀ
(5)
[0026]
其中,h∈ri×d为正文编码后的输出;wo∈rd×d为训练的参数,dk∈d/h;
[0027]
利用上下文编码模块进行上下文特征编码:
[0028]
与标准的transformer编码器不同的是,上下文编码模块多了一个多头上下文注意力子层来融合上下文信息;为了减少计算成本,采用共享编码器的结构;编码器先编码当前句上下文,上下文注意力子层不参与此过程,第二步编码当前句时,当前句自注意力子层和上下文注意力子层同时参与计算利用上下文信息约束正文中当前句的表征,上下文注意力子层的输入k
con
,v
con
来自于上下文的编码输出,q来自于当前句的注意力子层的输出,当前句的编码输出作为隐状态进行下一步计算;
[0029]
h2=attention(q,k
con
,v
con
)
ꢀꢀꢀ
(6)
[0030]
其中h2表示上下文注意力模块输出隐状态;再将进行一个前馈神经网络的变换,最后将隐状态表征放入到crf模型中,进行一个序列标注的工作,最后得到一个标签序列y=(y1,y2,y3,...,y
t
,...,yn),其中每个y
t
对应着每个单词x
t
的标签;单词的标签一共只有两种l={d,n},分别表示缺失代词和没有缺失代词,将代词缺失的后一个单词位置标注为d,其他单词都标注为n,最终将预测的结果和真实的标签计算损失。
[0031]
作为本发明的进一步方案,所述step2中,零代词特征集生成包括:
[0032]
step2.2、检测到零代词的位置信息后,根据这个位置信息,挖掘对零代词预测有用的特征:根据零代词的位置信息,从词汇、句法、上下文方面来提取零代词特征集,零代词特征集包括词汇特征:标签词p、p前后各一个词、p前后各一个代词;句法特征:当前句s的主语、谓语、宾语;上下文特征:上一句s-1的主语和宾语、下一句s+1的主语和宾语。
[0033]
作为本发明的进一步方案,所述step2中,零代词预测包括:
[0034]
step2.3、进行零代词预测,确定在代词缺失位置具体该补齐哪个代词,把预测出的零代词放入源句子进行零代词补齐从而对汉越数据进行增强:
[0035]
训练一个多分类器,其中每一个类代表着一个可能缺失的代词;使用transformer编码端来对当前句进行表征,与传统transformer编码端不一样的是,增加了一个代词注意力模块,通过挖掘对零代词分类有用的特征,来使输入隐状态更好的表示出零代词信息;零代词注意力模块的k
dp
、v
dp
来自于零代词特征集的编码输入,q
dp
来自于正文多头注意力子层的输出,再将零代词注意力模块的输出进行下一步分类计算;
[0036]hdp
=attention(q
dp
,k
dp
,v
dp
)
ꢀꢀꢀ
(7)
[0037]
其中h
dp
表示零代词注意力模块的输出;
[0038]
在多分类模块,将编码模块的输入隐状态通过一个线性变化,再进行归一化计算,得到最后的分类结果,即零代词预测结果,把预测出的零代词放入源句子进行零代词补齐从而对汉越数据进行增强;
[0039]
y=soft max(σ(hw1+b1)w2+b2)
ꢀꢀꢀ
(8)
[0040]
其中h表示编码端输入隐状态,w1,w2,b1,b2为模型参数,σ为sigmoid函数;
[0041]
最终将预测的结果和真实的标签计算损失;损失函数为:
[0042][0043]
其中n表示训练样例数,c表示类别标签数,表示模型预测类别c的概率。
[0044]
本发明的有益效果是:
[0045]
1、针对于汉语、越南语在非正式场合下使用会出现代词省略的语法特性,提出一
种基于零代词补齐的汉越数据增强方法。通过补齐缺失的代词,提升了汉越双语平行数据库的数量和质量。
[0046]
2、针对零代词位置预测这个序列标注任务,提出了一种全新的transformer+crf的模型方法,同时利用共享编码器的方法进一步融入更多上下文信息。实验结果表明,零代词位置预测准确率有了一定的提升。
[0047]
