一种基于Epsilon贪心算法监测人工流量作弊的方法及装置与流程
一种基于epsilon贪心算法监测人工流量作弊的方法及装置
技术领域
1.本发明涉及计算机领域,具体涉及一种基于epsilon贪心算法监测人工流量作弊的方法及装置。
背景技术:
2.本部分的描述仅提供与本发明公开相关的背景信息,而不构成现有技术。
3.流量作弊行为是广告渠道商通过自动化脚本程序或有组织人工点击方式请求厂商服务器,从而增加访问量获取不正当利益。自动化脚本程序生成的作弊流量在访问频率、停留时长、二次访问率明显区别于理性人类。因此,传统机器学习模型能准确识别此类作弊攻击。但人工点击方式生成的作弊流量在其行为表现上更具欺诈性和迷惑性,因此传统机器学习模型在该类作弊攻击上表现欠佳。1、空间特征提取:多层感知机(mlp)模型只考虑样本对预测结果的影响,并未考虑样本之间的关系对预测结果的影响。2、时间特征提取:长短期记忆(lstm)模型在解决长序列训练过程中存在梯度消失和梯度爆炸等问题,从而导致时间特征不具有细粒度以及训练周期长。3、特征融合:传统融合方式一般采用固定配置时空特征权重,这会导致信息冗余或信息缺失。4、智能算法:传统粒子群智能算法求平方和函数最小值,由于没有特意指定函数自变量量纲,因此不进行数据归一化处理。基于现有问题,本发明提供了一种基于epsilon贪心算法检测人工流量作弊的方法从而高效且精确的识别人工流量作弊行为。
4.应该注意,上面对技术背景的介绍只是为了方便对本发明的技术方案进行清楚、完整的说明,并方便本领域技术人员的理解而阐述的。不能仅仅因为这些方案在本发明的背景技术部分进行了阐述而认为上述技术方案为本领域技术人员所公知。
技术实现要素:
5.基于上述传统方式所造成的分类预测结果差、训练耗时较长的技术问题,提供了一种基于epsilon贪心算法监测人工流量作弊的方法。
6.为了解决上述技术问题,本发明提供了一种基于epsilon贪心算法监测人工流量作弊的方法,所述的方法包括,
7.(一)对原始数据预处理:将原始数据集,进行pca降维处理,筛选出空间特征数据集和时间特征数据集;
8.(二)从空间特征判断,判断是否为空间特征作弊流量;
9.(三)从时间特征判断,判断是否为时间特征作弊流量;
10.(四)将空间特征作弊流量和时间特征作弊流量融合并最终分类。
11.优选地,所述的步骤(一)具体为,
12.将原始数据集,进行pca降维处理,pca处理后的访问日志,按照空间特征和时间特征进行切割,将其分成2个矩阵,一个矩阵为空间特征矩阵,另一个为时间特征矩阵。
13.优选地,所述的步骤(二)具体为,
14.基于空间特征数据切片分类,当空间特征数据切片中的某一类数据出现的频率大于阈值,将该类数据打上空间特征作弊标签,否则,判断该类数据下的子数据出现的频率是否大于阈值,当该类子数据出现的频率大于阈值时,则将该类数据打上作弊标签,否则打上正常标签,
15.其中作弊流量标签为(0,1),正常流量标签为(0,0),
16.所述的空间特征数据集包括ip地址、mac地址及根签名中的一种或多种。
17.优选地,所述的空间特征数据集包括ip地址,所述的步骤(二)具体为,基于ip子网段分类,当每一ip子网段内的ip总数量大于预设阈值时,则打上作弊标签(0,1),否则,判断该子网段下某一ip总数是否大于预设阈值,若该子网段下的某一ip总数大于预设阈值,则打上作弊标签(0,1),否则打上正常标签(0,0)。
18.优选地,所述的步骤(三)具体为,
19.设定最小持续时间t
min
,
20.确定作弊者作弊动作,描述作弊动作奖励函数,当作弊者会话链接时长小于t
min
时,作弊者收益为0;其中当作弊者会话链接时长介于(t
min
,t
mmin
θ)时,作弊者收益为r1,当作弊者会话时长大于t
min
+θ时,作弊者收益为,r1+2b/(exp(4k(a-(x-t
min
+θ))+1),公式表达如下:
[0021][0022]
其中,当t≥tmin+θ时,s型曲线表达式:y=2b/(exp(4k(a-x))+1),x是时间变量,y是广告费用,k为曲线变化率,(a,b)表示s型曲线关于(a,b)对称,其中a是横坐标,b是纵坐标,所述的s曲线具有两个拐点,第一个拐点用于区别一般粘性和中度粘性、第二个拐点用于区别中毒粘性和高度粘性;
[0023]
使用epsilon算法近似出作弊者的最优策略。epsilon算法如下所示:
[0024]
function
epsilon
=ε
×aexploitation
(ti)+(1-ε)
×aexploration
(tj)
