基于区块链和联邦学习的软件行为智能管控方法
1.本发明属于互联网技术领域,特别涉及基于区块链和联邦学习的软件行为智能管控方法。
背景技术:
2.目前,部分软件提供商对其开发的应用软件捆绑了大量的广告及信息类弹窗,这种行为损害了软件用户的系统操作体验。软件弹窗的出现会导致干扰用户视线、影响用户操作、降低计算机使用效率和网速等问题,这极大地影响了用户体验。虽然目前市面上出现一些能够进行弹窗拦截的安全软件,例如专利号cn202010503928.7公开的弹窗拦截方法,通过目标钩子函数监控到弹窗事件,然后根据该弹窗事件对应的进程获取该弹窗事件对应弹窗的至少一个属性特征,并根据属性特征确定所述弹窗是否为广告弹窗,若所述弹窗为广告弹窗,则拒绝响应该弹窗事件。该方法能够实现在显示广告弹窗之前进行拦截,提高了用户体验,但该方法依赖一定的规则来判断软件的广告弹窗行为,由于软件弹窗的各种特征不断在变化,因此这种方式存在漏检或误判的风险。
3.显然现有方案中,弹窗的控制主要依赖于用户的规则配置,需要用户手动配置弹窗的控制选项,并且没有建立多用户间的软件弹窗行为信息共享机制,无法借助用户群体的软件喜好实现弹窗行为的智能管控。
4.在软件行为的检测与分类方面,传统的机器学习算法和深度学习算法能够通过大量的数据来学习相应特征,最终实现对软件行为准确分类。然而由于缺乏数量大且质量高的软件行为训练数据,软件行为检测与分类研究面临数据孤岛的现状,导致在进行机器学习模型训练时无法有效利用各参与方的软件行为数据,阻碍了算法模型效果的提升,因此需要探索与设计软件行为感知方法采集各类软件弹窗的用户界面内容和进程等数据,从而为软件行为的分类与管控提供数据支撑。
5.此外,由于采集到的软件行为数据如软件窗口截图中会包含用户的个人偏好信息、窗口进程会暴露用户使用软件的行为,这些数据涉及用户隐私,此外这些数据分散在各个节点,单节点使用有限的数据训练模型效果具有局限性,集中所有节点的数据集中训练又会导致泄露隐私,所以如何在保护数据隐私的前提下打破数据孤岛,提升模型的准确率是需要解决的关键问题。
技术实现要素:
6.针对现有技术存在的不足,本发明提供一种基于区块链和联邦学习的软件行为智能管控方法,结合机器学习、联邦学习和区块链技术,在保护用户的软件行为数据隐私的前提下,综合多方数据协同训练软件行为分类模型,并根据分类结果及时对软件弹窗行为实施管控。相比原有集中数据训练模型的方法,本发明的方法可以实现在保护用户数据隐私的前提下提升软件弹窗行为分类准确率,同时也为跨用户共享弹窗类软件的管控策略提供了支持。
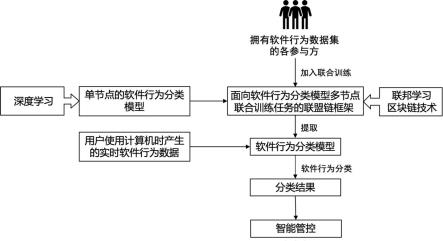
7.为了解决上述技术问题,本发明采用的技术方案是:基于区块链和联邦学习的软件行为智能管控方法,包括以下步骤:(1)构建单节点的软件行为分类模型,包括软件行为感知与存储、构建软件行为数据集、设计软件弹窗用户界面内容识别和软件行为分类模型网络结构的步骤;(2)构建面向软件行为分类模型多节点联合训练任务的联盟链,将上一步构建的软件行为分类模型作为各节点本地训练的模型,并结合区块链和联邦学习技术,实现联盟链上的各节点在无中心节点驱动的情况下,多方协同训练软件行为分类模型,包括设计软件行为分类模型联合训练任务的联盟链架构、定义链上区块结构和联合训练流程、设计模型聚合算法和编写软件行为分类模型联合训练过程中的智能合约的部分;(3)设计软件行为智能管控客户端工具,实时感知用户使用计算机时产生的软件行为数据,并输入构建的软件行为分类模型,为软件行为分类,获得分类结果,根据分类结果对软件行为智能管控。
