一种基于工况划分与神经网络的锅炉性能预测方法
1.本技术涉及燃煤锅炉性能在线预测方法,尤其涉及一种基于工况划分与神经网络的锅炉性能预测方法。
背景技术:
2.燃烧模型的精确建立是实现燃煤锅炉燃烧优化的重要步骤。因采用机理建模还存在许多困难,目前多采用智能算法如神经网络算法直接建立锅炉输入参数与输出参数之间的映射模型。对于从电厂采集的原始数据中建立模型所需要的数据集的处理一般包括异常值剔除和稳态检测。这样处理的目的是筛除仪器故障导致的异常数据和锅炉变工况时的不稳定数据。但是锅炉燃烧是一个多工况的复杂过程,上述数据处理方法在数据量较少时可以满足模型建立需求,但是当所需要预测的锅炉性能的时间跨度变大时,锅炉的典型工况的数据量会大大超过其他工况,使得模型在训练时为了满足精度要求而偏向典型工况,这样会导致模型在预测其他工况时失真,所以亟需对模型所用的数据集做进一步处理。
技术实现要素:
3.本技术提供了一种基于工况划分与神经网络的锅炉性能预测方法,其技术目的是对锅炉各工况的数据进行划分,按工况建立神经网络模型,以实现对锅炉性能的精准预测。
4.本技术的上述技术目的是通过以下技术方案得以实现的:
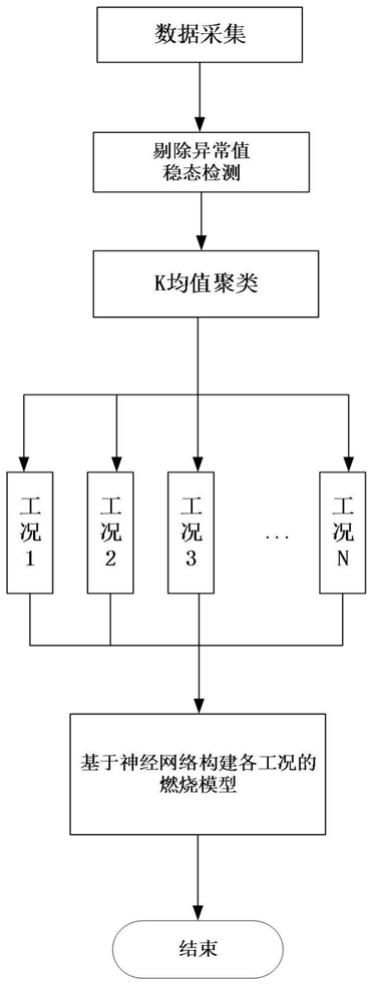
5.一种基于工况划分与神经网络的锅炉性能预测方法,包括:
6.s1:获取锅炉运行数据和锅炉性能指标,对运行数据和性能指标进行预处理,得到用于建模的静态数据集,避免锅炉变工况数据的影响。
7.其中,锅炉性能指标包括锅炉效率与nox排放浓度。锅炉效率通过预设的效率计算模块间接获得,nox排放浓度由连续性排放检测仪获得。
8.s2:采用k均值聚类方法对所述静态数据集进行划分,得到划分结果,根据划分结果建立不同数据池。
9.s3:对不同数据池中的各工况分别建立bp神经网络模型,通过各bp神经网络模型对锅炉性能进行预测。
10.将各数据集分别按照7:3的比例划分训练集与测试集,训练集与测试集的选取采用随机抽取的方法,提高模型的泛化能力。
11.另外,可以判断各bp神经网络模型的输出是否达到精度要求,若未达到精度要求,则返回所述步骤s3对相应工况的bp神经网络模型进行调整。
12.进一步地,所述步骤s1中,所述预处理的方法包括剔除异常值法和稳态判别法;
13.所述剔除异常值法包括根据实践经验划定参数范围或通过3σ原则处理数据;
14.所述稳态判别法为滑动窗口法,通过判断窗口内数据的波动范围是否符合锅炉试验手册中的稳态工况的要求。
15.进一步地,所述步骤s2中,采用k均值聚类方法对所述静态数据集进行划分,包括:
16.根据距离最大化原则选取k个初始聚类中心;
17.计算t时刻采集到的数据di与初始聚类中心的误差平方和,根据误差平方和得到划分结果,表示为:
[0018][0019]
其中,k表示聚类中心,di=(d(1)
t
,
…
,d(m)
t
,
…
,d(m)
t
,p),d(m)
t
表示在t时刻采集到的第m个锅炉运行数据,p表示锅炉工况划分的指标,m表示运行数据总数;静态数据集s 表示为s={d1,
…
,di,
…dn
}。
[0020]
公式(1)的本质要求是求解聚类后的各类数据与聚类中心的误差平方和,在电厂的工况划分中是求性能指标与聚类中心的性能指标的误差平方和。为避免随机选取的初始聚类中心对聚类结果的影响,在初始化聚类中心时引入彼此距离最大化原则,通过该原则加上大量的电厂运行数据并经过多次迭代后可以获得稳定的聚类中心。
[0021]
本技术的有益效果在于:通过采集锅炉运行数据与锅炉性能指标获取原始数据集,通过数据预处理剔除异常数据与非稳态数据获取静态数据集,通过k均值聚类方法获取锅炉工况划分标准,对锅炉各工况建立数据池,按工况建立神经网络模型,实现准确预测锅炉性能的目的。
[0022]
本技术根据锅炉不同的运行工况进行单独建模,模型误差比整体建模的误差更小,精度更高;且使训练的网络更贴近工况运行实际,有利于后续对锅炉参数的寻优。
附图说明
[0023]
图1为本技术所述方法的流程图;
[0024]
图2为误差平方和随聚类数的变化示意图;
[0025]
图3为bp神经网络模型的结构示意图;
