基于计算机视觉的模板支架安全风险识别方法
1.本发明涉及基于计算机视觉的模板支架安全风险识别方法,属于施工安全技术领域。
背景技术:
2.建筑业作为世界上最大的工业部门之一,在施工过程当中仍面临多种风险的威胁,因此风险识别十分重要。而目前依赖人工观察的方法仍然是监测施工生产力和现场安全的主要手段,效率低、成本高是人工观察法的缺点。随着计算机视觉与人工智能技术的发展,自动识别与评价的方法已成为研究界的重要方向并逐渐应用到各行各业。摄像机已成为建筑工地的标准设备,施工现场的实时监控数据包含有关项目进度和活动的重要视觉信息,对施工现场的风险自动识别有着极大的帮助。
3.工程施工过程常常伴随着众多施工风险,因此风险识别工作在工程安全管理中属于极其重要的一环,而某一风险常常是由多个至灾因子耦合作用导致。通过利用计算机视觉与深度学习技术,可以同时对不同施工位置的致灾因子进行识别,从而可以根据风险类别与分级规范,在致灾因子组合会触发某一风险时,及时发出危险警报和报告风险源。在图像或视频中检测建筑资源(例如机器、工人和材料)是开发自动化分析施工视频所需的第一个基本步骤。一旦施工对象得到正确识别,大量的施工监控任务就可以实现自动化。例如,同时检测挖掘机和自卸卡车可以自动计算土方工程中的土方装载周期。参照图1所示,机器和工人的连续检测可以及时防止潜在的碰撞,并即时提醒建筑工程师。对建筑材料的检测确定了供应链中的材料位置,并能够毫不费力地得出项目绩效指标。
技术实现要素:
4.本发明提出了基于计算机视觉的模板支架安全风险识别方法,利用计算机视觉与深度学习技术研究自动识别、划分模板支架位置区域,识别塔吊提取的建筑材料、塔吊行为,实时跟踪吊起物体位置,分析其行为对模板支架的安全影响,以解决人工观察法存在的效率低成本高的问题。
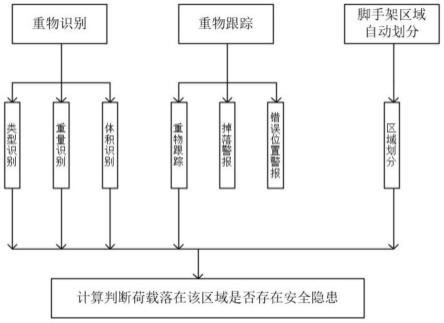
5.基于计算机视觉的模板支架安全风险识别方法,计算机视觉的模板支架安全监测方法包括以下步骤:
6.s100、通过实现多类型重物识别,在塔吊起吊重物之前,识别调取物品的材料信息,同时用力传感器测量待吊重物的重量信息;
7.s200、通过在需监控模板支架附近布置视觉传感器,经过预处理,将视觉传感器视野内的模板支架位置划分成若干单元,若有荷载出现在视野中时,系统将立即识别并判断其所处位置,结合结构荷载信息判断荷载对模板支架安全是否会造成影响;
8.s300、在重物提起阶段,通过目标跟踪技术与背景分割技术,实时跟踪被吊起目标所处位置,判断其即将落在模板支架的区域位置,对不安全行为及时做出预警,同时也可以判断起吊轨迹是否正确及吊起目标是否脱落,起吊终点是否正确等。
9.进一步的,在s100前,还包括s000:得到训练好的卷积神经网络cnn:
10.s010、从各种视频中提取多类重物图片,对图片进行预处理,对将所有图片的分辨率统一降为512
×
512像素,作为待分类数据;
11.s020、将待分类数据进行分类和标注,放在不同的文件夹中;
12.s030、对分类和标注好的数据进行数据增强;
13.s040、将经过数据增强和数据扩充的数据输入卷积神经网络cnn,对卷积神经网络cnn进行训练。
14.进一步的,在s030中,具体的,增强方式为:水平随机翻转图像和相关的框标签、随机缩放图像以及相关的框标签、抖动图像颜色。
15.进一步的,在s040中,具体包括以下步骤:
16.s041、确定数据流及建立数据结构:
17.卷积神经网络cnn是一个包含输入层、卷积层和输出层的网络模型,输入层是112
×
1的列向量,每个分量的值为0或1,对于每个子单元,有224
×
224像素和3个频道,然后进入第一个卷积层,卷积核的大小为7
×
7,卷积核的个数为64,步长为2,填充为3,
18.卷积层计算:
[0019][0020]
池化层计算:
[0021][0022]
式中:f为卷积核,卷积核的大小为f
×
f,s为步长大小,p为填充值大小,n为输出大小,w为输入大小,f为卷积核大小;
[0023]
s042、对卷积神经网络cnn进行训练:
[0024]
一次输入所有的训练样本,调整训练样本以平衡训练集中的图像数量,将第一卷积层的网络滤波器权值可视化,使用cnn图像特征训练一个多类svm分类器,
[0025]
