基于堆叠泊松自编码器网络的计数数据软测量建模方法
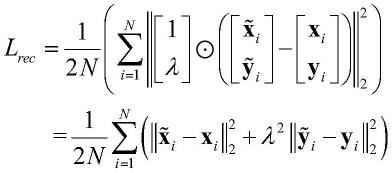
1.本发明属于工业过程预测及软测量领域,涉及一种基于堆叠泊松自编码器网络的计数数据软测量建模方法。
背景技术:
2.计数数据作为一种重要数据类型,其具有离散、非负整数、高偏斜分布等特点,有必要建立离散计数数据模型,即建立某一事件发生次数(称为因变量、输出变量或响应变量)与引起其发生的因素(称为自变量、输入变量或过程变量)之间的联系,以预报事件的发生次数。
3.在过程工业中,软测量作为一种工具,可以用来预测产品质量或其他重要变量,可以考虑用来对计数数据建模处理。基于数据驱动的软测量建模方法常见的是多元线性回归(mlr)和偏最小二乘(pls)回归。它们假设响应变量服从正态和同方差分布,这与观测到的计数数据高度过分散分布相违背。此外计数数据是非负整数,但mlr和pls可能会使因变量产生负值。而非线性建模方法如支持向量回归(svr)和人工神经网络(ann)方法存在较差的可解释性的缺点,同时不能保证预测的非负性。
4.针对计数数据,泊松回归模型是其建模的典型代表。但是工业流程中,过程数据存在高维、非线性等特征,泊松回归用于工业过程时有着数据特征挖掘不充分的问题。因此,提取过程数据的深度特征是计数数据软测量建模至关重要的步骤。
5.自编码器结构作为其典型代表,已被设计并广泛应用于复杂工业过程。但是传统自编码器的预训练都是采用无监督的学习方式,通过对输入的重构并约束误差最小化来学习有效的特征表示,因此从深度网络中所提取的特征可能与计数数据软测量的预测输出并无关系,使得这部分过程显得低效。
6.对工业过程的计数数据进行预测时,由于过程变量可能较多,同时数据存在非线性、高维等特点,因此在建立计数数据软测量模型时,提取出与计数数据类型质量变量具有高度相关性的特征是十分有必要的。针对上述特征提取阶段存在的问题,如果能够设计合理的方式去引入质量变量对于提取输入数据的特征进行有效指导,同时还能考虑计数数据的特性,那么这个问题可以迎刃而解。
技术实现要素:
7.针对常规自编码器不能提取质量变量相关特征的问题,同时考虑计数数据的离散、非负与高偏斜特性,本发明提出一种基于堆叠泊松自编码器网络的计数数据软测量建模方法。本发明方法在预训练的解码阶段引入计数型质量变量来指导特征提取,通过泊松网络层将计数型质量变量集成到深度堆叠编码器结构中,使得模型学习到的特征表示与计数型的质量变量高度相关,提升了特征提取效率,并且提升了计数型质量变量的预测效果。
8.本发明的具体技术方案如下:
9.一种基于堆叠泊松自编码器网络的计数数据软测量建模方法,该方法包括如下步
骤:
10.s1:收集建模用的输入输出训练数据集:其中,x代表输入变量,y代表离散计数数据类型的输出变量,n表示数据样本个数;
11.s2:构建堆叠泊松自编码器网络,所述堆叠泊松自编码器网络由多个监督泊松自编码器分层堆叠而成,前一个监督泊松自编码器的隐藏层的输出作为下一个监督泊松自编码器的输入层的输入;所述监督泊松自编码器包括一个输入层、一个隐藏层和一个输出层,从隐藏层到输出层包含输入重构网络层和泊松网络层,所述输入重构网络层用于对输入向量进行重构,所述泊松网络层用于对计数型质量数据进行预测;
12.随机初始化堆叠泊松自编码器网络的泊松网络权重、神经网络连接权重及偏置参数。
13.s3:将训练数据输入给堆叠泊松自编码器网络,根据最小化损失函数训练第一个监督泊松自编码器,获得第一个监督泊松自编码器的权重和偏置参数和隐藏层的输出将h1作为第二个监督泊松自编码器的输入层的输入,根据最小化损失函数训练第二个监督泊松自编码器,获得对应的权重和偏置参数,以此层层递进,使用h
k-1
,根据训练第k个监督泊松自编码器spaek获得参数和hk,直到最后一个监督泊松自编码器训练完成;k≤l,其中,l为监督泊松自编码器的数量;