8.进一步的,步骤(1)中具体步骤如下:(1.1)软件行为感知与存储:分析不同弹窗类软件的自动弹窗原理,实时感知各类多维度软件的行为数据,并存储;(1.2)构建软件行为数据集:将存储的多维度软件行为数据进行数据清洗,然后对该弹窗软件的行为数据做标注,由用户判断是否喜欢该内容并标注,将标注过的软件行为数据作为最终的训练与测试数据集;(1.3)软件弹窗用户界面内容识别:对软件弹窗用户界面中的文本内容进行识别,并将其作为后续软件行为分类模型输入的一部分;(1.4)构建软件行为分类模型:分别将软件弹窗用户界面内容的识别结果、进程行为数据和网络行为数据映射为特征向量形式并将特征向量以不同权重进行融合,然后通过深度神经网络进行特征学习,最后将学习到的特征向量输入到概率输出层,输出每个类别的概率,实现对软件弹窗行为的分类。
9.进一步的,步骤(2)基于hyperledger fabric设计了面向软件行为分类模型联合训练任务的联盟链架构,建立起去中心化软件行为分类模型联合训练框架。为了保障软件行为数据的隐私性和软件行为分类模型的安全性,本方法提出的框架用到的区块链类型为联盟链。相比于公有链架构,联盟链为各节点设置了更严格的身份认证条件,能够为系统提升安全性。同时,为避免链上数据存储给各节点带来的存储空间负担和保障用户本地数据的隐私性,该联盟链只记录模型训练任务信息、节点本地模型的摘要信息、共享模型参数信息,各节点无需上传本地软件行为数据。联盟链中节点的角色分为任务协调节点和数据提供节点,任务协调节点负责发布软件行为分类模型联合训练任务、初始化全局模型,最终通过提取全局模型参数来完成此次任务;数据提供节点负责针对任务协调节点发布的软件行为分类模型联合训练任务,使用本地软件行为数据集训练模型,并上传本地模型的摘要信息与模型参数,以完成此次任务。
10.在已初始化构建联盟链的去中心化网络上,软件行为分类模型联合训练流程的详细步骤如下:(2.1)任务协调节点向联盟链系统发布学习训练任务描述并初始化全局模型参数,然后新增一个软件行为分类联合训练任务,其中,初始全局模型选用步骤(1)构建的软
件行为分类模型。
11.(2.2)参与此次任务的数据提供节点形成一个集合,然后从联盟链中获取联合训练任务信息和全局模型参数并解密,基于本地的软件行为数据集执行联邦学习,协作训练同一个机器学习模型。
12.(2.3)各数据提供节点在每一轮迭代训练结束后将本地模型的摘要数据(如模型的准确率、损失值等)和加密后的模型参数作为交易内容发起交易,然后由智能合约评估各节点对模型做出的贡献,并仅保留符合要求的模型交易信息至联盟链上。
13.(2.4)在每轮迭代训练结束后,智能合约计算各节点对全局模型贡献度的权重,然后基于权重实现模型参数的聚合并更新全局模型,判断全局模型是否拟合或达到最大迭代次数。如果达到此条件,则判定本次联合训练任务完成,然后通知任务协调节点;如果未达到此条件,则将聚合后的全局模型打包成区块并发布下一轮的迭代训练任务,各节点开始下一轮的迭代训练,继续执行步骤(2.2)。
14.(2.5)任务协调节点提取全局模型参数并验证模型的有效性以结束此次联合训练任务。
15.进一步的,步骤(2)中所述模型聚合算法,根据各数据提供节点本地模型的摘要信息调整各自本地模型的聚合权重,调整本地模型参数在更新的全局模型参数中的占比,增加高质量模型参数在聚合模型中的权重占比;各数据提供节点对模型的贡献度通过节点在第k轮本地训练迭代的模型损失确定,使用交叉熵评估各节点的本地模型损失,将模型聚合算法的模型贡献度权重定义为:型损失,将模型聚合算法的模型贡献度权重定义为:和分别为节点和节点的交叉熵损失函数,为输入参数,为期望输出,则基于模型贡献度权重的模型聚合算法中更新全局模型参数的过程可以表示为:其中,表示第k-1轮聚合之后的全局模型参数,n为参与本轮模型聚合的节点数,为节点在第k轮模型聚合中的模型贡献度权重,为节点在第k轮本地更新后的模型参数,为节点在的本地数据的平
均梯度,为第k轮聚合后的全局模型参数。
