一种信息识别方法、信息识别系统、电子设备及计算机可读存储介质
1.本技术涉及人工智能领域,具体涉及一种信息识别方法、信息识别系统、电子设备及计算机可读存储介质。
背景技术:
2.人工智能(ai,artificial intelligence)领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
3.人工智能的核心是机器学习。在机器学习中,通过标签已知的训练数据(也称为学习数据)进行学习,优化算法模型的参数,对标签未知的测试数据进行识别。
4.在机器学习中,当训练数据和测试数据存在较大差异时,机器学习中使用的训练数据与测试数据不同,导致对测试数据进行识别时,识别性能下降,存在很大的不确定性,影响系统性能。
5.因此,领域泛化技术(domain generalization)受到越来越多的关注,其要解决的问题是如何利用训练数据训练一个模型,使得该模型能够泛化到其他不同数据分布的目标领域,减小对测试数据进行识别时的不确定性,提高机器学习算法对新样本的适应能力,即,提高机器学习的泛化能力(generalization ability)。领域泛化技术中,训练数据集也称为源域,测试数据集也称为目标域。领域泛化的训练数据和测试数据来源于不同领域、且具有不同分布的数据,一般的领域泛化方法是尽量抽取不同领域数据中和领域无关的信息,或者学习得到隐含在不同领域数据背后的规律,使其在面对新领域数据时,可能得到合理的性能。
6.现有技术中,主要通过元学习、变分推理方法改善系统的泛化能力。
7.元学习(meta-learning)是以很多个任务作为训练数据。元学习是解决小样本问题(few-shot learning)常用方法之一,可以被用于提高领域泛化能力。小样本学习中,由于样本少而造成模型学习不充分,而元学习中,将每一个信息识别任务作为一个训练样本,生成很多这样的样本进行学习,训练单位包括任务,以及每个任务对应的数据,通过在学习过程中不断适应各个具体任务,优化网络模型的参数的确定方式,使网络具备抽象的学习能力。元学习能够提高系统对多任务的泛化能力,能够依赖很少的样本,识别训练时未出现的样本。
8.领域泛化的元学习中,用若干个训练和测试数据均来源于不同领域,具有不同分布的任务学习得到一个泛化能力强的模型,并在学习中,旨在学到隐含在各任务数据背后的规律,使其在遇到新的任务时,能克服领域不同导致的偏移的影响,取得较好的识别效果。
9.变分推理是一种数据生成模型算法,用于生成指定要求的分布数据,对复杂的目标分布进行近似。具体来说,变分推理是一种确定式的近似推理方法,就是一种用来近似一个计算复杂的分布或者至少获得目标分布的一些统计量的方法。在深度学习中常用的变分
自编码器(vae)就是基于变分推理。在变分推理中,一般是仅依据输入信息推理潜在变量分布,而在有监督学习系统中标签(输出)信息的指导作用至关重要。
10.条件变分是指在变分推理中将样本的已知的标签信息作为输入信息,生成该样本分布。因此条件变分推理是在变分推理的基础上,将样本已知的标签信息也加入输入端,起到对生成分布的指导作用。由于变分推理和条件变分推理都是在分布层面对数据或参数进行分析,而不是针对固定的数值分析,这在一定程度上可以增强泛化性能。
11.但是现有技术的方法减小未知目标域数据集的识别不确定性的能力不足,当未知目标域与源域具有不同分布时,泛化能力仍然有限。
技术实现要素:
12.本发明提供一种信息识别方法、信息识别系统、电子设备,以及计算机可读存储介质,其能够提高泛化能力,降低信息识别的不确定性。
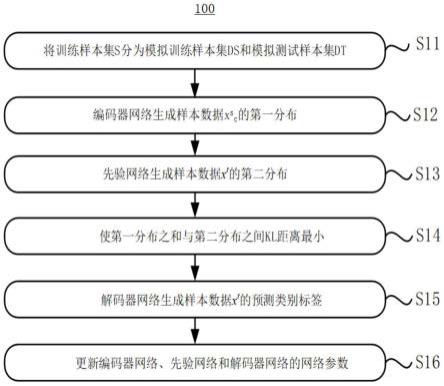
13.第一方面,本发明提供一种信息识别方法,其学习阶段包括以下步骤:
14.步骤s11,将包含多个样本类别、多个样本域的训练样本集s划分为模拟训练样本集ds和模拟测试样本集dt;
15.步骤s12,将模拟训练样本集ds的各个类别c的样本数据x
sc
、样本数据x
sc
的类别标签y
sc
输入编码器网络,编码器网络生成样本数据x
sc
的各个类别c在潜在空间的第一分布,
16.步骤s13,将模拟测试样本集dt的样本数据x
t
输入先验网络,先验网络生成基于样本数据x
t
在所述在潜在空间的第二分布,
17.步骤s14,计算各个类别c的第一分布之和与第二分布之间的kl距离,使该kl距离最小。
18.在以上发明中,在学习阶段,将标签已知的训练样本集s划分为模拟训练样本集ds和模拟测试样本集dt,模仿训练数据集和测试数据集的差异。本发明中以源域上的训练、目标域(与源域不一致)上的测试这样的任务作为训练样本,即采用了元学习框架。