14.s4:结束s3的逐层训练后,在第l个监督泊松自编码器的隐藏层的输出h
l
和输出变量y之间建立泊松网络进行回归,根据预测误差对回归网络参数进行调整更新;回归网络训练结束并保存堆叠泊松自编码器网络;
15.s5:将待预测输入数据输入到保存的堆叠泊松自编码器网络,经过堆叠泊松自编码器网络的前向传播即可得到计数型质量变量预测值。
16.进一步地,所述s3中,监督泊松自编码器中的编码器表示为:
17.h=σ(we·
x+be)
18.其中,σ代表sigmoid激活函数,x是输入层的输入向量,h是隐藏层的输出向量,we和be分别表示编码器的权重和偏置;
19.监督泊松自编码器中的解码器表示为:
[0020][0021][0022]
其中,exp代表指数函数,wr和br分别表示解码器中重构输入向量的权重和偏置;w
p
和b
p
分别表示泊松网络层的权重和偏差参数,表示重构后的输入向量,分别预测的输出向量;
[0023]
所述损失函数l
rec
表示为:
[0024][0025]
其中,λ表示对输入向量的重构误差和输出向量的预测误差的权重的比值;的含义为二范数,
⊙
表示哈达玛积。
[0026]
进一步地,所述s3中,第k个监督泊松自编码器的训练过程表示如下:
[0027][0028][0029][0030][0031]
其中,k=1,2,
…
l,和分别是第i个样本在第k个监督泊松自编码器的输入数据和重构的数据,和分别是第k层编码器和解码器的权重矩阵以及偏置项;
[0032]
通过如下的子步骤来实现:
[0033]
第k个监督泊松自编码器训练的损失函数如下:
[0034][0035]
其中,yi和分别代表第i个样本对应的计数型质量变量实际观测值和其在第k个监督泊松自编码器的预测值。
[0036]
进一步地,所述s4中,预测的输出变量的计算公式如下:
[0037][0038]
其中,wy和by分别表示泊松网络的权重和偏置;
[0039]
损失函数如下:
[0040][0041]
本发明的有益效果如下:
[0042]
本发明提出的基于堆叠泊松自编码器网络的计数数据软测量建模方法用于计数数据质量预测,来解决常规自编码器特征提取效率低下且不适用于计数数据建模的问题。通过把计数型质量变量添加到解码阶段的输出层,且考虑到计数数据的离散性、非负性,计数数据是经过泊松回归网络层的方式集成到深度自编码器框架中,改进了损失函数,使得模型可以学习到与计数数据质量变量高度相关的特征,模型在计数数据上的的预测效果得到改善。
附图说明
[0043]
图1是深度堆叠泊松自编码器(sspae)结构图;
[0044]
图2是基于sspae的计数数据软测量建模流程图;
[0045]
图3是钢铁铸轧工艺缺陷系统流程图;
[0046]
图4是sspae、stae和sae方法预测结果图,分别对应子图(c)、(b)和(a),其中横坐标代表测量样本,纵坐标代表质量数据的值,图中“+”代表模型预测值,“*”代表真实值。
具体实施方式
[0047]
下面根据附图和优选实施例详细描述本发明,本发明的目的和效果将变得更加明白,应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0048]
本发明的方法基于堆叠泊松自编码器网络(sspae)结构,在原始自编码器的基础上将编码器进行改进,在预训练的解码阶段引入质量变量来指导特征提取,此外,考虑到计数数据的离散性,质量变量是通过泊松回归网络层的方式集成到深度堆叠自编码器框架中,使得模型学习到的特征表示与计数数据类型质量变量高度相关,提升特征提取效率,同时提高对计数数据的软测量精度。
[0049]
如图1所示,本发明的方法具体步骤如下:
[0050]
