一种提高数据意图识别能力的文本数据增强方法及装置
1.本发明属于自然语言处理技术领域,具体涉及一种提高数据意图识别能力的文本数据增强方法及装置。
背景技术:
2.随着新时代人民生活水平的提高,越来越多的人在日常生活中遇到一些健康问题时,更希望在网络平台上快速而方便地寻求。随着自然语言处理和语音识别技术的不断发展成熟,智能医疗问答机器人应运而生。
3.目前业界搭建一个智能医疗机器人普遍会出现一个少样本数据的问题,即用于训练智能医疗机器人的意图样本数据过少。在自然语言处理领域,意图代表着一类问题的统称。比如“今天杭州天气怎么样”、“明天北京天气如何”这样的句子都可以归于询问天气这一意图。如果在初期意图样本数据不足,智能医疗机器人可能会无法正确识别用户的意图,也就不能做出正确回复。丰富的意图样本数据是智能医疗机器人的重要基石,所以在构建智能医疗机器人前期,丰富的意图数据可提高其意图识别能力。
4.数据增强正是解决意图样本数据不足这一问题的方法之一。目前对于文本的数据增强方法主要有三类:释义、噪声和采样。释义是对句子中的词、短语在不改变其语义的情况下做一些更改,使之产生更多样式的句子。主要方案有同义词的修改、替换和删除等。噪声是指在不变更句子语义的情况下,对句子添加一些噪声数据从而提高鲁棒性。最后,采样是指掌握数据分布,并从数据分布中采样出新的样本。与基于释义的模型类似,但不同之处在于采样更依赖任务,需要标签和数据格式等任务信息。以上三种方法都比较简单易实现,但是实际应用场景下,数据增强后的效果不尽人意。
5.基于此,本发明的关注点在于如何根据现有文本数据进行数据增强,以获得质量更高且丰富的文本数据,从而训练出一个具有更好的意图识别能力的和鲁棒性较高的意图分类模型。
技术实现要素:
6.本发明的第一个目的是针对上述技术问题,提供一种提高数据意图识别能力的文本数据增强方法,该方法基于依存句法解析树,将具有相同依存句法解析子树结构的两个句子进行混合数据增强和语义替换。并再此基础上,通过掩码语言模型将相同依存句法解析子树之外的部分去最掩码预测生成。上述方法,可以将一个少样本的数据集扩增为一个形式丰富的数据集,从而可以用意图分类识别的训练任务,提高其识别能力,增强其鲁棒性。
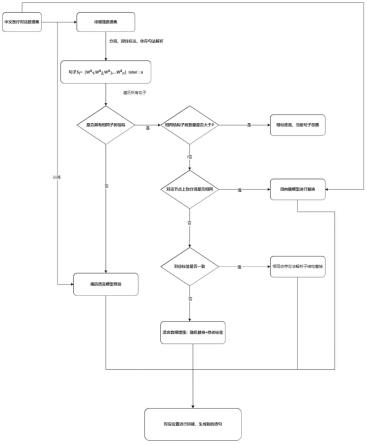
7.一种提高数据意图识别能力的文本数据增强方法,包括步骤:
8.步骤(1)、使用自然语言处理技术将待增强文本数据进行分词、词性标注和依存句法分析,从而生成每个句子的依存句法解析树;所述依存句法解析树的每个节点包含分词和所述分词所属的依存关系;同时对每个句子进行标注,所述标签为所属类别;
9.步骤(2)、遍历所有句子,对每个句子si,i=1,2,
…
,n进行数据增强,直至完成所有句子的数据增强,具体如下:
10.2-1遍历所有句子,对句子si,i=1,2,
…
,n与其他句子sj,j=1,2,
…
,n,i≠j进行依存句法解析树分析,获得多个当前句子si与其他句子sj,j=1,2,
…
,n,i≠j具有相同树结构部分和不同树结构部分,其中与其他句子具有相同树结构部分记为具有相同结构的依存句法解析子树,与其他句子具有不同树结构部分记为具有不相同结构的依存句法解析子树;
11.2-2对句子si的与句子sj具有相同结构的依存句法解析子树进行混合数据增强;具体是:
12.2-2-1判断当前依存句法解析子树是否满足树高度小于预设值p,若否则不做操作;若是则继续判断句子si与句子sj的当前依存句法解析子树上节点对应的分词是否相同,若相同则将句子si中当前依存句法解析子树所有节点对应分词使用词向量模型进行语义替换,若不同则跳转至步骤(2-2-2);
13.2-2-2判断当前依存句法解析子树上节点对应分词的标签是否相同,若相同则将句子si与句子sj具有相同结构的依存句法解析子树所有节点对应分词进行随机替换,若不同则将句子si与句子sj具有相同结构的依存句法解析子树所有节点对应分词进行随机替换,并把类别标签按照替换后的节点数量在当前依存句法解析子树节点数量的比例作为新的标签;
14.2-3、将句子si的与句子sj具有不相同结构的依存句法解析子树节点对应的分词输入到掩码语言模型中进行预测;
15.2-4、将步骤2-2和步骤2-3的输出数据进行拼接,数据标签更新与步骤2-2中的标签保持一致;
16.2-5、重复步骤2-1至2-4直至完成句子si与所有句子的依存句法解析树分析与数据增强。
17.作为优选,步骤(2-1)中若句子sj中具有相同结构的依存句法解析子树数目与具有不相同结构的依存句法解析子树数目之比大于预设值p,则认为句子si与句子sj相似度高,执行dropout操作,忽略句子sj,然后将句子si与下一个句子进行比较,重复步骤(2-1)。
18.作为优选,所述掩码语言模型采用改进bert模型;所述改进bert模型包括多层堆叠的transformer的encoder单元,所述transformer的encoder单元由多头注意力机制层muliti-head-attention、归一化层layer normalization、前馈层feedforword、归一化层layer normalization堆叠产生;
