基于多目标跟踪的卡丁车比赛行为分析方法
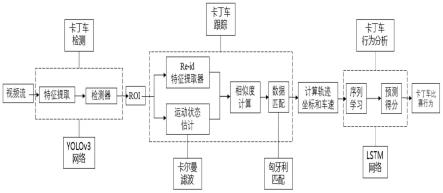
1.本发明属于视觉目标跟踪技术领域,具体涉及一种基于多目标跟踪的卡丁车比赛行为分析方法。
背景技术:
2.在各种汽车类运动中,卡丁车具有速度快、体积小、轨迹多变等特点,人们无法准确判断卡丁车的运动行为、测量卡丁车的运动速度,运动轨迹无法保留,经常错过比赛过程中的精彩画面。因此,需要对卡丁车进行检测、跟踪、分析,从而获得卡丁车比赛过程中的一些精彩运动信息。
3.常用的线圈检测器方法,只能定点检测经过的卡丁车,功能比较单一,并且安装维护时需要破坏卡丁车赛道。雷达、红外探测等方法相关设备昂贵,只能识别是否有卡丁车经过,测得其速度。利用gps的方法需要配合其他相关设备,且在室内gps信号会受到影响。以上方法的使用范围受到很多限制。
4.通过计算机视觉技术对卡丁车比赛的监控视频进行分析可以采集多种信息,而且开发和维护成本较低,可以广泛应用。由于监控系统汇集了大量的视频,视频中存在一些无可利用信息的片段,利用深度学习目标检测技术,可以排除监控视频中存在的冗余视频片段,相较于传统的运动目标检测技术,可以排除其它非目标的运动物体的影响。
技术实现要素:
5.本发明的目的是提供基于多目标跟踪的卡丁车比赛行为分析方法,解决现有技术中存在的卡丁车比赛中无法准确识别运动行为的问题。
6.本发明所采用的技术方案是,基于多目标跟踪的卡丁车比赛行为分析方法,具体按照以下步骤实施:
7.步骤1,制作卡丁车目标检测数据集,并训练卡丁车目标检测所需的yolov3网络权重;
8.步骤2,选取待处理的卡丁车监控视频,读取视频的第一帧图像,利用yolov3目标检测网络和步骤1训练得到的网络权重,检测视频帧图像中的卡丁车的位置,并绘制每辆卡丁车的外接矩形检测框,提取卡丁车的图像特征;
9.步骤3,读取视频的第二帧图像,利用yolov3目标检测网络和网络权重,检测视频帧图像中的卡丁车的位置,绘制卡丁车的外接矩形检测框,提取卡丁车的图像特征;然后通过卡尔曼滤波预测卡丁车的运动状态;
10.步骤4,将步骤2和步骤3得到的图像特征和检测框进行相似度计算,输出相似度矩阵;
11.步骤5,采用匈牙利算法以及步骤4得出的相似度矩阵对历史帧检测框id和当前预测框进行匹配,完成对卡丁车的多目标跟踪;
12.步骤6,采用直接线性变换法对卡丁车赛道进行场景标定,实现视频中的像素坐标
与其在真实世界中点的坐标之间进行互相转换,输出卡丁车在真实世界中的坐标变化;
13.步骤7,重复步骤3至步骤6,直到读取完视频中的图像,输出每辆卡丁车在视频中完整的运动轨迹和速度时序变化,并保存到csv格式的文件中;
14.步骤8,将步骤7中有车辆碰撞、超车、缠斗行为的卡丁车运动轨迹csv文件输入到lstm网络中训练,直到网络的损失函数趋于收敛,保存训练得到的权重;
15.步骤9,通过训练好的lstm网络,读取步骤7中卡丁车跟踪得到的csv格式轨迹和速度数据,输出包括碰撞、超车、缠斗或无特殊行为分类标签,即可得到该视频中卡丁车行为分析结果。
16.本发明的特点还在于,
17.步骤1中,具体过程如下:
18.步骤1.1,将卡丁车监控视频拆分成帧图像,通过labelimg目标检测标注工具将每一帧图像中的卡丁车进行数据标注,形成卡丁车检测数据集;
19.其中,标注的信息有filename:图片的文件名;name:标注物体名称;xmin、ymin:卡丁车位置的左上角坐标;xmax、ymax:卡丁车位置的右下角坐标;
20.步骤1.2,使用yolov3网络对步骤1.1制作的卡丁车检测数据集进行训练,直到损失函数趋于收敛,保存训练好的网络权重文件。
21.步骤4中,具体为:将步骤2和步骤3的检测框提取到的两帧图像特征进行余弦距离计算;将步骤3卡尔曼滤波算法预测的检测框和步骤2中的检测框进行马氏距离计算,把这两个距离进行融合输入到相似度计算的矩阵里面,输出相似度矩阵。
22.步骤8中,具体为:
23.步骤8.1,将目标跟踪得到的卡丁车比赛行为轨迹和速度数据,按照时序排列存放到.csv文件中;
24.步骤8.2,使用python编程读入.csv文件,并存放到数据结构list中;以one-hot的方式对数据标签进行编码,[1,0,0]表示碰撞,[0,0,1]表示超车,[0,1,0]表示缠斗;
[0025]
步骤8.3,将数据和标签转成tensorflow框架所支持的张量形式,传输给lstm网络并且加入注意力机制训练,将训练好的网络权重保存为.h5文件。