19.本发明中对模拟训练样本集ds的各个类别c的样本数据x
sc
进行条件变分编码,获得样本数据x
sc
的各个类别c在潜在空间的分布(即,第一分布);对模拟测试样本集dt的样本数据x
t
输入先验网络,获得样本数据x
t
在潜在空间的分布(即,第二分布)。即,本发明中将元学习框架和条件变分推理结合,发挥了条件变分推理的建模能力,能更好地解决跨域建模的不确定性,在元学习框架下,模拟从源域到目标域的泛化,通过跨域的训练和测试过程获得泛化能力。在元学习框架下重新推导出条件变分推理的下界,将变分推理过程转换为网络参数优化过程。
20.本发明中,使各个类别c的第一分布之和与第二分布之间的kl距离最小(即,使第一分布之和与第二分布之间的似然度最大)。
21.通过使先验网络在隐含空间上的分布,与编码器对模拟训练样本集ds的数据生成的隐含空间上的分布尽量接近,能减少模拟训练样本集ds和模拟测试样本集dt的跨度,增强泛化性能。
22.因此,本发明在模拟训练样本集ds与模拟测试样本集dt存在差异的情况下优化先验网络参数,增强泛化性能。
23.这里,先验网络是用来进行测试的神经网络,其网络参数由学习过程中获得的先
验知识确定,在学习过程中,通过与条件变分编码的结果进行比较,优化先验网络的参数,达到与条件变分编码同样的效果。
24.作为一个实施例,所述信息识别方法,还包括:
25.步骤s15,将模拟测试样本集dt的样本数据x
t
以及第一分布的参数输入解码器网络,解码器网络基于模拟测试样本集dt的样本数据x
t
以及第一分布的参数,生成样本数据x
t
的预测类别标签使预测类别标签与样本数据x
t
的已知类别标签y
t
的交叉熵最小。
26.在以上实施例中,解码器网络对基于模拟训练样本集ds的样本数据xs得到的第一分布进行解码,得到模拟测试样本集dt的样本数据x
t
的预测类别标签由于模拟测试样本集dt的样本数据x
t
的真实类别标签y
t
已知,使预测类别标签与样本数据x
t
的已知类别标签y
t
的交叉熵最小。
27.通过解码获得模拟测试样本集dt的样本数据x
t
的预测类别标签使其与样本数据x
t
的已知类别标签y
t
的交叉熵最小,完成学习过程,从而在模拟训练样本集ds与模拟测试样本集dt存在差异的情况下,优化先验网络、解码器网络的参数,增强系统的泛化性能。
28.作为一个实施例,所述信息识别方法的测试阶段包括以下步骤:
29.步骤s31,将测试样本集t的测试样本数据x输入先验网络,先验网络生成测试样本数据x在潜在空间的第三分布;
30.步骤s32,将测试样本数据x和第三分布的参数输入解码器网络,解码器网络根据第三分布的参数生成测试样本数据x的预测类别标签
31.在以上实施例中,测试样本集t的数据x的类别未知,有待识别。在测试阶段,使用学习阶段得到的优化后的先验网络、解码器网络的参数,先验网络生成样本数据x在潜在空间的分布(即,第三分布),解码器网络对第三分布进行解码,得到样本数据x的预测类别标签
32.由于在学习阶段,在模拟训练样本集ds与模拟测试样本集dt存在差异的情况下获得优化的先验网络、解码器网络的参数,即使测试样本集t与训练样本集s存在差异,测试阶段也能准确识别输入样本的类别,识别不确定性降低,系统的泛化性能增强。
33.作为一个实施例,步骤s12中,使不同类别的样本数据x
cs
的第一分布之间的wasserstein距离lw最大。
34.在以上实施例中,使不同类别的样本数据x
cs
在潜在空间的第一分布之间的wasserstein距离lw最大,该约束条件将潜在空间中的不同类别的第一分布之间的距离尽量拉大,从而进一步提高系统的预测性能。
35.作为一个实施例,步骤s11中,在训练样本集s的多个样本域中,随机选择一个样本域作为模拟测试样本集dt,其余的样本域作为模拟训练样本集ds。
36.在以上实施例中,在将训练样本集s划分为模拟训练样本集ds和模拟测试样本集dt时,随机选择训练样本集s的一个样本域作为模拟测试样本集dt,其余的样本域作为模拟训练样本集ds,来模仿训练数据集和测试数据集的差异,优化先验网络参数,增强泛化性能。
37.作为一个实施例,步骤s15中,对第一分布进行多次采样,将多个采样值z
l
以及样
本数据x
t
输入解码器网络,得到多个预测类别标签,对该多个预测类别标签取平均,将得到的平均值作为样本数据x
t
的预测类别标签