超参数设置:学习率为0.1;动量因子为0.9;权重衰减因子为5e-4;卷积层的层数为49;批处理的大小为32;损失函数为“crossentropyex”;
[0026]
s043、得到训练结果:
[0027]
将集合分割成训练和验证数据。从每个集合中选取60%的图像作为训练数据,其余的40%作为验证数据,分割形式为随机分割,训练集和测试集将由cnn模型进行处理,训练后,平均精确率为:98.15%。
[0028]
进一步的,在s300中,具体包括以下步骤:
[0029]
s310、计算前景掩码:使用opencv提供的背景分割器backgroundsubtractorknn计算前景掩码;
[0030]
s320、二值化处理:在s310中计算得到的前景掩码含有前景的白色值以及阴影的灰色值,将前景掩码二值化,即将非纯白色的所有像素点均设置为纯白色;
[0031]
s330、目标跟踪:使用基本的目标跟踪算法检测运动中物体的轮廓,并在原始帧上绘制检测结果。
[0032]
进一步的,在s200和s300间,还包括s250、对模板支架区域位置进行标定,具体包
括以下步骤:
[0033]
s251、通过相机设备拍摄得到的施工现场模板支架实际图像视频数据;
[0034]
s252、对模板支架区域进行划分,具体的:
[0035]
进行阈值分割:使用背景分割算法通过任意选取一个阈值t将图像分为前景和背景两部分,前景像素点占图像的比例为w0、均值为u0,背景像素点占图像的比例为w1、均值为u1,图像整体的均值为u=w0*u0+w1*u1,建立目标函数g(t)=w0*(u0-u)^2+w1*(u1-u)^2,g(t)即为当分割阈值为t时的类间方差,otsu算法使得g(t)最大时所对应的t为最佳阈值;
[0036]
进行图像滤波:对阈值分割后的结果进行滤波处理,消除不必要噪点;
[0037]
进行投影划分区域:对滤波处理后的图像分别进行水平和垂直方向的投影,根据其结果图像,以每个已规定长度的区间内波峰位置为目标点,得知相机视野中的模板支架分为5*5的区域。
[0038]
本发明的有益效果:
[0039]
本发明针对多风险源下施工过程安全风险识别问题,通过将工程施工中的具体问题抽象出来进行实验室方法研究,利用计算机视觉与人工智能技术实现了一种模板支架安全监测的方法。在具体研究中,将技术手段拆解为重物识别、重物跟踪、模板支架区域划分三个部分,其中重物识别部分准确率高达98.15%,重物跟踪及模板支架区域划分方面也克服了复杂背景因素的影响,取得了较为准确的跟踪与识别效果。
[0040]
通过上述分析模块,本发明可以通过及时发现致灾因子,根据风险类别与分级,在致灾因子组合会触发某一风险时,及时发出危险警报和报告风险源,并构建出如下的模板支架施工安全风险分析框架:基于工地现场视觉监测系统,通过材料识别和重物识别功能准确识别用于塔吊起重的材料种类和体积,进而通过后台程序估算吊起材料的大致重量;通过重物跟踪监视塔吊行为,从而判断材料的吊放位置,再通过模板支架区域识别提前识别吊放位置处模板支架的结构形式。后台根据材料重量估算情况和模板支架设计模型估算材料放置在模板支架上后模板支架的安全情况。一旦发现存在安全风险(局部屈曲、倒塌等)能够在材料落地前提醒塔吊操作员以及时终止操作,从而保证模板支架安全。
附图说明
[0041]
图1为多风险源施工过程下的风险识别原理图;
[0042]
图2为本发明的目标框图;
[0043]
图3为本发明申请的基于计算机视觉的模板支架安全风险识别方法的流程图;
[0044]
图4为resnet-50示意图;
[0045]
图5为木材数据集示例图;
[0046]
图6为图像扩充示例图,其中,图6(a)为原图,图6(b)为旋转90
°
图,图6(c)为镜像图;
[0047]
图7为识别结果示意图;
[0048]
图8为原理示意图;
[0049]
图9为吊钩水平运动的识别图;
[0050]
图10为初始图像;
[0051]
图11为灰度图及梯度幅值图;
[0052]
图12为阈值分割结果;
[0053]
图13为中值模糊滤波图;
[0054]
图14为像素投影结果,其中,图14(a)为水平投影,图14(b)为垂直投影。
具体实施方式
[0055]
