一种健康医疗文本自动分类和安全等级自动分级方法与流程
1.本发明涉及健康医疗文本处理技术领域,具体而言,涉及一种健康医疗文本自动分类和安全等级自动分级方法。
背景技术:
2.健康医疗大数据正成为我国重要的基础性战略资源,但在医疗健康领域,目前针对海量健康医疗文本数据的自动分类和自动分级尚没有高效、准确的方法。(1)健康医疗文本自动分类:健康医疗文本自动分类技术可以为不同的文本打上各类标签(1个到若干个),为海量医疗健康文本快速高效的类别分类、相似电子病例检索、机器人辅助诊断、医院智能导诊和医疗机器人智能问答等智慧健康医疗领域提供必要的数据理解技术。(2)健康医疗文本自动分级:健康医疗文本安全分级的目的是为了对数据采取更合理的安全管理和保护,对不同安全级别的数据进行自动标记区分,明确不同级别数据的访问人员和访问方式,采取的安全保护措施。准确清晰的健康医疗数据分级技术,将为建立完善的健康医疗数据生命周期保护框架奠定基础,从而规范和推动健康医疗数据的融合共享、开放应用。
3.近些年来,大型互联网科技公司普遍使用机器学习、深度学习、预训练模型等技术来进行海量文本自动分类,以满足其系统在文本分类和内容分发、商品推荐、搜索引擎、智能问答、内容理解和内容安全防护等应用场景的需求。在基于人工智能技术的文本自动分类领域,文本特征抽取技术和将文本语义表示再进行分类的技术是重难点,目前对健康医疗文本的自动分类、分级技术还不够成熟,尤其是对健康医疗文本的安全等级自动分级技术还较少,同时,对健康医疗文本的特征抽取及语义理解还不够充分,在特定领域的文本分类上主要的技术路线是对文本全文进行特征抽取和语义理解,然后将固定维度的特征向量输入含有softmax神经网络的全连接层进行文本分类,目前的分类效果还有待提高,所以需要在特征抽取和分类方法上进行改进和提高,从而提高健康医疗文本自动分类的准确性。
4.传统的技术方案具体为:传统的机器学习方法主要利用自然语言处理领域中的基于统计语言模型中n-gram思想对文本进行特征提取,利用词频-逆文档频率对n-gram特征进行计算和语义表示,然后将提取到的文本特征输入到逻辑回归、朴素贝叶斯等分类器中进行训练,最终得到文本分类模型。但是,上述基于词频-逆文档频率的特征提取方法可能存在特征数据稀疏和向量维度爆炸等问题,这对以上分类器来说是灾难性的,并使得训练的机器学习模型泛化能力有限。
5.在深度学习技术兴起之后,基于卷积神经网络cnn、循环神经网络rnn、长短期记忆人工神经网络lstm等神经网络的特征抽取器使得文本分类技术的效果有所提高,近几年bert、gpt、xlnet等基于大规模预料进行无监督学习的预训练语言模型的出现,使得利用少量标注数据进行模型微调训练就能实现譬如文本分类、命名实体识别、文本对匹配等具体任务,但是对这些预训练模型进行下游任务的微调时由于其预训练使用的数据与下游任务中的具体领域数据语义特征分布并不一定相匹配,因此会影响预训练模型的性能,导致下游任务无法达到很好的效果。
6.再者,目前的文本分类技术主要是单独使用基于transfomer类形成的语义特征抽取模型对文本全文进行特征抽取和语义信息理解,但是文本全文本身存在一定的冗余信息,这种方法就存在一定的局限性,无法对同一篇含有不同尺度文本语义信息(微观、较宏观、宏观)进行特征提取和融合,同时模型对文本核心信息和关键信息的重视度和注意力较低,导致不能充分地理解一篇文章的整体语义信息。此外,在最终的分类上主要是通过含有softmax神经网络分类层的方法,最终分类结果的可解释性较弱,文本分类效果还有待提高。而且,通过transformer模型(如bert、gpt-2模型内部的特征抽取器)抽取后的向量表达会产生各向异性,表现状态就是向量会不均匀分布,且充斥在一个狭窄的锥形空间下,低频词离原点远,分布稀疏,高频词向量离原点近,分布紧密,这都是仅使用bert类模型特征抽取器中最后一层的[cls]向量表达(解释:在bert输入的每一个序列开头都插入特定的分类token([cls]),该分类token对应的最后一个transformer层输出被用来起到聚集整个序列表征信息的作用),导致最终文本分类效果不好的原因。
[0007]
综上所述,传统的技术方案存在如下问题:在基于人工智能技术的文本自动分类领域,文本特征抽取和通过文本语义表示后进行分类是重难点,目前对健康医疗文本的自动分类、安全分级技术还不够成熟,尤其是对健康医疗文本的自动安全分级技术还较少,同时,由于健康医疗文本中领域性专有名词较多,目前基于全文文本的自然语言理解模型技术对健康医疗文本的特征抽取及核心语义理解还不够充分,在特定领域的文本分类上主要的技术路线是对文本全文进行特征抽取和语义理解,然后将固定维度的特征向量输入含有softmax神经网络的全连接层进行文本分类,目前的分类效果还有待提高,所以需要在特征抽取和语义理解方法和最终的分类方法上进行改进和提高,从而提高健康医疗文本自动分类、安全等级自动分级的准确性。
技术实现要素:
[0008]
本发明旨在提供一种健康医疗文本自动分类和安全等级自动分级方法,以解决现有技术中使用单一的深度学习算法对健康医疗文本的语义理解不充分,同时由于健康医疗文本中领域性专有名词较多,导致目前基于深度学习技术的自动分类、自动分级的效果不好的技术问题,同时可以结合传统机器学习的文本分类技术技术使得分类模型的可解释性更好,最终提高健康医疗文本自动分类、安全等级自动分级的准确性。
[0009]
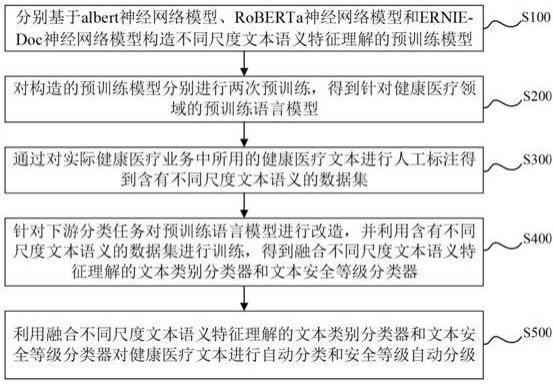