38.在以上实施例中,解码器网络对编码器网络生成的第一分布进行多次采样,得到多个预测类别标签;对该多个预测类别标签取平均,作为样本数据x
t
的预测类别标签由于多次采样,并对多个预测值取平均,可以有效减小数据域的差异对识别性能的影响,提高泛化能力,提高预测结果的准确性和可靠性。
39.作为一个实施例,根据以下式(1)计算整体损失函数
[0040][0041]
其中,为交叉熵,d
kl
为kl距离,为wasserstein距离,
[0042]
根据式(2),利用梯度下降法生成编码器网络、先验网络、解码器网络的参数:
[0043][0044]
在以上实施例中,将kl距离d
kl
,wasserstein距离作为约束条件优化编码器网络、先验网络、解码器网络的参数,能够提高泛化能力。在本发明中的元学习条件变分推理中,采用条件变分证据下界的目标函数(损失函数)进行参数优化,将推理过程转化为参数优化。
[0045]
作为一个实施例,步骤s32中,对第三分布进行多次采样,将多个采样值z
l
以及样本数据x输入解码器网络,得到多个预测类别标签,对该多个预测类别标签取平均,将得到的平均值作为样本数据x的预测类别标签
[0046]
在以上实施例中,由于多次采样,并对多个预测值取平均,可以有效减小数据域的差异对识别性能的影响,提高泛化能力,提高预测结果的准确性和可靠性。
[0047]
在一些实施例中,训练样本集s、测试样本集t的样本数据为图形数据、语音数据、或文字数据。
[0048]
以上实施例能够对不同类型的信息数据集解决领域泛化问题,提升系统性能。
[0049]
第二方面,本发明提供一种信息识别系统,包括:
[0050]
编码网络单元,在学习阶段,其接收从训练样本集s划分出的模拟训练样本集ds的各个类别c的样本数据x
sc
、以及所述样本数据x
sc
的类别标签y
sc
,生成基于所述样本数据x
sc
的各个类别c的第一分布,其中,所述训练样本集s包含多个样本类别、多个样本域,所述训练样本集s划分为所述模拟训练样本集ds和模拟测试样本集dt;
[0051]
先验网络单元,在学习阶段,其接收所述模拟测试样本集dt的样本数据x
t
,并生成基于所述样本数据x
t
的所述第二分布,其中,各个类别c的所述第一分布之和与所述第二分布之间的所述kl距离最小;
[0052]
解码器网络单元,在学习阶段,其接收所述模拟测试样本集dt的的样本数据x
t
以及所述第一分布的参数,生成所述样本数据x
t
的预测类别标签其中,所述预测类别标签与所述样本数据x
t
的已知类别标签y
t
的交叉熵最小。
[0053]
在一些实施例中,所述信息识别系统,在测试阶段,
[0054]
先验网络单元接收测试样本集t的测试样本数据x生成基于测试样本数据x的第三
分布;
[0055]
解码器网络单元接收测试样本数据x和第三分布的参数,生成测试样本数据x的预测类别标签
[0056]
在一些实施例中,所述信息识别系统,编码网络单元输出的不同类别的样本数据x
cs
的第一分布之间的wasserstein距离lw最大。
[0057]
第三方面,本发明提供一种电子设备,包括一个或多个处理器及存储器,存储器上存储有一个或多个计算机程序,当一个或多个处理器执行一个或多个计算机程序时,实现本发明第一方面任一项的信息识别方法步骤。
[0058]
第四方面,本发明提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,计算机程序程序被处理器运行时实现本发明一个方面任一项的信息识别方法。
附图说明
[0059]
以下结合附图说明本发明的具体实施例。以下附图仅用于示出优选实施方式,而不是对本发明的限制。另外,在全部附图中,用相同的附图标号表示相同的部件。
[0060]
图1是本发明的实施例的涉及的样本数据集的示例图;
[0061]
图2是本发明的实施例的信息识别方法的学习阶段的流程图;
[0062]
图3是说明本发明的实施例的信息识别方法的学习阶段的示意图;
[0063]
图4是本发明的实施例的信息识别方法的测试阶段的流程图;
[0064]
图5是说明本发明的实施例的信息识别方法的测试阶段的示意图;
[0065]
图6显示现有技术的识别方法的识别性能;
[0066]
图7显示现有技术的识别方法的识别性能;
[0067]
图8显示本发明实施例的识别方法的识别效果;
[0068]
图9是本发明的实施例的信息识别方法系统的结构示意图。
具体实施方式
[0069]
