一种精神障碍类磁共振图像初步筛查模型构建方法
1.本发明涉及图像处理技术领域,特别地涉及一种精神障碍类磁共振图像初步筛查模型构建方法。
背景技术:
2.精神障碍是一种严重残疾的常见病,影响着全世界约10-20%的普通人群,在每年发生的8万起自杀事件中占绝大部分。然而,精神障碍患者常常被忽视,人力和财政资源分配的负担比例在精神障碍患者中也远低于其他疾病。在全球范围内,精神卫生支出的中位数占政府卫生支出总额的2.4%,而据估计,精神障碍占伤残调整生命年(total disability-adjusted life-years,dalys)总额的12%,占残疾生活年(years lived with disability,ylds)总额的35%,表明疾病负担与有效分配支出之间存在严重失衡。虽然填补这一空白是具有挑战性的,但用一种最有效的方法检测早期受精神疾病影响的个体和那些临床风险高的个体,是提供早期干预以改善临床结果和预防长期疾病损害的一个有意义的途径。
3.磁共振成像是一种先进的医学成像技术,用于描述大脑的解剖和功能改变,这有助于对精神障碍的临床风险、神经生物学过程和认知概况机制的理解。尽管以前大多数研究的病例/对照比较结果提供了信息,但在帮助个体识别处于临床高风险或已受疾病影响的受试者方面价值有限。然而,这些研究表明,精神疾病患者的大脑mri数据有细微且可测量的变化,以及机器学习(ml)算法在神经成像中的应用,使其能够提取非常微小的信息,以区分精神障碍患者和健康受试者。在过去的深入研究中,精神分裂症患者与健康对照者分类的准确率在60%到100%之间,重度抑郁症患者分类准确率在50%到100%之间,双相情感障碍分类准确率在57%到100%之间。前期研究结果的存在相当大的异质性,因此目前需要新的方法,更广泛的验证和在特定临床环境中的应用,为未来计算机辅助判断(cad) 精神疾病和其他应用带来希望。
4.在传统的ml模型中,最常用的是支持向量机(support vector machine,svm),但其对缺失数据的稳定性和敏感性较低。相比之下,基于深度学习的神经网络保持了传统ml方法的优势,因此cad在精神障碍类疾病学的神经影像学数据中显示出特别的前景。此外,深度学习算法在精确检测医学影像上的细微病灶方面显示出了与专家水平相当甚至超过其准确率的优势。然而,在以往的工作中,深度学习模型是在小数据集和少数患者中训练的。在每种精神障碍的研究中,样本量大多被限制在数百个,当这些参与者被进一步划分为训练和测试数据集时,当外部验证数据集无法获得时,情况变得更糟。这是导致先前研究结果差异的一个关键因素,导致训练模型的准确性较差,或者精度不错但泛化程度较差。因此,建立大规模数据集的cad模型,并在不同的情况下使用外部参考标准进行测试,是在模型能够在真实的临床环境中使用之前必不可少的。
5.至于应用之前训练的ml模型的临床背景,开发一种诊断工具是为了帮助识别受试者是否患有特定的精神疾病(即精神分裂症vs健康对照)或将受试者区分为两种疾病(即精
神分裂症vs双相情感障碍)。值得注意的是,所使用的图像是在研究目的下获得的,通常需要一个小时或更长时间才能获得。然而,在临床实践中,如果花一小时左右的时间扫描一个怀疑患有精神疾病的对象,然后通过将图像导入ml模型来确认诊断是没有意义的,尽管模型的平均准确率为70%-90%,但这实际上比与有经验的治疗精神障碍类疾病医生面谈要花费更多的金钱和时间。因此,目前的重点应从精确性和特异性的诊断精神障碍转向开发一种常用的筛查工具,以识别临床高风险或疾病早期的受试者,并在脆弱人群中开展早期干预。在这方面,应将不同精神障碍的患者作为一个整体来构建模型。这与先前研究提出的发展跨诊断精神障碍类疾病理学筛查方法的概念相一致,因为精神疾病有共同的遗传、影像学和精神障碍类疾病理学表现,它们更像是一个谱系,而不是单独的实体。
技术实现要素:
