一种基于深度学习的结直肠息肉图像分割方法
1.本发明涉及计算机视觉以及深度学习领域,具体而言是一种基于深度学习的结直肠息肉图像分割方法。
技术背景
2.结直肠癌是全世界最常见的一种癌症。多项研究表明,早期结肠镜检查可以使结直肠癌的发病率下降30%。因此,通过结直肠镜来筛查和切除癌前病变来预防直肠癌至关重要。医生可以通过结肠镜检查所提供的结直肠息肉的位置和外观信息来对其在发展为结直肠癌之前切除,这是一种有效的结直肠癌筛查和预防技术。因此,在临床上,对息肉的精确定位和分割技术的研究是有实际应用价值的,这可以辅助内窥镜医生检测息肉,从而提高准确率。然而,对于这项技术充满了挑战性,主要有两方面的原因:一方面,息肉的外观通常不同,即使它们是同一类型,也会存在大小,颜色和质地等差别,这大大增加了息肉分割的难度;另一方面,在结肠镜图像中,息肉与其周围黏膜之间的边界通常是模糊的,并且缺乏分割方法所需的强烈对比度,这导致息肉变成了一个较难定位分割的伪装对象。
3.因此,一种能够在早期发现所有潜在息肉的自动而准确的息肉图像分割方法对预防结直肠癌具有重要意义。
技术实现要素:
4.本发明提出一种基于深度学习的结直肠息肉图像分割方法。该方法可以准确快速的对息肉进行分割,解决息肉具有不同的大小、颜色和质地以及和周围组织黏膜高度相似所造成的分割精度不高的问题。
5.本发明的技术方案是这样实现的:
6.一种基于深度学习的结直肠息肉图像分割方法,包括以下步骤:
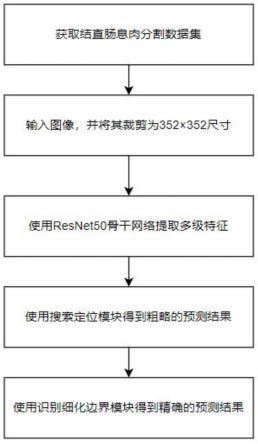
7.步骤(1)、获取结直肠息肉分割数据集。
8.结直肠息肉分割数据集采用现有的cvc-clinicdb数据集。该数据集被随机分成训练集和测试集,其中80%作为训练集用于对所提出的模型进行训练,20%作为测试集用于对所提出的模型的鲁棒性进行评判。
9.步骤(2)、数据预处理;
10.将结直肠息肉分割图像通过双线性插值算法裁剪为352
×
352尺寸;
11.步骤(3)、构建基于深度学习的结直肠息肉图像分割模型。
12.所述的基于深度学习的结直肠息肉图像分割模型包括一个resnet50特征提取模块,三个cbr模块,搜索定位模块以及三个识别细化边界模块rrm。首先,输入图像通过resnet50特征提取模块获得5个由浅层到深层的特征x1、x2、x3、x4和x5;接着将x1、x2和x3通过cbr模块进行特征增强;然后,使用搜索定位模块融合三个深层的特征x1、x2、x3,从而得到粗略的预测结果p1;最后,使用识别细化边界模块通过级联的方式得到精确的预测结果p2,p3,p4。
13.步骤(4)、通过训练集对构建好的基于深度学习的结直肠息肉图像分割模型训练,对每一级预测结果使用结构损失函数进行监督学习,并且将最后一级的预测结果作为最终的预测结果。
14.步骤(5)、对模型训练结果加以验证,将测试集的数据输入到训练好的模型中,然后获取预测结果,与真实结果对比验证是否有效。预测结果和真实结果都是只有0和1的二值化图像,通过相减的方式获取一张图不同的像素点,然后除以整张图总像素数就是mae指标,该指标越小越好。
15.所述搜索定位模块由三个non-local模块和一个特征聚合解码器组成,用于融合三个输入的信息,保留有用的细节,去除其中的噪声,从而得到一个粗略的预测结果。
16.将resnet50特征提取模块获得x1,x2和x3特征分别通过一个non-local模块,从而得到z1,z2和z3特征;将z1,z2和z3特征输入到特征聚合解码器中,得到粗略的全局预测结果p1。
17.所述的non-local模块,用于对特征进行增强,捕获长距离依赖,使特征有丰富的上下文信息,增加息肉搜索的准确性。具体地说,输入一个特征x通过三个1
×
1卷积并进行reshape得到三个不同的特征y1、y2和y3。y1和y2进行矩阵乘法运算得到的结果通过sigmoid函数然后与y3进行矩阵乘法运算,从而得到长距离依赖特征,该特征经过一个1
×
1卷积后与特征x相加得到最终增强的特征z。