下面结合附图对本发明实施例进行详细的描述。以下实施例仅用于清楚地说明本发明,而不能以此来限制本发明的保护范围。说明书中描述的各个实施例相互之间并不排斥,本领域技术人员根据本发明的技术思想以及技术常识,可以将各个实施例进行结合。除非另有定义,本文使用的技术术语与本技术领域的技术人员通常理解的含义相同;本文中使用的术语只是为了描述具体的实施例,而不是限制本发明。本技术的说明书和权利要求书及附图说明中的术语“包括”和“具有”以及它们的任何变形为不排他的包含;术语“第一”、“第二”等仅用于区别不同对象,而不表示相对重要性、数量、特定顺序或主次关系。术语“和/或”仅仅是一种描述关联对象的关联关系,可以存在三种关系,例如a和/或b,可以表示单独存在a,同时存在a和b,单独存在b这三种情况。“多个”指的是两个以上(包括两个)。字符“/”,一般表示前后关联对象是“或”的关系。
[0070]
本发明实施例的信息识别方法、信息识别系统、电子设备及计算机可读存储介质能够提高领域泛化能力,在测试与学习过程数据差异较大的样本数据时,也能够快速适应并识别该数据的类别。
[0071]
本发明实施例的信息识别方法100和信息识别系统10可适用于识别图形数据、语音数据、或文字数据。下述实施例以识别图形数据为例进行详细说明。
[0072]
图1是本发明实施例的涉及的样本数据集的示例图。
[0073]
图1是本发明实施例涉及的图形样本数据集合101的一个例子,包含train(火车),tortoise(乌龟),snail(蜗牛),pickup(卡车),octopus(章鱼),duck(鸭子),cat(猫),car(汽车),candle(蜡烛),butterfly(蝴蝶),bicycle(自行车),apple(苹果),airplane(飞机)等多个图片样本,这些图片可能是sketch(简笔画),cartoon(卡通画),art painting(艺术画),或photo(照片)。图1所示数据集合也称为pacs数据库。
[0074]
这里,train(火车),tortoise(乌龟),snail(蜗牛),pickup(卡车),octopus(章鱼),duck(鸭子),cat(猫),car(汽车),candle(蜡烛),butterfly(蝴蝶),bicycle(自行车),apple(苹果),airplane(飞机)称为图形样本的类别,sketch(简笔画),cartoon(卡通画),art painting(艺术画),或photo(照片)称为图形样本数据的域(domain)或领域。
[0075]
本发明的信息识别系统的训练样本s、测试样本t具有图1中的数据集合101的形式。本发明的信息识别系统利用这样的训练样本进行学习,优化神经网络的参数,并从具有图1的数据集合101的形式的测试样本中选取样本数据,输入本发明的信息识别系统进行识别分类,确定输入的图片样本的类别。识别出的图形数据的类别称为类别标签(label),或类别标签值。
[0076]
实际的学习和测试中,训练数据经常没有图1中的数据集合101那样完整,可能仅有某几个领域的数据,而测试的样本则可能来源于任意领域,可能与训练数据的领域不同。在这种情形下,现有技术的识别系统可能存在学习不充分的问题,识别性能明显下降。
[0077]
本发明改善学习过程,增强系统的泛化性能,在测试样本与训练样本差异较大时,也能够快速适应并识别输入样本的类别。
[0078]
比如,本发明的信息识别系统的训练数据集s(也称为源域)、测试数据集t(也称为目标域)由图1的数据集合101中的若干个域构成,测试数据集t的域可能与训练数据集s的域不同,存在跨域,在这种情形下,现有技术的识别系统的识别性能明显下降。
[0079]
本发明中,将训练样本集s的多个域划分为模拟训练样本集ds(也称为元源域)和模拟测试样本集dt(也称为元目标域),来模拟训练过程和测试过程样本数据领域不同的情形,即,以源域上的训练、目标域的测试这样的任务作为训练样本,采用元学习框架,利用模拟训练样本集ds和模拟测试样本集dt的样本数据的类别c已知这个条件,通过以下所述本实施例的技术方案,改善在模拟训练样本集ds上的学习方式、优化神经网络参数,改善系统在模拟测试样本集dt上的测试性能,提高系统的泛化性能,保证在对测试数据集t的样本进行测试时,即使测试数据集t的域可能与训练数据集s的域有差异,也能够快速适应并识别输入样本的类别。
[0080]
以下,参照图2、图3、图4、图5具体说明本发明一个实施例的信息识别方法。
[0081]
图2是本发明一个实施例的信息识别方法100的学习阶段的流程图。
[0082]