[0025]
其中,ε为选择下一个动作的概率,a
exploitation
(ti)表示为下一个动作,ti表示为下一个动作的时间选择,a
exploration
表示为当前最优动作,tj表示为当前动作的时间选择,
[0026]
当function
epsilon
数值变化率低于设定值时,找到作弊者单次作弊最优链接时长t
best
,
[0027]
设定最小持续时间t
min
,奖励函数是由s型曲线定义,
[0028]
当会话时长t小于t
min
时,则将该部分数据过滤,
[0029]
当会话时长t大于t
min
时,进入下一步操作,
[0030]
判断t是否介于(t
best-τ,t
best
+τ),判断为是,则打上作弊标签(1,0),否则打上正常标签(0,0),
[0031]
其中,t
best
为最优动作的时间参数,τ为符合高斯分布的噪声。
[0032]
优选地,所述的步骤(四)具体为,
[0033]
计算数据样本的最终决策:
[0034]
decision
fin
=λ
×
label
space
(0,value)+(1-λ)label
time
(value,0),
[0035]
当decision
fin
≥threshold
pre
,我们将该条数据识别为作弊流量,当decision
fin
<
threshold
pre
,将该条数据识别为正常流量,
[0036]
其中,λ为空间特征的权重,threshold
pre
为预先设定的阈值,其中,λ为空间特征的权重,threshold
pre
为预先设定的阈值,label
space
(0,value)是空间特征标签,label
time
(value,0)是时间特征标签,value的取值为0或1。
[0037]
本技术还提供一种基于epsilon贪心算法监测人工流量作弊的装置,所述的装置包括,
[0038]
原始数据预处理模块,用于将原始数据集,进行pca降维处理,筛选出空间特征数据集和时间特征数据集;
[0039]
空间特征判断模块,用于判断是否为空间特征作弊流量;
[0040]
时间特征判断模块,用于判断是否为时间特征作弊流量;
[0041]
时空融合最终判断模块,用于将空间特征作弊流量和时间特征作弊流量融合并最终分类。
[0042]
优选地,所述的原始数据预处理模块,具体用于将原始数据集,进行pca降维处理,pca处理后的访问日志,按照空间特征和时间特征进行切割,将其分成2个矩阵,一个矩阵为空间特征矩阵,另一个为时间特征矩阵;
[0043]
所述的空间特征判断模块,具体用于基于空间特征数据切片分类,当空间特征数据切片中的某一类数据出现的频率大于阈值,将该类数据打上空间特征作弊标签,否则,判断该类数据下的子数据出现的频率是否大于阈值,当该类子数据出现的频率大于阈值时,则将该类数据打上作弊标签,否则打上正常标签,其中作弊流量标签为(0,1),正常流量标签为(0,0);
[0044]
所述的时间特征判断模块,具体用于设定最小持续时间t
min
,
[0045]
确定作弊者作弊动作,描述作弊动作奖励函数,当作弊者会话链接时长小于t
min
时,作弊者收益为0;其中当作弊者会话链接时长介于(t
min
,t
min
+θ)时,作弊者收益为r1,当作弊者会话时长大于t
min
+θ时,作弊者收益为,r1+2b/(exp(4k(a-(x-t
min
+θ))+1),公式表达如下:
[0046][0047]
其中,当t≥tmin+θ时,s型曲线表达式:y=2b/(exp(4k(a-x))+1),x是时间变量,y是广告费用,k为曲线变化率,(a,b)表示s型曲线关于(a,b)对称,其中a是横坐标,b是纵坐标,所述的s曲线具有两个拐点,第一个拐点用于区别一般粘性和中度粘性、第二个拐点用于区别中毒粘性和高度粘性;
[0048]
使用epsilon算法近似出作弊者的最优策略。epsilon算法如下所示:
[0049]
function
epsilon
=ε
×aexploitation
(ti)+(1-ε)
×aexploration
(tj)
[0050]
其中,ε为选择下一个动作的概率,a
exploitation
(ti)表示为下一个动作,ti表示为下一个动作的时间选择,a
exploration
表示为当前最优动作,tj表示为当前动作的时间选择,
[0051]
当function
epsilon
数值变化率低于设定值时,找到作弊者单次作弊最优链接时长t
best
,
[0052]
设定最小持续时间t
min
,奖励函数是由s型曲线定义,
[0053]