下面的参照附图将更详细地描述本发明的具体实施例。虽然附图中显示了本发明的具体实施例,然而应当理解,可以以各种形式实现本发明而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本发明,并且能够将本发明的范围完整的传达给本领域的技术人员。
[0056]
需要说明的是,在说明书及权利要求当中使用了某些词汇来指称特定组件。本领域技术人员应可以理解,技术人员可能会用不同名词来称呼同一个组件。本说明书及权利要求并不以名词的差异作为区分组件的方式,而是以组件在功能上的差异作为区分的准则。如在通篇说明书及权利要求当中所提及的“包含”或“包括”为一开放式用语,故应解释成“包含但不限定于”。说明书后续描述为实施本发明的较佳实施方式,然所述描述乃以说明书的一般原则为目的,并非用以限定本发明的范围。本发明的保护范围当视所附权利要求所界定者为准。
[0057]
本发明将利用计算机视觉与深度学习技术研究自动识别、划分模板支架位置区域,识别塔吊提取的建筑材料、塔吊行为,实时跟踪吊起物体位置,分析其行为对模板支架的安全影响。
[0058]
参照图3所示,基于计算机视觉的模板支架安全风险识别方法,计算机视觉的模板支架安全监测方法包括以下步骤:
[0059]
s100、通过实现多类型重物识别,在塔吊起吊重物之前,识别调取物品的材料信息,利用计算机视觉技术识别它是什么材料,比如是钢筋或是混凝土砌块,同时用力传感器测量它的重量信息;
[0060]
s200、通过在需监控模板支架附近布置视觉传感器,经过阈值分割、滤波、投影等操作,将视野内的模板支架位置划分成一个个格子的区域。若有荷载(重物)出现在视野中时,系统将立即识别并判断其所处位置,结合结构荷载等信息判断其对模板支架安全是否会造成影响;
[0061]
s300、在重物提起阶段,通过目标跟踪技术与背景分割技术,实时跟踪吊起目标所处位置,判断其即将落在模板支架的区域位置,对不安全行为及时做出预警,同时也可以判断起吊轨迹是否正确及吊起目标是否脱落,起吊终点是否正确等。
[0062]
具体的,参照图2所示,通过实现多类型重物识别、目标跟踪与区域定位、模板支架区域划分三个部分内容,利用视觉传感器与计算机识别并跟踪不同种类重物到达模板支架位置区域,对其安全风险做出实时评估,降低施工安全风险。
[0063]
工程施工过程中的某一风险常常是由多个至灾因子耦合作用导致,因此致灾因子的识别是施工风险识别的重要一环。图像识别技术可以对施工场景和材料的类型进行准确识别,进而有效识别施工风险,如识别到焊接作业和可燃材料出现在同一场景时,可判断其存在起火风险。
[0064]
卷积神经网络(cnn)是一种强大的机器学习技术,来自深度学习领域。cnn使用大量不同种类的集合进行训练。在这个模型中,重物的图像被分类为n类。分类使用多类线性支持向量机训练与cnn的特征提取图像。这种图像分类方法遵循的是标准实验。使用从图像中提取的特征训练现成的分类器。
[0065]
有几个训练有素的网络已经流行起来。大多数的这些已经在imagenet数据集上训练过,本发明是使用resnet50函数加载。
[0066]
本模型采用基于现代卷积神经网络的图像类别分类方法,其优点是完全自主学习性。流程是首先是输入的图片(image),经过一层卷积层(convolution),然后在用池化(pooling)方式处理卷积的信息(比如使用max pooling的方式),在经过一次同样的处理,把得到的第二次处理的信息传入两层全连接的神经层(fully connected),这也是一般的两层神经网络层。
[0067]
进一步的,在s100前,还包括s000:得到训练好的卷积神经网络cnn:
[0068]
s010、从各种视频中提取多类重物图片,对图片进行预处理,对将所有图片的分辨率统一降为512
×
512像素,作为待分类数据;
[0069]
s020、参照图5所示,为完成由输入图像到输出重物类别端训练的有监督学习过程,我们将不同的重物图片分类放入不同的文件夹中;
[0070]
s030、对分类好的数据进行数据增强;
[0071]
s040、将经过数据增强和数据扩充的数据输入卷积神经网络cnn,对卷积神经网络cnn进行训练。
[0072]
进一步的,在s030中,具体的,增强方式为:水平随机翻转图像和相关的框标签、随机缩放图像以及相关的框标签、抖动图像颜色。