图3是说明本发明一个实施例的信息识别方法100的学习阶段的示意图。
[0083]
如图2、图3所示,本发明一个实施例的信息识别方法100的学习阶段包括以下步骤。
[0084]
步骤s11,将训练样本集s划分为模拟训练样本集ds和模拟测试样本集dt。
[0085]
比如,假设训练样本集s(也称为源域)由图1的数据集合101中的若干个域构成,将训练样本集s中的若干个域定义为模拟训练样本集ds,训练样本集s中其余的域定义为模拟测试样本集dt。
[0086]
比如,在训练样本集s的多个样本域中,随机选择一个样本域作为模拟测试样本集dt,其余的样本域作为模拟训练样本集ds。
[0087]
步骤s12,参照图3,将模拟训练样本集ds的各个类别c的样本数据x
sc
、样本数据x
sc
的类别标签y
sc
输入编码器网络12。图3中,符号c表示合并输入。编码网络单元12对样本数据x
sc
进行条件变分编码,生成样本数据x
sc
在潜在空间z上的分布(以下称为第一分布)。
[0088]
这里,xs是模拟训练样本集ds的数据,即,图1中的图形样本,其类别c是已知的,类别作为已知信息输入编码器网络12,类别c的样本数据表示为x
sc
,x
sc
的类别标签表示为y
sc
。
[0089]
假设样本数据x
sc
在潜在空间z上的第一分布为高斯分布,其均值与方差为和
[0090]
类别变量c的取值从1到c,其中c为整体任务中的类别数。图3中,作为例子,示出类别1的样本数据x
s1
和类别标签y
s1
输入编码网络单元12。
[0091]
步骤s13,参照图3,将模拟测试样本集dt的样本数据x
t
输入先验网络14,先验网络单元14对样本数据x
t
进行变分编码,生成样本数据x
t
在潜在空间z的分布(以下称为第二分布)。
[0092]
这里,x
t
表示模拟测试样本集dt中的样本数据,即,图1中的图形。因为x
t
表示是测试样本集s中的数据,所以其类别是已知的,记为y
t
。以下也称y
t
为x
t
的真实类别标签。
[0093]
假设样本数据x
t
在潜在空间z上的第二分布为高斯分布,其均值与方差为μ
t
和σ
t
。
[0094]
步骤s14,计算各个类别c的第一分布之和与第二分布之间的kl距离,使该kl距离最小。
[0095]
kl距离,是kullback-leibler差异(kullback-leibler divergence)的简称,也叫做相对熵(relativeentropy),用来表达两个概率分布的差异程度。
[0096]
先验网络单元14是对输入样本进行识别的神经网络,其网络参数根据学习过程中获得的先验知识确定。在学习过程中,将编码网络单元12输出的第一分布与先验网络单元14输出的第二分布进行比较,使两者尽可能接近。
[0097]
步骤s15,如图2、图3所示,将模拟测试样本集dt的样本数据x
t
以及第一分布的参数输入解码器网络16,解码器网络16基于模拟测试样本集dt的样本数据x
t
以及第一分布的参数,生成样本数据x
t
的预测类别标签且使预测类别标签与样本数据x
t
的已知类别标签y
t
的交叉熵最小。
[0098]
交叉熵用于度量两个概率分布间的差异性信息。交叉熵在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。
[0099]
本实施例中,解码器网络16基于模拟训练样本集ds的样本在潜在空间z的第一分布,得到模拟测试样本集dt样本数据x
t
的预测类别标签并在学习过程中,使预测类别标签与样本数据x
t
的已知类别标签y
t
的交叉熵最小,增强泛化性能。
[0100]
步骤s16,比如,利用梯度下降法,更新编码器网络14、先验网络12、解码器网络16的参数。
[0101]
在以上实施例中,在学习阶段采用元学习框架,将类别已知的训练样本集s划分为模拟训练样本集ds和模拟测试样本集dt,模仿训练数据集和测试数据集的差异,以源域上的训练、目标域上的测试任务作为训练样本。在元学习框架下,模拟从源域到目标域的泛化,通过跨域的训练和测试过程获得泛化能力。
[0102]
编码网络单元12对模拟训练样本集ds的各个类别c的样本数据x
sc
进行条件变分编码(样本的已知标签信息作为输入信息),获得各个类别c的样本数据x
sc
在潜在空间z的分布(即,第一分布)。即,本发明中,将元学习框架和条件变分推理结合,条件变分推理具有较强建模能力,能更好地解决跨域建模的不确定性。在元学习框架下,重新推导出条件变分推理的下界,将变分推理过程转换为网络参数优化过程。
[0103]