[0026]
本发明的有益效果是,本发明的方法,可以识别卡丁车的比赛行为和记录有车辆碰撞、超车、缠斗等精彩行为的画面,提供车手和观众回顾、观赏和留念;还可以识别记录同一画面多辆车的运动轨迹,分析多辆卡丁车之间的行为;较传统方法来说能够使卡丁车检测的精度更高、效率更高、智能化程度更高,排除其他非目标运动物体的干扰。
附图说明
[0027]
图1是本发明基于多目标跟踪的卡丁车比赛行为分析方法的流程图;
[0028]
图2是本发明方法中卡丁车跟踪结果图;
[0029]
图3是本发明方法中卡丁车行为分析结果图。
具体实施方式
[0030]
下面结合附图和具体实施方式对本发明进行详细说明。
[0031]
本发明基于多目标跟踪的卡丁车比赛行为分析方法,如图1所示,具体按照以下步
骤实施:
[0032]
步骤1,制作卡丁车目标检测数据集,并训练卡丁车目标检测所需的yolov3网络权重,具体过程如下:
[0033]
步骤1.1,将卡丁车监控视频拆分成帧图像,通过labelimg目标检测标注工具将每一帧图像中的卡丁车进行数据标注,形成卡丁车检测数据集;
[0034]
其中,标注的信息有filename:图片的文件名;name:标注物体名称(卡丁车);xmin、ymin:卡丁车位置的左上角坐标;xmax、ymax:卡丁车位置的右下角坐标;
[0035]
步骤1.2,使用yolov3网络对步骤1.1制作的卡丁车检测数据集进行训练,直到损失函数趋于收敛,保存训练好的网络权重文件;
[0036]
步骤2,选取待处理的卡丁车监控视频,读取视频的第一帧图像,利用yolov3目标检测网络和步骤1训练得到的网络权重,检测视频帧图像中的卡丁车的位置,并绘制每辆卡丁车的外接矩形检测框(roi),提取卡丁车的图像特征;
[0037]
步骤3,读取视频的第二帧图像,利用yolov3目标检测网络和步骤1训练得到的网络权重,检测视频帧图像中的卡丁车的位置,并绘制每辆卡丁车的外接矩形检测框(roi),提取卡丁车的图像特征;然后通过卡尔曼滤波预测卡丁车的运动状态,即检测框的位置和移动速度;
[0038]
采用卡尔曼滤波算法估计物体运动状态,即检测框的位置和移动的速度。根据历史帧的信息,能够得到当前帧的检测框的位置和估计值,根据现有帧的检测器,可以得到当前检测框位置的观测值,卡尔曼滤波综合估计值和观测值,获得更加精准的数值。
[0039]
(1)预测阶段:通过之前边界框移动的信息,预测出当前框的位置。
[0040]
预测当前最佳估计值:
[0041]
预测当前的协方差矩阵:pk=fkp
k-1ft
+qk[0042]
(2)修正阶段:
[0043]
计算卡尔曼增益:
[0044]
更新最佳估计:
[0045]
更新协方差矩阵:p
′k=p
k-k
′hk
pk[0046]
其中输入的变量xk=[cx,cy,w,h,vx,vy,vw,vh]是四维检测框相关变量和四维检测框相关变量的动量,cx,cy为边界框的中心点;w,h为边界框的宽和高,vx,vy,vw,vh为上述变量的变化速度;f为状态转移矩阵,用来对目标的运动建模;pk代表位置精确度(即协方差矩阵);qk为环境中的噪声,即预测过程中所带来的干扰;k
′
是滤波增益矩阵,是滤波的中间计算结果;hk是状态变量到观测值的转换矩阵,将m维的测量值转换到n维,使之符合状态变量的数学形式;r为测量噪声协方差;
[0047]
通过当前帧的修正可以得到现在的估计值,把估计值拿到下一帧,预测下一帧的数值,预测出来以后又通过修正进一步进行迭代,通过不断的迭代卡尔曼滤波估计使运动状态越来越精准。
[0048]
步骤4,将步骤2和步骤3得到的图像特征和检测框进行相似度计算,输出相似度矩阵;
[0049]
具体为:将步骤2和步骤3的检测框提取到的两帧图像特征进行余弦距离计算;将
步骤3卡尔曼滤波算法预测的检测框和步骤2中的检测框进行马氏距离计算,把这两个距离进行融合输入到相似度计算的矩阵里面,输出相似度矩阵;
[0050]
步骤5,采用匈牙利算法和步骤4得出的相似度矩阵对历史帧检测框id和当前预测框进行匹配(即得出当前帧检测出的卡丁车1是上一帧id为1的卡丁车),完成对卡丁车的多目标跟踪;
[0051]
步骤6,计算卡丁车的速度并提取卡丁车的运动轨迹;采用直接线性变换(dlt)法对卡丁车赛道进行场景标定,实现视频中的像素坐标与其在真实世界中点的坐标之间进行互相转换,即可以输出卡丁车在真实世界中的坐标变化;
[0052]
具体过程如下:
[0053]
