一种通用盲文到汉字的转换方法及系统
1.本发明涉及盲文处理技术领域,特别是通用盲文到汉字的自动转换领域。
背景技术:
2.盲文是盲人阅读和获取信息的重要方式。它是一种触觉符号系统,印刷在纸张或显示在点显器上,通过触摸进行阅读。盲文的基本单位称作“方”,一方包含6个点位,通过设置每个点位是否有点共可形成64种组合(包括6个点位都没有点的空方),这些组合构成了最基本的盲文符号。
3.为了促进盲人与普通人的交流与沟通,需将盲人使用的盲文转换为汉字。对于字母文字,存在字母与盲文符号的直接映射,转换相对简单。而由于汉语盲文自身的特点,盲文-汉字自动转换难度较大。
4.由于盲文符号与汉字之间没有一一对应关系,汉语盲文被定义为一种拼音文字。在汉语盲文中,大多数情况下用2-3方表示一个汉字,其中一方表示声母,一方表示韵母,有些情况还需要再增加一方表示声调。汉语盲文与汉字文本最大的区别在于及其“分词连写”规则,即要求词与词之间用空方分隔。盲文分词与汉语分词不同,许多汉语中的短语在盲文中需要连写。针对分词连写,中国盲文标准中给出了100多条基于词法、语法和语义的细则,如
“‘
不’与动词、能愿动词、形容词、介词、单音节程度副词均应连写”等。
5.为了进一步减少歧义,盲文还制定了标调规则,即规定哪些音节需要显式地标出声调。当前主要有两种盲文方案在使用中,即“现行盲文”和“通用盲文”。两种盲文方案的分词规则相同,主要区别在于标调规则。在现行盲文中,为节省阅读时间和印刷成本,规定只对易混淆的词语、生疏词语、古汉语实词、非常用的单音节词等标调。一般认为现行盲文的标调率大约在5%左右。但是大量未标调的音节容易造成混淆,影响阅读和理解。因此,国家语委在2018年发布了“通用盲文”方案,通用盲文中虽然采用了一定的声调缺省设置,但是经过缺省规则转换,绝大多数音节都可确定声调。从2018年发布之日起,国家开始大力推广通用盲文,但是,由于目前缺乏通用盲文到汉字自动转换的工具和系统,而人工转换效率很低,导致目前盲人与普通人的文字交流存在障碍。
6.当前虽然已有一些汉字到盲文的自动转换系统,有些已经投入实用,但这些系统大多以汉字到现行盲文的转换为主,能够实现通用盲文到汉字转换的系统较少。
技术实现要素:
7.针对目前通用盲文到汉字的转换研究较少、未充分利用盲文分词信息等问题,本发明采用通用盲文-汉字对照语料及标记盲文分词信息的拼音-汉字对照语料,训练一个深度学习模型实现高效率和高准确的通用盲文到汉字转换。
8.具体来说,本发明提出了一种通用盲文到汉字的转换方法,其中包括:
9.步骤1、构建包括局部语义特征提取层和全局语义特征提取层的深度学习模型,获取待转换的通用盲文文本,且该局部语义特征提取层和该全局语义特征提取层共享嵌入层
和全连接层;
10.步骤2、由该通用盲文文本生成拼音音节序列和分词标记序列,经由嵌入层向量化后拼接得到融合盲文分词信息的拼音嵌入向量,分别输入该局部语义特征提取层和该全局语义特征提取层;
11.步骤3、该局部语义特征提取层提取该拼音嵌入向量的局部语义信息,该全局语义特征提取层提取该拼音嵌入向量中具有时序关系的上下文语义信息,将该局部语义信息和该上下文语义信息拼接后输入全连接层得到该通用盲文文本对应的汉字文本。
12.所述的通用盲文到汉字的转换方法,其中该深度学习模型的训练过程为将通用盲文-汉字对照语料分为多批数据,每批数据包括多条数据,每条数据均包含:拼音音节序列、分词标记序列、拼音对应的汉字文本;以该批数据的拼音音节序列和分词标记序列作为输入,得到该深度学习模型的预测汉字文本,根据该预测汉字文本和该拼音对应的汉字文本构建损失函数,通过反向传播更新该深度学习模型;
13.采用拼音-汉字对照语料微调更新完成的深度学习模型,在该拼音-汉字对照语料中,每条拼音文本有其对应的汉字文本;拼音按照通用盲文标调标准转换为省写音调的拼音,包括音节和声调,声调标记为:1表示阴平,2表示阳平,3表示上声,4表示去声,无音调表示轻声或声调被省写;采用一个盲文分词系统根据汉字和拼音信息自动得到盲文分词信息,得到标记分词信息的该拼音-汉字对照语料。
