一种面向主题语义的图像检索方法与流程
1.本发明涉及图像检索技术领域,尤其涉及一种面向主题语义的图像检索方法。
背景技术:
2.传统图像检索技术是基于内容的图像检索技术(cotent-based image retrieval,cbir)。其基本思路是从图像中抽取低层视觉特征,如颜色、纹理与形状等,然而基于这些特征将用户查询的图像与数据库中的图像进行相似程度衡量,检索出与用户查询图像在视觉特征上相似的图像。然而,用户更需要地是从语义层面、主题层面进行图像检索,如“人与大自然”、“体育盛会”,而同一图像主题未必有相似的低层视觉特征。因此,基于内容的传统图像检索技术还不足以支撑面向主题的图像检索。相比之下,本发明针对面向主题语义的图像检索,创新提出了一种基于图像实体检测的图像主题检索方法。
技术实现要素:
3.发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种面向主题语义的图像检索方法。
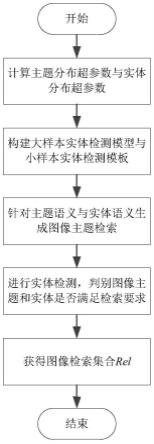
4.为了解决上述技术问题,本发明公开了一种面向主题语义的图像检索方法,包括:
5.步骤1,根据开源图像样本分别计算主题分布超参数与实体分布超参数;
6.步骤2,构建大样本实体检测模型与小样本实体检测模板;
7.步骤3,针对主题语义与实体语义生成图像主题检索;
8.步骤4,进行实体检测,判别图像的主题语义与实体语义是否满足检索要求;
9.步骤5,重复执行步骤4,获得图像检索集合rel。
10.进一步的,假设每一幅图像主题属于k个主题中的一个且主题在k个主题类别中的概率分布属于狄利克雷dirichlet分布,表示主题分布超参数,k≥1;。进一步假设各主题k分别对应一个实体分布且该实体分布属于dirichlet分布,表示实体分布超参数,其中n表示实体类别数目,1≤k≤k。另外,假设能够获取大量百度百科等开源图像样本,而每一图像在进行实体检测以后可表示为一个实体集合。在上述假设条件下,所述步骤1包括如下步骤:
11.步骤1.1主题分布超参数计算:基于百度百科等开源图像样本构建k个主题的图像训练样本集合,将训练样本在k个主题上的分布比例记为r1、r2、
……
、rk,根据公式(1)计算dirichlet主题分布中的主题分布超参数
[0012][0013]
步骤1.2实体分布超参数计算:根据每一主题k上各图像训练样本中实体分布,分别根据该主题中实体类别出现频率对n类实体由高到低进行排序,记为o
k1
、o
k2
、
……
、o
kn
,假设其中nh类为样本数量不少于ns的大样本实体类别数目,n
l
类为样本数量小于ns的小样本实体类别数目,n=nh+n
l
,ns表示样本数量阈值,将各主题k上n个实体的分布比例记为r
k1
、r
k2
、
……
、r
kn
,则根据公式(2)计算各主题k对应dirichlet实体分布的实体分布超参数
[0014][0015]
进一步的,所述步骤2中构建大样本实体检测模型是基于yolo模型(参考文献:redmon,j.,divvala,s.,girshick,r.,farhadi,a.:you only look once:unified,real-time object detection,cvpr2016)构建大样本实体检测模型,其输入是nh类大样本实体类别的训练样本,针对各图像主题k,将实体类别按其在主题中的出现频率由高到低进行排序,假设所有样本已标注位置和类别,选取已标注位置和类别的nk类高频实体e
kp
(1≤p≤nk)样本对第k个yolo模型进行训练,1≤nk≤nh,p表示高频实体索引;如果同一大样本实体类别对应多个yolo模型,则选取其中平均重叠度(iou,intersection over union)最优的yolo模型对其类别置信度与位置进行检测,针对各大样本实体类别选择其最优yolo模型来构建大样本实体检测模型,进而基于大样本实体检测模型检测获得训练样本中nh类大样本实体类别的实体检测位置坐标(x坐标、y坐标)、检测宽度(w)、检测高度(h)、类别置信度。
[0016]
进一步的,所述步骤2中构建小样本实体检测模板包括:针对n
l
个小样本实体类别,基于m个hu不变矩(参考文献:基于hu不变矩的图像形状特征提取研究,《网络安全技术与应用》,2017)构建小样本实体检测模板,即行数为n