步骤6.1,在卡丁车赛道上放置四个特征点(圆点)标志物,四个点形成一个矩形,以矩形中一个点为坐标原点,建立卡丁车赛道平面坐标系,然后测量每个点之间的距离,得到四个点在卡丁车赛道平面坐标系上的坐标;通过上述四个点可以求出摄像头的内外参数。卡丁车赛道平面坐标p=(x,y,z)与图像坐标p=(x,y)之间的映射关系为:
[0054][0055]
其中,s是个非零实数,k为相机内参矩阵;r为旋转矩阵、t为平移矩阵,属于相机外参;
[0056]
步骤6.2,截取监控摄像头四个标志点的赛道图像,利用霍夫圆检测,检测出图像中的特征点(圆点)标志,并输出圆心的像素坐标;
[0057]
步骤6.3,利用上述信息,采用直接线性变换(dlt)法求出卡丁车赛道平面坐标系和赛道图像坐标系之间的转换关系;根据步骤6.1公式得出从卡丁车赛道平面坐标到图像坐标的映射f的表达式:
[0058][0059]
其中,a=kr=(a
ij
),1≤i,j≤3,b=kt=(b1,b2,b3)
t
。
[0060]
步骤7,重复步骤3至步骤6,直到读取完视频中的每一帧图像,输出每辆卡丁车在视频中完整的运动轨迹和速度时序变化,并保存到csv格式的文件中;
[0061]
步骤8,将步骤7中有车辆碰撞、超车、缠斗行为的卡丁车运动轨迹csv文件输入到lstm网络中训练,直到网络的损失函数趋于收敛,保存训练得到的权重;具体为:
[0062]
步骤8.1,将目标跟踪得到的卡丁车比赛行为轨迹和速度数据,按照时序排列存放到.csv文件中;
[0063]
步骤8.2,使用python编程读入.csv文件,并存放到数据结构list中;以one-hot的方式对数据标签进行编码,[1,0,0]表示碰撞,[0,0,1]表示超车,[0,1,0]表示缠斗;
[0064]
步骤8.3,将数据和标签转成tensorflow框架所支持的张量形式,传输给lstm网络并且加入注意力机制训练,将训练好的网络权重保存为.h5文件;
[0065]
步骤9,通过训练好的lstm网络,读取步骤7中卡丁车跟踪得到的csv格式轨迹和速度数据,输出包括碰撞、超车、缠斗或无特殊行为分类标签,即可得到卡丁车行为分析结果。
[0066]
本发明的方法可以有效并精确地识别视频帧中的卡丁车,标记卡丁车的位置,并且在8个不同场景的监控视频帧得到的400幅卡丁车图像数据集上测试,结果如表1,平均检测精准度在91.38%-99.76%之间。
[0067]
表1卡丁车检测实验结果
[0068][0069]
上述评价指标如下所示:
[0070]
精确率:正确预测为正样本的占全部预测为正样本的比例,即模型检测出来的目标有多大比例是真正的目标物体。
[0071][0072]
召回率:正确预测为正样本的占全部实际为正样本的比例,即所有真实的目标有多大比例被模型检测出来了。
[0073][0074]
平均精准度是对precision-recall(pr)曲线上的精确率的值求均值。使用对pr曲线积分来进行计算。
[0075]
图2为卡丁车跟踪结果,图3为卡丁车行为分析结果,由图可知,本方法可以识别卡丁车的比赛行为;另外,本发明的方法可以跟踪连续视频帧中的不同车辆,绘制出它们的运动轨迹,并且在一段时常30s,帧率25fps的视频测得本方法的多目标追踪精度为90.6%。
[0076]
mota(multiple object tracking accuracy)多目标跟踪的准确度,如式所示:
[0077][0078]
式中,idsw
t
表示在时间t内id改变的总数量,fn
t
(false negatives)为t时间内的漏检总数,也即是未匹配成功的真实值个数;fp
t
(false positives)称为误检总数,也即是预测错误的跟踪结果个数。gt
t
(ground truth)为t时间内跟踪目标个数。
[0079]
本发明的方法可以分析监控视频中卡丁车比赛过程中的比赛行为和记录有车辆碰撞、超车、缠斗等行为的精彩画面,提供车手和观众回顾、观赏和留念。自动化测量卡丁车的运动速度,保留运动轨迹。采用深度学习的卡丁车检测方法,较传统方法来说能够使卡丁车检测的精度更高、效率更高、智能化程度更高,排除其他非目标运动物体的干扰。采用多目标跟踪的卡丁车跟踪方法,可以识别记录同一画面多辆车的运动轨迹,分析多辆卡丁车之间的行为。其开发维护成本低,减少资源浪费,自动化程度高并且广泛适用于对卡丁车比赛行为分析。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1