当会话时长t小于t
min
时,则将该部分数据过滤,
[0054]
当会话时长t大于t
min
时,进入下一步操作,
[0055]
判断t是否介于(t
best-τ,t
best
+τ),判断为是,则打上作弊标签(1,0),否则打上正常标签(0,0),
[0056]
其中,t
best
为最优动作的时间参数,τ为符合高斯分布的噪声;
[0057]
所述的时空融合最终判断模块,具体用于计算数据样本的最终决策:
[0058]
decision
fin
=λ
×
label
space
(0,value)+(1-λ)label
time
(value,0),
[0059]
当decision
fin
≥threshold
pre
,我们将该条数据识别为作弊流量,当decision
fin
<threshold
pre
,将该条数据识别为正常流量,其中,λ为空间特征的权重,threshold
pre
为预先设定的阈值,其中,λ为空间特征的权重,threshold
pre
为预先设定的阈值,label
space
(0,value)是空间特征标签,label
time
(value,0)是时间特征标签,value的取值为0或1。
[0060]
本技术还提供一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现所述的方法。
[0061]
本技术还提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现所述的方法。
[0062]
借由以上的技术方案,本发明的有益效果如下:
[0063]
本发明的基于epsilon贪心算法监测人工流量作弊的方法及装置,可有效识别人工点击方式生成的作弊流量,从而让厂商规避广告成本增加的风险。并且间接提高了厂商服务器的可用性和可靠性。
附图说明
[0064]
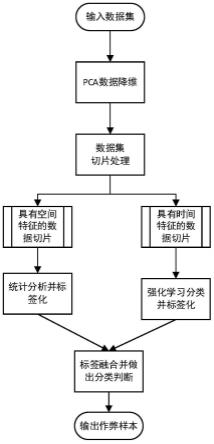
图1是本技术的监测人工流量作弊的方法的整体流程图;
[0065]
图2是本技术的从空间角度判断作弊流量的流程图;
[0066]
图3是本技术的从时间角度判断作弊流量的流程图;
[0067]
图4是本技术的厂商设定的最小会话持续时间及最大广告收益时间节点的示意图;
[0068]
图5是本技术的广告收益与持续时间的s型曲线图。
具体实施方式
[0069]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0070]
用户通过第三方广告平台(即点击广告平台上的广告链接)访问厂商服务器,每一次点击会开启一次会话。会话将会被记录在厂商服务器的日志中。
[0071]
那么如果对厂商服务器的日志进行分析,怎么才能从日志中区别分正常用户和作弊用户呢?做法如下所示:采用空间特征和时间特征对日志分别分析,并做出初步判断,即从空间的角度对数据集进行二分类(正常用户/作弊用户),即从时间的角度对数据集进行二分类(正常用户/作弊用户)具体步骤如下。
[0072]
如图1所示,为本技术的监测人工流量作弊的方法的整体流程图,输入数据切片,对原始数据预处理:将原始数据集,进行pca降维处理,筛选出空间特征数据集和时间特征数据集;从空间特征判断,判断是否为空间特征作弊流量;从时间特征判断,判断是否为时间特征作弊流量;将空间特征作弊流量和时间特征作弊流量融合并最终分类。其中对原始数据预处理具体为,将该数据切片进行pca降维处理,pca处理后的访问日志,按照空间特征和时间特征进行切割,将其分成2个矩阵,一个矩阵为空间特征矩阵,另一个为时间特征矩阵。
[0073]
从空间角度判断作弊流量的具体步骤包括,基于空间特征数据切片分类,当空间特征数据切片中的某一类数据出现的频率大于阈值,将该类数据打上空间特征作弊标签,否则,判断该类数据下的子数据出现的频率是否大于阈值,当该类子数据出现的频率大于阈值时,则将该类数据打上作弊标签,否则打上正常标签,其中作弊流量标签为(0,1),正常流量标签为(0,0)。所述的空间特征数据集包括ip地址、mac地址及根签名中的一种或多种。
[0074]
如图2所示,当空间特征数据为ip地址时,判断作弊流量的流程图,具体步骤为,基于ip子网段分类,当每一ip子网段内的ip总数量大于预设阈值时,则打上作弊标签(0,1),否则,判断该子网段下某一ip总数是否大于预设阈值,若该子网段下的某一ip总数大于预设阈值,则打上作弊标签(0,1),否则打上正常标签(0,0)。以下举例说明。
[0075]