[0073]
进一步的,在s040中,具体包括以下步骤:
[0074]
具体的,对于s010数据处理,从各种视频中提取多类重物图像,原始图像的分辨率与格式都不相同,对图片进行预处理。图像中不仅仅包含了多类重物信息,还包括了各种具有干扰作用的背景信息,可以较好的模拟真实检测中不可避免的出现众多其他复杂信息的状况。原始图像从数个不同种类的视频文件中提取出来,范围较广,具有多尺度的特征。
[0075]
图像的分辨率都普遍比较大,且大小不统一,考虑到在识别过程中,塔吊区域在图像中的占比更加重要,并且在实际的工程现场拍摄的塔吊图片也不一定有这么高的分辨率,因此将所有图片的分辨率统一降为512
×
512像素,输入到深度学习网络模型,如此可以降低计算成本,同时保留了塔吊位置的重要信息。
[0076]
对于数据增强,参照图6所示,首先对图像进行增强,数据扩充用于在训练过程中通过随机转换原始数据来提高网络准确性。通过使用数据扩充,可以增加训练数据大小,而不必实际增加标记训练样本的数量。增强方式为:水平随机翻转图像和相关的框标签、随机缩放图像以及相关的框标签、抖动图像颜色。
[0077]
s041、确定数据流及建立数据结构:
[0078]
该组件是一个包含输入层、卷积层和输出层的网络模型,输入层是112
×
1的列向量,每个分量的值为0或1,对于每个子单元,有224
×
224像素和3个频道,然后进入第一个卷积层,卷积核的大小为7
×
7,卷积核的个数为64,步长为2,填充为3,
[0079]
卷积层计算:
[0080][0081]
池化层计算:
[0082][0083]
式中:f为卷积核,卷积核的大小为f
×
f,s为步长,p为填充,;
[0084]
s042、对卷积神经网络cnn进行训练:
[0085]
一次输入所有的训练样本。由于每个类别的数据集中包含的图像数量不相等,我们首先调整它以平衡训练集中的图像数量。cnn的每一层都会对输入图像产生响应或激活。要看到这一点,可以将第一卷积层的网络滤波器权值可视化。这有助于建立一种直觉,了解为什么从cnn提取的特征在图像识别任务中如此有效。接下来,使用cnn图像特征训练一个多类svm分类器。
[0086]
超参数设置:学习率为0.1;动量因子为0.9;权重衰减因子为5e-4;卷积层的层数为49;批处理的大小为32;损失函数为“crossentropyex”;
[0087]
s043、得到训练结果:
[0088]
参照图7所示,将集合分割成训练和验证数据。从每个集合中选取60%的图像作为训练数据,其余的40%作为验证数据,分割形式为随机分割,训练集和测试集将由cnn模型进行处理,训练后,平均精确率为:98.15%。
[0089]
在现实施工项目中,塔吊处于十分复杂的视觉背景环境中,传统的目标跟踪技术(如kcf)往往不能达到很好的使用效果。因此,分割塔吊与施工背景非常有必要,通过背景分割,去除与塔吊运动无关的背景可使得目标跟踪更为准确且有实用价值。通过使用目标跟踪技术,可实时识别和跟踪吊钩和重物位置,结合异常检测技术判断塔吊运行轨迹是否正确、重物是否脱落以及重物有无脱落风险等。
[0090]
基于模型密度评估的背景提取算法原理是先进行模型密度评估,然后在像素级对图像进行前景与背景分类的方法,它们具有相同的假设前提——各个像素之间是没有相关性的,跟它们算法思想不同的方法主要是基于马尔可夫随机场理论,认为每个像素跟周围的像素是有相关性关系,但是基于马尔可夫随机场的方法速度与执行效率都堪忧!所以opencv中没有实现。
[0091]
k-nearest(knn)对应的算法可用来计算背景分割。opencv提供了一个称为backgroundsubtractor的类,在分割前景和背景时很方便,它是一个功能很全的类,不仅执行背景分割,而且能够提高背景检测的效果,并提供将分类结果保存到文件的功能。
[0092]
为保证数据的真实有效,本发明将施工工作中具体问题抽象出来,选择了具有复杂背景的视角,通过微单数码相机(f=15mm)拍摄了一组塔吊的运动视频。视频内容包括塔吊的水平方向旋转、吊钩的水平方向运动和吊钩的铅锤方向运动。
[0093]
进一步的,在s300中,具体包括以下步骤:
[0094]
