一种儿童临床低剂量CT图像的增强方法
一种儿童临床低剂量ct图像的增强方法
技术领域
1.本发明属于医学人工智能领域,尤其是涉及一种儿童临床低剂量ct图像的增强方法。
背景技术:
2.在儿科放射成像中,儿童处于生长发育的关键时期,细胞分裂旺盛,对射线更加敏感。有研究表明,在接受相同剂量的射线辐射情况下,儿童患癌的几率显著大于成人,证明放射线辐射对儿童的损伤更大。多个临床研究中开展了儿童低剂量ct检查,尤其以肺部研究居多。儿童肺部疾病主要以感染和解剖学发育异常为主,对于图像分辨率要求低于成人;儿童体型较小,对射线衰减较少。因此,儿童应该且适合采用比成人更低剂量的ct扫描进行诊断。
3.但是,低剂量的ct图像具有较低的图像分辨率,不便于医生观察ct,因此亟需设计一种儿童临床低剂量ct图像的增强方法,使得低剂量的ct图像具有较高的图像分辨率,便于医生观察ct,减少儿童辐射。
4.现有技术公开了一些对低剂量ct图像进行降噪或重建的方法,如公开号为cn114331921a的中国专利文献公开了一种低剂量ct图像降噪方法,采集若干个ct匹配图像对,并基于采集的ct匹配图像对构建训练数据集;构建用于将低剂量ct图像进行降噪处理得到高剂量ct图像的神经网络模型;利用训练数据集训练神经网络模型,得到ct图像降噪模型;将待优化的低剂量ct图像输入至ct图像降噪模型中,得到降噪处理后的高剂量ct图像。
5.公开号为cn106780641a的中国专利文献公开了一种低剂量x射线ct图像重建方法,首先获取ct设备的成像系统参数和低剂量ct扫描协议下的投影数据;通过成像过程的统计规律构建弦图数据的统计生成模型;根据投影数据和图像的结构特征与实际应用中的需求,构建弦图数据先验的统计模型;构建完整的统计模型,并根据最大后验估计方法,将模型转化为弦图数据复原模型;应用弦图数据复原模型,得到估计的弦图数据与其它统计变量;根据得到的弦图数据进行ct图像重建,得到输出ct图。
6.但是现有的方法,并不能很好的适用于儿童临床低剂量ct图像的增强处理,无法满足临床诊断要求的图像质量。
技术实现要素:
7.本发明提供了一种儿童临床低剂量ct图像的增强方法,可以将低剂量噪声污染严重的图像增强至满足临床诊断要求的图像质量。
8.一种儿童临床低剂量ct图像的增强方法,包括以下步骤:
9.(1)收集训练数据集和验证数据集,其中,训练数据集包含不同部位的多个低剂量ct图像和对应的高剂量ct图像,验证集包括不同部位的多个低剂量ct图像;
10.(2)对训练数据集及验证数据集中的图像进行预处理;
11.(3)构建ct图像增强模型,所述的ct图像增强模型基于改进的双通道transformer网络,还包含图像分解模块和分段重建模块,模型工作过程如下:
12.首先利用图像分解模块,将低剂量ct图像分解为低频部分和高频部分,从低频部分提取内容特征x
lc
和潜在纹理特征x
lt
,从高频部分提取嵌入特征x
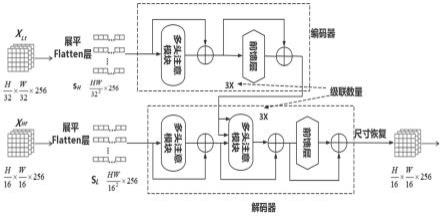
hf
;
13.将x
lt
和x
hf
分别重构为两个序列s
l
和sh后作为双通道transformer中编码器和解码器的输入,得到解码器的输出特征y;
14.利用分段重建模块,将输出特征y与低频部分中特定的内容特征x
lc1
、x
lc2
相结合,分段重建成最终增强的儿童低剂量ct图像;
15.(4)利用训练数据集对ct图像增强模型进行训练,并利用验证数据集对ct图像增强模型进行评估,根据评估的效果对模型的超参数进行调整;
16.(5)将待增强的儿童临床低剂量ct图像输入训练好的ct图像增强模型,得到最终增强的儿童低剂量ct图像。
17.进一步地,步骤(2)中,所述的预处理包括随机裁剪、镜像翻转和仿射变换操作,以上操作均采用0.5概率值随机采样。