19.所述改进bert模型是将bert模型中的多层堆叠的transformer的encoder单元结构进行优化微调,具体过程为:
20.所述多头注意力机制层的输入编码向量是由掩码处理后的单词嵌入,以及位置嵌入和分割嵌入进行单位和,然后再拼接上分句符号[sep]构成,其中掩码处理后的单词嵌入是单词嵌入进行随机mask掩码处理得到,单词嵌入表示当前单词的语义信息,分割嵌入表示当前单词所在句子的索引嵌入,位置嵌入表示当前单词在句子中的位置信息。
[0021]
本发明提出在原bert模型encoder单元中多头注意力机制层的输入的编码向量中将用于分类模型的[cls]句向量特征删除,忽略该符号对应的输出向量作为整个句子的语
义表示,模型能够更好的关注单词的前后关系,可以更好的捕捉上下文的语义信息,更准确的预测下一个词的概率。
[0022]
此外还随机地将输入句子中的部分单词嵌入随机替换成[mask]符号,以适应单词预测任务。具体来说,有70%的概率该单词嵌入被替换成[mask]符号,有15%的概率该单词嵌入替换成其他任意一个token,有15%的概率该单词嵌入保持不变。
[0023]
所述归一化层是使用sigmoid函数代替原来的softmax函数进行归一化,sigmoid函数是可以将多头注意力机制层的输出映射在区间(0,1)之间,在有限的输出范围之间可以使得归一化层优化更加稳定;
[0024]
作为优选,所述改进bert模型的具体训练过程是:假设sent_a和sent_b是一组相似句,在同一个batch中,由掩码处理后的单词嵌入,以及位置嵌入和分割嵌入进行单位和,然后再拼接上分句符号[sep]作为改进bert模型中多头注意力机制层的输入编码向量,在整个batch内剔除的句向量特征[cls]去生成一个句向量矩阵v,即b*d,其维度是b是batch_size,d是hidden_size,然后对句向量矩阵v在d维度上做0均值标准化,得到矩阵对进行两两内积,得到相似度矩阵然后掩盖矩阵的对角线部分,最后在归一化层对于相似度矩阵每一行使用sigmoid函数进行归一化,使用交叉熵作为损失函数,最后在每个transformer的encoder单元得到每个单词新的向量表示。
[0025]
本发明的第二个目的是提供文本数据增强装置,包括:
[0026]
数据分词模块,用于将待增强文本数据进行分词;
[0027]
数据词性标注模块,用于将数据分词模块得到的单词进行词性标注;
[0028]
数据依存句法分析模块,用于将数据分词模块得到的单词和数据词性标注模块得到的单词词性进行依存句法分析,生成每个句子的依存句法解析树;
[0029]
数据增强模块,对所有句子完成数据增强。
[0030]
本发明的第三个目的是提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机所述的方法。
[0031]
本发明的第四个目的是提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现所述的方法。
[0032]
本发明与现有技术相比,主要优点包括:
[0033]
(1)将两个句子中的相似部分进行混合增强,生成新的标签数据。对于不相似的部分,通过掩码语言模型进行预测。通过混合增强,在原始数据的基础上增加了数据样本的多样性,将两种方式结合可以在生成不过分偏离原始数据分布又具有多样性的数据。
[0034]
(2)将混合数据增强和相同依赖解析子树结合起来。相同的依赖解析树可以精确捕捉句子中具有相似意义的部分,能更好的保持句子的语义信息。而混合数据增强可以将标签与句子融合从而生成新的数据,从而可以更好的捕捉不同标签的数据之间的语义关系。
附图说明
[0035]
图1为本发明的依存句法解析树相同子结构的示意图。
[0036]
图2为本发方法的流程示意图。
具体实施方式
[0037]
下面结合附图及具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。下列实施例中未注明具体条件的操作方法,通常按照常规条件,或按照制造厂商所建议的条件。
[0038]
本发明的一种提高数据意图识别能力的文本数据增强方法如图2所示,具体地,包括步骤:
[0039]
步骤(1)、将中文医疗对话数据集使用agglomerative clustering算法进行聚类作为待增强数据集,使用自然语言处理技术将待增强文本数据进行分词、词性标注和依存句法分析,从而生成每个句子的依存句法解析树;所述依存句法解析树的每个节点包含两个信息分别是分词和分词所属的依存关系;对于每个句子表示为个信息分别是分词和分词所属的依存关系;对于每个句子表示为label为句子的类别标签;
[0040]
如图1,是使用自然语言技术解析的结果,其本质上是数据结构中的树。每个节点包含两个信息分别是当前词语和当前词语所属的依存关系。每个句子都是从root节点构建依存解析树,root节点由所使用的自然语言处理库hanlp解析给出。依存关系的判定标准是按照chinese stanforddependencies依存关系标注集。