16.进一步的,联合训练过程中,编写智能合约,每轮迭代包括三个过程:1)任务协调节点或调用智能合约发布软件行为分类模型联合训练任务,将任务信息记录在区块链上后,各数据提供节点请求并接收此模型训练任务相关数据,在此过程中,数据提供节点将调用智能合约通过获取分类帐得到相关数据;2)获取全局模型参数后,各数据提供节点基于私有的软件行为数据集进行本地训练,然后将得到的模型摘要信息和加密后的模型参数发送回区块链网络中,这时会调用智能合约的一个函数,这个函数会以本轮各个节点传输的模型摘要信息和模型参数作为输入,验证交易中模型摘要信息,仅保留能够提升模型准确率或着样本数达到规定的最小样本数的模型数据;3)最后一个过程是软件行为分类模型的聚合,智能合约将步骤(2.3)中通过模型贡献评估流程保留在链上的模型摘要信息和模型参数作为输入,计算各数据提供节点的模型贡献度权重,并基于模型贡献度权重的模型聚合算法来更新全局模型,然后判断其是否达到最大拟合程度或迭代次数,进而触发完成本次软件行为分类联合训练任务或继续发布下一轮的迭代训练任务。
17.进一步的,联盟链中的各节点通过软件行为分类模型联合训练过程,不断迭代优化模型,最终输出一个效果最好的优化后的软件行为分类模型,提取此模型用于实际的软件行为分类。
18.与现有技术相比,本发明优点在于:(1)本发明将深度学习方法应用于软件行为分类与管控,自动化感知多维度软件行为数据,将能更准确地表达软件行为特征的软件进程、网络流量和用户界面内容数据进行融合,然后学习软件行为数据的特征实现软件行为的分类,分类结果较为可靠并能根据分类结果进行智能管控,提高了用户的系统操作体验。
19.(2)本发明设计的软件行为分类模型联合训练思路能够使各节点的数据不出本地,充分利用各参与方的数据协同训练出更准确的软件行为分类模型,既保障了用户数据的私密性,也能充分利用各参与方的软件行为数据,提升模型的性能。
20.(3)传统联邦学习过程依赖中心服务器驱动训练,无法保证学习的公开透明,同时也无法实现联邦学习全过程的跟踪与追溯。为解决此类问题,本发明结合区块链和联邦学习技术,设计了软件行为分类模型联合训练任务的联盟链框架,该框架能够在无中心节点驱动的情况下,将软件行为分类模型训练过程的模型准确率、损失值等摘要数据存储在区块链上,通过编写的智能合约实现联邦学习过程的自动化与透明化。
21.(4)本发明提出了基于模型贡献度权重的模型参数聚合算法,该算法根据各数据提供节点本地模型的摘要信息调整各自模型的聚合权重,增加高质量模型参数在聚合模型中的权重占比,能够增强联邦学习节点间的互信度与聚合模型的准确性。
附图说明
22.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
23.图1为本发明的方法流程图;图2为本发明构建单节点的软件行为分类模型的流程图;图3为本发明面向软件行为分类模型多节点联合训练任务的联盟链框架;图4为本发明发布与获取模型训练任务流程图;图5为本发明模型贡献评估流程图;图6为本发明模型聚合流程图;图7为本发明软件行为智能管控客户端工具功能结构图。
具体实施方式
24.下面结合附图及具体实施例对本发明作进一步的说明。
25.结合图1所示,基于区块链和联邦学习的软件行为智能管控方法,包括以下步骤:(1)构建单节点的软件行为分类模型,包括软件行为感知与存储、构建软件行为数据集、设计软件弹窗用户界面内容识别和软件行为分类模型网络结构的步骤。(2)构建面向软件行为分类模型多节点联合训练任务的联盟链,将上一步构建的软件行为分类模型作为各节点本地训练的模型,并结合区块链和联邦学习技术,实现联盟链上的各节点在无中心节点驱动的情况下,多方协同训练软件行为分类模型,包括设计软件行为分类模型联合训练任务的联盟链架构、定义链上区块结构和联合训练流程、设计模型聚合算法和编写软件行为分类模型联合训练过程中的智能合约的部分。
26.(3)将用户使用计算机时产生的实时软件行为数据输入构建的软件行为分类模型,为软件行为分类,获得分类结果,根据分类结果对软件行为智能管控。