考虑作弊者使用单一主机作为攻击主机,即该作弊者的作弊流量来自于同一个ip,那么在一个数据集中,该ip将多次出现在该数据集,当该ip出现的频率超过防作弊策略设置的阈值时,我们将含有该ip的所有日志项标记为作弊流量。例子:当数据集数量为100时,当日志项中ip为192.168.1.113的项数大于20时,即该类日志项的占比为20/100=1/5时,我们将该类流量标记为作弊流量,即为其打上作弊流量的标签,作弊流量标签为(0,1)。
[0076]
考虑作弊者为团体作案(即使用多台物理机),或者是单个作弊者使用多个虚拟机发动作弊流量攻击时。无论是是团体作案,还是多台虚拟机作案时,同一个网段的不同ip将会多次出现在数据集中,即日志中。例子,假设数据集数量为100时,当日志项中网段为192.168.199.xxx出现次数大于40时,即该类日志项的占比为40/100=2/5时,我们将该类流量标记为作弊流量,即为其打上作弊流量的标签,作弊流量标签为(0,1)。
[0077]
作弊者不知道广告主制定的收费准则,所以要通过多次链接尝试寻求给定时间间隔内的最优链接时长。由于广告主不知道作弊者具体的作弊策略,因此我们需要采用强化学习epsilon算法近似模拟出作弊者的作弊策略。
[0078]
算法第一步,设定最小持续时间t
min
,确定作弊者作弊动作。由于作弊者的作弊动作是一致的,都是与广告服务器进行会话通信,并不本质上的区别,只有时间长短上的差异。因此我们固定作弊动作唯一。
[0079]
算法第二部,描述作弊动作奖励函数,其中当作弊者会话链接时长小于t
min
时,作弊者收益为0;其中当作弊者会话链接时长介于(t
min
,t
min
+θ)时,作弊者收益为r1,当作弊者会话时长大于t
min
+θ时,作弊者收益为r1+2b/(exp(4k(a-(x-t
min
+θ))+1)。公式表达如下:
[0080][0081]
这里t≥tmin+θ时的奖励函数是由s型曲线定义出来的,其意思为收益先是缓慢的
增加,当时间达到某一阈值后高速增加,并达到某一时间结点后收敛于某一个定值。s型曲线的两个拐点可由用户粘性表示,第一个拐点用来区别一般粘性和中度粘性、第二个拐点用来区别中毒粘性和高度粘性。
[0082]
如图5所示,s型曲线表达式:y=2b/(exp(4k(a-x))+1),x是时间变量,y是广告费用,k为曲线变化率,(a,b)表示s型曲线关于(a,b)对称,其中a是横坐标,b是纵坐标。
[0083]
算法第三步,当定义完作弊者的动作空间和作弊者奖励函数后,使用epsilon算法近似出作弊者的最优策略。epsilon算法如下所示:
[0084]
function
epsilon
=ε
×aexploitation
(ti)+(1-ε)
×aexploration
(tj)
[0085]
其中ε为选择下一动作(选择下一个链接会话时长)的概率,ε最开始选的值较大,通过模型训练后会逐渐减小,逼近于0。其中a
exploitation
(ti)表示为下一个动作,ti表示为下一个动作的时间选择。a
exploration
表示为当前最优动作,tj表示为当前动作的时间选择。
[0086]
当function
epsilon
收敛到固定区间时,即数值变化率低于设定值时,我们认为找到了作弊者的最优作弊策略,即可通过该函数找到作弊者的最优动作(通过每一次迭代的参数展示,即显示出当前会话的链接时长),即可找到作弊者单次作弊最优链接时长t
best
。
[0087]
当会话时长t小于t
min
时,则打上作弊标签(1,0),当会话时长t大于tmin时,则进入下一步,判断t是否介于(t
best-τ,t
best
+τ),判断为是,则打上作弊标签(1,0),否则打上正常标签(0,0),其中,t
best
为最优动作的时间参数,τ为厂商设定并符合高斯分布的噪声。
[0088]
时空融合最终判断步骤具体为,计算数据样本的最终决策:
[0089]
decision
fin
=λ
×
label
space
(0,value)+(1-λ)label
time
(value,0),
[0090]
当decision
fin
≥threshold
pre
,我们将该条数据识别为作弊流量,当decision
fin
<threshold
pre
,将该条数据识别为正常流量,其中,λ为空间特征的权重,threshold
pre
为预先设定的阈值,label
space
(0,value)为(0,1),label
time
(value,0)为(1,0)。
[0091]