s310、计算前景掩码:参照图8所示,使用opencv提供的背景分割器backgroundsubtractorknn计算前景掩码;
[0095]
s320、二值化处理:在s310中计算得到的前景掩码含有前景的白色值以及阴影的灰色值,将前景掩码二值化,即将非纯白色的所有像素点均设置为纯白色;
[0096]
s330、目标跟踪:使用基本的目标跟踪算法检测运动中物体的轮廓,并在原始帧上绘制检测结果。
[0097]
具体的,参照图9所示,根据运行结果,使用背景分割算法的目标跟踪相比于传统目标跟踪在效果上具有十分明显的优势,改善了传统跟踪算法在复杂背景下无法准确跟踪的弊端,准确自动识别并跟踪运行中的塔吊及调取材料的位置。
[0098]
模板支架上的荷载分布往往会严重影响到其安全性,因此判断荷载位置对于模板支架安全检测和评估有着极其重要的作用,通过对模板支架区域进行识别和标定,利用图像识别与目标检测技术识别重物荷载类型和即将作用在模板支架上的位置,并结合力传感器数据得到荷载大小,在材料落地前判断是否存在安全风险(局部屈曲、倒塌等)。
[0099]
图像阈值化分割是一种最常用,同时也是最简单的图像分割方法,它特别适用于目标和背景占据不同灰度级范围的图像。它不仅可以极大的压缩数据量,而且也大大简化了分析和处理步骤,因此在很多情况下,是进行图像分析、特征提取与模式识别之前的必要的图像预处理过程。图像阈值化的目的是要按照灰度级,对像素集合进行一个划分,得到的每个子集形成一个与现实景物相对应的区域,各个区域内部具有一致的属性,而相邻区域布局有这种一致属性。这样的划分可以通过从灰度级出发选取一个或多个阈值来实现。otsu算法是由日本学者otsu于1979年提出的一种对图像进行二值化的高效算法,是一种自适应的阈值确定的方法,又称大津阈值分割法,是最小二乘法意义下的最优分割。
[0100]
图像滤波,即在尽量保留图像细节特征的条件下对目标图像的噪声进行抑制,是图像预处理中不可缺少的操作,其处理效果的好坏将直接影响到后续图像处理和分析的有效性和可靠性。由于成像系统、传输介质和记录设备等的不完善,数字图像在其形成、传输记录过程中往往会受到多种噪声的污染。另外,在图像处理的某些环节当输入的像对象并不如预想时也会在结果图像中引入噪声。这些噪声在图像上常表现为一引起较强视觉效果的孤立像素点或像素块。一般,噪声信号与要研究的对象不相关它以无用的信息形式出现,扰乱图像的可观测信息。对于数字图像信号,噪声表为或大或小的极值,这些极值通过加减作用于图像像素的真实灰度值上,对图像造成亮、暗点干扰,极大降低了图像质量,影响图像复原、分割、特征提取、图像识别等后继工作的进行。要构造一种有效抑制噪声的滤波器必须考虑两个基本问题:能有效地去除目标和背景中的噪声;同时,能很好地保护图像目标的形状、大小及特定的几何和拓扑结构特征。
[0101]
为保证结果真实有效,本发明采用通过相机设备拍摄得到的施工现场模板支架实际图像视频数据。
[0102]
进一步的,参照图10-图14所示,在s200和s300间,还包括s250、对模板支架区域位置进行标定,具体包括以下步骤:
[0103]
s251、通过相机设备拍摄得到的施工现场模板支架实际图像视频数据;
[0104]
s252、对模板支架区域进行划分,具体的:
[0105]
该算法通过对任意选取一个阈值t将图像分为两部分(前景和背景),前景像素点占图像的比例为w0、均值为u0,背景像素点占图像的比例为w1、均值为u1,图像整体的均值为u=w0*u0+w1*u1,建立目标函数g(t)=w0*(u0-u)^2+w1*(u1-u)^2,g(t)即为当分割阈值为t时的类间方差。otsu算法使得g(t)最大时所对应的t为最佳阈值(遍历不同阈值下[0,255])。结果如图9所示;
[0106]
不难看出,阈值分割后的结果中有很多噪点,在此对其进行滤波处理,消除不必要噪点,经过对比选择,中值模糊滤波结果较为理想,有利于之后的步骤;
[0107]
对滤波处理后的图像分别进行水平和垂直方向的投影,根据其结果图像,以每个已规定长度的区间内波峰位置为目标点,可知相机视野中的模板支架可分为5*5的区域。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1