18.步骤(3)中,图像分解模块的工作流程如下:将低剂量ct图像利用高斯滤波分解为低频部分和高频部分;对于低频部分,使用两个卷积层获得低分辨率的特征,然后设置两条路径提取内容特征,一条路径分别通过一层和两层卷积后获得特定的内容特征x
lc1
和x
lc2
,另一条路径通过三层卷积后获得潜在的纹理特征x
lt
;
19.对于高频部分,采用亚像素层使高频部分成为低分辨率图像,并通过三层卷积得到最终的嵌入特征x
hf
。
20.x
lc1
、x
lc2
、x
lt
、x
hf
的特征尺寸分别为h/8
×
w/8
×
64、h/16
×
w/16
×
256、h/32
×
w/32
×
256和h/16
×
w/16
×
256,其中,h、w分别为ct图像的原长宽尺寸,64、256为filters数。
21.步骤(3)中,改进的双通道transformer网络包括三个编码器和三个解码器,每个编码器包括一个多头注意模块和一个前馈层,每个解码器包括两个多头注意模块和一个前馈层;相同的编码器之间采用级联方式连接,即每个编码器同时作为下一个编码器的输入;每个解码器同时也作为下一个解码器的输入。
22.对于编码器,使用由特征重构的序列s
l
作为输入,运算公式如下:
[0023][0024][0025]
s.t.i∈{1,2,3}
[0026]
其中,mhsa表示多头注意模块,mlp表示前馈层,i为编码器或解码器的序号;
[0027]
然后使用一个多注意模块来寻找区域的全局关系,最后使用两个全连接层输出;得到编码器的输出后,将sh输入到解码器的第一个多头注意模块中,并将作为第二个多头注意模块中每个解码器的key和值,公式如下:
[0028][0029]
[0030][0031]
s.t.i∈{1,2,3}
[0032]
最终,解码器输出特征y。
[0033]
步骤(3)中,分段重建模块的工作流程如下:
[0034]
将输出的特征y和x
lc2
叠加,输入resnet50后输出到两个conv2d+lrelu层,接着输入一个亚像素层,输出特征尺寸为h/8
×
w/8
×
64的高分辨率特征;
[0035]
然后,将输出的高分辨率特征和x
lc1
叠加,再经过一个带有两个conv2d+lrelu图层和亚像素层的resnet50,得到与输入图像尺寸一致的大小为h、w的ct图像最终输出。
[0036]
步骤(4)中,ct图像增强模型训练时采用有监督训练,损失函数为mse,用于测量输出和正常剂量ct图像之间的差值,mse的公式如下:
[0037][0038]
式中,i
nd
为正常剂量ct图像,i
ld
为低剂量ct图像,f为ct图像增强模型,θ为网络参数。
[0039]
与现有技术相比,本发明具有以下有益效果:
[0040]
本发明构具有较高的处理效率和较好的增强效果,通过图像分解模块将低剂量ct图像分解为低频部分和高频部分,从低频部分提取内容特征x
lc
和潜在纹理特征x
lt
,从高频部分提取嵌入特征x
hf
后输入改进的双通道transformer中编码器和解码器,得到输出特征y;并利用分段重建模块将输出特征y与低频部分中特定的内容特征x
lc1
、x
lc2
相结合,分段重建成最终增强的儿童低剂量ct图像,从而得到可靠的清晰ct图像。
附图说明
[0041]
图1为本发明ct图像增强模型中图像分解模块的网络结构示意图;
[0042]
图2为本发明ct图像增强模型中改进的双通道transformer网络结构示意图;
[0043]
图3为本发明ct图像增强模型中分段重建模块的网络结构示意图。
具体实施方式
[0044]
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
[0045]
一种儿童临床低剂量ct图像的增强方法,包括以下步骤:
[0046]
