一种基于伪标签的视线估计方法
1.本发明涉及视线估计技术领域,特别是涉及一种基于伪标签的视线估计方法。
背景技术:
2.视线估计方法可以分为基于模型的方法和基于表观的方法,基于模型的方法从人眼或人脸图像中计算关键点,结合三维人眼模型预测视线;基于表观的方法直接从人眼或人脸图像中提取特征以预测视线。基于模型的方法准确率高,但依赖于红外相机等专业设备,通常局限于室内场景;基于表观的方法不依赖于专业设备,在室内室外场景都适用,但准确率相对较低。
3.得益于深度学习的发展,基于表观的深度学习方法在精度上有了巨大的提升,已经超越了传统机器学习的方法,但是深度学习依赖于大规模的数据集,现有的视线估计数据集场景单一,图像数量相对较少,制约了算法性能的进一步提升,如何在现有数据集上生成更多的有标签数据成了研究重点。
4.直观的想法就是给无标签的数据打上伪标签,这样就能以较低的代价得到大量有标签数据。ghosh等人先检测出眼部关键点,然后使用关键点结合人眼三维模型估计视线伪标签;这种方法严重依赖于眼部关键点检测算法,而且不同人的眼部生理结构存在差异,用同一个人眼模型无法兼顾个体的差异。kothari等人利用人在交谈时相互看着对方的特性,设计了眼部视线的伪标签,但是这些方法依赖于特定场景,无法保证交谈者时刻盯着对方。
5.cheng等人首次将vision transformer(vit)引入到视线估计领域,他们首先用残差网络提取面部图像的特征图,然后将特征图作为transformer的输入,其他结构和vit保持不变,最后输出视线;这种方法虽然在常见的视线估计数据集上都取得了目前最好的结果,但是vit模型的参数量很大,在给定小数据集上直接训练的效果很差,需要先用大量的有标签数据做预训练,这严重增加了模型的计算代价,也限制了算法的可拓展性。
6.transformer中主要起作用的是多头注意力机制,cai等人摒弃了vit中其他复杂结构,仅保留了多头注意力部分,他们先用残差网络提取出左右眼部图像和面部图像的特征,而后将这三个特征看成是长度为三的序列,输入到多头注意力网络中,最后将特征拼接起来,利用全连接层和relu激活函数输出视线;这种方法相比于cheng等人的方法在模型结构上相对简单,也不需要大数据集做预训练,但模型需要额外的左右眼图像输入,这增加了额外的数据预处理工作,且若眼部被遮挡,无法采集到眼部图像时,模型的性能可能会受到较大的影响。
技术实现要素:
7.本发明提供一种基于伪标签的视线估计方法,解决数据集场景单一、图像数量相对较少的问题。
8.本发明解决其技术问题所采用的技术方案是:提供一种基于伪标签的视线估计方法,包括以下步骤:
9.获取面部图像;
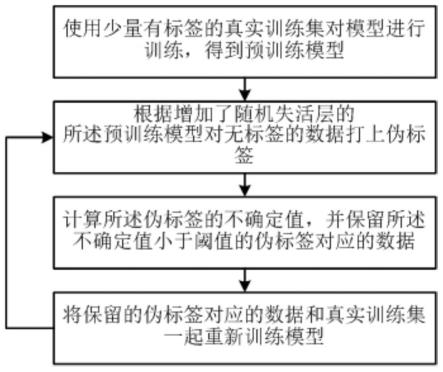
10.将所述面部图像输入至训练好的视线评估模型中进行预测得到预测视线;其中,所述视线评估模型在训练时,使用少量有标签的真实训练集对模型进行训练,得到预训练模型,根据增加了随机失活层的所述预训练模型对无标签的数据打上伪标签,计算所述伪标签的不确定值,并保留所述不确定值小于阈值的伪标签对应的数据,将保留的伪标签对应的数据和真实训练集一起重新训练模型,如此循环迭代直至训练完毕,得到所述视线评估模型。
11.所述根据增加了随机失活层的所述预训练模型对无标签的数据打上伪标签具体为:将同一个无标签的数据多次输入打开随机失活层的所述预训练模型中得到的多个伪标签。
12.所述计算所述伪标签的不确定值具体为:计算多个伪标签的均值,将所述均值作为所述无标签的数据的视线伪标签;计算多个所述伪标签的标准差,将所述标准差作为所述伪标签的不确定值。
13.所述模型的损失函数为:其中,是模型对真实训练集图像的预测结果,y
train
是真实训练集的真实标签,是模型对伪标签数据的预测结果,y
pseudo
是保留的伪标签,α是伪标签数据的权重信息。
14.所述视线评估模型包括:主干网络,用于从所述面部图像中提取出特征表示;全连接层,用于从所述特征表示中回归出预测视线;在对无标签的数据打上伪标签时,所述随机失活层设置在所述主干网络和全连接层之间。
15.有益效果
16.由于采用了上述的技术方案,本发明与现有技术相比,具有以下的优点和积极效果:本发明用少量有标签数据训练模型得到预训练模型,然后用预训练模型给大量无标签数据打上伪标签,接着计算伪标签的不确定,再设置一个阈值,去除不确定性大于阈值的伪标签数据,仅保留伪标签较小的数据,添加到真实训练集中,用真实训练集和挑选出的伪标签数据重新训练模型,如此循环迭代直至训练完毕。本发明可以在不依赖人工标签的情况下,在多个视线评估数据集上取得优异性能,大大减轻了视线估计对人工标签的依赖性。
