一种基于渐进式候选框高亮的检测方法、设备和介质
1.本发明涉及一种基于渐进式候选框高亮的检测方法,属于图像识别技术领域。
背景技术:
2.计算机视觉是通过计算机对一些视觉目标如图像、视频进行识别和分析,从而辅助或代替人类视觉系统进行工作,以减轻人类获取和处理这些视觉信息的工作量的一种技术。
3.目前,用于视觉目标检测的方法,发展出了两个分支,一个是卷积神经网络,一个是基于transformer的网络。
4.基于卷积神经网络的检测器会充分利用局部区域的特征,但是在捕捉与远距离对象之间的语义依赖会遇到困难;基于transformer的目标检测器擅长捕捉远距离对象之间的语义依赖,但是会恶化局部特征的细节。
5.因此,有必要研究一种检测方法,以解决上述问题。
技术实现要素:
6.为了克服上述问题,本发明人进行了深入研究,提出了一种基于渐进式候选框高亮的检测方法,通过将卷积神经网络和基于transformer的网络的两个框架特征合理地同时利用和融合,使得检测器既可以充分吸收局部特征细节,也可以擅长捕捉远距离对象之间的语义依赖,实现了良好的检测效果。
7.具体地,本发明公开了一种基于渐进式候选框高亮的检测方法,将图像输入检测器中,通过检测器识别图像中目标,获得目标在图像中位置。
8.进一步地,所述检测器通过以下步骤进行图像中目标位置的识别:
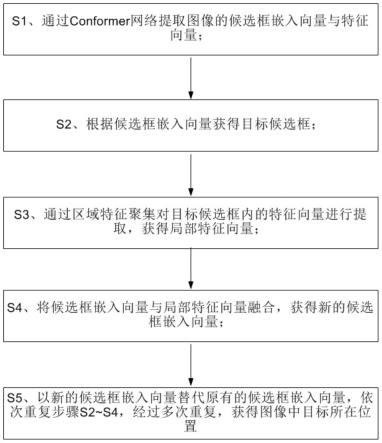
9.s1、通过conformer网络提取图像的候选框嵌入向量与特征向量;
10.s2、根据候选框嵌入向量获得目标候选框;
11.s3、通过区域特征聚集对目标候选框内的特征向量进行提取,获得局部特征向量;
12.s4、将候选框嵌入向量与局部特征向量融合,获得新的候选框嵌入向量;
13.s5、以新的候选框嵌入向量替代原有的候选框嵌入向量,依次重复步骤s2~s4,经过多次重复,获得图像中目标所在位置,所述位置通过最后一次获得的目标候选框标示出来。
14.进一步地,所述目标候选框包括分类分数和边界框,
15.所述分类分数用于表示候选框内存在目标的概率,所述边界框用于表示候选框的边界范围。
16.优选地,在s2中,通过感知层对初始目标边界框进行修正,获得目标边界框,所述初始目标边界框由conformer网络生成。
17.优选地,所述感知层的参数为利用候选框嵌入向量,通过最小化匹配损失法训练获得,包括以下步骤:
18.s21、将候选框嵌入向量输入线性层获得预测分类分数;
19.s22、通过将候选框嵌入向量输入感知层得到边界框偏移量,通过边界框偏移量对初始目标边界框进行修正,获得预测边界框;
20.s23、预测边界框与预测分类分数组合成预测集合r,将预测集合r与真值目标集合进行匹配,通过最小化匹配损失更新并获得感知层的参数。
21.优选地,s23中,通过匈牙利法实现最小化匹配损失,其中匹配的损失函数为分类损失函数、目标定位l1损失函数和giou损失函数的加权和;
22.分类损失函数表征预测分类分数与真值目标分类分数的损失;目标定位l1损失函数和giou损失函数表征预测边界框与真值目标边界框的损失。
23.优选地,在s3中,通过roialign方法对特征向量进行提取,获得局部特征向量。
24.优选地,在s4中,所述融合包括以下子步骤:
25.s41、通过线性层将候选框嵌入向量增强至i个,形成嵌入向量集;
26.s42、将候选框嵌入向量集和局部特征向量通过交叉注意力方法进行增强,获得增强特征向量;
27.s43、将增强特征向量输入卷积层,获得新的候选框嵌入向量。
28.优选地,在s42中,所述交叉注意力方法可以表示为:
[0029][0030]
其中,为增强特征向量,fi为局部特征向量,为嵌入向量集,θq、θk、θv为线性转换层参数,c表示特征向量的维度,h
′
为超参数,上标
t
表示转置。
[0031]
本发明还提供了一种电子设备,包括:
[0032]
至少一个处理器;以及
[0033]
与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述任一项所述的方法。
[0034]
本发明还提供了一种存储有计算机指令的计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行上述任一项所述的方法。
[0035]
本发明所具有的有益效果包括:
[0036]
(1)在目标候选框预测和在可学习的迭代优化框架中增强了目标特征;
[0037]
(2)通过交叉注意力方法,融合了稀疏的transformer嵌入向量和密集的卷积神经网络局部特征,有效地增强了嵌入向量的表征能力,显著提高了检测的准确性。
附图说明
[0038]
