一种用于带钢缺陷分类的多阶段半监督深度学习方法
1.本发明涉及缺陷检测技术,尤其用于具有明显缺陷的带钢的缺陷分类方法,具体是一种用于带钢缺陷分类的多阶段半监督深度学习方法。
背景技术:
2.钢带是制造业的关键材料。然而,由于原材料和工艺的问题,在钢带生产过程中产生各种类型的缺陷似乎是不可避免的。在现代工业化生产线中,缺陷的分类和及时处理是非常重要的。在工业生产中,这些缺陷会在一定程度上影响产品的质量和外观,进而影响工厂的经济效益。表面缺陷分类是质量检验过程中的一个重要阶段,旨在确定缺陷的种类,以确保工业产品的表面质量。另一方面,表面缺陷检测和分类通常依赖于员工的经验,这既不可靠又耗时。相反,钢铁产品的自动监控有利于保证产品质量,不仅可靠、经济,而且大大提高了大型生产线的效率。随着深度学习技术的快速发展,使用深度学习中的计算机视觉技术对钢带缺陷进行分类已经广泛应用于工业界中。
3.在工业界及学术界中,为了提高现代工厂的生产率,减轻雇佣工人进行手工检测所带来的巨大经济负担,已经提出了许多缺陷检测方法。基于深度学习视觉的表面缺陷分类方法主要有两种:全监督分类方法和半监督分类方法,这两种方法都使用深度学习视觉对表面缺陷进行分类。这两种方法中,全监督分类方法通过使用大量的已标记数据对模型进行训练,虽然能取得较好的效果,但显然并不能满足工业界中仅使用少量标记样本完成训练的需求,所以并不能很好地在工业中落地。半监督分类方法同样基于深度学习和机器视觉,但其在保证模型分类精度的同时,克服了全监督分类方法所需标记样本量过多的不足。
4.在使用半监督分类的许多方法中,目前工业中使用的主要通过结合卷积自动编码器(convolutional auto-encode,简称cae)和半监督生成对抗网络(semi-supervised learning with generative adversarial networks,简称sgan),分类器是使用从真实生产线上拍摄的大量图片和sgan随机生成的图片进行训练的。
技术实现要素:
5.本发明的目的是针对现有半监督学习缺陷分类方法的不足,而提供一种用于带钢缺陷分类的多阶段半监督深度学习方法。这种方法解决了现有的全监督分类方法中对标注样本需求量大的问题,容易复现、速度快、精度高、易于推广应用。
6.实现本发明目的的技术方案是:
7.一种用于带钢缺陷分类的多阶段半监督深度学习方法,包括如下步骤:
8.(1)获取训练样本所需的图像数据,对获取到的图像进行分类标注,过程包括:
9.1-1)对于带钢生产流水线,采用工业摄像头以垂直于流水线的方向对带钢产品进行图像采集;
10.1-2)采用文件夹分类的方式对步骤1-1)采集的图像部分进行类别标注;
11.1-3)将采集到的图片中未进行标注的图像数据作为未标注数据集;
12.(2)图像预处理:将现有的公共缺陷分类图像数据集neu-cls中的全部图像像素重定义为[224,224]大小的图片;
[0013]
(3)划分数据集:已标注的图片中,将70%的图片作为训练集,20%的图片作为验证集,10%的图片作为测试集;
[0014]
(4)将步骤(3)划分的训练集和验证集输入到深度残差网络resnet-50中对像素重定义后的缺陷分类图像进行特征提取,对特征进行分层提取操作,其中深度残差网络resnet-50包括:输入层,最大池化层,convblock,identityblock,残差网络的特性消除了模型训练过程中的梯度消失现象,提高缺陷分类的准确率;
[0015]
(5)convblock输入和输出的维度一样,连续串联多个convblock以实现卷积计算;identityblock输入和输出的维度不一样,所以不能连续串联,identityblock作用是为了改变特征向量的维度;
[0016]
(6)将注意力模型squeeze-and-excitation(se-net)网络模块插入到深度残差网络resnet-50结构的末尾;
[0017]
(7)深度残差网络将提取到的特征信息输出到注意力模型se-net网络模块中,该注意力模型模拟人眼的视觉机制,在复杂的图片中专注于目标区域,忽略无关信息;
[0018]
(8)特征信息在se-net网络模块中进行通道注意,过程包括:
[0019]
8-1)采用squeeze操作将通道上的整个空间特征转化为全局特征,并使用全局平均池化及自适应大小的一维卷积来得到每个通道上的平均池化结果,设h是单个特征通道特征图的高度,w表示单个特征通道特征图的宽度,yc(i,j)表示特征图通道上每个点的值,写为:
[0020][0021]
8-2)采用excitation操作捕获通道之间的关系,通过使用多通道特征并结合激活函数relu进行通道特征提取,设w1和w2是两个全连接层,σ表示激活函数,写为:
[0022]fex
(z,w)=σ(g(z,w))=σ(w2relu(w1z)(1.2);
[0023]
(9)采用步骤2)中得到的图像作为深度残差网络的输入,在使用深度残差网络进行训练后,对深度残差网络输出的缺陷分类模型进行保存;
[0024]
(10)采用步骤(9)中保存的缺陷分类模型对未标注的图像数据进行分类,并进行多阶段训练,得到一个新的分类模型;对步骤1-3)中的未标注数据集中的所有图像进行预测,记录每张图片的预测结果及置信度;
[0025]