l
、列数为m的hu不变矩矩阵humatrix,其中矩阵单元humatrix(q,m)表示小样本实体类别q的第m个hu不变矩在该实体类别样本上
的平均值,其中m≥5,1≤q≤n
l
,1≤m≤m;
[0017]
进一步的,步骤3包括面向主题语义的图像检索条件设置和图像检索初始化,所述面向主题语义的图像检索条件设置从主题检索范围与实体检索范围等2个维度设置面向主题语义的数据库图像检索,包括:
[0018]
主题语义设置:根据待检索图像的主题设置数据库检索的主题范围,该主题范围表示为一个集合t,
[0019]
实体语义设置:根据待检索图像的实体设置数据库检索的实体范围,该实体范围表示为一个集合e,其中r表示设置的实体数目,1≤r≤n;
[0020]
图像检索初始化包括:将图像检索集合rel初始化为空集,即将待检索图像的数目num初始化为数据库中的图像数目,将当期待检索图像索引g初始化为0,即g=0;
[0021]
进一步的,步骤4包括:
[0022]
步骤4-1,待检索图像数目判断:判断数据库待检索图像的数目num是否为零,如果是跳至步骤5,如果否继续步骤4-2;
[0023]
步骤4-2,图像索引更新:更新当前图像索引为g=g+1,更新数据库待检索图像数目num=num-1;
[0024]
步骤4-3,检测大样本实体;
[0025]
步骤4-4,检测小样本实体;
[0026]
步骤4-5,构建实体检测矩阵;
[0027]
步骤4-6,判断图像主题和实体类别,获得检索结果。
[0028]
进一步的,步骤4-3包括:基于大样本实体检测模型对大样本实体类别进行检测,检测结果包括nh个大样本实体类别所属实体eh的x、y坐标、检测窗口的宽度、高度、nh类大样本实体类别中最高置信度及对应类别,分别表示为:x(eh)、y(eh)、w(eh)、h(eh)、maxconf(eh)及cls(eh),最高置信度与对应类别cls(eh)满足:
[0029][0030]
cls(eh)=argmaxu(conf(eh,u))
ꢀꢀꢀ
(4)
[0031]
其中,conf(eh,u)表示大样本实体eh在第u个类别上的置信度,1≤u≤nh;
[0032]
进一步的,所述步骤4-4包括:大样本实体检测以后,基于grabcut算法将图像剩余部分分割成若干区域,每个区域对应一个候选小样本实体e
l
,其对应的m个hu不变矩特征记为hu(e
l
,m),1≤m≤m,根据公式(5)计算候选小样本实体e
l
隶属于第q个小样本实体类别的置信度conf(e
l
,q),1≤q≤n
l
:
[0033][0034]
进而得到候选小样本实体e
l
隶属于n
l
个小样本实体类别的置信度,小样本实体检测结果包括小样本实体的x、y坐标、检测窗口宽度w、检测窗口高度h、n
l
个小样本实体类别中最高置信度及对应类别,分别表示为:x(e
l
)、y(e
l
)、w(e
l
)、h(e
l
)、maxconf(e
l
)及cls(e
l
),对应类别cls(e
l
)满足:
[0035][0036]
cls(e
l
)=argmaxq(conf(e
l
,q))
ꢀꢀꢀ
(7)
[0037]
其中,conf(e
l
,q)表示小样本实体e
l
在第q个类别上的置信度。
[0038]
进一步的,所述步骤4-5包括:基于大样本实体检测结果与小样本实体检测结果,综合生成|es|
×
6的实体检测矩阵darray,es表示大样本实体检测与小样本实体检测中类别置信度大于门限δ的实体数目,即
[0039]
es={e|(e∈{eh}||e∈{e
l
})&&maxconf(e)≥0.8)}
ꢀꢀꢀ
(8)
[0040]
6列则分别表示对应实体e∈es在图像g中的x坐标、y坐标、宽度w、高度h、实体类别cls与类别置信度conf,如果实体e属于大样本实体,e∈eh,对应步骤9中的大样本实体检测结果,即分别对应x(eh)、y(eh)、w(eh)、h(eh)、cls(eh)及maxconf(eh),如果属于小样本实体则对应步骤10中的小样本实体检测结果,即分别对应x(e
l
)、y(e
l
)、w(e
l
)、h(e
l
)、cls(e
l
)及maxconf(e
l
);
[0041]
进一步的,所述步骤4-6包括:
[0042]