6.针对上述现有技术中的问题,本技术提出了一种精神障碍类磁共振图像初步筛查模型构建方法,包括以下步骤:
7.步骤s1、对多个受试者进行全脑mri扫描,扫描数据包括t1wi和t2wi,所有受试者的t1wi和t2wi图像均为dicom的数据形式,图像处理均在联影工作站;
8.步骤s2、由神经放射科医生检查所有受试者的图像,以排除有明显脑异常或有图像伪影的受试者;
9.步骤s3、将dicom文件存储格式的数据转换为nifti格式,保存在3d模型图像中;
10.步骤s4、用颅骨剥离工具去除骨体素以消除非组织的影响;
11.步骤s5、通过大脑分割包获得代表大脑半球信息的去颅骨的脑模板,以 t1wi-nii、t2wi-nii及相应的脑模板作为卷积神经网络模型的输入;
12.步骤s6、基于问卷在患者级标记,以弱监督的方式训练分类模型,移除所述分类模型中对图像类别置信分数贡献度低的特征通道及其对应的滤波器,降低模型冗余度,压缩模型的同时保持模型性能;
13.步骤s7、继续以弱监督的方式训练分类模型,并对训练后的分类模型进行检验。
14.优选地,所述分类模型将特征通道作为掩码反作用于输入图像,不同特征通道对正样本图像分类准确度的促进或抑制程度的不同,所述分类模型判别不同特征通道和滤波器的重要性。
15.优选地,压缩模型包括以下步骤:
16.步骤s61:选择任务数据集及待压缩模型;
17.步骤s62:选取正样本图像输入模型,获得各层输出特征图;
18.步骤s63:根据卷积神经网络模型输出的通道重要性置信分数,预设通道重要性置信分数阈值,移除重要程度低于预设通道重要性置信分数阈值的通道重要性置信分数;
19.步骤s64:微调压缩后的卷积神经网络模型,使其恢复精度。
20.优选地,步骤s61包括以下步骤:
21.步骤s611:给定图像分类数据集d和待压缩的卷积神经网络模型,训练一个卷积神经网络分类模型;
22.步骤s612:选取合适的超参数和优化器,迭代地训练分类模型,直到分类模型收敛并在图像分类数据集d上获得较高的分类准确率时,保存训练好的分类模型m。
23.优选地,步骤s62包括以下步骤:
24.步骤s621:从数据集中选取一张图像为ic∈d,其类别标签为c,使其满足: c=argmax(m(ic));
25.步骤s622:将图像ic输入训练好的模型,针对模型的每一层,获得其输出特征图:
[0026][0027]
其中m
l
(
·
)表示模型从第一层到第l层的算子,表示模型的第l层的输出特征图,它有n
l
个通道,空间尺寸为w
l
×hl
;
[0028]
步骤s623:将获得共l个层的特征图构成集合
[0029]
优选地,所述分类模型的训练通过mil方案训练的两阶段方法,包括一个切片级分类器和一个患者级分类器。
[0030]
优选地,所述切片级分类器将三维模型图像分成一系列切片,每个切片完全包含在单个图像中;每个图像来自数据集s={si:i=1,2,
…
,n},给定一个切片策略,组成数据包数据包包含了所有切片;设置每个受试者的切片数为23,作为使用脑模板的mil的袋大小(mi);同时,通过对侧区域比较检测异常的策略,增强对异常脑区的识别,并对是否包含精神障碍类疾病相关异常类别进行分类;使用4个连续的下行块来提取每个切片的特征,其中包括两个卷积层、批处理归一化层、线性整流函数、最大池化层;然后采用全连接层在切片级上利用压缩的特征图生成分类结果。
[0031]
上述技术特征可以各种适合的方式组合或由等效的技术特征来替代,只要能够达到本发明的目的。
[0032]