27.下面结合附图分别介绍各步骤,如图2所示的构建单节点的软件行为分类模型的流程,步骤(1)中具体步骤如下:(1.1)软件行为感知与存储:面向windows操作系统中普遍存在的弹窗类互联网应用软件,针对基于不同开发框架所开发的软件之间的技术差异,研究其运行过程中的自动弹窗原理,基于windows api和winpcap库设计开发软件行为信息采集客户端工具,实时感知各类软件的窗口创建、窗口图像、进程运行时资源(主要包括cpu、内存和网络)占用等多维度软件行为数据,并用sqlite数据库和pcap类型文件存储这些数据,为软件行为建模分析提供数据支撑。
28.(1.2)构建软件行为数据集:将存储的多维度软件行为数据进行数据清洗,然后对该弹窗软件的行为数据做标注,由用户判断是否喜欢该内容并标注,将标注过的软件行为数据作为最终的训练与测试数据集。
29.(1.3)软件弹窗用户界面内容识别:软件弹窗用户界面图片中的文字部分占主体,且用户一般会通过阅读文字的方式来了解弹窗中的内容,因此本方法会对软件弹窗用户界面中的文本内容进行识别,并将其作为后续软件行为分类模型输入的一部分。
30.在本文采集的广告弹窗用户界面图片中,由于文字区域没有充满整张图片,若是直接使用文本识别模型进行识别,将会收到其他背景信息的干扰,这样模型的效果会大打折扣。因此在广告弹窗用户界面图片使用文本识别模型之前,一般会使用文本区域检测算法对图片中的文本进行定位,将图片中检测出的文本区域作为文本识别模型的输入,以提升识别效果。
31.文本区域检测网络将软件弹窗用户界面内容中的文本区域进行了归一化处理,然后通过深度卷积神经网络和序列标注模块,将用户界面文字特征提取和序列预测整合,实现端到端的用户界面内容识别,最终输出软件弹窗用户界面内容的识别结果。
32.(1.4)构建软件行为分类模型:分别将软件弹窗用户界面内容的识别结果、进程行为数据和网络行为数据映射为特征向量形式并将特征向量以不同权重进行融合,然后通过深度神经网络进行特征学习,最后将学习到的特征向量输入到概率输出层,输出每个类别的概率,实现对软件弹窗行为的分类。
[0033] 结合图3所示的面向软件行为分类模型多节点联合训练任务的联盟链框架,步骤(2)基于hyperledger fabric设计了面向软件行为分类模型联合训练任务的联盟链架构,建立起去中心化软件行为分类模型联合训练框架。为了保障软件行为数据的隐私性和软件行为分类模型的安全性,本方法提出的框架用到的区块链类型为联盟链。相比于公有链架构,联盟链为各节点设置了更严格的身份认证条件,能够为系统提升安全性。同时,为避免链上数据存储给各节点带来的存储空间负担和保障用户本地数据的隐私性,该联盟链只记录模型训练任务信息、节点本地模型的摘要信息、共享模型参数信息,各节点无需上传本地软件行为数据。联盟链中节点的角色分为任务协调节点和数据提供节点,任务协调节点负责发布软件行为分类模型联合训练任务、初始化全局模型,最终通过提取全局模型参数来完成此次任务;数据提供节点负责针对任务协调节点发布的软件行为分类模型联合训练任务,使用本地软件行为数据集训练模型,并上传本地模型的摘要信息与模型参数,以完成此次任务。
[0034]
在已初始化构建联盟链的去中心化网络上,软件行为分类模型联合训练流程的详细步骤如下:(2.1)任务协调节点向联盟链系统发布学习训练任务描述并初始化全局模型参数,然后新增一个软件行为分类联合训练任务,其中,初始全局模型选用步骤(1)构建的软件行为分类模型。
[0035]
(2.2)参与此次任务的数据提供节点形成一个集合,然后从联盟链中获取联合训练任务信息和全局模型参数并解密,基于本地的软件行为数据集执行联邦学习,协作训练同一个机器学习模型。
[0036]