本发明提供的一种健康医疗文本自动分类和安全等级自动分级方法,包括如下步骤:s100,分别基于albert神经网络模型、roberta神经网络模型和ernie-doc神经网络模型构造不同尺度文本语义特征理解的预训练模型;s200,对构造的预训练模型分别进行两次预训练,得到针对健康医疗领域的预训练语言模型;s300,通过对实际健康医疗业务中所用的健康医疗文本进行人工标注得到含有不同尺度文本语义的文本数据集;s400,针对下游分类任务对预训练语言模型进行改造,并利用含有不同尺度文本语义的数据集进行训练,得到融合不同尺度文本语义特征理解的文本类别分类器和文本安全等级分类器;
s500,利用融合不同尺度文本语义特征理解的文本类别分类器和文本安全等级分类器对健康医疗文本进行自动分类和安全等级自动分级。
[0010]
进一步的,步骤s100中分别基于albert神经网络模型、roberta神经网络模型和ernie-doc神经网络模型构造不同尺度文本语义特征理解的预训练模型的方法包括:分别通过对albert神经网络模型、roberta神经网络模型和ernie-doc神经网络模型的特征抽取层进行改造,得到不同尺度文本语义特征理解的预训练模型:通过对albert神经网络模型的特征抽取层进行改造,得到3个不同尺度的预训练模型,分别为第一微型预训练模型albert-small、第一中型预训练模型albert-middle和第一大型预训练模型albert-big;通过对roberta神经网络模型的特征抽取层进行改造,得到3个不同尺度的预训练模型,分别为第二微型预训练模型roberta-small、第二中型预训练模型roberta-middle和第二大型预训练模型roberta-big;通过对ernie-doc神经网络模型的特征抽取层进行改造,得到3个不同尺度的预训练模型,分别为第三微型预训练模型ernie-doc-small、第三中型预训练模型ernie-doc-middle和第三大型预训练模型ernie-doc-big。
[0011]
进一步的,所述第一微型预训练模型albert-small、第一中型预训练模型albert-middle和第一大型预训练模型albert-big含有不同数量的特征抽取层;所述第二微型预训练模型roberta-small、第二中型预训练模型roberta-middle和第二大型预训练模型roberta-big含有不同数量的特征抽取层;所述第三微型预训练模型ernie-doc-small、第三中型预训练模型ernie-doc-middle和第三大型预训练模型ernie-doc-big含有不同数量的特征抽取层;所述第一微型预训练模型albert-small、第二微型预训练模型roberta-small和第三微型预训练模型ernie-doc-small含有相同数量的特征抽取层,所述第一中型预训练模型albert-small、第二中型预训练模型roberta-small和第三中型预训练模型ernie-doc-small含有相同数量的特征抽取层,所述第一大型预训练模型albert-small、第二大型预训练模型roberta-small和第三大型预训练模型ernie-doc-small含有相同数量的特征抽取层。
[0012]
进一步的,步骤s200中对构造的预训练模型分别进行两次预训练,得到针对健康医疗领域的预训练语言模型的方法包括:s201,使用大规模通用语料对不同尺度的预训练模型分别进行第一次无监督学习预训练,训练任务为在每一句话中随机遮住一定比例的字然后让预训练模型对遮住的字进行预测,从而让各个预训练模型学习通用语料知识和语义关系;s202,使用大规模健康医疗文本,并采用第一次无监督学习预训练的方法,对各个预训练模型进行第二次无监督学习预训练,得到9个预训练语言模型,分别命名为健康医疗领域第一微型预训练语言模型albert-small-med、健康医疗领域第一中型预训练语言模型albert-middle-med、健康医疗领域第一大型预训练语言模型albert-big-med,健康医疗领域第二微型预训练语言模型roberta-small-med、健康医疗领域第二中型预训练语言模型roberta-middle-med、健康医疗领域第二大型预训练语言模型roberta-big-med,健康医疗领域第三微型预训练语言模型ernie-doc-small-med、健康医疗领域第三中型预训练语言模型ernie-doc-middle-med、健康医疗领域第三大型预训练语言模型ernie-doc-big-med。
[0013]
进一步的,在第二次无监督学习预训练的过程中,需要通过正则化和降低学习率的方法,避免预训练的过程中产生知识灾难遗忘的情况。
[0014]
进一步的,步骤s300中通过对实际健康医疗业务中所用的健康医疗文本进行人工标注得到含有不同尺度文本语义的数据集的方法包括:s301,收集实际健康医疗业务中所用的健康医疗文本,记为1号健康医疗文本;对1号健康医疗文本进行分类和安全等级的人工标注,将1号健康医疗文本和标注的分类和安全等级标签存储为第三尺度数据集;s302,对1号健康医疗文本全文进行摘要抽取,将抽取的摘要作为记为2号健康医疗文本;对2号健康医疗文本全文进行分类和安全等级的人工标注,将2号健康医疗文本和标注的分类和安全等级标签存储为第二尺度数据集;s303,对2号健康医疗文本进行进行关键词提取,将提取的关键词作为3号健康医疗文本;对3号健康医疗文本进行分类和安全等级的人工标注,将3号健康医疗文本和标注的分类和安全等级标签存储为第一尺度数据集。
[0015]