先验网络对模拟测试样本集dt的样本数据x
t
进行变分编码,获得样本数据x
t
在潜在空间z的分布(即,第二分布),且使各个类别c的第一分布之和与第二分布之间的kl距离最小,即,使第一分布之和与第二分布之间的似然度最大,这可以减少模拟训练样本集ds和模拟测试样本集dt的跨度,从而在模拟训练样本集ds与模拟测试样本集dt存在差异的情况下,优化先验网络参数,增强泛化性能。
[0104]
图4是本发明一个实施例的信息识别方法100的测试阶段的流程图。
[0105]
图5是说明本发明一个实施例的信息识别方法100的测试阶段的示意图。
[0106]
步骤s31,将测试样本集t的测试样本数据x输入先验网络,先验网络生成测试样本数据x在潜在空间z的第三分布。
[0107]
步骤s32,将测试样本数据x和第三分布的参数输入解码器网络,解码器网络根据第三分布的参数生成测试样本数据x的预测类别标签
[0108]
测试样本集t中的图形样本的类别未知,有待识别。
[0109]
在测试阶段,使用学习阶段得到的优化后的先验网络、解码器网络的参数,先验网络生成样本数据x在潜在空间z的分布(即,第三分布),解码器网络对第三分布进行解码,得到样本数据x的预测类别标签
[0110]
由于在学习阶段,在模拟训练样本集ds与模拟测试样本集dt存在差异的情况下获得优化的先验网络、解码器网络的参数,泛化能力提高,所以即使测试样本集t与训练样本集s存在差异,测试阶段也能准确识别输入样本的类别,降低识别不确定性。
[0111]
作为一个实施例,在图2所示的步骤s12中,编码器网络生成的、不同类别的样本数据x
cs
的第一分布之间的wasserstein距离lw最大。
[0112]
wasserstein距离是在度量空间m,定义概率分布之间距离的距离函数,关于wasserstein距离的详细定义,将在以下详述。
[0113]
本实施例中,在结合元学习、条件变分的基础上,进一步加入wasserstein距离lw这一约束,要求不同类别的样本数据x
cs
在潜在空间z的第一分布之间的wasserstein距离lw最大,这使得潜在空间z中的不同类别的第一分布之间的距离拉大,从而进一步提高系统的预测性能。图3中例示了不同类别的样本数据x
cs
、x
ls
在潜在空间z的高斯分布与高斯分布之间的距离受wasserstein约束条件限制。
[0114]
以下详细说明本发明的信息识别方法的一个实施例。
[0115]
在学习阶段,输入系统的数据包括:包含k个域的训练样本集s,学习率λ,迭代次数num,特征提取网络h(*)。
[0116]
系统输出的数据包括:编码器网络g
θ
(*)、先验网络g
φ
(*)和解码器网络g
ψ
(*)的网络参数,用参数集合θ={θ,φ,ψ}表示。
[0117]
首先,初始化参数集合θ={θ,φ,ψ}。
[0118]
然后,执行图2中的步骤s11、s12、s13、s14、s15、s16的以下操作,并迭代num次,即it=1:num。
[0119]
步骤s11中执行以下步骤s111、s112的操作。
[0120]
步骤s111,在训练样本集s的1到k个域中,随机选择一个域作为模拟测试样本集dt,除模拟测试样本集dt外,其他k-1个域作为模拟训练样本集ds。
[0121]
步骤s112,分别从模拟训练样本集ds和模拟测试样本集dt中采样样本,表示为:
[0122][0123]
其中,m为模拟训练样本集ds的样本个数,n为模拟测试样本集dt的样本个数;
[0124]
步骤s12中执行以下步骤s121、s122、s123的操作。
[0125]
步骤s121,编码器网络生成的模拟训练样本集ds样本的第一分布(高斯分布)的均值和方差为μs、σs,令μs=0和σs=0。
[0126]
步骤s122,对于类别c=1:c,其中c为整体任务中的类别数(即,训练样本集s和测试样本集t的类别总数),即对每一个类别,执行以下操作:
[0127][0128][0129]
其中,mc为第c类样本总数,为模拟训练样本集ds中第c类样本特征表示的均值,和表示第c类样本在潜在空间z中产生的第一分布的均值和方差,μs和σs表示模拟训练样本集ds中所有样本生成的第一分布的均值和方差。
[0130]
特征提取网络h(*)用于提取图像等信息整体和细节的特征,例如根据图像的像素数据,用设计好的公式来检测图像的特征,包括角点、轮廓、颜色梯度等。
[0131]
步骤s123,计算wasserstein距离
[0132][0133]
其中,ε为实验中确定的固定的调节参数;