图1示出根据本发明一种优选实施方式的基于渐进式候选框高亮的检测方法中检测器识别目标位置的方法示意图。
具体实施方式
[0039]
下面通过附图和实施例对本发明进一步详细说明。通过这些说明,本发明的特点和优点将变得更为清楚明确。
[0040]
在这里专用的词“示例性”意为“用作例子、实施例或说明性”。这里作为“示例性”所说明的任何实施例不必解释为优于或好于其它实施例。尽管在附图中示出了实施例的各种方面,但是除非特别指出,不必按比例绘制附图。
[0041]
本发明提供了一种基于渐进式候选框高亮的检测方法,将图像输入检测器中,通过检测器识别图像中目标,获得目标在图像中位置。本发明所述的检测方法,能够同时兼顾并高效关注目标的纹理细节和远距离语义依赖,有效地解决了基于卷积神经网络的检测器无法捕获远距离语义依赖以及基于transformer的检测器丢失局部细节的缺点。
[0042]
具体地,本发明中所述的检测器通过以下步骤进行图像中目标位置的识别:
[0043]
s1、通过conformer网络提取图像的候选框嵌入向量与特征向量;
[0044]
s2、根据候选框嵌入向量获得目标候选框;
[0045]
s3、通过区域特征聚集对目标候选框内的特征向量进行提取,获得局部特征向量;
[0046]
s4、将候选框嵌入向量与局部特征向量融合,获得新的候选框嵌入向量;
[0047]
s5、以新的候选框嵌入向量替代原有的候选框嵌入向量,依次重复步骤s2~s4,经过多次重复,获得图像中目标所在位置,所述位置通过最后一次获得的目标候选框标示出来。
[0048]
在s1中,所述conformer网络是2020年提出的一种网络模型,在conformer网络中,具有transformer分支和卷积神经网络分支,具体conformer网络的结构可参见论文gulati,anmol,et al.'conformer:convolution-augmented transformer for speech recognition.'arxiv preprint arxiv:2005.08100(2020).,在本发明中不做赘述。
[0049]
在本发明中,所述conformer网络可以是原始conformer网络,也可以是其任意一种变种,例如conformer-s网络。
[0050]
进一步地,在transformer分支中,图像中每个目标区域可以表示为一个候选框嵌入向量则每张图像的候选框嵌入向量表示为其中i表示不同的候选框嵌入向量,n表示每张图像中候选框嵌入向量的总数,表示实数集,c为向量的维度。
[0051]
进一步地,在本发明中,所述目标候选框包括分类分数和边界框,
[0052]
所述分类分数用于表示候选框内存在目标的概率,所述边界框用于表示候选框的边界范围。
[0053]
在conformer网络中,可以对输入的图像进行识别,输出目标边界框,在s2中,将conformer网络生成的目标边界框称之为初始边界框,对初始边界框进行修正,加强其定位的准确性。
[0054]
进一步地,在本发明中,将初始边界框表示为bi表示边界框,b
0i
={x
0i
,y
0i
,w
0i
,h
0i
},{x,y}为目标候选框中心坐标,{w,h}为宽度和高度。
[0055]
具体地,通过感知层对初始目标边界框进行修正,获得目标边界框,所述初始目标边界框由conformer网络生成。
[0056]
进一步地,所述感知层的参数为利用候选框嵌入向量,通过最小化匹配损失法训练获得,包括以下步骤:
[0057]
s21、将候选框嵌入向量ei输入线性层获得预测分类分数si;
[0058]
s22、通过将候选框嵌入向量输入感知层得到边界框偏移量,通过边界框偏移量对初始目标边界框进行修正,获得预测边界框;
[0059]
s23、预测边界框与预测分类分数组合成预测集合r,将预测集合r与真值目标集合进行匹配,通过最小化匹配损失更新并获得感知层的参数。
[0060]
线性层、感知层均为神经网络中常用的层结构,在本发明中对其具体结构组成不做赘述。
[0061]
在s21中,将图像中每个候选框嵌入向量均输入线性层获得对应的预测分类分数si;
[0062]
在s22中,所述感知层为3层,感知层的激活函数设置为relu函数,候选框嵌入向量ei通过感知层得到边界框偏移量δbi={δxi,δyi,δwi,δhi},通过边界框偏移量对初始目标边界框进行修正,获得预测边界框其中其中
[0063]
进一步地,将预测边界框与预测分类分数si可以组合成预测集合将预测集合与真值目标集合进行匹配。
[0064]
所述真值目标集合表示为其中gk为真值边界框,yk为第k个目标的独热标签。
[0065]
在一个优选的实施方式中,s23中,利用二分图匹配策略将预测集合r与真值目标集合g进行匹配。