[0041]
步骤(2)、遍历所有句子,对每个句子si,i=1,2,
…
,n进行数据增强,直至完成所有句子的数据增强,具体如下:
[0042]
2-1遍历所有句子,对句子与其他句子进行依存句法解析树分析,获得多个当前句子si与其他句子sj,j=1,2,
…
,n,i≠j具有相同树结构部分和不同树结构部分,其中与其他句子具有相同树结构部分记为具有相同结构的依存句法解析子树,与其他句子具有不同树结构部分记为具有不相同结构的依存句法解析子树;若具有相同结构的依存句法解析子树数目与具有不相同结构的依存句法解析子树数目之比大于预设值q,则认为句子si与句子sj相似度高,执行dropout操作,忽略句子sj,然后将句子si与下一个句子进行比较,重复步骤(2-1);
[0043]
2-2对句子si的与句子sj具有相同结构的依存句法解析子树进行混合数据增强;具体是:
[0044]
2-2-1判断当前依存句法解析子树是否满足树高度小于预设值p(p可以取值为1),若否则不做操作;若是则继续判断句子si与句子sj的当前依存句法解析子树上节点对应的分词是否相同,若相同则将句子si中当前依存句法解析子树所有节点对应分词使用词向量模型进行语义替换,若不同则跳转至步骤(2-2-2);
[0045]
2-2-2判断当前依存句法解析子树上节点对应分词的标签是否相同,若相同则将句子si与句子sj具有相同结构的依存句法解析子树所有节点对应分词进行随机替换,若不同则将句子si与句子sj具有相同结构的依存句法解析子树所有节点对应分词进行随机替换,并把类别标签按照替换后的节点数量在当前依存句法解析子树节点数量的比例作为新的标签,得到数据增强后的当前依存句法解析子树对应部分句子的标签,得到数据增强后的当前依存句法解析子树对应部分句子
[0046]
2-3、将句子si的与句子sj具有不相同结构的依存句法解析子树节点对应的分词输
入到掩码语言模型中进行预测;
[0047]
所述掩码语言模型采用改进bert模型;所述改进bert模型是在常规bert模型上将原attention模块更改为muliti-head-attention;所述常规bert模型一个基于transformer encode的双向编码表示的预训练模型;所述bert模型训练时的任务之一是预测句子中被掩盖的词;所述改进bert模型的整体结构是包括多层堆叠的transformer的encoder单元;所述transformer的encoder单元包多头注意力机制层(muliti-head-attention)、归一化层(layer normalization)、前馈层(feedforword)、归一化层(layer normalization)四个模块;
[0048]
本发明将bert模型中的多层堆叠的transformer的encoder单元结构进行优化微调并适应当前预测任务;具体来说:
[0049]
1、原bert模型encoder单元中多头注意力机制层的输入的编码向量是由三个嵌入特征单位和再拼接上[cls]和[sep]而成的,这三个嵌入特征分别为单词嵌入、位置嵌入和分割嵌入,[cls]为句向量特征,[sep]为分句符号。本发明对多头注意力机制层的输入的编码向量中用于分类模型的[cls]特征删除,此外还随机地将输入句子中的部分单词嵌入随机替换成[mask],以适应单词预测任务;
[0050]
2、对于原attention模块中得到的相似度矩阵使用sigmod函数代替原来的softmax函数进行归一化;所述预测词语的标准并不是最大的概率值,而是多个极大值;所述sigmod函数可以比softmax函数更好的去解决这个问题;
[0051]
所述改进bert模型的具体训练过程是:假设sent_a和sent_b是一组相似句,在同一个batch中,由掩码处理后的单词嵌入,以及位置嵌入和分割嵌入进行单位和,然后再拼接上分句符号[sep]作为改进bert模型中多头注意力机制层的输入编码向量,在整个batch内剔除的句向量特征[cls]去生成一个句向量矩阵v,即b*d,其维度是b是batch_size,d是hidden_size,然后对句向量矩阵v在d维度上做0均值标准化,得到矩阵对进行两两内积,得到相似度矩阵然后掩盖矩阵的对角线部分,最后在归一化层对于相似度矩阵每一行使用sigmoid函数进行归一化,使用交叉熵作为损失函数,最后在每个transformer的encoder单元得到每个单词新的向量表示。
[0052]
2-4、将步骤2-2和步骤2-3的输出数据进行拼接,数据标签更新与步骤2-2中的标签保持一致;
[0053]
2-5、重复步骤2-1至2-4直至完成句子si与所有句子的依存句法解析树分析与数据增强。
[0054]
此外应理解,在阅读了本发明的上述描述内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本技术所附权利要求书所限定的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1