[0134]
步骤s13中执行以下步骤的操作。
[0135]
步骤s131,如下计算先验网络生成的模拟测试样本集dt的样本的第二分布(高斯分布)的参数:
[0136]
[0137]
其中,表示模拟测试样本集dt中所有样本特征表示的均值,μ
t
和σ
t
分别表示模拟测试样本集dt中所有样本生成的第二分布的均值和方差。
[0138]
步骤s14中执行以下的操作。
[0139]
步骤s141,计算由模拟训练样本集ds产生的第一分布和模拟测试样本集dt产生的第二分布之间的kl距离d
kl
:
[0140][0141]
其中,d为维数,和分别表示模拟测试样本集dt在潜在空间z中第二分布的均值和方差的第i维;和分别表示模拟训练样本集ds在潜在空间z中第一分布的均值和方差的第i维。
[0142]
步骤s15中执行以下步骤s151、s152的操作。
[0143]
步骤s151,令交叉熵函数初始值为0。
[0144]
步骤s152,对模拟测试样本集dt中所有样本,即n=1:n,执行以下步骤s1521至s1524的操作:
[0145]
步骤s1521,根据第一分布的参数μs和σs,重采样l次,第次重采样如下:
[0146][0147]
其中,
[0148]
步骤s1522,将潜在空间z的采样z
(l)
和结合,送入解码器网络,得到预测结果如下:
[0149][0150]
步骤s1523,对取平均,其中得到最后的预测值
[0151][0152]
步骤s1524,计算交叉熵如下:
[0153][0154]
其中,为模拟测试样本集dt第n个样本的已知类别标签,为模拟测试样本集dt第n个样本的预测类别标签。
[0155]
步骤s16中执行以下操作。
[0156]
步骤s161,如下计算整体损失函数
[0157][0158]
其中,为交叉熵,d
kl
为kl距离,为wasserstein距离。
[0159]
步骤s162,如下式所示,利用梯度下降法更新编码器网络、先验网络、解码器网络
的参数:
[0160][0161]
其中,θ为编码器网络、先验网络、解码器网络的参数,λ为学习率,或迭代步长,为梯度,为损失函数。
[0162]
在测试阶段,输入系统的数据包括:来自测试样本集t的测试样本x,模型参数θ={φ,ψ}。
[0163]
系统输出的数据包括:对测试样本集t的测试样本x的预测类别标签
[0164]
测试阶段执行如下步骤。
[0165]
步骤s31中执行以下操作。
[0166]
步骤s311,按照下式生成测试样本集t的测试样本x在隐含空间的第三分布(高斯分布)的均值μ和方差σ:μ,σ=g
φ
(h(x));
[0167]
步骤s32中执行以下步骤s321至s323的操作。
[0168]
步骤s321,使模拟测试样本集dt的预测类别标签
[0169]
步骤s322,根据第三分布的参数μ和σ,重采样l次,即执行以下操作:
[0170][0171][0172]
步骤s323,模拟测试样本集dt的预测类别标签
[0173]
步骤s152、步骤s322中,对第一分布、第三分布进行多次采样,将多个采样值z
l
以及样本数据x
t
输入解码器网络,得到多个预测类别标签,对该多个预测类别标签取平均,将得到的平均值作为样本数据x
t
的预测类别标签通过多次采样,能够有效避免跨域带来的域偏差对分类性能造成的影响,提高预测类别标签数据准确可靠性。
[0174]
以下,参照图6、7、8,说明本发明实施例的识别方法的识别性能。
[0175]
图6显示现有技术的识别方法的识别性能。
[0176]
图7显示现有技术的识别方法的识别性能。
[0177]
图8显示本发明实施例的识别方法的识别效果。
[0178]
图6至图8为图1所示的图形样本中的
‘
狗’图片的四个域(sketch,cartoon,art painting,photo)的样本的t-sne表示。
[0179]
t-sne(t-distributed stochastic neighbor embedding)是一种非线性降维算法,用于将高维空间的数据及表示降到二维或三维的低维度空间中,以便可以对其进行可视化展示。
[0180]
图6至图8中,每个点是每个样本在高维空间的特征利用t-sne方法降维到二维空间中的表示,其中横轴和纵轴分别表示降维后的两个维度,可以为任意两个维度。
[0181]
图6是预训练的alexnet情况下的样本的可视化表示。
[0182]
alexnet是一个网络模型。预训练指用imagenet的数据集进行训练、训练中没有任何参数修正。imagenet是一个用于视觉对象识别软件研究的大型可视化数据库。