18.所述特征聚合解码器即fad模块,将多层特征进行聚合来生成一个粗略的息肉分割预测图。fad模块使用金字塔结构,以渐近的方式分层聚合相邻特征,将重点关注在相邻特征节点,使得聚合细节和语义信息并丢弃干扰信息。运算步骤依次为:输入z1、z2和z3特征,将z1和z2特征通过上采样到与z3特征同大小尺寸;将z1和z2进行点乘操作,随后通过一个卷积层得到z12;将z2和z3进行点乘操作,随后通过一个卷积层得到z23;然后将z12和z23特征进行点乘操作,随后通过一个卷积层;最后通过一个1
×
1卷积层得到粗略的全局预测结果p1。
19.所述的识别细化边界模块,有两个输入,一个输入是预测结果prediction,也就是p1、p2和p3,另一个是特征features,也就是z1、z2和z3。首先对prediction进行上采样操作使得其大小与features大小一致,然后用1减去上采样后的prediction。然后将1-prediction与features经过cbr模块的结果相乘从而得到反向注意图,这个反向注意图在与features进行拼接融合操作,在经过cbr模块进一步优化息肉边界,后将这个结果与features相乘并经过卷积得到最终预测结果。
20.所述结构损失函数来源于显著性目标检测,它由二值交叉熵损失和交并比损失组成,所述结构损失函数如下:
21.l=l
wbce
+l
wiou
22.所述二值交叉熵损失l
wbce
表达式如下:
[0023][0024]
h为输出高度,w为输出宽度,g
ij
表示ground truth对应像素点(i,j)的值,p
ij
表示预测结果对应像素点(i,j)的值,γ是个超参数;α
ij
表示像素点(i,j)的权重。
[0025]
所述α
ij
的表达式如下:
[0026][0027]aij
代表像素点(i,j)上下左右15个像素范围的区域;如果α
ij
越大,则说明该点像素(i,j)与周围像素不同,因此这是一个重要的像素,需要得到更多的关注。
[0028]
所述交并比损失l
wiou
表达式如下:
[0029][0030]
本发明有益效果:
[0031]
本发明设计合理,基于深度学习来构建结直肠息肉图像分割模型,对结直肠息肉分割图像的特征进行精确提取并且细节保留完整,利用显著性目标检测中效果较好的结构损失函数对结果进行监督学习,使得预测结果更加准确,具有较强的鲁棒性,从而实现对结直肠息肉图像的精确分割,对社会具有重要意义。
附图说明
[0032]
图1是本发明实施例的整体实现流程图;
[0033]
图2是本发明基于深度学习的结直肠息肉图像分割模型结构示意图;
[0034]
图3是本发明实施例non-local模块结构示意图;
[0035]
图4是本发明实施例特征聚合解码器结构示意图;
[0036]
图5是本发明实施例识别细化边界模块模块结构示意图。
具体实施方式
[0037]
下面根据附图详细说明本发明,本发明的目的和效果将变得更加明显。
[0038]
如图1所示,本发明整体实现流程如下:
[0039]
步骤(1)、获取结直肠息肉分割数据集。使用网上所存在的cvc-clinicdb结直肠息肉分割数据集作为本任务的数据集。该数据集被分为训练集和测试集,训练集用于对所提出的模型进行训练,测试集用于对所提出的模型的鲁棒性进行评判;
[0040]
步骤(2)、输入结直肠息肉分割图像。将结直肠息肉分割图像输入到模型中,并将该图像通过双线性插值算法裁剪为352
×
352尺寸;
[0041]
步骤(3)、使用resnet50骨干网络提取多级特征。输入图像通过resnet50骨干网络会产生5个由浅层到深层的特征;
[0042]
步骤(4)、使用搜索定位模块融合三个深层的特征,从而得到粗略的预测结果。然后,对该预测结果使用结构损失函数进行监督学习;
[0043]
步骤(5)、使用识别细化边界模块通过级联的方式得到精确的预测结果。然后,对每一级预测结果使用结构损失函数进行监督学习,并且将最后一级的预测结果作为最终的预测结果。
[0044]
如图2所示,所述基于深度学习的结直肠息肉图像分割模型,它的运算步骤依次为:输入352