步骤4-6-1,图像主题判断:判断图像g的主题是否符合查询要求,根据公式(9)判断图像g所属主题topic:
[0043][0044]
其中,p(θk)表示图像g隶属于主题k的概率,p(cls(e)|θk)表示实体e隶属于主题k的概率,conf(e)表示实体e的类别置信度;如果图像g的主题topic属于检索主题范围t,即topic∈t,如果是继续步骤4-6-2,否则跳至步骤4-1;
[0045]
步骤4-6-2,实体类别判断:判断实体检测矩阵darray中的实体集合是否包含数据库检索的实体范围e,即如果是继续步骤4-6-3,否则跳至步骤4-1;
[0046]
步骤4-6-3,图像输出:将图像g加入检索集合,即rel=rel∪{g},跳至步骤4-1。
[0047]
有益效果:(1)克服了传统基于内容的图像检索技术通过颜色、纹理与形状等低层视觉特征相似性进行图像检索而忽略高层语义的局限性,创新提出了面向高层语义主题检索的新技术;(2)语义检测与实体检测既相互关联也相互独立,有利于根据主题语义检索需求对实体检索技术不断优化改进,具有高度的灵活性;(3)latent dirichlet allocation(lda)模型有利于描述复杂主题语义、实体语义的图像检索,细化图像主题语义的描述粒度。
附图说明
[0048]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述或其他方面的优点将会变得更加清楚。
[0049]
图1是本发明实施例提供的一种面向主题语义的图像检索方法的流程图一。
[0050]
图2是本发明实施例提供的一种面向主题语义的图像检索方法的流程图二。
具体实施方式
[0051]
下面结合附图及实施例对本发明做进一步说明。
[0052]
本发明实施例公开了一种面向主题语义的图像检索方法,借鉴了隐狄利克雷分配模型(latent dirichlet allocation,lda)模型,假设每一幅图像主题属于k个主题中的一
个且主题在k个主题类别中的概率分布属于dirichlet分布;每个主题分别对应一个实体分布且该实体分布属于dirichlet分布;每一图像在进行实体检测以后可表示为一个实体集合,如图1所示,所述方法包括:
[0053]
步骤1,根据开源图像样本分别计算主题分布超参数与实体分布超参数;
[0054]
步骤2,针对大样本实体与小样本实体分别构建基于目标检测网络yolo(you only look once,)的大样本实体检测模型与小样本实体检测模板;
[0055]
步骤3,针对主题语义与实体语义生成图像主题检索;
[0056]
步骤4,基于大样本实体检测模型与小样本实体检测模板对数据库中图像进行实体检测,判别图像的主题语义与实体语义是否满足检索要求;
[0057]
步骤5,重复执行步骤4,输出满足检索要求的数据库图像集合,即图像检索集合rel。
[0058]
本发明实施例假设每一幅图像主题属于k个主题中的一个且主题在k个主题类别中的概率分布属于dirichlet分布,表示主题分布超参数,k≥1。进一步假设各主题k分别对应一个实体分布且该实体分布属于dirichlet分布,表示实体分布超参数,其中n表示实体类别数目,1≤k≤k。另外,假设能够获取大量百度百科等开源图像样本,而每一图像在进行实体检测以后可表示为一个实体集合。如图2所示,在上述假设条件下,所述步骤1具体包括以下步骤:
[0059]
步骤1.1,主题分布超参数计算:基于百度百科等开源图像样本构建k个主题的图像训练样本集合,将训练样本在k个主题上的分布比例记为r1、r2、
……
、rk,根据公式(1)计算dirichlet主题分布中的主题分布超参数
[0060][0061]
步骤1.2,实体分布超参数计算:根据每一主题k上各图像训练样本中实体分布,分别根据该主题中实体类别出现频率对n类实体由高到低进行排序,记为o
k1
、o
k2
、
……
、o
kn
,假设其中nh类为样本数量不少于200的大样本实体类别数目,n
l
类为样本数量小于200的小样本实体类别数目,n=nh+n
l
,将各主题k上n个实体的分布比例记为r
k1
、r
k2
、
……
、r
kn
,则根据公式(2)计算各主题k对应dirichlet实体分布的实体分布超参数
[0062][0063]