3、在零代词预测任务中,本发明根据零代词特性,分析并提出了与零代词息息相关的包含词信息、语法信息和上下文信息的特征集合。并通过注意力机制融入零代词预测模型中。提升了零代词预测准确率。
附图说明
[0048]
图1是本发明提出的基于零代词补齐的汉越数据增强方法流程示意图;
[0049]
图2是代词位置预测模型的具体结构示意图;
[0050]
图3是代词预测模型的具体结构示意图。
具体实施方式
[0051]
实施例1:如图1-图3所示,基于零代词补齐的汉越数据增强方法,所述方法的具体步骤如下:
[0052]
step1、数据收集处理:通过网络爬虫技术爬取收集并构建英汉、英越双语平行数据,利用矩阵对齐方法找出汉语、越南语中缺失的代词,并利用英语平行语料中的对应代词,将汉语、越南语中缺失的代词标注补齐,得到零代词信息标注的汉语、越南语单语数据集;缺失的代词即为零代词;
[0053]
所述step1的具体步骤为:
[0054]
step1.1、通过网络爬虫技术爬取英汉、英越双语字幕文件,解析字幕文件,对语料初步预处理,构建英汉、英越双语平行数据;
[0055]
step1.2、利用英语不省略代词的特性,采用有监督的代词补齐方法;通过词矩阵对齐找出汉语、越南语中缺失的代词,并利用英语平行语料中的对应代词,将汉语、越南语中缺失的代词补齐;
[0056]
step1.3、采用人工标注的方法,对补齐了代词的汉语、越南语打上标签;单词的标签一共只有两种l={d,n},分别表示缺失代词和没有缺失代词,将代词缺失的后一个单词位置标注为d,其他单词都标注为n。
[0057]
表1零代词标签结构
[0058][0059]
实验语料规模如表2所示:
[0060]
表2实验数据规模统计
[0061][0062]
step2、进行零代词补齐,零代词补齐包括零代词位置预测、零代词特征集生成和零代词预测,把预测出的零代词放入源句子进行零代词补齐从而对汉越数据进行增强:
[0063]
零代词位置预测通过词嵌入和位置嵌入分别对正文和上下文进行特征编码,利用transformer编码器提取特征,其中正文和上下文共享编码端以减少参数;利用上下文注意力机制对正文表征约束,将transformer编码器得到隐状态输入crf模型中进行标注,得到零代词位置信息;
[0064]
零代词特征集生成是利用零代词位置信息生成与零代词相关的词汇、句法、上下文特征集合;
[0065]
零代词预测是重新利用transformer编码端对正文进行编码,同时与零代词特征集做注意力计算,以提升零代词信息表征,最后将注意力计算后的输入表征通过一个多分类器模块,经过线性变换和归一个处理得到分类结果,即零代词预测结果。
[0066]
作为本发明的进一步方案,所述step2的具体步骤如下:
[0067]
step2.1、零代词位置预测的任务是找到句子中是否缺失代词,并将代词缺失位置标注出来;
[0068]
设x=x
(1)
,..,x
(k)
,..,x
(k)
表示k个源句子组成的源语言文档,表示k个源句子组成的源语言文档,表示第k个源句子包含i个词;使用transformer编码模块对正文的特征嵌入进行编码;为了能够利用序列的顺序,在编码模块中将位置编码添加到词嵌入表征中,位置编码与词嵌入表征具有相同的维数,编码模块核心是自注意力机制,多头注意力模块计算时需要将输入表征分别处理成query(q),key(k),value(v),具体如下:
[0069]
e=e(x1,x2,...,xi)
ꢀꢀꢀ
(1)
[0070]
e=q=k=v
ꢀꢀꢀ
(2)
[0071][0072]
其中,e为正文中当前句的词嵌入表征,d表示正文中当前句的词向量维度,q,k,v∈ri×d分别为查询向量、键向量、值向量,为缩放因子;
[0073]
多头注意力通过不同的线性投影将q、k、v进行h次线性投影,然后h次投影并行执行缩放点积注意,最后将这些注意结果串联起来再次获得新的表示;
[0074]
headi=attention(qw
iq
,kw
ik