×
352的结直肠息肉分割图像,经过resnet50骨干网络提取特征{x1,x2,x3,x4,
x5};然后将x1,x2和x3特征分别通过一个non-local模块,从而得到z1,z2和z3特征;将z1,z2和z3特征输入到如图4所示的特征聚合解码器(fad)中,从而输出得到预测结果p1;将预测结果p1与z1输入到识别细化边界模块(rrm)中,输出得到预测结果p2;将预测结果p2与z2输入到识别细化边界模块(rrm)中,输出得到预测结果p3;将预测结果p3与z3输入到识别细化边界模块(rrm)中,输出得到预测结果p4。其中,p1,p2,p3和p4通过结构损失进行监督学习,并且p4将作为最终的预测结果。
[0045]
如图3所示,是本发明所述的non-local模块,该模块可以对特征进行增强,捕获长距离依赖,使特征有丰富的上下文信息,增加息肉搜索的准确性。具体地说,输入一个特征x通过三个1
×
1卷积并进行reshape得到三个不同的特征y1、y2和y3。y1和y2进行矩阵乘法运算得到的结果通过sigmoid函数然后与y3进行矩阵乘法运算,从而得到长距离依赖特征,该特征经过一个1
×
1卷积后与特征x相加得到最终增强的特征z。
[0046]
如图4所示,是本发明所述特征聚合解码器,将多层特征进行聚合来生成一个粗略的息肉分割预测图。fad模块使用金字塔结构,以渐近的方式分层聚合相邻特征,将重点关注在相邻特征节点,使得聚合细节和语义信息并丢弃干扰信息。它的运算步骤依次为:输入z1、z2和z3特征,将z1和z2特征通过上采样到与z3特征同大小尺寸;将z1和z2进行点乘操作,随后通过一个卷积层cnn得到z12;将z2和z3进行点乘操作,随后通过一个卷积层cnn得到z23;然后将z12和z23特征进行点乘操作,随后通过一个卷积层cnn最后通过一个1
×
1卷积层得到预测结果。
[0047]
所述卷积层cnn是指3
×
3的卷积层、bn层和relu激活函数串联组成。
[0048]
如图5所示,是本发明所述的识别细化边界模块,它有两个输入,一个输入是前一个的预测结果prediction,也就是p1、p2和p3,另一个是特征features,也就是z1、z2和z3。首先对prediction进行上采样操作使得其大小与features大小一致,然后用1减去上采样后的prediction。然后将1-prediction与features经过cbr模块的结果相乘从而得到反向注意图,这个反向注意图在与features进行拼接融合操作,在经过cbr模块进一步优化息肉边界,后将这个结果与features相乘并经过卷积得到最终预测结果。
[0049]
所述结构损失函数来源于显著性目标检测,它由二值交叉熵损失和交并比损失组成,所述结构损失函数如下:
[0050]
l=l
wbce
+l
wiou
[0051]
所述二值交叉熵损失l
wbce
表达式如下:
[0052][0053]
h为输出高度,w为输出宽度,g
ij
表示groundtruth对应像素点(i,j)的值,p
ij
表示预测结果对应像素点(i,j)的值,γ是个超参数;α
ij
表示像素点(i,j)的权重。
[0054]
所述α
ij
的表达式如下:
[0055][0056]aij
代表像素点(i,j)上下左右15个像素范围的区域;如果α
ij
越大,则说明该点像
素(i,j)与周围像素不同,因此这是一个重要的像素,需要得到更多的关注。
[0057]
所述交并比损失l
wiou
表达式如下:
[0058][0059]
以上内容是结合具体/优选的实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员,在不脱离本发明构思的前提下,其还可以对这些已描述的实施方式做出若干替代或变型,而这些替代或变型方式都应当视为属于本发明的保护范围。
[0060]
本发明未详细说明部分属于本领域技术人员公知技术。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1