一种基于联邦学习的地区用电量中长期预测方法与流程
1.本发明涉及电气工程技术领域,尤其是涉及一种基于联邦学习的地区用电量中长期预测方法。
背景技术:
2.在“碳达峰、碳中和”(“双碳”)战略的大背景下,未来的电力系统转型方向是构建以新能源为主体的新型电力系统。准确的地区用电量中长期预测可以指导地区新能源、传统火电装机容量等电力规划,有助于政府制定“双碳”战略目标。现有的机器学习和深度学习方法在地区用电量中长期预测方面取得了一些成果,但在实际的用电量预测中,各地区所记录的准确用电量数据只有数年甚至数月的少量数据,导致使用机器学习算法所训练的模型预测准确度降低。而且,仅使用单个地区的数据训练模型,导致模型泛化能力低,难以直接迁移到新的地区进行用电量预测。因此,研究多地区用电量协同预测的方法具有重要的理论和工程价值。近年来,联邦学习作为一种分布式机器学习技术受到国内外学者的广泛关注,可以实现多个客户端在中央服务器的协调下共同训练模型,而无需数据持有者共享数据。在保护数据隐私的前提下,不仅丰富了数据样本,还提高了模型的泛化能力。
3.此外,现有的地区用电量预测方法仅考虑经济、社会等影响因素,忽视了“双碳”背景下碳排放量对用电量的影响,其预测结果可能不符合未来的“双碳”目标。因此,亟需面向“双碳”目标,构建新的用电量影响因素体系,以使地区用电量预测结果更符合未来的低碳发展路径。
技术实现要素:
4.针对现有技术中存在的问题,本发明基于联邦学习和深度学习的方法,提出一种基于联邦学习的地区用电量中长期预测方法,以达成多地区用电量协同预测的目的。
5.为实现上述目的,本发明采用如下技术方案:
6.与现有技术相比,本发明的有益效果如下:本发明提供了一种基于联邦学习的地区用电量中长期预测方法,包括如下步骤:
7.(1)搭建n个lstm用电量预测模型,作为联邦学习的基础模型;
8.(2)选取lstm模型的特征输入量和输出量,对参与联邦学习的本地数据进行归一化处理;
9.(3)基于联邦学习,对n个lstm用电量预测模型进行协同训练,依次进行本地模型训练、本地模型上传、服务器接收模型、服务器聚合模型、服务器下发模型等流程,直到训练结束;
10.(4)训练结束后得到更新后的服务器全局模型,通过输入本地数据的测试集到全局模型,得到地区用电量预测结果。
11.进一步地,所述lstm用电量预测模型具体为:由一个输入层、若干个隐藏层和一个输出层构成,隐藏层神经元个数都为100;前一层的输出作为后一层的输入,最后通过线性
的全连接层输出得到用电量预测值。
12.进一步地,所述步骤(2)中选取lstm模型的特征输入量和输出量,具体为:lstm网络的输入特征主要由预测期前的历史用电量数据和预测期对应的人均gdp、产业结构、地区常住人口、城镇化率和碳排放量组成;lstm模型的输出特征是预测期的用电量值。
13.进一步地,所述步骤(2)中对参与联邦学习的本地数据归一化处理,具体为,采用min-max归一化方法对本地数据预处理:
[0014][0015]
其中,x代表原始数据;x
max
和x
min
分别代表样本数据的最大值和最小值。
[0016]
进一步地,所述步骤(3)中基于联邦学习对n个lstm模型进行协同训练,具体为,联邦学习整体过程有多轮训练,但每轮训练的步骤相同,每轮训练的流程如下:
[0017]
step 1:如果这是第一轮训练,服务器将初始化全局lstm模型权重参数;否则,服务器继续使用上一轮训练获得的权重,然后将全局模型下发到所有本地客户端;
[0018]
step 2:本地客户端接收下发的模型,将本地的lstm模型参数替换为更新的全局模型参数,然后所有的用户都只使用本地数据并采用adam优化算法训练本地lstm模型;
[0019]
step 3:本地训练结束后,所有客户端向服务器上传更新后的本地模型参数;
[0020]
step 4:服务器接收并聚合本地模型参数,得到更新的全局模型;
[0021]
在全局通信轮次内重复上述步骤,直到训练结束。
[0022]
进一步地,所述采用adam优化算法训练本地lstm模型,具体为,根据t时刻的梯度g
t
分别计算梯度的一阶矩m
t
和二阶矩v
t
:
[0023]mt
=β1m
t-1
+(1-β1)g
t
[0024][0025]
其中,β1和β2分别是一阶矩衰减系数和二阶矩衰减系数;g
t
为对t时刻求导所得梯度;为降低偏差对训练带来的影响,需将m