步骤1,收集训练数据集和验证数据集。
[0047]
针对儿童不同部位相应的扫描协议方案收集训练数据集和验证数据集。训练数据集用于微调和训练现有的预训练模型,训练数据集包括低剂量和正常剂量各部位ct图像患者例数,其中头部300例,肺部300例,冠状动脉及其他(腹盆)300例,训练数据集中低剂量部分形成微调前低剂量ct图像数据集。验证数据集:获取低剂量图像,头部数据200例,肺部200例,冠状动脉及其他(腹盆)200例。验证数据集用于验证增强算法处理后的图像质量。该数据集与训练数据集合并为儿童多部位低剂量ct图像数据库。
[0048]
步骤2,对训练数据集及验证数据集中的图像进行预处理。
[0049]
为了丰富样本种类针对数据库做了相应的数据增强:采用随机裁剪、镜像翻转、仿
射变换等操作。以上增强操作均采用0.5概率值随机采样。其中,随机裁剪通过在原始图像中随机裁剪0.5~0.8面积比例的区域;镜像翻转近采用水平镜像反转;仿射变换采用如下矩阵运算:
[0050][0051]
步骤3,构建ct图像增强模型。
[0052]
ct图像增强模型基于改进的双通道transformer网络,还包含图像分解模块和分段重建模块,模型工作过程如下:
[0053]
首先将低剂量ct(low-dose ct,ldct)图像分解为两部分:高频(hf)和低频(lf)成分。然后,从低频部分提取内容特征(x
lc
)和潜在纹理特征(x
lt
),从高频部分提取高频嵌入(x
hf
)。此外,将x
lt
和x
hf
输入到一个改进的双通道transformer中,用三个编码器和解码器来获得良好的高频纹理特征。然后,将这些精细的hf纹理特征与预提取的x
lc
相结合,在分段重建的辅助下促进高质量ct图像的恢复。
[0054]
具体来说,对于图像去噪,噪声主要包含在高频子带。此外,剩下的低频子带中不仅包含了图像的主要内容,还包含了减弱的图像纹理,它们是无噪声的。这些减弱的图像纹理可以用来帮助去除高频子带的噪声。本发明使用双通道的transformer对ldct成像。首先,将带噪声的ldct图像分解为高频部分和低频部分。为了在保留图像内容的前提下去除图像噪声,从lf部分提取了相应的内容特征(x
lc
)和潜在纹理特征(x
lt
)。同时,从高频部分提取相应的嵌入特征(x
hf
)。由于transformer只能使用序列作为输入,因此本发明将x
lt
和x
hf
分别转换成分离的序列作为transformer编码器和解码器的输入。为了保留最终ldct图像的细节,本发明将变压器解码器的输出信息与低频部分的一些特定特征进行集成,然后逐级重建高质量和高分辨率的ldct图像。
[0055]
其次由于噪声主要留在hf部分,hf部分也含有大量的图像纹理。然而,只有在高频部分去除噪声,打破了高频部分和低频部分的关系,因为噪声降低的低频部分也有减弱的潜在织构。因此,本发明利用低频部分的潜在纹理去除高频部分的噪声。
[0056]
图像分解模块的结构如图1所示,首先使用两个卷积层从x
l
获得低分辨率的特征,然后设置两条路径提取内容特征,x
lc1
(h/8
×
w/8
×
64)(h,w分布为ct图像的原长宽尺寸,64为filters数),x
lc2
(h/16
×
w/16
×
256)和潜在的纹理特征x
lt
(h/32
×
w/32
×
256)。对于xh,本发明采用亚像素层使xh成为低分辨率图像(h/16
×
w/16
×
256),(亚像素层具有较大的感知场,可提供更多的上下文信息,能帮助生成更准确的细节)通过三层卷积得到最终的高级特征x
hf
。最终得到一个中等维度的序列从而可输入至transformer网络中。为了利用transformer的长距离依赖特性,本发明将x
lt
和x
hf
分别重构为两个序列s
l
和sh。
[0057]