综上所述,由于采用了上述技术方案,本发明的有益效果是:1、本发明基于深度学习、预训练模型技术(基于albert神经网络模型、roberta神经网络模型和ernie-doc神经网络模型),针对要构造对含有不同尺度文本语义的文本语义理解的模型特征抽取层进行重新设计,生成9个新的深度神经网络模型,从而对含有不同尺度文本语义的文本特征进行更好地语义理解和特征抽取,同时可以增强模型对文本核心信息和关键信息的重视程度和注意力,从而充分地理解一篇文章的整体语义信息,可以更好地进行文本分类、文本安全等级分级的下游任务。
[0016]
2、本发明通过大规模通用文本语料和健康医疗文本语料的两次预训练,使9个预训练模型对通用知识、医疗健康知识和各种语义信息进行充分学习,形成了针对健康医疗领域文本的预训练语言模型,为健康医疗领域下游任务的再训练和预测提供了坚实的文本特征抽取基础。
[0017]
3、本发明通过9个训练好的针对不同尺度文本语义特征提取的文本特征抽取器,可以对字词级、摘要级、篇章级的文本进行各类文本特征的抽取,同时将经过每一个特征抽取器的第一层和最后一层所有字的向量表示求平均后得到文本的语义表示,通过叠加融合宏微观不同尺度文本语义抽取后的语义向量,可以更加充分地对文本进行语义理解和语义特征表示,还可以增强特征抽取模型对文本核心信息的重视程度,降低模型对文本冗余信息的关注度。
[0018]
4、本发明使用集成学习的思想对最终融合语义的特征向量进行文本分类模型的训练,可以更好地关注医疗健康领域文本的专有名词并通过提取重要的内容特征进行类别分类,同时增强文本分类的可解释性,从而提高健康医疗文本分类的准确性。
[0019]
5、本发明使用传统机器学习的思想对最终融合语义的特征向量进行文本安全等级分类器的训练,从而提高医疗健康文本分级的准确性和可解释性。
附图说明
[0020]
图1为本发明实施例中健康医疗文本自动分类和安全等级自动分级方法的流程图。
[0021]
图2a为本发明实施例中第一微型预训练语言模型albert-small的特征抽取层的结构示意图。
[0022]
图2b为本发明实施例中第一微型预训练语言模型albert-small的多头注意力机制示意图。
[0023]
图3a为本发明实施例中健康医疗文本自动分类时,对构造的预训练模型分别进行两次预训练,得到针对健康医疗领域的预训练语言模型的技术路线图。
[0024]
图3b为本发明实施例中健康医疗文本自动分类时,基于健康医疗领域的预训练语言模型和深度学习的方法分别训练针对不同尺度文本的特征抽取器的技术路线图。
[0025]
图3c为本发明实施例中健康医疗文本自动分类时,基于传统机器学习的方法训练叠加融合的文本高维语义向量和对应标签,从而得到融合不同尺度文本语义特征理解的文本类别分类器的技术路线图。
[0026]
图4a为本发明实施例中健康医疗文本安全等级自动分级时,对构造的预训练模型分别进行两次预训练,得到针对健康医疗领域的预训练语言模型的技术路线图。
[0027]
图4b为本发明实施例中健康医疗文本安全等级自动分级时,基于健康医疗领域的预训练语言模型和深度学习的方法分别训练针对不同尺度文本的特征抽取器的技术路线图。
[0028]
图4c为本发明实施例中健康医疗文本安全等级自动分级时,基于传统机器学习的方法训练叠加融合的文本高维语义向量和对应标签,从而得到融合不同尺度文本语义特征理解的文本安全等级分类器的技术路线图。
具体实施方式
[0029]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
[0030]
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例
[0031]
如图1所示,本实施例提出一种健康医疗文本自动分类和安全等级自动分级方法,包括如下步骤:s100,分别基于albert神经网络模型、roberta神经网络模型和ernie-doc神经网络模型构造不同尺度文本语义特征理解的预训练模型;s200,对构造的预训练模型分别进行两次预训练,得到针对健康医疗领域的预训练语言模型;s300,通过对实际健康医疗业务中所用的健康医疗文本进行人工标注得到含有不同尺度文本语义的数据集;s400,针对下游分类任务对预训练语言模型进行改造,并利用含有不同尺度文本语义的数据集进行训练,得到融合不同尺度文本语义特征理解的文本类别分类器和文本安
全等级分类器;s500,利用融合不同尺度文本语义特征理解的文本类别分类器和文本安全等级分类器对健康医疗文本进行自动分类和安全等级自动分级。
[0032]
由此,本发明是一种基于深度学习、预训练模型技术(基于albert神经网络模型、roberta神经网络模型和ernie-doc神经网络模型设计和改造)与传统机器学习(catboost模型或者lightgbm模型)相结合的健康医疗文本自动分类和安全等级自动分级方法,能够解决现有技术中使用单一的深度学习算法对健康医疗文本的语义理解不充分,同时解决由于健康医疗文本中领域性专有名词较多,导致目前基于深度学习技术的自动分类、安全等级自动分级效果不好的技术问题,同时结合传统机器学习的文本分类技术技术可以使得分类模型的可解释性更好。
[0033]
具体地:s100,分别基于albert神经网络模型、roberta神经网络模型和ernie-doc神经网络模型构造不同尺度文本语义特征理解的预训练模型:分别通过对albert神经网络模型、roberta神经网络模型和ernie-doc神经网络模型的特征抽取层进行改造,得到不同尺度文本语义特征理解的预训练模型:通过对albert神经网络模型的特征抽取层进行改造,得到3个不同尺度的预训练模型,分别为第一微型预训练模型albert-small、第一中型预训练模型albert-middle和第一大型预训练模型albert-big;通过对roberta神经网络模型的特征抽取层进行改造,得到3个不同尺度的预训练模型,分别为第二微型预训练模型roberta-small、第二中型预训练模型roberta-middle和第二大型预训练模型roberta-big;通过对ernie-doc神经网络模型的特征抽取层进行改造,得到3个不同尺度的预训练模型,分别为第三微型预训练模型ernie-doc-small、第三中型预训练模型ernie-doc-middle和第三大型预训练模型ernie-doc-big。