[0183]
图7是适用条件变分推理时的样本的可视化表示。
[0184]
图8是适用本发明的元条件变分的样本的可视化表示。
[0185]
图6至图8中,不同的图标表示不同的域,圆形、三角形、星形和十字形中图标分别代表sketch,cartoon,art painting,photo四个域。在现有技术中,在没有适用泛化算法时,如图6所示,各个域之间的数据分布差异较大,各个域之间的数据彼此不相关,各自聚集度更高。在适用某种泛化算法后,如图7和图8所示,各个域之间的数据彼此交融,表明在训练数据与测试数据不同的情形下的泛化能力提高,识别性能提升。
[0186]
如图6所示,使用预训练的alexnet进行识别时,sketch,cartoon,art painting,photo四个域之间的特征分隔得较为清晰,域之间的表征存在较大差异,即,泛化能力很低。
[0187]
如图7所示,在条件变分推理的情形下,sketch,cartoon,art painting,photo四个域之间的特征分隔得到一定改善,四的域的图形的表示之间有融合,即,泛化能力优于预训练的alexnet。
[0188]
如图8所示,采用本发明的识别方法时,四个域之间的特征表示的融合性更好,说明本发明的识别方法能够有效消除域偏差,提高领域泛化性能,提高跨领域识别能力。
[0189]
图9是本发明一个实施例的信息识别系统10的结构示意图。
[0190]
如图9所示,本发明一个实施例的信息识别系统10包括编码网络单元12,先验网络单元14,解码器网络单元16。
[0191]
在学习阶段,模拟训练样本集ds的各个类别c的样本数据x
sc
、以及所述样本数据x
sc
的类别标签y
sc
输入编码网络单元12,编码网络单元12进行条件变分编码,生成样本数据x
sc
在潜在空间z的分布(即,第一分布)。
[0192]
本实施例中,编码网络单元12输出的不同类别c的样本数据x
cs
的第一分布之间的wasserstein距离lw最大。
[0193]
在学习阶段,模拟测试样本集dt的样本数据x
t
输入先验网络单元14,先验网络单元14进行变分编码,生成样本数据x
t
在潜在空间z的分布(即,第二分布)。
[0194]
信息识别系统10计算各个类别c的第一分布之和与第二分布之间的所述kl距离d
kl
,使kl距离d
kl
最小。
[0195]
先验网络单元14的网络参数是根据学习过程中获得的先验知识确定。在学习过程中,通过与编码网络单元12输出的条件变分编码的结果进行比较,优化先验网络14的参数,达到与编码网络单元12的条件变分编码同样的效果。
[0196]
在学习阶段,模拟测试样本集dt的的样本数据x
t
以及第一分布的参数输入解码器网络单元16,解码器网络单元16对输入数据进行解码,得到样本数据x
t
的预测类别标签这里,解码器网络单元16以预测类别标签与样本数据x
t
的已知的类别标签y
t
的交叉熵最小为条件确定预测类别标签
[0197]
在测试阶段,通过学习,网络参数得到优化的先验网络单元14接收测试样本集t的测试样本数据x,生成测试样本数据x在潜在空间z的分布,以下称之为第三分布。假定第三分布也为高斯分布。解码器网络单元16接收测试样本数据x和第三分布的参数,经过解码,得到测试样本数据x的预测类别标签
[0198]
本技术实施例的一种电子设备,包括一个或多个处理器及存储器,存储器上存储
有一个或多个计算机程序,当一个或多个处理器执行一个或多个计算机程序时,实现上述本技术实施例中任一项所述的信息识别方法步骤。
[0199]
本技术实施例的一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,计算机程序程序被处理器运行时实现上述本技术实施例中任一项所述的信息识别方法。
[0200]
以上各实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述各实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的范围,其均应涵盖在本技术的权利要求和说明书的范围当中。尤其是,只要不存在结构冲突,各个实施例中所提到的各项技术特征均可以任意方式组合起来。本技术并不局限于文中公开的特定实施例,而是包括落入权利要求的范围内的所有技术方案。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1