14.所述的通用盲文到汉字的转换方法,其中该分词标记序列基于bmes四位序列标注表示该拼音音节序列中各拼音音节的分词信息,其中b表示拼音音节对应盲文词的首位置;m表示拼音音节对应盲文词的中间位置;e表示拼音音节对应盲文词的末尾位置;s表示拼音音节对应一个单独的字。
15.所述的通用盲文到汉字的转换方法,其中该局部语义特征提取层包括三种不同高度的卷积核,高度分别为1、3和5,每种高度分别有两个卷积核,每个卷积核通过对该拼音嵌入向量做卷积运算得到特征向量,最终得到融合6个特征空间的特征向量,得到局部语义信息;该全局语义特征提取层采用双向门控循环单元网络实现该上下文语义信息的抓取。
16.本发明还提出了一种通用盲文到汉字的转换系统,其中包括:
17.模型构建模块,用于构建包括局部语义特征提取层和全局语义特征提取层的深度学习模型,获取待转换的通用盲文文本,且该局部语义特征提取层和该全局语义特征提取层共享嵌入层和全连接层;
18.预处理模块,用于由该通用盲文文本生成拼音音节序列和分词标记序列,经由嵌入层向量化后拼接得到融合盲文分词信息的拼音嵌入向量,分别输入该局部语义特征提取层和该全局语义特征提取层;
19.特征拼接模块,用于该局部语义特征提取层提取该拼音嵌入向量的局部语义信息,该全局语义特征提取层提取该拼音嵌入向量中具有时序关系的上下文语义信息,将该局部语义信息和该上下文语义信息拼接后输入全连接层得到该通用盲文文本对应的汉字文本。
20.所述的通用盲文到汉字的转换系统,其中该深度学习模型的训练过程为将通用盲文-汉字对照语料分为多批数据,每批数据包括多条数据,每条数据均包含:拼音音节序列、分词标记序列、拼音对应的汉字文本;以该批数据的拼音音节序列和分词标记序列作为输
入,得到该深度学习模型的预测汉字文本,根据该预测汉字文本和该拼音对应的汉字文本构建损失函数,通过反向传播更新该深度学习模型;
21.采用拼音-汉字对照语料微调更新完成的深度学习模型,在该拼音-汉字对照语料中,每条拼音文本有其对应的汉字文本;拼音按照通用盲文标调标准转换为省写音调的拼音,包括音节和声调,声调标记为:1表示阴平,2表示阳平,3表示上声,4表示去声,无音调表示轻声或声调被省写;采用一个盲文分词系统根据汉字和拼音信息自动得到盲文分词信息,得到标记分词信息的该拼音-汉字对照语料。
22.所述的通用盲文到汉字的转换系统,其中该分词标记序列基于bmes四位序列标注表示该拼音音节序列中各拼音音节的分词信息,其中b表示拼音音节对应盲文词的首位置;m表示拼音音节对应盲文词的中间位置;e表示拼音音节对应盲文词的末尾位置;s表示拼音音节对应一个单独的字。
23.所述的通用盲文到汉字的转换系统,其中该局部语义特征提取层包括三种不同高度的卷积核,高度分别为1、3和5,每种高度分别有两个卷积核,每个卷积核通过对该拼音嵌入向量做卷积运算得到特征向量,最终得到融合6个特征空间的特征向量,得到局部语义信息;该全局语义特征提取层采用双向门控循环单元网络实现该上下文语义信息的抓取。
24.本发明还提出了一种存储介质,用于存储执行如所述任意一种通用盲文到汉字的转换方法的程序。
25.本发明还提出了一种客户端,用于所述的任意一种通用盲文到汉字的转换系统。
26.由以上方案可知,本发明的优点在于:
27.通过采用本发明提出的通用盲文到汉字的转换方法和系统,可以有效利用盲文的分词信息,采用通用盲文-汉字对照语料和标记盲文分词信息的拼音-汉字对照语料即可训练基于深度神经网络的通用盲文-汉字转换模型,实现高准确率的通用盲文-汉字转换。该技术有利于消除普通人从事盲人教育的屏障,促进盲人教育的发展,方便盲人和普通人交流,进而使得盲人更好的融入信息化社会,同时在盲文出版、盲用终端等领域具有重要应用。
附图说明
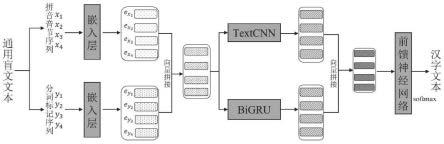
28.图1为总体流程图;
29.图2为模型结构图;
30.图3为textcnn结构图;
31.图4为bigru结构图;
32.图5为textcnn和bigru的输出拼接图;