t
和v
t
分别修正为和
[0026][0027][0028]
所述更新模型权重参数的具体公式为:
[0029][0030]
其中,θ
k,t-1
和θ
k,t
分别为第k个本地模型在t-1时刻和t时刻的模型权重;η为学习率;ε为常数。
[0031]
进一步地,所述客户端向服务器上传更新后的本地模型参数,将上传的本地模型模型参数作为权重参数。
[0032]
进一步地,所述服务器聚合本地模型参数,具体为:各个本地模型参与聚合的权值wk与其参与训练的样本数量有关,当客户端自身样本数量越多,其模型参数聚合的权值wk也越大,权值计算公式如下:
[0033][0034]
其中,qi表示第i个客户端的本地训练数据样本总数,wk表示第k个本地模型参与聚合的权值;
[0035]
所述模型聚合的计算公式如下:
[0036][0037]
其中,θ表示聚合更新后全局模型的参数;wi和θi分别表示第i个模型聚合的权值和经过本地训练后上传的模型权重参数。
[0038]
进一步地,所述步骤(4)具体为:通过输入本地数据的测试集到全局模型,服务器将最终的全局模型下发到全部客户端,每个客户端用户使用全局模型在本地测试集进行测试,得到地区用电量预测结果。
[0039]
与现有技术相比,本发明的有益效果为:
[0040]
1、采用数据驱动的思路和深度学习的算法,不涉及任何显式的建模,相比于传统的统计学方法和回归模型,本发明对于高维非线性问题具有更好的自适应能力,可以通过自学习来挖掘地区用电量的潜在变化规律;
[0041]
2、在保护数据隐私的前提下,本发明实现了不同地区的用电量模型协同训练,既丰富了样本特征,还有效提高了模型的预测准确率和泛化能力;
[0042]
3、在经济、社会等用电量传统影响因素基础上,本发明考虑了碳排放量对用电量的影响,使地区用电量预测结果更符合未来的低碳发展路径。
附图说明
[0043]
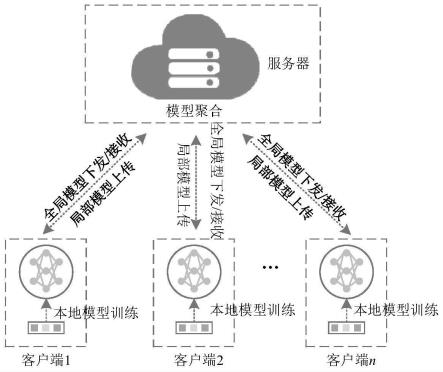
图1为本发明实施例基于联邦学习的整体架构图;
[0044]
图2为本发明实施例的用电量预测基础模型lstm结构示意图;
[0045]
图3为本发明实施例的地区用电量影响因素体系;
[0046]
图4为本发明实施例的某地区2022-2035年用电量预测结果。
具体实施方式
[0047]
下面结合附图及具体实施示例对本发明作进一步详细说明。
[0048]
图1为本发明基于联邦学习的整体架构图,所述联邦学习是一种分布式机器学习技术,可以实现多个客户端在中央服务器的协调下共同训练模型,而无需数据持有者共享数据。以中国四个地区的用电量预测为例,基于联邦学习的地区用电量中长期预测包含以下步骤:
[0049]
(1)搭建n个lstm用电量预测模型,作为联邦学习的基础模型;本发明实施例中搭建4个lstm用电量预测基础模型。
[0050]
图2为本发明的用电量预测基础模型lstm网络结构示意图,4个模型的结构和超参数都是相同的。lstm网络采用典型结构,由一个输入层、4个隐藏层和一个输出层构成,隐藏层神经元个数都为100。前一层的输出作为后一层的输入,最后通过线性的全连接层输出得
到用电量预测值。
[0051]
(2)选取lstm模型的特征输入量和输出量。
[0052]
lstm网络的输入特征主要由预测期前的历史用电量数据和预测期对应的人均gdp、产业结构、地区常住人口、城镇化率和碳排放量组成。上述输入特征都是与用电量相关的影响因素,包含了经济、社会和环境三个方面,如图3所示。其中人均gdp和产业结构是衡量经济发展的因素。未来趋势将降低第二产业比重,大力发展第三产业,因此选择第三产业增加值占比作为衡量产业结构的指标。此外,选取地区常住人口和城镇化率作为社会影响因素。在我国2060碳中和背景下,用电量的增长将受到碳排放量的限制,因此,在经济和社会传统影响因素的基础上,增加碳排放量影响因素。lstm输出层将输出数据特征限制为1,即lstm模型的输出特征是预测期的用电量值。
[0053]
(3)对参与联邦学习的本地数据归一化处理。
[0054]
采用min-max归一化方法对本地数据预处理:
[0055][0056]
其中,x代表原始数据;x
max
和x
min
分别代表样本数据的最大值和最小值。
[0057]
(4)基于联邦学习,对4个lstm模型进行协同训练,依次进行本地模型训练、本地模型上传、服务器接收模型、服务器聚合模型、服务器下发模型等流程,直到训练结束。