,vw
iv
)
ꢀꢀꢀ
(4)
[0075]
h=multihead(q,k,v)=concat(head1,head2,
…
,headh)woꢀꢀꢀ
(5)
[0076]
其中,h∈ri×d为正文编码后的输出;wo∈rd×d为训练的参数,dk∈d/h;
[0077]
利用上下文编码模块进行上下文特征编码:
[0078]
与标准的transformer编码器不同的是,上下文编码模块多了一个多头上下文注意力子层来融合上下文信息;为了减少计算成本,采用共享编码器的结构;编码器先编码当前句上下文,上下文注意力子层不参与此过程,第二步编码当前句时,当前句自注意力子层和上下文注意力子层同时参与计算利用上下文信息约束正文中当前句的表征,上下文注意力子层的输入k
con
,v
con
来自于上下文的编码输出,q来自于当前句的注意力子层的输出,当前句的编码输出作为隐状态进行下一步计算;
[0079]
h2=attention(q,k
con
,v
con
)
ꢀꢀꢀ
(6)
[0080]
其中h2表示上下文注意力模块输出隐状态;再将进行一个前馈神经网络的变换,最后将隐状态表征放入到crf模型中,进行一个序列标注的工作,最后得到一个标签序列y=(y1,y2,y3,...,y
t
,...,yn),其中每个y
t
对应着每个单词x
t
的标签;单词的标签一共只有两种l={d,n},分别表示缺失代词和没有缺失代词,将代词缺失的后一个单词位置标注为d,其他单词都标注为n,最终将预测的结果和真实的标签计算损失;
[0081]
step2.2、检测到零代词的位置信息后,根据这个位置信息,挖掘对零代词预测有用的特征:代词在句子中往往会充当重要的句法成分,用作主语、宾语等,而且代词的使用会与句子的其他句法成分息息相关,根据零代词的位置信息,从词汇、句法、上下文方面来提取零代词特征集,零代词特征集包括词汇特征:标签词p、p前后各一个词、p前后各一个代词;句法特征:当前句s的主语、谓语、宾语;上下文特征:上一句s-1的主语和宾语、下一句s+1的主语和宾语;
[0082]
step2.3、进行零代词预测,确定在代词缺失位置具体该补齐哪个代词,把预测出的零代词放入源句子进行零代词补齐从而对汉越数据进行增强:
[0083]
训练一个多分类器,其中每一个类代表着一个可能缺失的代词;使用transformer编码端来对当前句进行表征,与传统transformer编码端不一样的是,增加了一个代词注意力模块,通过挖掘对零代词分类有用的特征,来使输入隐状态更好的表示出零代词信息;零代词注意力模块的k
dp
、v
dp
来自于零代词特征集的编码输入,q
dp
来自于正文多头注意力子层的输出,再将零代词注意力模块的输出进行下一步分类计算;
[0084]hdp
=attention(q
dp
,k
dp
,v
dp
)
ꢀꢀꢀ
(7)
[0085]
其中h
dp
表示零代词注意力模块的输出;
[0086]
在多分类模块,将编码模块的输入隐状态通过一个线性变化,再进行归一化计算,得到最后的分类结果,即零代词预测结果,把预测出的零代词放入源句子进行零代词补齐从而对汉越数据进行增强;
[0087]
y=soft max(σ(hw1+b1)w2+b2)
ꢀꢀꢀ
(8)
[0088]
其中h表示编码端输入隐状态,w1,w2,b1,b2为模型参数,σ为sigmoid函数;
[0089]
最终将预测的结果和真实的标签计算损失;损失函数为:
[0090][0091]
其中n表示训练样例数,c表示类别标签数,表示模型预测类别c的概率。
[0092]
step2.4、最后选择adam优化器,它收敛速度较快且收敛过程较稳定,能基于训练数据迭代地更新神经网络权重。学习率(步长)设置为5e-5,决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度。步长太小,收敛慢,步长太大,会远离最优解。所以从
小到大,分别测试,选出一个最优解5e-5。
[0093]