s1:收集设备数据,组成建模用的输入输出训练数据集:其中,x代表输入变量,y代表离散计数数据类型的输出变量,n表示数据样本个数;并将数据集分为训练集、验证集和测试集,根据不同工况进行数据预处理;
[0051]
s2:构建堆叠泊松自编码器网络sspae,如图2所示,sspae由多个监督泊松自编码器spae分层堆叠而成,前一个监督泊松自编码器的隐藏层的输出作为下一个监督泊松自编码器的输入层的输入;所述监督泊松自编码器包括一个输入层、一个隐藏层和一个输出层,从隐藏层到输出层包含输入重构网络层和泊松网络层,所述输入重构网络层用于对输入向量进行重构,所述泊松网络层用于对计数型质量数据进行预测;
[0052]
假设x是输入向量,h是隐藏向量,y是质量变量。spae在解码器中会同时重建其输入数据且预测计数数据,这两个数据分别表示为和spae预测质量数据采用针对计数数据的泊松网络。
[0053]
{we,be}和{wd,bd}分别用于表示编码器和解码器的参数集。编码器表示为:
[0054]
h=σ(we·
x+be)
[0055]
其中,σ代表sigmoid激活函数。
[0056]
由于解码器由两部分组成,其解码权重矩阵和解码偏置向量可以分解为输入数据和计数数据质量变量两部分。也就是说,它的参数可以分解为:
[0057][0058]
在spae的输出层,重构的输入数据由隐藏数据经过输入重构网络层映射可得:
[0059][0060]
特别地,针对离散的计数数据建模,隐藏特征到输出数据的映射是泊松网络层,如
下所示:
[0061][0062]
其中,其中,exp代表指数函数,{w
p
,b
p
}表示泊松网络层的权重和偏差参数。一方面,泊松网络层的泊松分布的误差结构使数据可以具有非线性的特征和非恒定方差结构;另一方面,泊松网络层可以保证预测的非负性。
[0063]
所以,spae的解码器输出可以表示为:
[0064][0065][0066]
(2)给定输入训练数据x={x1,x2,
…
,xn}和对应的计数质量数据y={y1,y2,
…
,yn},spae网络学习参数的方式是通过最小化输出层的损失函数,如下所示:
[0067][0068]
其中,λ表示对输入向量的重构误差和输出向量的预测误差的权重的比值;的含义为二范数,
⊙
表示哈达玛积。
[0069]
(3)根据以上最小化损失函数训练第一个监督泊松自编码器,获得参数和第一潜在特征表示
[0070]
随机初始化sspae模型的泊松网络权重、神经网络连接权重及偏置参数。
[0071]
s3:将训练数据输入给堆叠泊松自编码器网络,根据最小化损失函数训练第一个监督泊松自编码器,获得第一个监督泊松自编码器的权重和偏置参数和隐藏层的输出将h1作为第二个监督泊松自编码器的输入层的输入,根据最小化损失函数训练第二个监督泊松自编码器,获得对应的权重和偏置参数,以此层层递进,使用h
k-1
,根据训练第k个监督泊松自编码器spaek获得参数和hk,直到最后一个监督泊松自编码器训练完成;k≤l,其中,l为监督泊松自编码器的数量;
[0072]
s3具体包括如下子步骤:
[0073]
(1)通过分层堆叠多个spae构建深度spae网络,将输入数据传输到sspae的输入层,经过具有参数集的第一隐藏层,生成相应的第一级特征数据spae1在其输出层使用输入重构网络层重构原始输入数据以及泊松网络层预测质量数据。其预训练是通过最小化训练数据上的重建和预测误差来进行的,如下所示:
[0074][0075]
(2)spae1经过预训练后,其编码器部分保留在整个spae网络中,可以计算出紧接着,第一层隐藏特征向量会作为第二个spae的输入,经过映射获得第二层特征向量。在spae2的输出层,第一层特征向量和计数数据质量向量也由第二层特征向量重构和预测。以此获得第二级特征数据对于其余层次的特征,可以通过类似的方式逐步获得。