本发明提供的一种精神障碍类磁共振图像初步筛查模型构建方法,与现有技术相比,至少具备有以下有益效果:1)有效利用以往病历大数据,采用深度学习的方法对大量精神障碍患者磁共振脑成像病例进行数据分析,特征提取和经验学习,为医生提供准确度较高的精神障碍疾病诊断辅助,使精神障碍诊断准确度独立于医生经验。2)极大的提高了诊断速度,可以使患者早发现早治疗,为患者的良好预后提供机会。3)自动化处理水平较高,自动化分析并智能检测精神障碍患者,可以极大地降低操作人员工作量。4)有效降低卷积神经网络部署所需的存储和内存空间、硬件算力等资源,扩大了卷积神经网络的应用平台范围。5)压缩后的模型可以直接应用于现有的软件平台和硬件设备中,简单方便,不需要特殊的平台和算法的支持。6)很好地利用了模型自身的特性,可解释性好,无需引入新的判别参数重要性的假设和标准。
附图说明
[0033]
在下文中将基于实施例并参考附图来对本发明进行更详细的描述。其中:
[0034]
图1显示了本发明的mil方案训练示意图;
[0035]
图2显示了本发明的模型参数移除操作示意图;
[0036]
在附图中,相同的部件使用相同的附图标记。附图并未按照实际的比例。
具体实施方式
[0037]
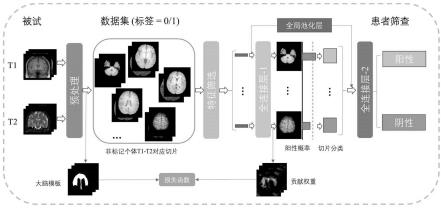
考虑到现有技术,在当前的研究中,我们采用基于多实例学习(mil)的方法来训练
和测试cad模型,对大样本回顾性数据,对象为回顾性招募的14915名不同精神障碍患者和4538名健康对照组。另一个数据集有290名精神障碍患者和310名来自另一个独立中心的健康对照组,用于验证诊断性能和测试所建立模型的泛化性。为了进一步检验所建立的cad模型在现实生活中的效用,在一项前瞻性研究中,我们收集了另外148名被试,他们都是医学院的大学生,据研究发现他们的精神疾病的患病率普遍较高。在这一部分中,每个参与者都获得了大脑mri扫描、自评量表以及与经验丰富的治疗精神障碍类疾病医生的诊断访谈的数据。
[0038]
下面将结合附图对本发明作进一步说明。
[0039]
本发明提供了一种精神障碍类磁共振图像初步筛查模型构建方法,所有受试者均进行临床全脑mri扫描,由经验丰富的神经放射科医生检查所有参与者的图像,以排除有明显脑异常或有图像伪影的参与者。
[0040]
所有受试者的全脑mri扫描图像为dicom的数据形式,图像处理均在联影工作站。首先,由于dicom的文件存储格式对机器学习不友好,我们将其转换为nifti(.nii)格式,将医疗数据保存在3d模型图像中。然后用颅骨剥离工具去除骨体素以消除非组织的影响。最后,我们通过大脑分割包获得代表大脑半球信息的去颅骨的脑模板,以t1wi-nii、t2wi-nii及相应的脑模板作为模型的输入,基于问卷在患者级标记,以弱监督的方式训练分类模型。
[0041]
现有的卷积神经网络模型因参数量庞大而对应用的软硬件平台的存储和内存空间、算力等资源要求高,不能被广泛地应用于资源受限的平台。为了有效降低模型的资源消耗量,拓宽卷积神经网络模型的应用范围。本发明根据卷积神经网络过剩的预设编码空间导致模型参数冗余的原理,利用卷积神经网络提取的特征通道对图像类别置信分数贡献度不同的特点,通过将特征通道作为掩码反作用于输入图像,根据不同特征通道对正样本图像分类准确度的促进或抑制程度的不同,利用模型判别不同特征通道和滤波器的重要性。采取移除对图像类别置信分数贡献度低的特征通道及其对应的滤波器的方式,降低模型冗余度,达到压缩模型的同时尽可能保持模型性能的目的。处理步骤具体分为:
[0042]
步骤1:选择任务数据集及待压缩模型。给定图像分类数据集d和待压缩的卷积神经网络模型,训练一个卷积神经网络分类模型。选取合适的超参数和优化器,迭代地训练分类模型,直到模型收敛并在图像分类数据集d上获得较高的分类准确率时,保存训练好的分类模型m。
[0043]
步骤2:选取正样本图像输入模型,获得各层输出特征图。由于训练好的卷积神经网络具有对图像类别特征编码的能力,其对数据集中正样本的特征编码具有更高的准确度,这些编码以特征图的形式存在于分类模型各层的输出中。
[0044]
设从数据集中选取一张图像为ic∈d,其类别标签为c,使其满足:
[0045]
c=argmax(m(ic))
[0046]