附图说明
17.图1是本发明实施方式中模型训练的流程图;
18.图2是本发明实施方式中的模型结构示意图。
具体实施方式
19.下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本技术所附权利要求书所限定的范围。
20.本发明的实施方式涉及一种基于伪标签的视线估计方法,包括以下步骤:获取面部图像;将所述面部图像输入至训练好的视线评估模型中进行预测得到预测视线。
21.如图1所示,所述视线评估模型在训练时,使用少量有标签的真实训练集对模型进行训练,得到预训练模型;根据增加了随机失活层的所述预训练模型对无标签的数据打上伪标签;计算所述伪标签的不确定值,并保留所述不确定值小于阈值的伪标签对应的数据;将保留的伪标签对应的数据和真实训练集一起重新训练模型,如此循环迭代直至训练完毕,得到所述视线评估模型。
22.本实施方式中采用预测值的标准差来作为伪标签的不确定性。在根据所述预训练模型对无标签的数据打上伪标签时,本实施方式打开随机失活层,使得对于同一个样本,多次输入到预训练模型中得到的预测值是不一样的,例如,将同一张面部图像分m次输入到预训练模型中,因为随机失活层的存在,预训练模型每次测试的时候会随机将一部分参数置零,使得每次模型的参数都不一样,每次的预测结果也就不一样,这样就得到m个不同的伪标签,不妨设每次预测的伪标签为m次预测结果的平均值为该值可以作为所述无标签的数据的视线伪标签,则标准差为:
[0023][0024]
不妨设有标签数据(data label)为d
l
,无标签数据(data unlabel)为d
ul
,无标签图像共有q张,总共循环迭代n次,标准差阈值为μ,则每次的训练集为
[0025][0026][0027]
如果输入图像清晰度高,遮挡少,且模型学到了图像较好的表征,那么即使因随机丢弃部分参数导致每次的模型略有不同,得到的预测视线值也应该非常接近甚至一样;反之,若每次的预测值很接近,就说明模型对于当前预测结果的鲁棒性好,当前预测结果是可信的。
[0028]
显然,可以通过计算多次预测结果的标准差来判断预测值的接近程度,如果多次预测结果的标准差较小,说明多次预测的结果很接近,当前预测结果可信,是一个可靠的视线伪标签;若多次预测结果的标准差较大,说明多次预测结果相差较大,当前结果的相对不可信,应该丢弃当前伪标签。只要设置好合适的阈值,就能挑选出置信度高的伪标签对应的数据,作为真实训练集的补充。将置信度高的伪标签对应的数据添加到真实训练集中,得到新的训练集,用新的训练集重新训练模型,考虑到伪标签数据多少存在一点误差,对于这部分的损失函数可以设置一个系数,降低错误标签的影响,如下式:
[0029][0030]
是模型对真实训练集图像的预测结果,y
train
是真实训练集的真实标签,是模型对伪标签数据的预测结果,y
pseudo
是保留的伪标签,α是伪标签数据的权重信息,可以设置为小于1.0的数,如0.5,表示增加真实标签损失函数的比重,减少伪标签预测错误的影响。
[0031]
考虑到训练集的数量相比于上一轮有了明显的提升,此次训练的模型效果肯定会
更好,对于图像质量较差的面部图像也能预测出相对稳定的结果,能挑选出更多的伪标签数据,并用挑选出的伪标签和真实标签重新训练模型,不断迭代,直到无法挑选出更多的伪标签数据或达到预先设定的循环次数时,停止迭代优化。最后输出训练好的模型,作为视线评估模型。
[0032]
不难发现,本发明用少量有标签数据训练模型得到预训练模型,然后用预训练模型给大量无标签数据打上伪标签,接着计算伪标签的不确定,再设置一个阈值,去除不确定性大于阈值的伪标签数据,仅保留伪标签较小的数据,添加到真实训练集中,用真实训练集和挑选出的伪标签数据重新训练模型,如此循环迭代直至训练完毕。本发明可以在不依赖人工标签的情况下,在多个视线评估数据集上取得优异性能,大大减轻了视线估计对人工标签的依赖性。
[0033]
本实施方式中采用的视线评估模型的网络结构如图2所示,包括:主干网络,用于从所述面部图像中提取出特征表示;全连接层,用于从所述特征表示中回归出预测视线;在对无标签的数据打上伪标签时,所述随机失活层设置在所述主干网络和全连接层之间。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1