以样本数量200为界将n个实体划分成nh个大样本实体与n
l
个小样本实体,nh个大样本实体所属样本在标注实体位置与类别以后可在步骤2用于训练yolo模型,充足的样本数量才能够保证yolo模型的精准性;n
l
个小样本实体所属样本则可以在步骤2构建对样本数量要求不高的小样本实体检测模板。
[0064]
步骤2中基于yolo的大样本实体检测模型构建:基于yolo模型(参考文献:redmon,j.,divvala,s.,girshick,r.,farhadi,a.:you only look once:unified,real-time object detection,cvpr2016)构建大样本实体检测模型,其输入是nh个大样本实体类别的训练样本,针对各图像主题k,将实体按其在主题中的出现频率由高到低进行排序,假设所有样本已标注位置和类别,选取已标注位置和类别的nk类高频实体e
kp
(1≤p≤nk)样本对第k个yolo模型进行训练,1≤nk≤nh,如果同一大样本实体类别对应多个yolo模型,则选取其中平均重叠度(iou,intersection over union)最优的yolo模型对其类别置信度与位置进行检测,针对各大样本实体类别选择其最优yolo模型来构建大样本实体检测模型,进而基于大样本实体检测模型检测获得训练样本中nh类大样本实体类别的实体检测位置坐标(x坐标、y坐标)、检测宽度(w)、检测高度(h)、类别置信度;
[0065]
步骤2中小样本实体检测模板构建:针对n
l
个小样本实体类别,基于m=7个hu不变矩(参考文献:基于hu不变矩的图像形状特征提取研究,《网络安全技术与应用》,2017)构建小样本实体检测模板,即行数为n
l
、列数为m的hu不变矩矩阵humatrix,其中矩阵单元humatrix(q,m)表示小样本实体类别q的第m个hu不变矩在该实体类别样本上的平均值,其中1≤q≤n
l
,1≤m≤m;
[0066]
hu不变矩是一种高度概括的图像特征,在连续图像下具有平移、灰度、尺度、旋转不变性,适合于描述实体形状。
[0067]
步骤3包括面向主题语义的图像检索条件设置和图像检索初始化,所述面向主题语义的图像检索条件设置从主题检索范围与实体检索范围等2个维度设置面向主题语义的数据库图像检索,包括:
[0068]
主题语义设置:根据待检索图像的主题设置数据库检索的主题范围,该主题范围表示为一个集合t,
[0069]
实体语义设置:根据待检索图像的实体设置数据库检索的实体范围,该实体范围表示为一个集合e,其中r表示设置的实体数目,1≤r≤n;
[0070]
图像检索初始化:将图像检索集合初始化为空集,即将待检索图像的数目num初始化为数据库中的图像数目,将当期待检索图像索引g初始化为0,即g=0;
[0071]
步骤4包括:
[0072]
步骤4-1,待检索图像数目判断:判断数据库待检索图像的数目num是否为零,如果是跳至步骤5,如果否继续步骤4-2;
[0073]
步骤4-2,图像索引更新:更新当前图像索引为g=g+1,更新数据库待检索图像数目num=num-1;
[0074]
步骤4-3,检测大样本实体;
[0075]
步骤4-4,检测小样本实体;
[0076]
步骤4-5,构建实体检测矩阵;
[0077]
步骤4-6,判断图像主题和实体类别,获得检索结果。
[0078]
步骤4-3包括:基于大样本实体检测模型对大样本实体类别进行检测,检测结果包括nh个大样本实体类别所属实体eh的x、y坐标、检测窗口的宽度、高度、nh个大样本实体类别中最高置信度及对应类别,分别表示为:x(eh)、y(eh)、w(eh)、h(eh)、maxconf(eh)及cls(eh),最高置信度与对应类别cls(eh)满足:
[0079][0080]
cls(eh)=argmaxu(conf(eh,u))
ꢀꢀꢀ
(4)
[0081]
其中,conf(eh,u)表示大样本实体eh在第u个类别上的置信度,1≤u≤nh;
[0082]
步骤4-4包括:大样本实体检测以后,基于图像分割算法grabcut算法将图像剩余部分分割成若干区域,每个区域对应一个候选小样本实体e
l
,其对应的m个hu不变矩特征记为hu(e
l
,m),1≤m≤m,根据公式(5)计算候选小样本实体e
l
隶属于第q个小样本实体类别的置信度conf(e
l
,q),1≤q≤n