[0034]
在本实施例中,所述第一微型预训练模型albert-small、第一中型预训练模型albert-middle和第一大型预训练模型albert-big含有不同数量的特征抽取层;所述第二微型预训练模型roberta-small、第二中型预训练模型roberta-middle和第二大型预训练模型roberta-big含有不同数量的特征抽取层;所述第三微型预训练模型ernie-doc-small、第三中型预训练模型ernie-doc-middle和第三大型预训练模型ernie-doc-big含有不同数量的特征抽取层;所述第一微型预训练模型albert-small、第二微型预训练模型roberta-small和第三微型预训练模型ernie-doc-small含有相同数量的特征抽取层,所述第一中型预训练模型albert-small、第二中型预训练模型roberta-small和第三中型预训练模型ernie-doc-small含有相同数量的特征抽取层,所述第一大型预训练模型albert-small、第二大型预训练模型roberta-small和第三大型预训练模型ernie-doc-small含有相同数量的特征抽取层。
[0035]
示例:如图2a、图2b所示,第一微型预训练模型albert-small包括4层特征抽取层(每层特征抽取层为一个神经网络transformer-encoder编码器),768个隐藏单元和4个自注意力头;图中参数矩阵q、参数矩阵k、参数矩阵v分别表示模型训练得到的权值矩阵。第一中型预训练模型albert-middle包括8层特征抽取层,768个隐藏单元和8个自注意力头;第一大型预训练模型albert-big包括16层特征抽取层,768个隐藏单元和16个自注意力头。
[0036]
同理,第二微型预训练模型roberta-small包括4层特征抽取层,768个隐藏单元和4个自注意力头;第二中型预训练模型roberta-middle包括8层特征抽取层,768个隐藏单元和8个自注意力头;第二大型预训练模型roberta-big包括16层特征抽取层,768个隐藏单元和16个自注意力头。
[0037]
同理,第三小型预训练模型ernie-doc-small为包括4层特征抽取层,768个隐藏单元和4个自注意力头;第三中型预训练模型ernie-doc-middle包括8层特征抽取层,768个隐藏单元和8个自注意力头;第三大型预训练模型ernie-doc-big包括16层特征抽取层,768个隐藏单元和16个自注意力头。
[0038]
s200,如图3a、4a所示,对构造的预训练模型分别进行两次预训练,得到针对健康医疗领域的预训练语言模型:s201,使用大规模通用语料(中文维基百科、百度百科)对不同尺度的预训练模型分别进行第一次无监督学习预训练,训练任务为在每一句话中随机遮住一定比例(根据需要进行设定,一般可设置为10%)的字然后让预训练模型对遮住的字进行预测,从而让各个预训练模型学习通用语料知识和语义关系;s202,使用大规模健康医疗文本,并采用第一次无监督学习预训练的方法,对各个预训练模型进行第二次无监督学习预训练,得到9个预训练语言模型,分别命名为健康医疗领域第一微型预训练语言模型albert-small-med、健康医疗领域第一中型预训练语言模型albert-middle-med、健康医疗领域第一大型预训练语言模型albert-big-med,健康医疗领域第二微型预训练语言模型roberta-small-med、健康医疗领域第二中型预训练语言模型roberta-middle-med、健康医疗领域第二大型预训练语言模型roberta-big-med,健康医疗领域第三微型预训练语言模型ernie-doc-small-med、健康医疗领域第三中型预训练语言模型ernie-doc-middle-med、健康医疗领域第三大型预训练语言模型ernie-doc-big-med。进一步地,在第二次无监督学习预训练的过程中,需要通过正则化和降低学习率的方法,避免预训练的过程中产生知识灾难遗忘的情况。
[0039]
s300,通过对实际健康医疗业务中所用的健康医疗文本进行人工标注得到含有不同尺度文本语义的数据集:s301,收集实际健康医疗业务中所用的健康医疗文本,记为1号健康医疗文本;对1号健康医疗文本进行分类和安全等级的人工标注,将1号健康医疗文本和标注的分类和安全等级标签存储为第三尺度数据集;s302,对1号健康医疗文本全文进行摘要抽取(可以采用基于图的排序算法text rank算法,或pyhanlp第三方工具等),将抽取的摘要作为记为2号健康医疗文本;对2号健康医疗文本全文进行分类和安全等级的人工标注,将2号健康医疗文本和标注的分类和安全等级标签存储为第二尺度数据集;s303,对2号健康医疗文本进行进行关键词提取(可以采用基于图的排序算法text rank算法,或pyhanlp第三方工具等),将提取的关键词作为3号健康医疗文本;对3号健康医疗文本进行分类和安全等级的人工标注,将3号健康医疗文本和标注的分类和安全等级标签存储为第一尺度数据集。
[0040]
本实施例中,文本分类类别通常分为6类,分别是个人基本信息、卫生综合信息、卫生费用、公共卫生数据、卫生管理数据和物联网数据(也可以是根据实际健康医疗业务再制