即分类模型对图像ic的预测类别就是它的真实类别,我们将这样的图像ic称为正样本图像。将图像ic输入训练好的分类模型,针对分类模型的每一层,获得其输出特征图:
[0047][0048]
其中m
l
(
·
)表示分类模型从第一层到第l层的算子,表示分类模型的第l层的输出特征图,它有n
l
个通道,空间尺寸为w
l
×hl
。将获得共l个层的特征图构成集
合
[0049]
步骤3:根据分类模型输出的通道重要性置信分数,移除重要程度低的参数。分类模型对图像的特征编码由多个通道组合而成,由于预设的通道数过多导致编码空间过剩,因而造成分类模型参数冗余。然而,特征编码的不同通道由不同功能的滤波器提取图像特征生成,这些通道中编码的不同特征对分类模型输出的图像类别置信分数的贡献度是不同的。本发明利用这一特点移除分类模型中对图像类别置信分数贡献低的部分特征通道及提取这些特征的相应滤波器,通过减小编码空间的方式降低模型冗余。
[0050]
本发明将不同的特征图通道作为输入图像的掩码,将其覆盖在输入图像上。若一个特征通道对图像类别置信分数的贡献度大,那么其作用在图像上会突出对分类有促进作用的特征,使得模型在该类别的预测置信分数上有较大的值;反之,若一个通道对图像类别置信分数的贡献度小,其作用后的图像则会降低模型对该类别的置信分数。由此确定不同特征通道及其滤波器的重要程度。
[0051]
给定各层的剪枝率p
l
=[p1,p2,
…
,p
l
],其中p
l
∈[0,1)表示预设的第l层要移除的通道和滤波器的比例。对于l=1,2,
…
,l,逐层迭代地执行如下过程:
[0052]
(1)获取第l层的特征图以及图像ic,利用插值算法将特征图上采样至其空间维度和ic相同:
[0053][0054]
其中upsample(
·
)表示插值上采样算子,表示上采样得到的特征图。
[0055]
(2)将特征图按通道维度展开成一个集合并将集合 a
l
的每个元素作为图像掩码与图像ic逐元素相乘,得到由第l层的特征图覆盖后的图像集合s
l
:
[0056][0057]
其中
⊙
表示矩阵逐元素相乘。
[0058]
(3)将s
l
中的所有元素分批次输入到模型m中,得到它们对应的类别置信分数在第c类的值:
[0059][0060]
其中为输入模型后,模型输出的类别置信分数在第c类的值,yc是第l层得到的所有n
l
个值的集合。
[0061]
(4)获取第l层的剪枝率p
l
,将yc中的元素按从小到大的顺序排序,选择其中的前n
l
=n
l
p
l
个元素对应的下标索引序列。在模型f中,删除第l层中这些索引对应的的滤波器、第l+1层中这些索引对应的滤波器通道。本发明实施例中的模型参数移除操作如图2所示,其中矩形表示不同的特征通道,每行并列的菱形表示多个通道的滤波器,用“叉”号标记的是被模型判别为低重要程度的通道和滤波器,它们将被移除出模型。
[0062]
步骤4:微调压缩后的模型,使其恢复精度。由于删除了模型中部分冗余的参数,导致模型在数据集d上的分类准确度有一定程度的下降。为了恢复模型准确度,需要将压缩后的模型再进行一定轮次的迭代训练,训练时适度降低学习率,直到模型收敛,此时模型的准确率得以恢复。保存此时的模型,即为被压缩的模型。
[0063]
为了充分利用现有的数据,由经验丰富的治疗精神障碍类疾病医生基于问卷在患者级标记,以弱监督的方式训练分类模型。更具体地说,患者级诊断对特定3d模型图像中的所有切片进行弱标记。该方法是一种通过mil方案训练的两阶段方法,包括一个切片级分类器,然后是一个患者级分类器,如图1所示。
[0064]
mil是标准监督机器学习场景的变体。在mi学习中,每个例子由一个多实例集(包)组成。每个包都有一个类标签,但是实例本身没有标记。这个学习是基于给定的示例包建立一个模型,可以准确预测其他数据集的分类标签。
[0065]
将三维模型图像分成一系列切片(224
×
320像素),每个切片完全包含在单个图像中。每个图像来自我们的数据集s={si:i=1,2,
