一种基于ViT网络的小样本遥感图像分类方法、介质及设备
一种基于vit网络的小样本遥感图像分类方法、介质及设备
技术领域
1.本发明涉及图像分类技术领域,尤其涉及一种基于vit网络的小样本遥感图像分类方法、介质及设备。
背景技术:
2.传统的卷积神经网络具有空间感知偏差,因此卷积神经网络在计算机视觉任务上优势明显,其在少量参数的情况下依旧保持较好效果,但是卷积神经网络的空间感知偏差是局部的,以往的结构中通常使用注意力(attention)机制实现全局感知。例如通过增加用于图像分类的特征图或通过使用自注意力来进一步处理cnn的输出,例如用于对象检测、视频处理、图像分类。
3.而transformers编码器一般是用于自然语言处理领域,transformers之类的工作采用可扩展的近似值来吸引全局的自注意力,以适用于图像。
4.此外,transformers编码器缺乏上述提及的空间感知,例如平移不变性和局部性。故而在数据量较少的情况下难以概括训练集的所有特征信息。而vit将图像分割为非重叠序列进行特征学习,取得了较好的效果。
5.但囿于极大的参数量,导致其在实际训练中举步维艰。因此,一种用于图像分类领域的面向小样本数据的基于vit网络构建的发明就显得很有必要。
技术实现要素:
6.针对背景技术中存在的问题,本发明提供一种基于vit(vision transformers)网络的小样本遥感图像分类方法,目的在于利用多模态特征融合技术以及多头自注意力机制解决vit网络模型参数冗杂且训练时间过长难以落地的问题。
7.一种基于vit网络的小样本遥感图像分类方法,包括以下步骤:
8.步骤1:采用用于地标识别和图像恢复实验的数据集作为训练集,并对训练集中的图像数据进行预处理;
9.步骤2:将经过预处理的图像数据输入到transformers编码器中的多模态特征融合机制,并在多模态特征融合中将步骤1中经过预处理的图像数据通过多层感知机进行处理,再将多层感知机处理后的图像数据进行concat操作,concat操作完成后,对图像数据进行一次pca(主成分分析法)降维处理,使所有的图像数据的维度保持一致;
10.步骤3:将经过步骤2处理的图像数据送入多头自注意机制处理,得到特征信息;
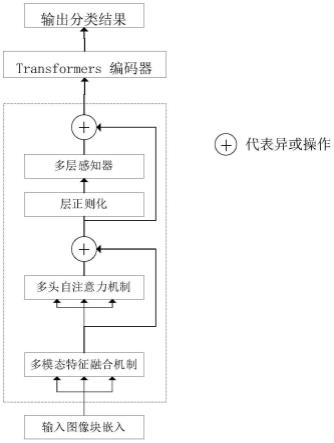
11.步骤4:基于步骤3中的特征信息得到图像数据的分类结果,输出图像数据的分类结果。
12.本发明基于vit的小样本sar(synthetic aperture radar)图像分类方法将多模态特征融合机制引入到transformers编码器中,通过将图像特征进行融合,解决了因为数据集小而导致模型获取信息量变少的情况。此外,由于序列模型难以对层次信息进行有效表达,因此将多头注意力机制引入到transformers编码器中,在可以并行计算的同时,还提
高了对长距离依赖关系的捕捉能力。
13.优选的,步骤1中所述的图像数据的预处理包括以下步骤:
14.对图像数据的维度进行变换操作,并将进行变换操作后的图像数据进行线性映射,将位置嵌入添加到图像块嵌入中,保留位置信息;嵌入向量的结果序列作为所述transformers编码器的输入。
15.优选的,所述transformers编码器由多头自注意机制、多模态特征融合机制以及多层感知机模块的层组成;在每个多模态特征融合机制以及多层感知机模块之前应用layernorm,之后应用残差连接;其中多层感知机模块包含具有gelu非线性的两全连接层。
16.优选的,所述多模态特征融合机制将图像嵌入图像块嵌入分别输入到不同的多层感知机中,再对图像块嵌入进行特征融合操作;所述特征融合操作为将下层输入的三个向量特征进行concat操作,再将三个向量通过多层感知机映射成同一个维度相加再还原,得到还原后的三个向量维度。
17.优选的,所述步骤3中将还原后的三个向量维度包含在并行的自注意力层中,每个向量经过多层感知机模块输入到自注意力层,再通过concat操作将三个向量连接在一起,经过最后一层多层感知机模块的网络得到特征信息。
18.优选的,所述分类结果通过在预训练时具有一个隐含层的mlp(多层感知机)以及在微调时通过一个线性层的mlp来实现。
19.一种存储介质,用于存储计算机指令,其中计算机指令用于使所述计算机执行上述任意一种所述的方法。