(11)计算步骤(10)中记录图片的置信度的平均值,采用置信度高于置信度平均值的未标注数据,将新的分类模型预测得到的类别作为该未标注数据的伪标签,将其视为已标注数据,重复步骤(10)并保存每次输出的新的分类模型,直至完成全部未标注的图像预测;最后分别使用不同的分类模型对步骤(3)中划分的测试集进行预测,采取预测准确率最高的分类模型作为最终的模型。
[0026]
本技术方案的技术效果在于:本技术方案通过带钢缺陷图像的特点,针对深度残差网络resnet-50对于图像特征提取的良好性能,提出了利用resnet-50结合se-net注意力机制实现的半监督深度学习缺陷分类方法。该分类模型可以在仅有少量已标注数据的情况
下,有效地利用大量的未标注数据对模型进行增强,提高模型对缺陷图像的分类准确率。
[0027]
这种方法易于实现、分类准确率高,易于推广应用。
附图说明
[0028]
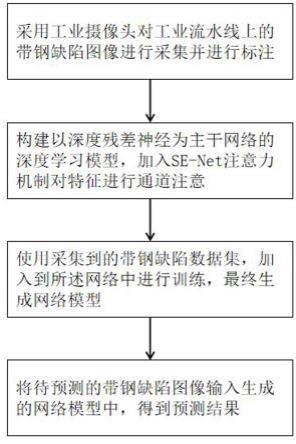
图1为实施例的流程示意图;
[0029]
图2为实施例中主干网络resnet的示意图;
[0030]
图3为实施例中注意力机制se-net示意图;
[0031]
图4为实施例中多阶段学习的示意图。
具体实施方式
[0032]
下面结合附图及具体实施例对本发明作进一步的详细描述,但不是对本发明的限定。
[0033]
实施例:
[0034]
参照图1,一种用于带钢缺陷分类的多阶段半监督深度学习方法,包括如下步骤:
[0035]
(1)获取训练样本所需的图像数据,对获取到的图像进行分类标注,过程包括:
[0036]
1-1)对于带钢生产流水线,采用工业摄像头以垂直于流水线的方向对带钢产品进行图像采集;
[0037]
1-2)采用文件夹分类的方式对步骤1-1)采集的图像进行类别标注;
[0038]
1-3)将采集到的图片中未进行标注的图像数据作为未标注数据集;
[0039]
(2)图像预处理:将现有的公共缺陷分类图像数据集neu-cls中的全部图像像素重定义为[224,224]大小的图片,本例缺陷分类图像数据集neu-cls取自http://faculty.neu.edu.cn/songkechen/zh_cn/zhym/263269/list/index.htm;
[0040]
(3)划分数据集:已标注的图片中,将70%的图片作为训练集,20%的图片作为验证集,10%的图片作为测试集;
[0041]
(4)如图2所示,将步骤(3)划分的训练集和验证集输入到深度残差网络resnet-50中对像素重定义后的缺陷分类图像进行特征提取,对特征进行分层提取操作,其中深度残差网络resnet-50包括:输入层,最大池化层,conv block,identity block;
[0042]
(5)conv block输入和输出的维度是一样的,连续串联多个conv block是为了实现卷积计算;identity block输入和输出的维度是不一样的,所以不能连续串联,identity block作用是为了改变特征向量的维度;
[0043]
(6)如图3所示,将注意力模型squeeze-and-excitation(se-net)网络模块插入到深度残差网络resnet-50网络结构的末尾;
[0044]
(7)深度残差网络将提取到的特征信息输出到注意力模型se-net网络模块中,该注意力模型模拟人眼的视觉机制,在复杂的图片中专注于目标区域,忽略无关信息;
[0045]
(8)特征信息在se-net网络模块中进行通道注意,过程包括:
[0046]
8-1)采用squeeze操作将通道上的整个空间特征转化为全局特征,并使用全局平均池化及自适应大小的一维卷积来得到每个通道上的平均池化结果,设h是单个特征通道特征图的高度,w表示单个特征通道特征图的宽度,yc(i,j)表示特征图通道上每个点的值,写为:
[0047][0048]
8-2)采用excitation操作捕获通道之间的关系,通过使用多通道特征并结合激活函数relu进行通道特征提取,设w1和w2是两个全连接层,σ表示激活函数,写为:
[0049]fex
(z,w)=σ(g(z,w))=σ(w2relu(w1z)(1.2);
[0050]
(9)采用步骤(2)中预处理得到的图像作为深度残差网络的输入,在使用深度残差网络进行训练后,对深度残差网络输出的缺陷分类模型进行保存;
[0051]
(10)采用步骤(9)中保存的缺陷分类模型对未标注的图像数据进行分类,如图4所示,并进行多阶段训练,得到一个新的分类模型;对步骤1-3)中的未标注数据集中的所有图像进行预测,记录每张图片的预测结果及置信度;
[0052]
(11)计算步骤(10)中记录图片的置信度的平均值,采用置信度高于置信度平均值的未标注数据,将新的分类模型预测得到的类别作为该未标注数据的伪标签,将其视为已标注数据,重复步骤(10)并保存每次输出的新的分类模型,直至完成全部未标注的图像预测;最后分别使用不同的分类模型对步骤(3)中划分的测试集进行预测,采取预测准确率最高的分类模型作为最终的模型。
[0053]
本例以neu-cls作为缺陷分类图像数据集,经过独立的重复实验,每次实验均取步骤(11)中最终的模型作为预测模型,得到缺陷分类准确率为98.29%;
[0054]
结果表明,本例方法的准确率高,所需的已标注图片少,更适合在缺少标注样本的条件下使用。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1