定其他类别)。文本安全等级分级通常分为5级,分别为1级、2级、3级、4级、5级(也可以是根据实际健康医疗业务再制定更多的等级划分)。进一步地,在标注分类和安全等级标签时,应将中每个文本类别、每个安全等级的数据尽量保持均衡。还需要说明的是,第一尺度数据集、第二尺度数据集和第三尺度数据集均可分为训练集、验证集和测试集,对于训练集、验证集和测试集在训练过程中的使用为常规技术,在此不再赘述。
[0041]
示例:1号健康医疗文本(文本全文):标注的文本分类类别:公共卫生。
[0042]
标注的文本安全等级:1级。
[0043]
1号健康医疗文本全文如下:骨质疏松可以通过下列方法进行预防:1、合理日照,科学健身,选择适当的锻炼方法,进行适应不同年龄者的承重运动。
[0044]
2、培养和坚持良好的生活习惯,合理配膳,均衡营养,增加钙的足够摄入,控制体重、减少肥胖。
[0045]
3、戒烟,限酒,养成良好的生活习惯。
[0046]
4、积极预防继发性骨质疏松,除正确防治原发性疾病外,如需使用能引起骨质疏松等副作用的药物时(如糖皮质激素、肝素、抗癫痫类药等)应谨遵医嘱,同时应采取相应措施,防止骨质疏松等并发症的发生。
[0047]
5、在饮食上宜选择以下食物,有利于预防骨质疏松:牛奶、乳酪等奶制品,海带、海鱼、虾皮、紫菜等海产品,韭菜、芹菜、苋菜、小白菜等新鲜绿色蔬菜。
[0048]
6、适当的进行体育锻炼、注意补充富含钙和维生素d的饮食,可以强健骨骼;但锻炼时应注意选择合适的锻炼方法,以免受伤。
[0049]
7、适当进行运动锻炼,提高肌肉质量、稳定关节,比如快步走、慢跑、骑自行车等。
[0050]
8、使用骨健康基本补充剂,如钙剂或维生素d。
[0051]
2号健康医疗文本(文本摘要):骨质疏松可以通过下列方法进行预防:1、合理日照,科学健身,选择适当的锻炼方法,进行适应不同年龄者的承重运动。
[0052]
2、积极预防继发性骨质疏松,除正确防治原发性疾病外,如需使用能引起骨质疏松等副作用的药物时(如糖皮质激素、肝素、抗癫痫类药等)应谨遵医嘱。
[0053]
3、在饮食上宜选择以下食物,有利于预防骨质疏松:牛奶、乳酪等奶制品,海带、海鱼、虾皮、紫菜等海产品,韭菜、芹菜、苋菜、小白菜等新鲜绿色蔬菜。
[0054]
3号健康医疗文本(关键词):骨质疏松、合理日照、健身、锻炼、营养、预防、健康、药物、维生素、绿色蔬菜。
[0055]
s400,针对下游分类任务对预训练语言模型进行改造,并利用含有不同尺度文本语义的数据集进行训练,得到融合不同尺度文本语义特征理解的文本类别分类器和文本安全等级分类器:(1)文本分类如图3b、3c所示,针对下游分类任务对预训练语言模型进行改造,并利用不同尺度的数据集进行训练,得到融合不同尺度文本语义特征理解的文本类别分类器的方法包括:
s4110,对于第一微型预训练语言模型albert-small-med、健康医疗领域第一中型预训练语言模型albert-middle-med、健康医疗领域第一大型预训练语言模型albert-big-med:s4111,在第一微型预训练语言模型albert-small-med、健康医疗领域第一中型预训练语言模型albert-middle-med、健康医疗领域第一大型预训练语言模型albert-big-med的最后一层分别接入softmax神经网络层,分别得到健康医疗领域第一微型文本分类模型albert-small-med-cls、健康医疗领域第一中型文本分类模型albert-middle-med-cls和健康医疗领域第一大型文本分类模型albert-big-med-cls;s4112,将第一尺度数据集、第二尺度数据集和第三尺度数据集中的文本和对应的分类标签分别送入健康医疗领域第一微型文本分类模型albert-small-med-cls、健康医疗领域第一中型文本分类模型albert-middle-med-cls和健康医疗领域第一大型文本分类模型albert-big-med-cls进行训练,当训练完成后去除三个模型最后一层的softmax神经网络层,得到3个第一文本特征抽取器,分别为健康医疗领域第一微型文本特征抽取器albert-small-med-cls-extractor、健康医疗领域第一中型文本特征抽取器albert-middle-med-cls-extractor和健康医疗领域第一大型文本特征抽取器albert-big-med-cls-extractor;s4113,将第一尺度数据集、第二尺度数据集和第三尺度数据集中来自同一篇健康医疗文本的三篇文本分别送入健康医疗领域第一微型文本特征抽取器albert-small-med-cls-extractor、健康医疗领域第一中型文本特征抽取器albert-middle-med-cls-extractor、健康医疗领域第一大型文本特征抽取器albert-big-med-cls-extractor,经过每一个第一文本特征抽取器的第一层和最后一层所有字的向量表示求平均,得到3个第一文本高维语义向量,分别为第一微型文本高维语义向量albert-small-med-cls-first-last-layer-average-pooling-embedding、第一中型文本高维语义向量albert-middle-med-cls-first-last-layer-average-pooling-embedding、第一大型文本高维语义向量albert-big-med-cls-first-last-layer-average-pooling-embedding;然后将3个第一文本高维语义向量进行叠加融合为健康医