[0058]
联邦学习整体过程有多轮训练,本实施例的联邦训练轮数设为500,每轮训练的步骤相同,依次进行本地模型训练、本地模型上传、服务器接收模型、服务器聚合模型、服务器下发模型等流程,每轮训练的流程如下:
[0059]
step 1:如果这是第一轮训练,服务器将初始化全局lstm模型权重参数。否则,服务器继续使用上一轮训练获得的权重,然后将全局模型下发到所有本地客户端。
[0060]
step 2:本地客户端接收下发的模型,将本地的lstm模型参数替换为更新的全局模型参数,然后所有的用户都只使用本地数据并采用adam优化算法训练本地lstm模型。所述adam优化算法需要根据t时刻的梯度g
t
分别计算梯度的一阶矩m
t
和二阶矩v
t
:
[0061]mt
=β1m
t-1
+(1-β1)g
t
[0062][0063]
其中,β1和β2分别是一阶矩衰减系数和二阶矩衰减系数,本发明实施例中分别取值为0.9和0.999;g
t
为对t时刻求导所得梯度;m0与v0均设为0。
[0064]
为降低偏差对训练带来的影响,需将m
t
和v
t
分别修正为和
[0065][0066][0067]
所述更新模型权重参数的具体公式为:
[0068][0069]
其中,θ
k,t-1
和θ
k,t
分别为第k个本地模型在t-1时刻和t时刻的模型权重;η为学习率,本发明实施例中取值为0.0001;ε为常数,本发明实施例中取值为10-8
。
[0070]
step 3:本地训练结束后,所有客户端向服务器上传更新后的本地模型权重参数,相比经典的联邦学习方法,直接传输模型权重而不是传输梯度的方法可以避免由梯度参数反推训练数据的网络攻击造成的数据泄露风险。由于每个客户端使用不同的本地数据来训练lstm模型,因此每个客户端模型的参数都是不同的。
[0071]
step 4:服务器接收并聚合本地模型参数,得到更新的全局模型。各个本地模型参与聚合的权值wk与其参与训练的样本数量有关,当客户端自身样本数量越多,其模型参数聚合的权值wk也越大,权值计算公式如下:
[0072][0073]
其中,qi表示第i个客户端的本地训练数据样本总数,wk表示第k个本地模型参与聚合的权值。
[0074]
所述模型聚合的计算公式如下:
[0075][0076]
其中,θ表示聚合更新后全局模型的参数;wi和θi分别表示第i个模型聚合的权值和经过本地训练后上传的模型权重参数。
[0077]
在全局通信轮次内重复上述4个步骤,直到训练结束。
[0078]
(5)输入本地数据的测试集到全局模型,得到地区用电量预测结果
[0079]
服务器将最终的全局模型下发到全部客户端,每个客户端用户使用全局模型在本地测试集进行测试,预测未来的用电量。
[0080]
以中国4个地区的用电量预测为例,选取1990-2020年4个地区的用电量及其影响因素为训练样本,联邦训练结束后,选择其中一个地区作为测试对象,预测其在2022-2035年的用电量。最终得到的预测结果如图4所示,图中比较了本发明的方法与不考虑碳排放量影响的传统时间序列方法,图上不仅展示了两种方法得到的用电量预测结果,还展示了不同的用电量年增长率。可以看出,2022-2035年的用电量将逐年增加,且两种结果的误差较小,说明本方法的预测结果是有效的。两种结果的不同之处在于,本发明方法得出的增长率在2023年左右达到峰值后会逐渐下降,而不考虑碳排放量的传统方法得出的增长率到2025年仍有较大峰值。可见,本方法得出的用电量增长趋势更符合未来“双碳”的发展路径和实际的用电量变化规律。因此,本方法的预测结果可以为未来的新型电力系统规划提供参考。
[0081]
综上所述,本发明采用数据驱动的思路和深度学习的算法,不涉及任何显式的建模,相比于传统的统计学方法和回归模型,本发明对于高维非线性问题具有更好的自适应能力,可以通过自学习来挖掘地区用电量的潜在变化规律。本发明方法在保护数据隐私的前提下,实现了不同地区的用电量模型协同训练,既丰富了样本特征,还有效提高了模型的泛化能力。本发明方法在经济、社会等用电量传统影响因素基础上,还考虑了碳排放量对用电量的影响,使用电量预测结果更符合未来的低碳发展路径。
[0082]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1