基于课程学习的无监督域自适应遥感图像语义分割方法
1.本发明涉及图像分割技术领域,具体而言,涉及一种基于课程学习的无监督域自适应遥感图像语义分割方法。
背景技术:
2.语义分割即对图像中每一个像素点进行分类,确定每个点的类别,从而进行区域划分;语义分割的目的是预测像素级的语义标签。随着遥感领域的发展,遥感卫星可以获取到大量的遥感图像数据,对遥感图像进行有效的语义分割可以对地物类别进行像素级分类,在路网提取、土地覆盖等方面都有广泛的应用,在更新基础地理数据、自主农业、智能交通、城市规划和可持续发展等方面有重要的意义,具有广泛的实用价值;但是遥感图像语义分割存在两个问题:分辨率高尺度大,标注需要花费巨大的人力和时间;而且不同地区地形地貌和建筑风格等方面存在较大的差异,将训练好的模型应用到不同地理空间区域时其分割效果往往不尽人意;例如:在城市和农村地区,土地覆盖的表现形式在类别分布、物体尺度和像元光谱上差异很大。
3.无监督域自适应方法可以较好的解决上述问题,尽可能利用有标注的源域数据,在不针对目标数据集进行重新标注的情况下,在不可见的目标数据集上取得较好的语义分割结果。无监督域自适应是假定所有的测试数据都没有标注,无监督域自适应的目标是即使在训练图像和测试图像之间存在较大的领域差异时也能生成高质量的分割,现有技术中,为了提高卷积神经网络(cnn)的泛化能力,常用方法之包括利用伽马校正、随机对比度变化等多种数据增强技术来丰富训练数据;此外,基于对抗的特征对齐方法采用生成对抗网络(gan)来尽可能缩小源域和目标域特征表示之间的距离,其中鉴别器可以在多个层次上使用。另外,基于图像风格迁移的方法则是在保留图像内容的条件下,将源域图像的风格变换到目标域,从而利用源域图像的标签进行训练,这类方法也大多采用生成对抗网络实现。
4.现有技术中也有采用自步训练的方式训练目标域数据生成伪标签,但是,由于自步训练过程中会不断更新训练模型,而目标域的验证集不可见,从而无法对更新的训练模型进行筛选,导致训练过程不稳定,进而导致生成的伪标签噪声大。
技术实现要素:
5.本发明解决的问题是如何减少伪标签在训练过程中的噪声影响,使得训练过程稳定,实现高精度的语义分割。
6.为解决上述问题,本发明提供基于课程学习的无监督域自适应遥感图像语义分割方法,其特征在于,包括:
7.步骤1、采集具有标签的源域数据ds={xs,ys}和无标签的目标域数据 d
t
={x
t
};其中,xs为源域图像,ys为对应源域图像xs的标签;x
t
是目标域图像;源域数据ds和目标域数据d
t
共享标签空间;
8.步骤2、构建交叉熵损失函数,根据交叉熵损失函数在源域数据ds上预训练教师模型m
t
,并保留预训练的权重参数;
9.步骤3、构建与教师模型m
t
相同的学生模型ms,并基于教师模型m
t
和预训练的权重参数初始化学生模型ms;
10.步骤4、使用教师模型m
t
对目标域数据d
t
进行预测,预测得到每个目标域像素属于某类别的概率的置信度图,并根据置信图统计每个类别的像素数目及占比;
11.步骤5、采用类别平衡的方式对占比ki的目标域像素数目进行筛选,得到目标域伪标签
12.步骤6、将源域数据和将占比ki的目标域数据及其伪标签采用交叉熵损失训练学生模型,计算并输出交叉熵损失曲线,根据交叉熵损失曲线判断交叉熵损失训练是否趋于稳定,若是,则进入步骤7,否则,继续通过源域数据和将占比ki的目标域数据训练学生模型;
13.步骤7、ki=ki+m,m为使得ki呈线性递增的常数;判断ki是否小于等于k;若是,则返回步骤5;若否,则进入步骤8;
14.步骤8、将目标域数据d
t
输入保存的学生模型ms进行测试,提取图像的特征,采用平均交并比miou作为评价指标评价训练后的学生模型ms,计算 miou并将像素类别进行可视化,得到语义分割的结果。
15.本发明的有益效果是:利用课程学习思想,通过线性增长的占比ki的目标域像素数目和类别平衡的伪标签筛选策略,使得教师模型m
t
以不同置信阈值生成伪标签,结合源域数据ds预训练的教师模型m
t
直接应用于置信度阈值的计算和伪标签的生成,使得训练过程更稳定;同时,训练过程中伪标签的数量呈线性增加,从而动态修改实现对目标域数据生成由易得到难的伪标签,实现稳定有效的训练。
16.作为优选,所述步骤2中的交叉熵损失函数为:
[0017][0018]
式中,是置信度图,是源域图像的标签;h和w分别是图像的长和宽,c为类别数目。
[0019]
作为优选,所述步骤4中将占比ki的目标域像素数目输入教师模型m
t
中,生成置信度图,并根据置信图统计每个类别的像素数目及占比σc:
[0020][0021]
σc=nc/n
t
[0022]
nc为目标域数据中第c个类别的像素数,n
t
是目标域数据的总像素数作为优选,所述步骤5中具体包括:
[0023]
步骤501、对每个类别内按照置信度从高到低排序,并选择c类中置信度最高的前nc个像素作为伪标签的样本;第nc个像素的置信度即为置信阈值τc;
[0024]
步骤502、选择对应类别c中且置信度高于该类置信阈值τc的像素进行标注,忽略低于该类置信阈值τc像素,得到目标域伪标签
[0025][0026]
其中,为目标域数据中i行j列的像素预测置信度,i=1,2,
…