33.图6为标记了盲文分词信息的拼音-汉字语料示例图。
具体实施方式
34.本发明提出一种通用盲文到汉字的转换模型,该模型结构包括拼音音节嵌入与分词信息嵌入拼接为一个总体的嵌入向量,以及局部语义特征提取层(ctextcnn)和全局语义特征提取层(bigru)共享嵌入层结合的特征提取模块。通用盲文到汉字的转换方法,主要步骤包括:
35.1.构建深度学习模型,并能有效利用通用盲文的分词信息。优选地,可以使用textcnn+bigru的网络结构,textcnn负责局部语义特征提取,bigru负责抓取全局语义信息,然后拼接相应的输出送入前馈神经网络预测得到汉字文本。
36.2.采用通用盲文-汉字对照语料训练步骤1构建的深度学习模型。
37.在具体训练模型时,将通用盲文-汉字对照语料整理成的数据集分为若干批(batch),每批包含若干条数据,每条数据都同时包含有:拼音音节序列、分词标记序列、拼音对应的汉字文本。依次用每批数据训练,在训练时,用该批数据的拼音和分词标记作为输入,分别经过嵌入层后进行拼接,得到包含分词信息的拼音嵌入序列,送入模型训练后生成的预测汉字与汉字文本通过交叉熵计算损失函数,然后通过反向传播算法更新整个模型的参数。
38.优选地,采用拼音-汉字对照语料微调步骤2训练完成的模型。在具体训练模型时,采用一个盲文分词系统根据汉字和拼音信息自动得到盲文分词信息,将标记了盲文分词信息的拼音-汉字对照语料分为若干批(batch),每批包含若干条数据,每条数据都同时包含有:拼音、拼音对应的盲文分词标记、拼音对应的汉字文本。依次用每批数据训练,训练方式与步骤2相同。
39.上述拼音-汉字对照语料来自非盲文领域,例如采用已有的各种汉字-拼音语料,可弥补盲文语料的不足;原始的拼音-汉字对照语料由于来自非盲文领域,因此没有盲文分词,需要采用一个盲文分词系统根据汉字和拼音信息自动得到盲文分词信息;自动得到的盲文分词信息虽然准确率较高,但仍然可能含有少量错误,与完全正确的盲文-汉字对照语料及从该语料得到的包含拼音和盲文分词信息的语料有一定差异,因此拼音-汉字对照语料仅能作为微调使用,不作为(或转换为)盲文-汉字对照语料参与前一步骤的模型训练。
40.训练好的模型进行通用盲文到汉字的自动转换。
41.模型训练好后,对于一条输入的通用盲文ascii码,转换为汉语拼音和分词标记,然后将其输入模型,进而得到相应的预测结果。
42.为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
43.为了使本发明的目的、技术方案及优点更加清楚,以下结合附图及实施例,对本发明的一种通用盲文到汉字的转换方法和系统进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
44.本发明提出了基于深度学习的通用盲文到汉字的转换方法和系统。采用深度学习的方法,将输入的通用盲文文本转换为拼音音节序列和分词标记序列,通过深度学习模型进行语义特征信息提取,然后得到其对应的汉字。其流程如图1所示:
45.具体步骤包括:
46.1.构建一个深度学习模型,并能有效利用盲文的分词信息。
47.在一个实施例中,由通用盲文文本生成拼音音节序列和分词标记序列,然后经由嵌入层向量化后拼接得到融合盲文分词信息的拼音嵌入向量,分别输入textcnn和bigru中,其中textcnn重点关注局部语义信息,bigru重点关注具有时序关系的上下文语义信息,然后将两者生成的高级语义表示进行拼接后输入前馈神经网络得到汉字文本输出,两个分支共享嵌入层和前馈神经网络(全连接层)。模型结构如图2所示。
48.2.采用通用盲文-汉字对照语料训练步骤1构建的深度学习模型。
49.(1)通用盲文到拼音转换
50.通用盲文ascii码中既有盲文的分词信息,也有盲文对应的每个汉字的读音信息,这种读音信息可以通过长优先匹配方法转化为汉语拼音和分词信息。通用盲文到拼音的转换主要基于规则映射的方法。除少量盲文符号串混淆情况外,盲文符号串基本一一对应相应的拼音音节或标点符号。盲文符号串混淆情况主要有以下几点:
51.a)通用盲文声调省写导致的盲文符号串相同,比如声调省写规则规定:声母为m的音节,省写阳平符号,因此拼音“mo2”和“mo”的盲文符号串相同;音节o1、o2、o3、o4的声调符号省写,音节e1、e2、e3、e4的声调符号不省写,轻声“e”与省写声调的“o”存在盲文符号串相同但音节不同的混淆情况。
52.b)相同的盲文符号串表示不同的拼音音节或标点符号,比如音节“yo”和“you”、“yo1”和“you1”,双引号、单引号、方括号等成对的标点符号,冒号和连接号,以及音节“eng”和阿拉伯数字的标志符号“#”等。
53.对以上混淆的盲文符号串进行预处理,没有歧义的盲文符号串按照规则映射的方式转为对应的拼音音节或标点符号,对于存在歧义但对应拼音不同的盲文符号串,将盲文符号串转为出现频率高的拼音音节,比如音节“you”和“yo”对应的盲文符号串统一转为“you”,轻声“e”与省写音调的“o”对应的盲文符号串统一转为“o”等;对于存在歧义但对应标点符号不同的盲文符号串,按照不同的书写格式及句中位置更改为对应符号,如冒号后空方以区分连接号,成对标点符号以出现的先后顺序更改为正确的标点符号,该方式能减少成对标点符号的歧义问题。
54.(2)融合盲文分词信息的音节嵌入
55.使用bmes四位序列标注法表示盲文的分词信息。b,即begin,表示盲文词的首位置;m,即middle,表示盲文词的中间位置,即不是其所在盲文词的第一个字,也不是最后一个字;e,即end,表示盲文词的末尾位置;s,即single,表示一个单独的字。在一个实施例中,如表1所示,其中句号作为单独的字标记为“s”,是因为盲文的书写规则规定句号前后均不空方,若将句号作为盲文词的一部分标注分词信息则割裂了原本盲文词的关系,对于句子的语义理解具有反作用,因此在生成分词信息时将标点符号作为单独的字标记为“s”。
56.表1盲文分词对照信息
[0057][0058]
(3)基于textcnn的局部语义特征提取
[0059]
融合分词信息的拼音嵌入作为textcnn的输入,经过三种不同高度的卷积核做卷
积运算后,得到句子的语义表示。一个实施例如图3所示,图3中包含三种不同高度的卷积核,高度分别为1、3和5,每种高度分别有两个卷积核,每个卷积核通过对句子嵌入做卷积运算得到特征向量,最终得到融合6个特征空间的特征向量,即句子的语义表示。
[0060]
(3)基于bigru的全局语义特征提取
[0061]
在通用盲文到汉字的转换任务中,每个句子是具有时序关系的拼音序列,预测当前位置的拼音对应的汉字不仅需要根据前文来判断,也需要根据后文即上下文信息进行判断,因此采用双向门控循环单元网络(bigru)实现全局语义信息的抓取。一个实施例如图4所示。
[0062]
将textcnn和bigru的输出进行拼接得到最终的语义向量并输入前馈神经网络中,其输出通过softmax函数得到汉字文本。一个实施例如图5所示,textcnn每个句子的输出维度为n
×
k,bigru每个句子的输出维度为n
×
m,最终得到的句子向量维度大小为n
×
(m+k)。
[0063]
在具体训练模型时,将通用盲文-汉字对照语料整理成的数据集分为若干批(batch),每批包含若干条数据,每条数据都同时包含有:拼音音节序列、分词标记序列、拼音对应的汉字文本。依次用每批数据训练,在训练时,用该批数据的拼音和分词标记作为输入,分别经过嵌入层后进行拼接,得到包含分词信息的拼音嵌入,送入模型训练后生成的预测汉字与汉字文本通过交叉熵计算损失函数,然后通过反向传播算法更新整个模型的参数。
[0064]
3.可选地,采用拼音-汉字对照语料微调步骤2训练完成的模型。
[0065]
在该语料中,每条拼音文本会有其对应的汉字文本。拼音是按照通用盲文标调标准进行省写音调的拼音,包括音节和声调,声调标记为:“1”表示一声(阴平),“2”表示二声(阳平),“3”表示三声(上声),“4”表示四声(去声),无音调表示轻声或声调被省写。采用一个盲文分词系统根据汉字和拼音信息自动得到盲文分词信息。
[0066]