[0066]
更优选地,采用二分图中的匈牙利法进行匹配,通过匈牙利法实现最小化匹配损失,其中匹配的损失函数为分类损失函数、目标定位l1损失函数和giou损失函数的加权和;
[0067]
分类损失函数表征预测分类分数与真值目标分类分数的损失;目标定位l1损失函数和giou损失函数表征预测边界框与真值目标边界框的损失。
[0068]
优选地,分类损失函数权重为1~3,更优选为2;目标定位l1损失函数的权重为4~6,更优选为5;giou损失函数的权重为1~2,更优选为1,上述权重为发明人根据经验总结获得,能够显著提高匹配精度。
[0069]
优选地,分类损失函数为focal loss函数,目标定位l1损失函数为l1 loss函数,giou损失函数为giou loss函数。
[0070]
进一步地,负样本预测边界框只计算分类损失函数。
[0071]
根据本发明,在上述损失函数的监督下,训练迭代中通过随机梯度下降法来更新网络参数。
[0072]
在s2中,候选框嵌入向量会在候选框预测损失函数的监督下学习预测候选区域,增强了目标特征。
[0073]
在一个优选的实施方式中,在s3中,通过roialign方法对特征向量进行提取,获得局部特征向量。
[0074]
在本发明中,将局部特征向量表示为fi,局部特征向量的集合表示为n、c与候选框嵌入向量中的n、c参数意义一致,s=14,表征特征向量的长和宽。
[0075]
优选地,在s4中,所述融合包括以下子步骤:
[0076]
s41、通过线性层将候选框嵌入向量增强至i个,形成嵌入向量集;
[0077]
s42、将候选框嵌入向量集和局部特征向量通过交叉注意力方法进行增强,获得增强特征向量;
[0078]
s43、将增强特征向量输入卷积层,获得新的候选框嵌入向量。
[0079]
在s41中,增强后的i个候选框嵌入向量中每一个均与原候选框嵌入向量相同,嵌入向量集可以表示为:
[0080]
在s42中,所述交叉注意力方法可以表示为:
[0081][0082]
其中,为增强特征向量,fi为局部特征向量,为嵌入向量集,θq、θk、θv为线性转换层参数,c表示特征向量的维度,h
′
为超参数,优选设置为8,上标
t
表示转置。
[0083]
在本发明中,通过交叉注意力方法,实现了卷积层输出量与嵌入向量的融合,进而增强了嵌入向量的表征能力,显著提高了检测的准确性。
[0084]
通过s4,融合transformer的候选框嵌入向量和密集的卷积神经网络局部特征,加强了候选框的可辨别性和定位的准确性。
[0085]
在s5中,优选地,所述多次重复为3~8次重复,更优选为6次重复。
[0086]
由于融合后得到的新的候选框嵌入向量包含了局部细节和远距离语义依赖,有效地在上下文高亮了候选框,通过多次重复,实现了候选框预测和目标特征加强的交替迭代,从而使得目标特征逐渐地高亮,目标位置逐渐地完善。
[0087]
本发明中以上描述的方法的各种实施方式可以在数字电子电路系统、集成电路系统、场可编程门阵列(fpga)、专用集成电路(asic)、专用标准产品(assp)、芯片上系统的系统(soc)、负载可编程逻辑设备(cpld)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。
[0088]
用于实施本发明的方法的程序代码可以采用一个或多个编程语言的任何组合来编写。这些程序代码可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器或控制器,使得程序代码当由处理器或控制器执行时使流程图和/或框图中所规定的功能/操作被实施。程序代码可以完全在机器上执行、部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。
[0089]
在本发明的上下文中,机器可读介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的程序。机器可读介质可以是机器可读信号介质或机器可读储存介质。机器可读介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的、或半导体系统、装置或设备,或者上述内容的任何合适组合。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom
或快闪存储器)、光纤、便捷式紧凑盘只读存储器(cd-rom)、光学储存设备、磁储存设备、或上述内容的任何合适组合。
[0090]