…
,n}可以看作是由实例集合组成的一个包。给定一个切片策略,我们也组成数据包成的一个包。给定一个切片策略,我们也组成数据包这个数据包是包含了所有切片。在这项工作中,我们设置每个受试者的切片数为23,作为使用脑模板的mil的袋大小(mi),它是由所有受试者在训练集中的最大厚度推导出来的。同时,通过对侧区域比较检测异常的策略,增强了对异常脑区的识别,并对是否包含精神障碍类疾病相关异常类别进行分类。在这一部分中,我们使用4个连续的下行块来提取每个切片的特征,其中包括两个卷积层,批处理归一化层和线性整流函数,然后是最大池化层。然后采用全连接层在切片级上利用压缩的特征图生成(正/负)分类结果。
[0066]
根据mil假设,我们知道,如果受试者是患者,那么在一个数据袋里至少有一片切片被认为是阳性。相反,如果受试者是正常被试,它所有切片也必须是阴性的。给定一个数据袋中的被试图像si,mi层数尽可能的根据它们的正概率进行详尽的分类和排名。如果一个袋子是阳性的,排名靠前的切片的概率应该超过0.5。同样,如果它是负的,上面的值应该低于0.5。我们认为是si的可能性,所以可能性为:从上一个模块中,我们获得了袋子中每一片的特征图和类。然后,我们根据上述规则使用分类器对包内的个体进行诊断。
[0067]
在本工作中,损失函数是由交叉熵损失和注意损失组成的。这被定义为交叉熵损失用来测量两种概率分布的不同,定义为其中代表是si的分类。我们利用交叉熵损失去限制接近于来优化我们的网络参数。此外,注意力损失被定义为外,注意力损失被定义为其中fc
cam
表示全连接层的类激活映射,将网络注意力集中在脑组织上。
[0068]
由于我们的数据集1中的p/n类的比例远离1,且有多种设备类型,我们采用了一种策略来平衡这个问题,以减少无用信息的影响。首先,我们计算所有装备中每种类别的最小数量n=min{n
(k,c)
|k=1,2,3,4,5;c=0,1},其中k为设备类型, c为受试者的标签。然后,我们以n为标准,在训练处理过程中对每种设备的每个时间点的每个标签上的数据进行采样。换句话说,通过上述操作,我们在不平衡的数据集1中,实现了标签(p/n)和设备类型的平衡。
[0069]
在测试时,每个受试者的测试数据集(包括数据集1和数据集2)的所有切片都被输入到训练好的网络中。取一个阈值(我们选择0.5),如果至少有一个切片是正的,则认为整个图像是正的。如果所有的切片都是负的,那么图像就是负的。
[0070]
在一个实施例中,临床全脑mri扫描信号,包括t1wi和t2wi。
[0071]
在一个实施例中,在所有数据都是层厚大于6mm的情况下,切片之间的相关性几乎是不可见的。相对于对gpu内存要求较高的3d patch和x、y、z不同倍数的下采样,2d slice对内存的要求更低,每次迭代都可以将整个slice送入网络,使得每个slice的全局信息能够被合理的消耗。因此,我们在医学图像领域中选择基于切片而不是普通的3d patch来训练我们的模型,获取精神障碍的特征。
[0072]
在一个实施例中,此外,我们将数据集1按照标签和厂商的比例,以8:2的比例打乱顺序并分为训练集和测试集,以保持训练集和测试集的分布一致。测试集是用于评估训练模型的图像集,数据集在训练过程中从未使用过。
[0073]
虽然在本文中参照了特定的实施方式来描述本发明,但是应该理解的是,这些实施例仅仅是本发明的原理和应用的示例。因此应该理解的是,可以对示例性的实施例进行许多修改,并且可以设计出其他的布置,只要不偏离所附权利要求所限定的本发明的精神和范围。应该理解的是,可以通过不同于原始权利要求所描述的方式来结合不同的从属权利要求和本文中所述的特征。还可以理解的是,结合单独实施例所描述的特征可以使用在其他所述实施例中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1