20.一种电子设备,包括至少一个处理器,以及与至少一个处理器通信连接的存储器;其中,所述存储器中存储有能被至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述任意一种所述的方法。
21.本发明的有益效果包括:
22.1.本发明基于vit的小样本sar图像分类方法将多模态特征融合机制引入到transformers编码器中,通过将图像特征进行融合,解决了因为数据集小而导致模型获取信息量变少的情况。此外,由于序列模型难以对层次信息进行有效表达,因此将多头注意力机制引入到transformers编码器中,在可以并行计算的同时,还提高了对长距离依赖关系的捕捉能力。
23.2.本发明在图像分类效果以及相关指标方面差强人意的前提下,其训练时长和模型规模均小于现有的基于vit的sar图像分类方法。
24.3.本发明与基线算法相比,在不过于降低图像分类精度的前提下,保证分类结果可接受的同时,将模型训练时间缩短至基线算法的一半。
附图说明
25.图1为本发明的流程示意图。
26.图2为本发明的整体网络结构示意图。
具体实施方式
27.为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例
中附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本技术实施例的组件可以各种不同的配置来布置和设计。因此,以下对在附图中提供的本技术的实施例的详细描述并非旨在限制要求保护的本技术的范围,而是仅仅表示本技术的选定实施例。基于本技术的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本技术保护的范围。
28.下面结合附图1和附图2对本发明的实施例作进一步的详细说明:
29.一种基于vit网络的小样本遥感图像分类方法,包括以下步骤:
30.步骤1:采用用于地标识别和图像恢复实验的数据集(google landmarks dataset v2)作为训练集,并对训练集中的图像数据进行预处理;
31.步骤1中所述的图像数据的预处理包括以下步骤:
32.对图像数据的维度进行变换操作,并将进行变换操作后的图像数据进行线性映射,将位置嵌入添加到图像块嵌入中,保留位置信息;嵌入向量的结果序列作为所述transformers编码器的输入。
33.具体如下所述:
34.表1 google landmarks dataset v2数据集划分情况表
[0035] 训练集验证集测试集总计图像数目(张)448,695124,261206,209779,165
[0036]
将一张尺寸为h
×w×
c的图像经过reshape操作变换为二维图块,其中h代表图像高度,w代表图像宽度,c代表图像通道数;尺寸为(n
×
(p2·
c)),其中,n代表样本数量(即输入图像数量),p2作为图块大小,一共得到数量为的图块。本发明为提高模型对图像的分类精度,将一张输入图像分为9个图像块,此时,需要将得到的9个图像块进行一维化操作。由于transformers在所有图层上的恒定隐矢量大小固定,我们需要将这些一维化后的图像块进行线性映射,映射结果与恒定隐矢量相匹配,且将此映射的输出结果称为图像块嵌入。将位置嵌入添加至图像块嵌入中,即将每一个图像块位置信息进行保留。嵌入向量的结果序列用作编码器的输入。
[0037]
步骤2:将经过预处理的图像数据输入到transformers编码器中的多模态特征融合机制,并在多模态特征融合中将步骤1中经过预处理的图像数据通过多层感知机进行处理,再将多层感知机处理后的图像数据进行concat操作,concat操作完成后,对图像数据进行一次pca降维处理,使所有的图像数据的维度保持一致;
[0038]
所述transformers编码器由多头自注意机制、多模态特征融合机制以及多层感知机模块的层组成;在每个块之前应用layernorm,每个块之后应用残差连接;其中多层感知机模块包含具有gelu非线性的两全连接层。
[0039]
所述多模态特征融合机制将图像嵌入图像块嵌入分别输入到不同的多层感知机中,再对图像块嵌入进行特征融合操作;所述特征融合操作为将下层输入的三个向量特征进行concat操作,再将三个向量通过多层感知机映射成同一个维度相加再还原,得到还原后的三个向量维度。
[0040]
步骤3:将经过步骤2处理的图像数据送入多头自注意机制处理,得到特征信息;
[0041]