作为模型输入的标记了盲文分词信息的汉字语料,每条数据分别是一条拼音文本,其每个拼音对应的汉字文本,以及相应的分词信息。图6所示即为一条标记了盲文分词信息的拼音-汉字语料示例。
[0067]
在具体训练模型时,将拼音-汉字对照语料分为若干批(batch),每批包含若干条数据,每条数据都同时包含有:拼音、拼音对应的盲文分词标记、拼音对应的汉字文本。依次用每批数据训练,训练方式与步骤2相同。
[0068]
4.采用步骤2或者步骤3训练好的模型进行通用盲文到汉字的自动转换。
[0069]
模型训练好后,对于一条输入的通用盲文ascii码,转换为汉语拼音和分词信息,然后将其输入模型,进而得到相应的预测结果。在一个实施例中,输入的通用盲文ascii码为“gv'0a zu'go1"2”,经过转换后得到的分词信息为“b e b e s”,拼音为“gan3 en1 zu3 guo2。”,预测得到的汉字文本为“感恩祖国。”。
[0070]
同时基于分词信息,可得到含有分词信息的汉字文本,方法为:首先,将汉字文本根据分词标记分词,按位置对应,将“b”和“e”之间的汉字连为一个词,将“s”标记对应的汉字单独成词。如上述实施例中,可得到汉字文本“感恩祖国。”。
[0071]
以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
[0072]
本发明还提出了一种通用盲文到汉字的转换系统,其中包括:
[0073]
模型构建模块,用于构建包括局部语义特征提取层和全局语义特征提取层的深度学习模型,获取待转换的通用盲文文本,且该局部语义特征提取层和该全局语义特征提取层共享嵌入层和全连接层;
[0074]
预处理模块,用于由该通用盲文文本生成拼音音节序列和分词标记序列,经由嵌入层向量化后拼接得到融合盲文分词信息的拼音嵌入向量,分别输入该局部语义特征提取层和该全局语义特征提取层;
[0075]
特征拼接模块,用于该局部语义特征提取层提取该拼音嵌入向量的局部语义信息,该全局语义特征提取层提取该拼音嵌入向量中具有时序关系的上下文语义信息,将该局部语义信息和该上下文语义信息拼接后输入全连接层得到该通用盲文文本对应的汉字文本。
[0076]
所述的通用盲文到汉字的转换系统,其中该深度学习模型的训练过程为将通用盲文-汉字对照语料分为多批数据,每批数据包括多条数据,每条数据均包含:拼音音节序列、分词标记序列、拼音对应的汉字文本;以该批数据的拼音音节序列和分词标记序列作为输入,得到该深度学习模型的预测汉字文本,根据该预测汉字文本和该拼音对应的汉字文本构建损失函数,通过反向传播更新该深度学习模型;
[0077]
采用拼音-汉字对照语料微调更新完成的深度学习模型,在该拼音-汉字对照语料中,每条拼音文本有其对应的汉字文本;拼音按照通用盲文标调标准转换为省写音调的拼音,包括音节和声调,声调标记为:1表示阴平,2表示阳平,3表示上声,4表示去声,无音调表示轻声或声调被省写;采用一个盲文分词系统根据汉字和拼音信息自动得到盲文分词信息,得到标记分词信息的该拼音-汉字对照语料。
[0078]
所述的通用盲文到汉字的转换系统,其中该分词标记序列基于bmes四位序列标注表示该拼音音节序列中各拼音音节的分词信息,其中b表示拼音音节对应盲文词的首位置;m表示拼音音节对应盲文词的中间位置;e表示拼音音节对应盲文词的末尾位置;s表示拼音音节对应一个单独的字。
[0079]
所述的通用盲文到汉字的转换系统,其中该局部语义特征提取层包括三种不同高度的卷积核,高度分别为1、3和5,每种高度分别有两个卷积核,每个卷积核通过对该拼音嵌入向量做卷积运算得到特征向量,最终得到融合6个特征空间的特征向量,得到局部语义信息;该全局语义特征提取层采用双向门控循环单元网络实现该上下文语义信息的抓取。
[0080]
本发明还提出了一种存储介质,用于存储执行如所述任意一种通用盲文到汉字的转换方法的程序。
[0081]
本发明还提出了一种客户端,用于所述的任意一种通用盲文到汉字的转换系统。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1