疗领域第一文本特征融合向量albert-med-cls-fuse-embedding;s4114,基于catboost模型或者lightbgm模型建立第一集成学习分类器,将大量健康医疗领域第一文本特征融合向量albert-med-cls-fuse-embedding以及对应的分类标签送入第一集成学习分类器进行训练,训练完成后得到第一融合不同尺度文本语义特征理解的文本类别分类器albert-med-fuse-cls;s4120,对于健康医疗领域第二微型预训练语言模型roberta-small-med、健康医疗领域第二中型预训练语言模型roberta-middle-med、健康医疗领域第二大型预训练语言模型roberta-big-med:s4121,在健康医疗领域第二微型预训练语言模型roberta-small-med、健康医疗领域第二中型预训练语言模型roberta-middle-med、健康医疗领域第二大型预训练语言模型roberta-big-med的最后一层分别接入softmax神经网络层,分别得到健康医疗领域第二微型文本分类模型roberta-small-med-cls、健康医疗领域第二中型文本分类模型roberta-middle-med-cls和健康医疗领域第二大型文本分类模型roberta-big-med-cls;
doc-big-med-cls-extractor;s4133,将第一尺度数据集、第二尺度数据集和第三尺度数据集中来自同一篇健康医疗文本的三篇文本分别送入健康医疗领域第三微型文本特征抽取器ernie-doc-small-med-cls-extractor、健康医疗领域第三中型文本特征抽取器ernie-doc-middle-med-cls-extractor和健康医疗领域第三大型文本特征抽取器ernie-doc-big-med-cls-extractor,经过每一个第三文本特征抽取器的第一层和最后一层所有字的向量表示求平均,得到3个第三文本高维语义向量,分别为第三微型文本高维语义向量ernie-doc-small-med-cls-first-last-layer-average-pooling-embedding、第三中型文本高维语义向量ernie-doc-middle-med-cls-first-last-layer-average-pooling-embedding、第三大型文本高维语义向量ernie-doc-big-med-cls-first-last-layer-average-pooling-embedding;然后将3个第三文本高维语义向量进行叠加融合为健康医疗领域第三文本特征融合向量ernie-doc-med-cls-fuse-embedding;s4134,基于catboost模型或者lightbgm模型建立第三集成学习分类器,将大量健康医疗领域第三文本特征融合向量ernie-doc-med-cls-fuse-embedding以及对应的分类标签送入第三集成学习分类器进行训练,训练完成后得到第三融合不同尺度文本语义特征理解的文本类别分类器ernie-doc-med-fuse-cls。
[0056]
(2)安全等级分级如图4b、4c所示,针对下游分类任务对语言模型进行改造,并利用不同尺度的数据集进行训练,得到融合不同尺度文本语义特征理解的文本安全等级分类器的方法包括:s4210,对于第一微型预训练语言模型albert-small-med、健康医疗领域第一中型预训练语言模型albert-middle-med、健康医疗领域第一大型预训练语言模型albert-big-med:s4211,在第一微型预训练语言模型albert-small-med、健康医疗领域第一中型预训练语言模型albert-middle-med、健康医疗领域第一大型预训练语言模型albert-big-med的最后一层分别接入softmax神经网络层,分别得到健康医疗领域第一微型文本安全分级模型albert-small-med-level、健康医疗领域第一中型文本安全分级模型albert-middle-med-level和健康医疗领域第一大型文本安全分级模型albert-big-med-level;s4212,将第一尺度数据集、第二尺度数据集和第三尺度数据集中的文本和对应的安全等级标签分别送入健康医疗领域第一微型文本分类模型albert-small-med-cls、健康医疗领域第一中型文本分类模型albert-middle-med-cls和健康医疗领域第一大型文本分类模型albert-big-med-cls进行训练,当训练完成后去除三个模型最后一层的softmax神经网络层,得到3个第一文本特征抽取器,分别为健康医疗领域第一微型文本特征抽取器albert-small-med-level-extractor、健康医疗领域第一中型文本特征抽取器albert-middle-med-level-extractor和健康医疗领域第一大型文本特征抽取器albert-big-med-level-extractor;s4213,将第一尺度数据集、第二尺度数据集和第三尺度数据集中来自同一篇健康医疗文本的三篇文本分别送入健康医疗领域第一微型文本特征抽取器albert-small-med-level-extractor、健康医疗领域第一中型文本特征抽取器albert-middle-med-level-extractor和健康医疗领域第一大型文本特征抽取器albert-big-med-level-extractor,