为了提供与用户的交互,可以在计算机上实施此处描述的方法和装置,该计算机具有:用于向用户显示信息的显示装置(例如,crt(阴极射线管)或者lcd(液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入或者、触觉输入)来接收来自用户的输入。
[0091]
可以将此处描述的方法和装置实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:局域网(lan)、广域网(wan)和互联网。
[0092]
计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。服务器可以是云服务器,又称为云计算服务器或云主机,是云计算服务体系中的一项主机产品,以解决了传统物理主机与v p s服务("virtual private server",或简称"vps")中,存在的管理难度大,业务扩展性弱的缺陷。服务器也可以为分布式系统的服务器,或者是结合了区块链的服务器。
[0093]
应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本发公开中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本发明公开的技术方案所期望的结果,本文在此不进行限制。
[0094]
实施例
[0095]
实施例1
[0096]
设置仿真实验,在mscoco和crowdhuman数据集上对检测器进行评估,观察检测器对图像中目标所在位置进行识别的效果。
[0097]
其中mscoco数据集是一个大型的、丰富的物体检测,分割和字幕数据集,这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定,图像包括80个类,训练集包含了118k张图片,验证集包含了5k张图片,测试集包含了20k张图片;crowdhuman是专门提供给拥挤场景的行人检测,特征之间的语义依赖对提升检测性能来说是尤其关键,训练集15k张图片,测试集5k张图片,验证集4370张图片。
[0098]
检测器通过以下步骤进行图像中目标位置的识别:
[0099]
s1、通过conformer网络提取图像的候选框嵌入向量与特征向量;
[0100]
s2、根据候选框嵌入向量获得目标候选框;
[0101]
s3、通过区域特征聚集对目标候选框内的特征向量进行提取,获得局部特征向量;
[0102]
s4、将候选框嵌入向量与局部特征向量融合,获得新的候选框嵌入向量;
[0103]
s5、以新的候选框嵌入向量替代原有的候选框嵌入向量,依次重复步骤s2~s4,经过多次重复,获得图像中目标所在位置。
[0104]
在s2中,通过感知层对初始目标边界框进行修正,获得目标边界框,所述初始目标边界框由conformer网络生成,感知层为3层,感知层的激活函数设置为relu函数,所述感知层的参数为利用候选框嵌入向量,通过最小化匹配损失法训练获得,包括以下步骤:
[0105]
s21、将候选框嵌入向量输入线性层获得预测分类分数;
[0106]
s22、通过将候选框嵌入向量输入感知层得到边界框偏移量,通过边界框偏移量对初始目标边界框进行修正,获得预测边界框;
[0107]
s23、预测边界框与预测分类分数组合成预测集合r,将预测集合r与真值目标集合进行匹配,通过最小化匹配损失更新并获得感知层的参数。
[0108]
进一步地,通过匈牙利法实现最小化匹配损失,其中匹配的损失函数为分类损失函数、目标定位l1损失函数和giou损失函数的加权和;
[0109]
其中,分类损失函数权重为2;l1损失函数的权重为5;giou损失函数的权重为1。在s3中,通过roialign方法对特征向量进行提取,获得局部特征向量。
[0110]
在s4中,所述融合包括以下子步骤:
[0111]
s41、通过线性层将候选框嵌入向量增强至i个,形成嵌入向量集;
[0112]
s42、将候选框嵌入向量集和局部特征向量通过交叉注意力方法进行增强,获得增强特征向量;
[0113]
s43、将增强特征向量输入卷积层,获得新的候选框嵌入向量。
[0114]
在s42中,所述交叉注意力方法为:
[0115][0116]
其中,h
′
=8。
[0117]
在s5中,共重复6次。对检测器的识别结果采用ap(average precision)指标来进行性能评测,ap具体方法参考文献mark everingham,luc van gool,christopher k.i.williams,john m.winn,and andrew zisserman.the pascal visual object classes(voc)challenge.int.j.comput.vis.,pages 303
–
338,2010.