[0026]
图4为具体实施例的模型训练情况示意图。
具体实施方式
[0027]
下面将结合附图对本技术技术方案进行详细说明。
[0028]
图1为本技术所述方法的流程图,具体过程不再赘述。本文采用某电站1000mw机组运行数据,对该技术方案进行阐述。
[0029]
(1)获取原始锅炉运行数据:提取机组连续运行46天的数据,采样频率为1分钟,共计66240条数据,通过参数范围划定与3σ原则剔除原始数据中的异常值,剔除后剩余 65299条数据;通过滑动窗口法判断稳态工况,共获得30720条数据。
[0030]
(2)使用k均值聚类方法对静态数据集进行划分,例如选择锅炉负荷与相对煤质系数作为划分指标。由电厂dcs系统获取的数据集为s={d1,
…
,di,
…dn
},其中,di=(d(1)
t
,
…
,d(m)
t
,
…
,d(m)
t
,p),d(k)
t
表示在t时刻采集到的第m个锅炉运行参数,p 表示锅炉负荷与相对煤质系数。根据距离最大化原则选取k个聚类中心,计算各运行参数与聚类中心的距离,根据公式(1)计算整体数据集与聚类中心的误差平方和,图2为计算的误差平方和随负荷与相对煤质系数聚类数的变化示意图,对于负荷的聚类数的计算一开始将40%左右的负荷排除在外,因为该类负荷与其他负荷距离较远,可以明显归为一类,最终选取图2中
椭圆中的点作为最终的聚类数,该点既考虑到了误差平方和较小的原则又会使划分不至于过细。
[0031]
最终按照负荷将工况划分为4类,按照相对煤质系数将工况分为了3类,聚类过程如图2所示。最终,共将锅炉工况划分为12类,划分结果如表1所示,各工况所占数据样本的数量不一,数据样本集中分布于负荷与煤质相匹配的工况,例如40%负荷与低煤质的样本数在同负荷工况中的样本数是最多的,50%负荷与70%负荷中中高煤质的工况数据样本量较多,高工况低煤质的工况数据量为0。数据样本的分布情况与电厂的实际生产情况是一致的。
[0032]
表1样本分类情况
[0033]
数据集负荷煤质样本数1[376.77,412.54](2.23,2.52)7452[376.77,412.54](2.52,3.07]3283[376.77,412.54][1.88,2.23]68784[500.27,588.30](2.23,2.52)59785[500.27,588.30](2,52,3.07]19006[500.27,588.30][1.88,2.23]4827[588.32,734.12](2.23,2.52)55718[588.32,734.12](2,52,3.07]31669[588.32,734.12][1.88,2.23]9410[734.15,1015.90](2.23,2.52)100811[734.15,1015.90](2,52,3.07]419512[734.15,1015.90][1.88,2.23]0
[0034]
(3)对各工况建立神经网络模型,模型的输入选取负荷、炉膛氧量、煤粉温度、一、二次风门开度共40个物理参数,输出选取nox排放浓度,因此神经网络模型的输入神经元个数为40,输出为1,隐藏层神经元个数选取12,模型的结构如图3所示,训练结果如图4所示,横坐标1-11数据集为表1中各数据集单独训练后训练集均方误差与测试集均方误差,数据集12的柱状图表示的是分工况建模后数据集全局的训练集均方误差与测试集均方误差。圆点横线表示整体建模时的测试集均方误差,星号横线为整体建模时的训练集均方误差。可以看出,除部分数据集(1,2,9)因为样本数量较少的原因误差会高于整体建模时的误差,数据集9数据量稀少导致训练集误差与测试集误差相距较远,其他数据集(3,4,5,7,8,10,11)的误差都可与整体建模时的误差相近,甚至更低,分工况建模后的整体误差也小于整体建模时的误差。这是因为分工况建模后,数据样本之间联系更为紧密,有利于网络的训练与学习,因此生成的网络更能反映当前的工况。
[0035]
以上为本技术示范性实施例,本技术的保护范围由权利要求书及其等效物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1