l
:
[0083][0084]
进而得到候选小样本实体e
l
隶属于n
l
个小样本实体类别的置信度,小样本实体检测结果包括小样本实体的x、y坐标、检测窗口宽度w、检测窗口高度h、n
l
个小样本实体类别中最高置信度及对应类别,分别表示为:x(e
l
)、y(e
l
)、w(e
l
)、h(e
l
)、maxconf(e
l
)及cls(e
l
),对应类别cls(e
l
)满足:
[0085][0086]
cls(e
l
)=argmaxq(conf(e
l
,q))
ꢀꢀꢀ
(7)
[0087]
其中,conf(e
l
,q)表示小样本实体e
l
在第q个类别上的置信度;
[0088]
步骤4-5包括:基于大样本实体检测结果与小样本实体检测结果,综合生成|es|
×
6的实体检测矩阵darray,es表示大样本实体检测与小样本实体检测中类别置信度大于门限δ=0.80的实体数目,即
[0089]
es={e|(e∈{eh}||e∈{e
l
})&&maxconf(e)≥0.8)}
ꢀꢀꢀ
(8)
[0090]
6列则分别表示对应实体e∈es在图像g中的x坐标、y坐标、宽度w、高度h、实体类别cls与类别置信度conf,如果实体e属于大样本实体,e∈eh,对应步骤9中的大样本实体检测结果,即分别对应x(eh)、y(eh)、w(eh)、h(eh)、cls(eh)及maxconf(eh),如果属于小样本实体则对应步骤10中的小样本实体检测结果,即分别对应x(e
l
)、y(e
l
)、w(e
l
)、h(e
l
)、cls(e
l
)及maxconf(e
l
);
[0091]
步骤4-6包括:
[0092]
步骤4-6-1,图像主题判断:判断图像g的主题是否符合查询要求,根据公式(9)判断图像g所属主题topic:
[0093][0094]
通过计算当前图像中所有实体出现的概率期望值进行主题判断,其中,p(θk)表示图像g隶属于主题k的概率,p(cls(e)|θk)表示实体e隶属于主题k的概率,conf(e)表示实体e的类别置信度;如果图像g的主题topic属于检索主题范围t,即topic∈t,如果是继续步骤4-6-2,否则跳至步骤4-1;
[0095]
步骤4-6-2,实体类别判断:判断实体检测矩阵darray中的实体集合是否包含数据库检索的实体范围e,即如果是继续步骤4-6-3,否则跳至步骤4-1;
[0096]
步骤4-6-3,图像输出:将图像g加入检索集合,即rel=rel∪{g},跳至步骤4-1。
[0097]
本发明方法突破了传统基于内容的图像检索技术通过颜色、纹理与形状等低层视觉特征相似性进行图像检索而忽略高层语义的局限性,创新提出了面向高层语义主题检索的新技术;本发明中的语义检测与实体检测既相互关联也相互独立,有利于根据主题语义检索需求对实体检索技术不断优化改进,具有高度的灵活性;latent dirichlet allocation(lda)模型有利于描述复杂主题语义、实体语义的图像检索,细化图像主题语义的描述粒度。
[0098]
实施例
[0099]
步骤1.1,主题分布超参数计算
[0100]
假设开源图像样本构建自然、人文等2个主题的图像训练样本集合,训练样本在2个主题上的分布比例为r1=1/4、r2=3/4,则两个主题分布超参数计算如下:
[0101]
根据公式(1)计算dirichlet主题分布中的超参数
[0102][0103]
进而可以得出α1=1,α2=3。
[0104]
步骤1.2,实体分布超参数计算
[0105]
假设开源图像样本构建自然、人文等2个主题上分布频率最高的实体类别按频率由高到低分别是“山川”、“河流”、“湖泊”,及“老人”、“儿童”,其中“山川”、“河流”、“老人”、“儿童”为样本数量不少于200的大样本实体,“湖泊”为样本数量小于200的小样本实体,“自然”主题上5个实体分布比例分别为r
11
=1/3,r
12
=1/3,r
13
=1/3,r
14
=0与r
15
=0,“人文”主题上5个实体分布比例分别为r
21
=0、r
22
=0、r
23
=0、r
24
=3/5与r
25
=2/5,则2个主题的实体分布超参数计算如下:
[0106]
根据2个主题上各图像训练样本中实体分布,获取2个主题上频率最高的n=5个实体“山川”、“河流”、“湖泊”、“老人”与“儿童”,其中大样本实体数目nh=4,小样本实体数目n