本技术还提供一种基于epsilon贪心算法监测人工流量作弊的装置,所述的装置包括,原始数据预处理模块,用于将原始数据集,进行pca降维处理,筛选出空间特征数据集和时间特征数据集;空间特征判断模块,用于判断是否为空间特征作弊流量;时间特征判断模块,用于判断是否为时间特征作弊流量;时空融合最终判断模块,用于将空间特征作弊流量和时间特征作弊流量融合并最终分类。
[0092]
所述的原始数据预处理模块,具体用于将原始数据集,进行pca降维处理,pca处理后的访问日志,按照空间特征和时间特征进行切割,将其分成2个矩阵,一个矩阵为空间特征矩阵,另一个为时间特征矩阵;
[0093]
所述的空间特征判断模块,具体用于基于空间特征数据切片分类,当空间特征数据切片中的某一类数据出现的频率大于阈值,将该类数据打上空间特征作弊标签,否则,判断该类数据下的子数据出现的频率是否大于阈值,当该类子数据出现的频率大于阈值时,则将该类数据打上作弊标签,否则打上正常标签,其中作弊流量标签为(0,1),正常流量标签为(0,0);
[0094]
所述的时间特征判断模块,具体设定最小持续时间t
min
,
[0095]
确定作弊者作弊动作,描述作弊动作奖励函数,当作弊者会话链接时长小于t
min
时,作弊者收益为0;其中当作弊者会话链接时长介于(t
min
,t
min
+θ)时,作弊者收益为r1,当作弊者会话时长大于t
min
+θ时,作弊者收益为,r1+2b/(exp(4k(a-(x-t
min
+θ))+1),公式表达
如下:
[0096][0097]
其中,当t≥tmin+θ时,s型曲线表达式:y=2b/(exp(4k(a-x))+1),x是时间变量,y是广告费用,k为曲线变化率,(a,b)表示s型曲线关于(a,b)对称,其中a是横坐标,b是纵坐标,所述的s曲线具有两个拐点,第一个拐点用于区别一般粘性和中度粘性、第二个拐点用于区别中毒粘性和高度粘性;
[0098]
使用epsilon算法近似出作弊者的最优策略。epsilon算法如下所示:
[0099]
function
epsilon
=ε
×aexploitation
(ti)+(1-ε)
×aexploration
(tj)
[0100]
其中,ε为选择下一个动作的概率,a
exploitation
(ti)表示为下一个动作,ti表示为下一个动作的时间选择,a
exploration
表示为当前最优动作,tj表示为当前动作的时间选择,
[0101]
当function
epsilon
数值变化率低于设定值时,找到作弊者单次作弊最优链接时长t
best
,
[0102]
设定最小持续时间t
min
,奖励函数是由s型曲线定义,
[0103]
当会话时长t小于t
min
时,则将该部分数据过滤,
[0104]
当会话时长t大于t
min
时,进入下一步操作,
[0105]
判断t是否介于(t
best-τ,t
best
+τ),判断为是,则打上作弊标签(1,0),否则打上正常标签(0,0),
[0106]
其中,t
best
为最优动作的时间参数,τ为符合高斯分布的噪声。
[0107]
所述的时空融合最终判断模块,具体用于计算数据样本的最终决策:
[0108]
decision
fin
=λ
×
label
space
(0,value)+(1-λ)label
time
(value,0),
[0109]
当decision
fin
≥threshold
pre
,我们将该条数据识别为作弊流量,当decision
fin
<threshold
pre
,将该条数据识别为正常流量,其中,λ为空间特征的权重,threshold
pre
为预先设定的阈值,label
space
(0,value)为(0,1),label
time
(value,0)为(1,0)。
[0110]
本技术还提供一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现以上基于epsilon贪心算法监测人工流量作弊方法。
[0111]
本技术还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以上基于epsilon贪心算法监测人工流量作弊方法。
[0112]
本发明的基于epsilon贪心算法监测人工流量作弊的方法及装置,可有效识别人工点击方式生成的作弊流量,从而让厂商规避广告成本增加的风险。并且间接提高了厂商服务器的可用性和可靠性。
[0113]
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1