经过每一个第一文本特征抽取器的第一层和最后一层所有字的向量表示求平均,得到3个第一文本高维语义向量,分别为第一微型文本高维语义向量albert-small-med-level-first-last-layer-average-pooling-embedding、第一中型文本高维语义向量albert-middle-med-level-first-last-layer-average-pooling-embedding和第一大型文本高维语义向量albert-big-med-level-first-last-layer-average-pooling-embedding;然后将3个第一文本高维语义向量进行叠加融合为健康医疗领域第一文本特征融合向量albert-med-level-fuse-embedding;s4214,建立第一支持向量机模型,将大量健康医疗领域第一文本特征融合向量albert-med-level-fuse-embedding以及对应的安全等级标签送入第一支持向量机模型进行训练,训练完成后得到第一融合不同尺度文本语义特征理解的文本安全等级分类器albert-med-fuse-level;s4220,对于健康医疗领域第二微型预训练语言模型roberta-small-med、健康医疗领域第二中型预训练语言模型roberta-middle-med、健康医疗领域第二大型预训练语言模型roberta-big-med:s4221,在健康医疗领域第二微型预训练语言模型roberta-small-med、健康医疗领域第二中型预训练语言模型roberta-middle-med、健康医疗领域第二大型预训练语言模型roberta-big-med的最后一层分别接入softmax神经网络层,分别得到健康医疗领域第一微型文本安全分级模型roberta-small-med-level、健康医疗领域第二中型文本安全分级模型roberta-middle-med-level和健康医疗领域第二大型文本安全分级模型roberta-big-med-level;s4222,将第一尺度数据集、第二尺度数据集和第三尺度数据集中的文本和对应的安全等级标签分别送入健康医疗领域第一微型文本安全分级模型roberta-small-med-level、健康医疗领域第二中型文本安全分级模型roberta-middle-med-level和健康医疗领域第二大型文本安全分级模型roberta-big-med-level进行训练,当训练完成后去除三个模型最后一层的softmax神经网络层,得到3个第二文本特征抽取器,分别为健康医疗领域第二微型文本特征抽取器roberta-small-med-level-extractor、健康医疗领域第二中型文本特征抽取器roberta-middle-med-level-extractor和健康医疗领域第二大型文本特征抽取器roberta-big-med-level-extractor;s4223,将第一尺度数据集、第二尺度数据集和第三尺度数据集中来自同一篇健康医疗文本的三篇文本分别送入健康医疗领域第二微型文本特征抽取器roberta-small-med-level-extractor、健康医疗领域第二中型文本特征抽取器roberta-middle-med-level-extractor和健康医疗领域第二大型文本特征抽取器roberta-big-med-level-extractor,经过每一个第二文本特征抽取器的第一层和最后一层所有字的向量表示求平均,得到3个第二文本高维语义向量,分别为第二微型文本高维语义向量roberta-small-med-level-first-last-layer-average-pooling-embedding、第二中型文本高维语义向量roberta-middle-med-level-first-last-layer-average-pooling-embedding和第二大型文本高维语义向量roberta-big-med-level-first-last-layer-average-pooling-embedding;然后将3个第二文本高维语义向量进行叠加融合为健康医疗领域第二文本特征融合向量roberta-med-level-fuse-embedding;
s4224,建立第二支持向量机模型,将大量健康医疗领域第二文本特征融合向量roberta-med-level-fuse-embedding以及对应的安全等级标签送入第二支持向量机模型进行训练,训练完成后得到第二融合不同尺度文本语义特征理解的文本安全等级分类器roberta-med-fuse-level;s4230,对于健康医疗领域第三微型预训练语言模型ernie-doc-small-med、健康医疗领域第三中型预训练语言模型ernie-doc-middle-med、健康医疗领域第三大型预训练语言模型ernie-doc-big-med:s4231,在健康医疗领域第三微型预训练语言模型ernie-doc-small-med、健康医疗领域第三中型预训练语言模型ernie-doc-middle-med、健康医疗领域第三大型预训练语言模型ernie-doc-big-med的最后一层分别接入softmax神经网络层,分别得到健康医疗领域第三微型文本安全分级模型ernie-doc-small-med-level、健康医疗领域第三中型文本安全分级模型ernie-doc-middle-med-level和健康医疗领域第三大型文本安全分级模型ernie-doc-big-med-level;s4232,将第一尺度数据集、第二尺度数据集和第三尺度数据集中的文本和对应的安全等级标签分别送入健康医疗领域第三微型文本安全分级模型ernie-doc-small-med-level、健康医疗领域第三中型文本安全分级模型ernie-doc-middle-med