[0118]
对比例1
[0119]
设置仿真实验,在mscoco和crowdhuman数据集上采用sparse r-cnn对图像中目标位置进行识别,sparse r-cnn的具体方法可参考文献“peize sun,rufeng zhang,yi jiang,tao kong,chenfeng xu,wei zhan,masayoshi tomizuka,lei li,zehuan yuan,changhu wang,and ping luo.sparse r-cnn:end-to-end object detection with learnable proposals.in ieee cvpr,pages 14454
–
14463,2021.”。
[0120]
对比例2
[0121]
设置仿真实验,在mscoco和crowdhuman数据集上采用vidt对图像中目标位置进行识别,vidt的具体方法可参考文献“hwanjun song,deqing sun,sanghyuk chun,varun jampani,dongyoon han,byeongho heo,wonjae kim,and ming-hsuan yang.vidt:an efficient and effective fully transformer-based object detector.arxiv preprint arxiv:2110.03921,2021”。
[0122]
对比例3
[0123]
设置仿真实验,在mscoco和crowdhuman数据集上采用efficientdet对图像中目标位置进行识别,efficientdet的具体方法可参考文献“mingxing tan,ruoming pang,and quoc v.le.efficientdet:scalable and efficient object detection.in ieee cvpr,pages 10778
–
10787,2020.”。
[0124]
对比例4
[0125]
设置仿真实验,在mscoco和crowdhuman数据集上采用deformerable detr对图像中目标位置进行识别,deformerable detr的具体方法可参考文献“xizhou zhu,weijie su,lewei lu,bin li,xiaogang wang,and jifeng dai.deformable detr:deformable transformers for end-to-end object detection.in iclr,2021.”[0126]
对比例5
[0127]
设置仿真实验,在mscoco和crowdhuman数据集上采用dyhead对图像中目标位置进行识别,dyhead的具体方法可参考文献“xiyang dai,yinpeng chen,bin xiao,dongdong chen,mengchen liu,lu yuan,and lei zhang.dynamic head:unifying object detection heads with attentions.in ieee cvpr,pages7373
–
7382,2021.”。
[0128]
实验例
[0129]
比对实施例1、对比例1~5在数据集中的测试性能,结果如表1~3所示,其中表1为在mscoco验证集的测试性能结果,表2为在mscoco测试集的测试性能结果,表3为在crowdhuman数据集的测试性能结果。
[0130]
表1在mscoco验证集的测试性能结果
[0131]
方法apsparse r-cnn(对比例1)47.9vidt(对比例2)49.2实施例150.1
[0132]
表2在mscoco测试集的测试性能结果
[0133]
方法apefficientdet(对比例3)52.2deformerable detr(对比例4)52.3dyhead(对比例5)52.3实施例152.5
[0134]
表3在crowdhuman数据集的测试性能结果
[0135]
方法apdeformable detr(对比例4)86.7sparse r-cnn(对比例1)89.2实施例189.4
[0136]
从表1中可以看出,实施例1相对于目前先进的检测器vidt来说,性能提升了0.9%;相比sparse r-cnn具有显著的提升,性能高出1.3%,这不仅验证了cnn局部特征和transformer表征相融合的合理性,还验证了候选框预测和目标特征增强的迭代优化策略
的有效性。
[0137]
表2中,在mscoco的test分支上,与目前先进的检测器state-of-the-art类检测器进行比较,实施例1实现了52.5%ap,与目前先进的检测器报告的检测性能相当。
[0138]
从表3中可以看出,实施例1实现了89.4%ap,比基于transformer的方法(对比例4)高出了2.7%,说明实施例1中的方法在复杂场景中的潜力较高,在拥挤的场景中,说明通过远距离语义依赖功能强调了被遮挡的或比较小的目标。
[0139]
以上结合了优选的实施方式对本发明进行了说明,不过这些实施方式仅是范例性的,仅起到说明性的作用。在此基础上,可以对本发明进行多种替换和改进,这些均落入本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1