为了说明本发明的效果,设置了3组对比实验。第一组实验验证代词位置预测模型的有效性,第二组实验验证代词预测模型的有效性,第三组实验验证本发明处理的语料对后期机器翻译任务性能的影响。
[0094]
(1)零代词位置预测对应的零代词位置预测模型的有效性验证
[0095]
本发明针对表2中的训练数据和测试数据,本发明零代词位置预测模型cmt-g&a-1和已有其它模型性能进行测试,测试结果如表3所示:
[0096]
表3零代词位置预测实验对比
[0097][0098]
从表3上可以看出,比较四组常用的序列标注模型实验,在汉语以及越南语的实验中,transformer+crf模型分别取得了90.78%和89.15%的f1值。这说明在序列标注任务上,transforme+crf模型的效果最好。transformer模型的编码端利用注意力机制可以更好的表征输入序列。本发明模型cmt-g&a-1相对于transformer+crf模型,在汉语和越南语任务上分别取得了1.63%和1.65%的提升。这表明融合上下文信息,对标注零代词缺失位置的准确率有一定的提升。表明本发明的有效性。
[0099]
(2)零代词补齐对应的零代词补齐模型有效性验证
[0100]
针对表1中的训练数据和测试数据,本发明零代词补齐模型cmt-g&a结果如表4所示,与前人模型性能对比实验如表5所示:
[0101]
表4零代词补齐质量评估
[0102][0103]
表4显示出,代词位置预测的f1分数在汉语数据集和越南语数据集上分别达到了92.42%和88.21%。然而,在代词预测任务上,f1分数在汉语数据集和越南语数据集上分别只取得69.08%和63.81%。这表明准确预测零代词是一项相当困难的任务。
[0104]
表5汉语零代词补齐与前人实验对比
[0105][0106]
如表5所示,与前人工作相比,cmt-g&a模型在汉语的代词位置预测任务上获得了4%的提升,在代词预测任务上,cmt-g&a模型针对汉语代词预测获得了3%的提升。这说明
使用最新的transformer编码端可以更好的表征输入语句。充分证明了本发明方法对应模型的有效性。
[0107]
(3)数据增强语料机器翻译性能有效性验证
[0108]
即使零代词预测不是非常准确,本发明仍然假设零代词生成模型足够可靠,可以用于端到端机器翻译。为了验证零代词补齐模型与下游任务的适配能力,本发明在30万句对的汉越对话数据集上进行实验。首先将利用上文的零代词补齐模型,将汉越双语的零代词进行补齐,然后分别搭配传统的rnn,lstm,cnn和transformer模型用于机器翻译任务。各模型的性能实验结果对比如表6所示。
[0109]
表6汉越、越汉翻译实验结果对比
[0110][0111]
从表6可以看出,dp模型在于各序列模型组合搭配后,各种方法的性能都有了一定的提升。这说明,补全缺失代词,可以有效提升神经机器翻译性能。比较各种方法的提升,可以发现dp+transformer模型相对而言提升更大,分别在汉越翻译任务和越汉翻译任务上达到了0.51和0.37的bleu值。这说明,transformer模型在机器翻译任务上的性能最好。
[0112]
通过以上实验数据证明了本发明基于零代词补齐的汉越数据增强方法的有效性。本发明包括零代词位置预测和零代词预测两个部分。零代词预测模型利用transformer+crf模型进行序列标注的工作。同时,利用上下文注意力机制来融合上下文信息。零代词预测模型使用transformer编码端,并融合零代词特征集。再进行多分类任务。本发明提出的零代词补齐模型效果优于已有模型。补全零代词后的汉越平行语料在下游机器翻译模型中取得了更好的效果。这说明,针对于非正式文体的汉越平行语料,补全零代词信息,可以恢复语料中缺失的句法成分,提高汉越平行数据的质量,用于后续改善低资源下汉越神经机器翻译的性能。
[0113]
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1