(2.3)各数据提供节点在每一轮迭代训练结束后将本地模型的摘要数据(如模型的准确率、损失值等)和加密后的模型参数作为交易内容发起交易,然后由背书节点模拟执行交易并背书,由选取的排序服务节点打包成区块,广播至全网进行区块信息验证,验证通过后发布到联盟链上。在各数据提供节点上传本地模型的摘要数据和加密后的模型参数时,智能合约会评估各节点对模型做出的贡献,并仅保留符合要求的模型交易信息至联盟链上。
[0037]
(2.4)在每轮迭代训练结束后,智能合约计算各节点对全局模型贡献度的权重,然后基于权重实现模型参数的聚合并更新全局模型,判断全局模型是否拟合或达到最大迭代次数。如果达到此条件,则潘迪昂本次联合训练任务完成,然后通知任务协调节点;如果未达到此条件,则将聚合后的全局模型打包成区块并发布下一轮的迭代训练任务,各节点开始下一轮的迭代训练,继续执行步骤(2.2)。
[0038]
(2.5)任务协调节点提取全局模型参数并验证模型的有效性以结束此次联合训练
任务。
[0039]
现有的模型聚合算法主要是联邦平均fedavg,但是fedavg没有考虑到低质量模型参与聚合导致的全局模型质量降低问题。本发明提出了基于模型贡献度权重的模型聚合算法,步骤(2)中所述模型聚合算法,根据各数据提供节点本地模型的摘要信息调整各自本地模型的聚合权重,调整本地模型参数在更新的全局模型参数中的占比,增加高质量模型参数在聚合模型中的权重占比;各数据提供节点对模型的贡献度通过节点在第k轮本地训练迭代的模型损失确定,使用交叉熵评估各节点的本地模型损失,将模型聚合算法的模型贡献度权重定义为:聚合算法的模型贡献度权重定义为:和分别为节点和节点的交叉熵损失函数,为输入参数,为期望输出,则基于模型贡献度权重的模型聚合算法中更新全局模型参数的过程可以表示为:其中,表示第k-1轮聚合之后的全局模型参数,n为参与本轮模型聚合的节点数,为节点在第k轮模型聚合中的模型贡献度权重,为节点在第k轮本地更新后的模型参数,为节点在的本地数据的平均梯度,为第k轮聚合后的全局模型参数。
[0040]
全局模型gk达到收敛的条件是当gk的交叉熵小于预先设定的值h或迭代次数达到最大迭代次数maxiterationnum,即:。
[0041]
基于模型贡献度权重的模型聚合算法如算法1所示。
[0042]
算法1 基于模型贡献度权重的模型聚合input: 参与节点,迭代次数,加密后的全局模型参数output: 加密后的全局模型参数1
ꢀꢀ
while
ꢀꢀ
do2
ꢀꢀꢀꢀꢀꢀꢀ
for
ꢀꢀ
do3ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
获取最新的模型参数并解密以获得,设4
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
for 从1到迭代次数s的每一次本地迭代j do5
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
从上一次迭代获得本地模型参数,即设6
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
for 从1到划分批量数据集b的批量序号b do7
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
计算该批量数据集b的梯度8
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
本地更新模型参数:9
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
计算本地更新模型损失:10
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
end for11
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
end for12
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