l
=1,则根据公式(2)计算自然主题(k=1)与人文主题(k=2)对应dirichlet实体分布,得到:
[0107]
根据步骤2中构建大样本实体检测模型:基于nh=4个大样本实体的训练样本,针对2个图像主题分别构建1个yolo模型,对同一大样本实体类别选取其中平均重叠度(iou,intersection over union)最优的yolo模型对其类别置信度与位置进行检测,主题1与主题2对应的yolo模型分别记为y1与y2,而yolo模型y1与y2对应的实体检测类别集合分别为{o
11
,o
12
}与{o
21
,o
22
};
[0108]
根据步骤2中构建小样本实体检测模板:基于n
l
=1个小样本实体的训练样本,针对主题1的小样本实体o
13
构建小样本实体检测模板,即行数为n
l
=1、列数m=7的hu不变矩矩阵humatrix;
[0109]
根据步骤3,生成的主题范围为t={主题1},实体范围为e={o
12
},则对当前图像g的检索结果如下:
[0110]
步骤4-3,大样本实体检测,基于大样本实体检测模型对大样本实体类别进行检测,检测结果包括nh=4个大样本实体类别所属实体eh∈{o
11
,o
12
,o
21
,o
22
}的x、y坐标、检测窗口的宽度w、高度h、大样本实体类别中最高置信度及对应类别,如表1所示:(单位为像素)
[0111]
表1大样本实体检测结果
[0112] xywh最高置信度类别1121335420.9o
11
2212338520.85o
12
3542439500.7o
22
[0113]
步骤4-4,小样本实体检测:大样本实体检测以后,基于grabcut算法将图像剩余部分分割成若干区域,每个区域对应一个候选小样本实体,计算各区域的7个hu不变矩特征,根据公式(5)计算候选小样本实体隶属于实体类别o
13
的置信度,其结果如表2所示:
[0114]
表2小样本实体检测结果
[0115] xy宽度高度最高置信度类别1253243260.85o
13
2363576350.65o
13
[0116]
步骤4-5,实体检测矩阵构建,基于大样本实体检测结果与小样本实体检测结果,综合生成|es|
×
6的实体检测矩阵darray,es表示大样本实体检测与小样本实体检测中类别置信度大于门限δ=0.80的实体数目,es={o
11
,o
12
,o
13
},生成实体检测矩阵darray,如所表3示:
[0117]
表3实体检测矩阵darray
[0118] xywh最高置信度类别1121335420.9o
11
2212338520.85o
12
3253243260.85o
13
[0119]
步骤4-6-1,图像主题判断,根据公式(9)判断当前图像所属主题topic
[0120][0121]
其中,表示图像g隶属于主题k的概率期望值,表示图像g隶属于主题k的概率期望值,表示实体e隶属于主题k的概率期望值,conf(e)表示实体e的类别置信度;判断当前图像主题属于检索主题范围t,即topic∈t,继续步骤4-6-2;
[0122]
步骤4-6-2,实体类别判断:判断实体检测矩阵darray中的实体集合rows(darray)包含数据库检索的实体范围e={o
12
},继续步骤4-6-3;
[0123]
步骤4-6-3,图像输出,将当前图像加入检索集合rel,跳至步骤4-1。
[0124]
在面向科技情报、医疗、卫生等不同专业领域进行图像资源主题检索时,可以采用本发明方法从主题、实体关联分布关系挖掘各专业领域的相关图像主题及资料,从而辅助专业人士高效获取相关的图像主题相关信息,更加精准地进行决策。本发明方法克服了传统基于内容的图像检索技术通过颜色、纹理与形状等低层视觉特征相似性进行图像检索而忽略高层语义的局限性,提升了面向主题检索的准确性和效率,同时能够根据主题语义检索需求对实体检索技术不断优化改进,具有高度的灵活性。
[0125]
本发明的研究工作得到国家自然科学基金(no.61771177)、软件新技术与产业化协同创新中心支持。
[0126]
本发明提供了一种面向主题语义的图像检索方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1