-level和健康医疗领域第三大型文本安全分级模型ernie-doc-big-med-level进行训练,当训练完成后去除三个模型最后一层的softmax神经网络层,得到3个第三文本特征抽取器,分别为健康医疗领域第三微型文本特征抽取器ernie-doc-small-med-level-extractor、健康医疗领域第三中型文本特征抽取器ernie-doc-middle-med-level-extractor和健康医疗领域第三大型文本特征抽取器ernie-doc-big-med-level-extractor;s4233,将第一尺度数据集、第二尺度数据集和第三尺度数据集中来自同一篇健康医疗文本的三篇文本分别送入健康医疗领域第三微型文本特征抽取器ernie-doc-small-med-level-extractor、健康医疗领域第三中型文本特征抽取器ernie-doc-middle-med-level-extractor和健康医疗领域第三大型文本特征抽取器ernie-doc-big-med-level-extractor,经过每一个第三文本特征抽取器的第一层和最后一层所有字的向量表示求平均,得到3个第三文本高维语义向量,分别为第三微型文本高维语义向量ernie-doc-small-med-level-first-last-layer-average-pooling-embedding、第三中型文本高维语义向量ernie-doc-middle-med-level-first-last-layer-average-pooling-embedding、第三大型文本高维语义向量ernie-doc-big-med-level-first-last-layer-average-pooling-embedding;然后将3个第三文本高维语义向量进行叠加融合为健康医疗领域第三文本特征融合向量ernie-doc-med-level-fuse-embedding;s4234,建立第三支持向量机模型,将大量健康医疗领域第三文本特征融合向量ernie-doc-med-level-fuse-embedding以及对应的安全等级标签送入第三支持向量机模型进行训练,训练完成后得到第三融合不同尺度文本语义特征理解的文本安全等级分类器ernie-doc-med-fuse-level。
[0057]
s500,利用融合不同尺度文本语义特征理解的文本类别分类器和文本安全等级分类器对健康医疗文本进行自动分类和安全等级自动分级:(1)文本分类
步骤s500中利用融合不同尺度文本语义特征理解的文类别分类器对健康医疗文本进行自动分类的方法包括:s511,对第一融合不同尺度文本语义特征理解的文本类别分类器albert-med-fuse-cls、第二融合不同尺度文本语义特征理解的文本类别分类器roberta-med-fuse-cls和第三融合不同尺度文本语义特征理解的文本类别分类器ernie-doc-med-fuse-cls均设置权重为1/3;s512,将待识别健康医疗文本抽取文本摘要和关键词,然后将关键词、文本摘要和文本全文均送入第一融合不同尺度文本语义特征理解的文本类别分类器albert-med-fuse-cls、第二融合不同尺度文本语义特征理解的文本类别分类器roberta-med-fuse-cls和第三融合不同尺度文本语义特征理解的文本类别分类器ernie-doc-med-fuse-cls,对待识别健康医疗文本进行自动分类,得到3个文本类别分类器的分类结果;s513,如果3个文本类别分类器的分类结果一致,则认为该待识别健康医疗文本的分类结果为文本类别分类器的分类结果;如果有两个文本类别分类器的分类结果一致,则认为该健康医疗文本的分类结果为这两个文本类别分类器的分类结果;如果三个文本类别分类器识别的分类结果均不一致,则以3个文本类别分类器的分类结果中概率值最高的分类结果为该健康医疗文本的分类结果。
[0058]
(2)安全等级分级步骤s500中利用融合不同尺度文本语义特征理解的文本安全等级分类器对健康医疗文本进行安全等级自动分级的方法包括:s521,对第一融合不同尺度文本语义特征理解的文本安全等级分类器albert-med-fuse-level、第二融合不同尺度文本语义特征理解的文本安全等级分类器roberta-med-fuse-level和第三融合不同尺度文本语义特征理解的文本安全等级分类器ernie-doc-med-fuse-level均设置权重为1/3;s522,将待识别健康医疗文本抽取文本摘要和关键词,然后将关键词、文本摘要和文本全文均送入第一融合不同尺度文本语义特征理解的文本安全等级分类器albert-med-fuse-level、第二融合不同尺度文本语义特征理解的文本安全等级分类器roberta-med-fuse-level和第三融合不同尺度文本语义特征理解的文本安全等级分类器ernie-doc-med-fuse-level,对待识别健康医疗文本进行安全等级自动分级,得到3个文本安全等级分类器的安全等级分级结果;s523,如果3个文本安全等级分类器的安全等级分级结果一致,则认为该待识别健康医疗文本的安全等级分级结果为文本安全等级分类器的安全等级分级结果;如果有两个文本安全等级分类器的安全等级分级结果一致,则认为该健康医疗文本的安全等级分级结果为这两个文本安全等级分类器的安全等级分级结果;如果三个文本安全等级分类器识别的安全等级分级结果均不一致,则以3个文本安全等级分类器的安全等级分级结果中概率值最高的安全等级分级结果为该健康医疗文本的安全等级分级结果。
[0059]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1