获得本地模型参数更新,在上执行加法同态加密得到,本地模型损失,并上传至区块链上13
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
智能合约进行模型参数聚合,对收到的模型参数加权平均,即14
ꢀꢀ
end while15
ꢀꢀ
return 本发明通过上述基于模型贡献度权重的模型参数聚合算法,评估各节点的本地模型损失值,调整本地模型参数在更新的全局模型参数中的占比,增强了联邦学习过程的公平性与聚合模型的准确性。
[0043]
结合图4-6所示,本发明通过编写智能合约实现软件行为分类模型联合训练过程的自动化与透明化,在联合训练过程中,每轮迭代包括三个主要过程:1)任务协调节点或调用智能合约发布软件行为分类模型联合训练任务,将任务信息记录在区块链上后,各数据提供节点请求并接收此模型训练任务相关数据,在此过程中,数据提供节点将调用智能合约通过获取分类帐得到相关数据;2)获取全局模型参数后,各数据提供节点基于私有的软件行为数据集进行本地训练,然后将得到的模型摘要信息和加密后的模型参数发送回区块链网络中,这时会调用智能合约的一个函数,这个函数会以本轮各个节点传输的模型摘要信息和模型参数作为输入,验证交易中模型摘要信息,仅保留能够提升模型准确率或着样本数达到规定的最小样本数的模型数据;3)最后一个过程是软件行为分类模型的聚合,智能合约将上一步中通过模型贡献评估流程保留在链上的模型摘要信息和模型参数作为输入,计算各数据提供节点的模型贡献度权重,并基于模型贡献度权重的模型聚合算法来更新全局模型,然后判断其是否达到最大拟合程度或迭代次数,进而触发完成本次软件行为分类联合训练任务或继续发布下一轮的迭代训练任务。
[0044]
本发明通过上述基于hyperledger fabric和联邦学习的联盟链框架,能够实现在保护用户数据隐私的前提下,利用多用户的软件行为数据协同训练模型,提升软件行为分类模型的准确率,借助用户群体的软件喜好来分类并管控弹窗行为;也能实现无中心节点驱动联合训练过程,保证节点间的互信与聚合模型的可信性;通过编写和部署智能合约实
现联合训练全过程的自动化和透明化;将训练过程中的摘要数据存储在链上,方便后续对联合训练任务追踪审计。
[0045]
在使用时,联盟链中的各节点通过软件行为分类模型联合训练过程,不断迭代优化模型,最终会输出一个效果更好的软件行为分类模型,提取此模型用于实际的软件行为分类。
[0046]
结合图7所示,本发明设计了软件行为智能管控客户端工具,当用户在使用计算机时,该工具能够实时感知系统中各类软件的行为,采集相关软件行为数据,调用软件行为分类模型实时地为软件行为分类。用户可以在客户端中定义软件行为管控策略,根据分类结果进行智能管控:对于分类结果为用户不喜欢的软件行为,采用结束进程等方式阻止此软件行为;对于分类结果为用户喜欢的软件行为,采取保留措施。同时客户端工具会记录分类结果为用户不喜欢的软件行为,包括软件名称、软件服务提供商、相同软件行为出现频次等数据,用户可以定期查询软件行为的统计信息。对于出现频次较多的用户不喜欢的软件行为,客户端会提示用户是否需要卸载此软件,当用户确认卸载后,客户端会自动卸载相应软件。
[0047]
综上所述,本发明从软件的进程数据、网络流量和用户界面内容等多维度学习软件行为特征,实现软件行为分类,并根据分类结果及时对软件行为实施管控。此外,本发明可以借助多用户的软件行为数据建设信息共享机制,结合区块链和联邦学习技术,实现依照用户群体的软件喜好进行软件行为的智能管控。
[0048]
当然,上述说明并非是对本发明的限制,本发明也并不限于上述举例,本技术领域的普通技术人员,在本发明的实质范围内,做出的变化、改型、添加或替换,都应属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1