所述步骤3中将还原后的三个向量维度包含在并行的自注意力层中,每个向量经过多层感知机模块输入到自注意力层,再通过concat操作将三个向量连接在一起,经过最后一层多层感知机模块的网络得到特征信息。
[0042]
步骤4:基于步骤3中的特征信息得到图像数据的分类结果,输出图像数据的分类结果。
[0043]
所述分类结果通过在预训练时具有一个隐含层的mlp以及在微调时通过一个线性层的mlp来实现。
[0044]
本发明基于vit的小样本sar图像分类方法将多模态特征融合机制引入到transformers编码器中,通过将图像特征进行融合,解决了因为数据集小而导致模型获取信息量变少的情况。此外,由于序列模型难以对层次信息进行有效表达,因此将多头注意力机制引入到transformers编码器中,在可以并行计算的同时,还提高了对长距离依赖关系的捕捉能力。
[0045]
一种存储介质,用于存储计算机指令,其中计算机指令用于使所述计算机执行上述任意一种所述的方法。
[0046]
一种电子设备,包括至少一个处理器,以及与至少一个处理器通信连接的存储器;其中,所述存储器中存储有能被至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述任意一种所述的方法。
[0047]
为帮助本领域的技术人员理解本发明,本实施例的做进一步的说明:
[0048]
本发明将vit作为基线模型,首先针对图中的整体网络结构进行说明:
[0049]
由于传统的transformers编码器的输入是一维的嵌入,而图像是二维的,因此将输入图像进行reshape操作,具体操作如下:
[0050]
将图像表示为[n,c,h,w],其中h代表图像高度,w代表图像宽度,c代表图像通道数,n代表样本数量。其经过维度变换后被表示为:
[0051]
[n
×
(p2·
c)]
[0052]
其中p2作为图块大小,故而一共得到图块数量为:
[0053][0054]
经过线性神经网络构造保留一个序列的输入,每一个patch都需要保持与原图对应的编号,保留空间与未知的信息。如下所示,其中,x
class
代表可嵌入的补丁序列,e代表在之前设定的图块的二维空间大小[d
×
(p2·
c)],e
pos
代表有n+1个样本下的恒定隐矢量d相同的维度,代表每一个被有编号的嵌入:
[0055][0056]
接下来这些被编号的图像块嵌入将输入到transformers编码器的多模态特征融合机制中,该部分的核心公式表示如下:
[0057]
xf=vf{ti(xi)}i∈c
[0058]
其中,xi是需要进行融合的特征分布,ti是进行下采样或者上采样操作的方法,使得scale保持一致,φf是对scale一致的特征图进行concat操作或者element-wisesum(按位加)操作,使得特征图scale相同。
[0059]
之后,需要对其进行多模态特征融合:
[0060]
input
l-1
=mlp(concat(mlp(layernorm(i1))+
…
mlp(layernorm(i9))))
[0061]
经过特征融合处理后,需要利用多头自注意力机制弥补transformers编码器缺乏全局感知的缺点,公式可以被表示为:
[0062]
input
′
l
=msa(layernorm(input
l-1
))+input
l-1
[0063]
其中,msa代表多头自注意,ln代表layernorm,即层正则化,input
l-1
表示多模态特征融合机制的输出。
[0064]
经过一层mlp,其中mlp包含了具有gelu非线性的两全连接层:
[0065]
input
l
=mlp(layernorm(input
′
l
))+input
′
l
[0066]
input
′
l
表示图像块嵌入在处理后的输出,本发明与基线模型的实验结果数据对比如下表2所示:
[0067]
模型准确率模型参数量训练时长(h)vit96.40%22855952106本发明92.07%261710056
[0068]
以上所述实施例仅表达了本技术的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本技术保护范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术技术方案构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1