,h,j= 1,2,
…
w。
[0027]
作为优选,所述步骤6中的交叉熵损失训练函数为:
[0028][0029]
l=ls+λ*l
t
[0030]
式中,λ为常数,用于控制目标域的损失占比。
[0031]
作为优选,所述步骤8中平均交并比miou为:
[0032][0033]
式中,n为目标域标签类别的个数,iiou表示第i个类别的交并比,i=1,2,
…
,n。
附图说明
[0034]
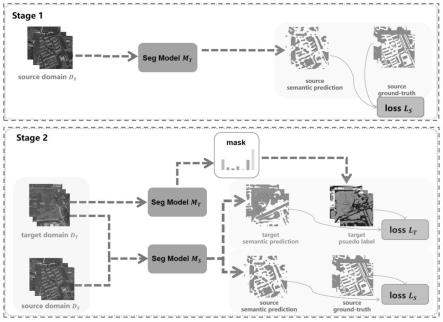
图1为本发明的语义分割框架示意图;
[0035]
图2为本发明流程伪代码。
具体实施方式
[0036]
为使本发明的上述目的、特征和优点能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
[0037]
如图1-2所示的基于课程学习的无监督域自适应遥感图像语义分割方法,包括:
[0038]
步骤1、采集具有标签的源域数据ds={xs,ys}和无标签的目标域数据 d
t
={x
t
};其中,xs为源域图像,ys为对应源域图像xs的标签;x
t
是目标域图像;源域数据ds和目标域数据d
t
共享标签空间;
[0039]
本具体实施例中的源域数据ds和目标域数据d
t
内的数据集包含城市和乡村两个域,其中,城市域数据集由1156幅训练图像、677幅验证图像和 820幅测试图像组成,乡村域数据集由1366幅训练图像、992幅验证图像和976幅测试图像组成;为了扩充数据集数据量,本具体实施例还对数据集进行了翻转变换、随机旋转变换、上下左右平移变换、随机裁切变换等增广操作;并且,本具体实施中的目标域数据d
t
包括用于训练的训练集数据和用于测试评价语义分割精度的学生模型的测试集数据;本具体实施例每次从数据集中随机抽取8个源域图像和8个目标域图像;
[0040]
步骤2、构建交叉熵损失函数,根据交叉熵损失函数在源域数据ds上预训练教师模型m
t
,并保留预训练的权重参数;交叉熵损失函数为:
[0041][0042]
式中,是置信度图,是源域图像的标签;h和w分别是图像的长和宽,c为类别数目;
[0043]
关于如何使用交叉熵损失函数在源域数据ds上预训练教师模型m
t
为现有技术,此处不做过多赘述;
[0044]
步骤3、构建与教师模型m
t
相同的学生模型ms,并基于教师模型m
t
和预训练的权重参数初始化学生模型ms;本具体实施例使用resnet-50作为骨干,在imagenet上进行预训练;
[0045]
步骤4、使用教师模型m
t
对目标域数据d
t
进行预测,预测得到每个目标域像素属于某类别的概率的置信度图,并根据置信图统计每个类别的像素数目及占比σc:
[0046][0047]
σc=nc/n
t
[0048]
nc为目标域数据中第c个类别的像素数,n
t
是目标域数据的总像素数;
[0049]
步骤5、采用类别平衡的方式对占比ki的目标域像素数目进行筛选,得到目标域伪标签具体包括:
[0050]
步骤501、对每个类别内按照置信度从高到低排序,并选择c类中置信度最高的前nc个像素作为伪标签的样本;第nc个像素的置信度即为置信阈值τc;
[0051]
步骤502、选择对应类别c中且置信度高于该类置信阈值τc的像素进行标注,忽略低于该类置信阈值τc像素,得到目标域伪标签
[0052][0053]
其中,为目标域数据中i行j列的像素预测置信度,i=1,2,
…
,h,j= 1,2,
…
w;
[0054]
步骤6、将源域数据和将占比ki的目标域数据及其伪标签采用交叉熵损失训练学生模型,计算并输出交叉熵损失曲线,根据交叉熵损失曲线判断交叉熵损失训练是否趋于稳定,若是,则进入步骤7,否则,继续通过源域数据和将占比ki的目标域数据训练学生模型;本具体实施例中计算交叉熵损失曲线为现有技术,不做过多赘述;根据交叉熵损失曲线判断交叉熵损失训练是否趋于稳定的判断方法,本具体实施例采用将计算的交叉上损失曲线进行傅里叶分析,得到频率-振幅曲线,然后将得到的频率-振幅曲线与标准参考曲线进行比例,以判断交叉熵损失训练是否稳定,具体操作方式为现有技术,此处不做过多赘述;而关于交叉熵损失训练函数为:
[0055]
[0056]
l=ls+λ*l
t
[0057]
式中,λ为常数,用于控制目标域的损失占比;
[0058]
步骤7、ki=ki+m,m为使得ki呈线性递增的常数;判断ki是否小于等于k;若是,则返回步骤5;若否,则进入步骤8;
[0059]
步骤8、将目标域数据d
t
中的测试集数据输入保存的学生模型ms进行测试,提取图像的特征,采用平均交并比miou作为评价指标评价训练后的学生模型ms,计算miou并将像素类别进行可视化,得到语义分割的结果;平均交并比miou的公式为:
[0060][0061]
式中,n为目标域标签类别的个数,iiou表示第i
[0062]
个类别的交并比,i=1,2,
…
,n。
[0063]
虽然本公开披露如上,但本公开的保护范围并非仅限于此。本领域技术人员,在不脱离本公开的精神和范围的前提下,可进行各种变更与修改,这些变更与修改均将落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1