[0076]
假设第k-1层特征隐层已经学习到,它将通过参数集为的非线性函数获得第k层特征隐层然后在输出层通过输入重构网络层映射重构h
k-1
,特别地,由泊松网络层预测输出计数数据。
[0077]
该过程如下所示:
[0078][0079][0080][0081][0082]
其中,k=1,2,
…
l,和分别是第i个样本在第k个自编码器的输入数据和重构的数据,和分别是第k层编码器和解码器的权重矩阵以及偏置项。
[0083]
s4:结束s3的逐层训练后,在第l个监督泊松自编码器的隐藏层的输出h
l
和输出变量y之间建立泊松网络进行回归,根据预测误差对回归网络参数进行调整更新;回归网络训练结束并保存堆叠泊松自编码器网络;
[0084]
在结束前向逐层训练后,输出映射网络被添加在在顶层,利用最后一层隐层特征向量h
l
来预测输出数据并最小化预测误差的损失函数去更新sspae网络的相关参数:
[0085][0086][0087]
其中,wy和by分别表示泊松网络的权重和偏置。
[0088]
s6:将待预测输入数据输入到保存的sspae模型,经过sspae网络的前向传播即可得到计数型质量变量预测值。
[0089]
以下结合一个具体的工业例子来说明本发明的有效性。为了提高产品质量和节约生产成本,实时地预测钢板的缺陷发生数量至关重要。例如,基于对缺陷数量的在线预测,操作者可以改变操作条件来控制缺陷的发生;此外,缺陷预测模型提供了缺陷数量的早期度量,这有助于操作者防止操作条件的进一步恶化;此外,基于缺陷预测模型,可以进一步探究影响缺陷发生率的关键因素。
[0090]
采用的数据是从某炼钢厂收集的某一种类型的钢铁缺陷数据,其收集于二次精
炼、连铸、轧制和冷却等过程,如图3所示。数据包含过程变量数据和质量变量数据。过程变量数据包括加热温度等146个过程操作变量,是连续型变量,数据存在较强的非线性。质量变量代表缺陷的数量,属于离散计数数据类型。本次实验中,收集的2500个样本被随机分为三个数据集,其中1500个样本作为训练数据集用于模型训练,500个样本作为验证数据集用于模型参数选择,500个样本作为测试数据集用于模型测试。,
[0091]
表1:网络结构参数
[0092]
网络层输入层隐层1隐层2隐层3隐层4节点数1468343105
[0093]
为了做对比分析,包括堆叠监督泊松自编码器sspae、堆叠目标相关自编码器stae、堆叠自编码器sae和泊松回归ps在内的多种方法被用于该工业过程的计数数据软测量建模。sspae、stae和sae的网络结构参数如表1所示。sspae模型中的关键超参数λ设置为1.5。
[0094]
表2:各个对比方法在测试集上的预测性能对比
[0095][0096][0097]
表2提供了各个对比方法在均方根误差rmse和相关系数r2两种模型评价指标下的预测精度对比。rmse越小以及,代表模型预测误差越小。r2越大,代表模型预测精度越高。从两个指标可以看出,本发明方法sspae的预测表现是最好的,具有最小的预测误差和最高的预测精度。
[0098]
图4分别展示sspae模型和stae模型、sae模型的部分预测效果图,其中横坐标代表测量样本,纵坐标代表质量数据的值。图4(c)为本发明方法,从图中可以看出,本发明方法sspae对于钢铁缺陷数量的预测值与真实值的拟合更加紧密,预测结果更加准确。
[0099]
本领域普通技术人员可以理解,以上所述仅为发明的优选实例而已,并不用于限制发明,尽管参照前述实例对发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在发明的精神和原则之内,所做的修改、等同替换等均应包含在发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1