如图2所示,改进双通道transformer,有三个编码器和三个解码器,每个编码器包括一个多头注意模块(mhsa)和一个前馈层(mlp)。每个解码器包括两个多头注意模块和一个前馈层。相同的编码器之间采用级联方式连接,即每个编码器同时作为下一个编码器的输入,同理每个解码器同时也作为下一个解码器的输入。对于transformer编码器,本发明使用由特征重构的序列s
l
(wh/1024
×
256)作为输入,运算公式如下,这里的i为编码器的序号,然后使用一个多注意模块来寻找区域的全局关系,最后使用两个全连接层输出,以增
加整个网络的表征能力。
[0058][0059][0060]
s.t.i∈{1,2,3}
[0061]
从x
l
中获取潜在纹理特征后,将sh(wh/256
×
256)输入到第一个多头注意模块中,并将作为第二个多头注意模块中每个transformer解码器的key和值,公式如下所示,中i为解码器的序号。
[0062][0063][0064][0065]
s.t.i∈{1,2,3}
[0066]
最终,解码器输出特征y。
[0067]
由于transformer只输出特征y(h/16
×
w/16
×
256),需要将y与x
lc1
、x
lc2
相结合,分段重建成最终的高质量的儿童低剂量ct图像。transformer的输出尺寸为h/16,w/162,256。
[0068]
分段重建模块的结构如图3所示,本发明对高分辨率ldct图像进行分段重建,第一步,本发明将输出的特征y和x
lc2
相加,然后输入输出到resnet50与两个conv2d+leaky-relu(lrelu)层,然后是一个亚像素层,这里输出的特征尺寸为h/8
×
w/8
×
64高分辨率特征。类似地,将输出的这些高分辨率特征和x
lc1
叠加。再经过一个带有两个conv2d+lrelu图层和亚像素层的resnet50,就可以得到与输入图像尺寸一致的大小为h,w的ct图像最终输出。
[0069]
步骤4,对ct图像增强模型进行训练。
[0070]
本发明实验环境如下,使用python 3.9版本编程语言,基于pytorch库实现,优化器使用adam框架优化参数,batchsize大小为8。显卡使用4张nvidia v100 gpu训练。
[0071]
模型训练采用有监督训练的方式,即low-dose ct作为网络输入,经过网络编解码即重建,获得重建预测输出,结合normal-dose ct进行监督,获得重建后的纹理信息,通过上采样网络结构,结合不同深度获得的图像内容信息对ct图像进行还原重建,即可获得可靠的清晰ct图像。
[0072]
模型使用的损失函数为mse,用于测量输出和正常剂量ct图像之间的差值,从而降低输入ldct图像中的噪声。mse的公式如下:
[0073]
式中,i
nd
为正常剂量ct(ndct)图像,i
ld
为低剂量ct(ldct)图像,f为提出的模型,θ为网络参数。
[0074]
学习速率前180个epoch设定为0.01,后续epoch采用余弦退火法调整学习率降低为0.00001,余弦退火法公式如下lr
max
、lr
min
分别表示学习率的最大值和最小值,t
cur
表示当前执行了多少个epoch,ti表示第一次运行的总epoch次数。最终损失值不在降低,或降低幅度低于10e-6则停止训练。
[0075][0076]
模型训练完成后再使用验证数据集包括头部数据200例,肺部200例,冠状动脉及其他(腹盆)200例输入至已训练好的模型中验证测试,为了达到更好的验证效果,实验设置增强前对照组,采用目标值法的双盲试验进行验证增强后图像质量是否满足临床要求。
[0077]
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1