一种物联网边缘服务环境下深度感知的人体行为分析方法
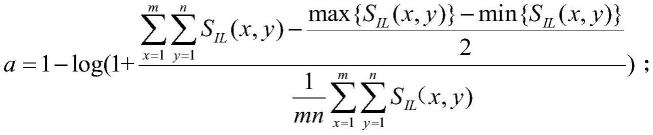
1.本发明属于人工智能目标识别,具体涉及一种物联网边缘服务环境下深度感知的人体行为分析方法。
背景技术:
2.计算机视觉领域中的人体行为识别方向在生活的诸多领域中都有着重大的应用价值,很多学者也对此展开了崇论宏议。人体行为识别中最热门的研究领域之一便是人体异常行为识别/检测。现实生活中,异常行为的表现方式各式各样,比如地铁里人群踩踏、马路上乱闯红绿灯、校园里打架斗殴、深水区游泳等。除此以外,异常行为定义与场景和时间息息相关。不同的时间,不同的场景中,同一种行为的定义也会随着不同。比如在餐厅的吃饭属于正常行为,但是在课堂中的吃饭却属于异常行为。因此,异常行为检测需要因地因时制宜,具体问题具体对待,设计不同解决方案。
3.目前,常见的异常行为检测方法主要有3种:1)基于环境设备的检测方法,根据人体产生异常行为时形成的环境噪声进行检测,如感知物体压力和声音的变化检测,误报率较高,极少被采纳使用。2)基于穿戴式传感器的检测方法,利用加速度计和陀螺仪检测跌倒等异常行为,长时间配戴传感器影响人的生活舒适度,会增加老年人机体负担,从事复杂活动时误报率较高。3)基于视觉识别的检测方法,可分为两类:一类是传统机器视觉方法提取有效的异常行为特征,对硬件要求低,但易受背景、光线变化等环境因素的影响,鲁棒性差;一类是人工智能方法,将相机图像数据用于卷积神经网络的训练和推理,虽然识别精度高,但高效的性能往往伴随着高昂的硬件成本,极大的限制了落地应用。近年来移动终端和小型嵌入式设备也具备了令人青睐的算力,且价格低廉,为人工智能算法的迁移部署提供了可能性。
技术实现要素:
4.解决的技术问题:针对在物联网边缘服务环境下当光线不足或不均匀的情况时拍摄的图像显示亮度低、对比度差、局部细节模糊、颜色保真度差、亮度突然变化;以及针对无法处理帧退化(快速运动造成的模糊)、视频散焦或姿势遮挡、检测目标过小等问题,本发明提出一种物联网边缘服务环境下的人体行为分析方法,依次进行图像预处理、姿态点提取、姿态预筛选、姿态点矫正、人体行为分析,确保检测结果的实时性和精准性。
5.技术方案:
6.一种物联网边缘服务环境下深度感知的人体行为分析方法,所述人体行为分析方法包括以下步骤:
7.s1,图像预处理:将采集得到的视频流转化为图像帧,针对不同环境参数下的图像的各个像素点灰度值的变化,对图像的对比度做出自适应调整;
8.s2,姿态点提取:基于yolov5s网络构建目标检测模型,采用目标检测模型进行目标检测,识别出图像中的人体目标,标记各个人体区域矩形框;对各个人体区域矩形框中的
人体姿态进行估计,提取出人体骨骼关键点;
9.s3,姿态预筛选:基于姿态点置信度,对人体姿态进行预筛选,对于任意一个人体姿态,当其所对应的人体骨骼关键点置信度为0的数目大于预设阈值时,忽略此人体姿态;
10.s4,正面人体姿态点二维坐标信息计算:针对每个预筛选的人体姿态,获取其所对应的目标姿态点深度信息,通过人体两侧姿态点深度信息得到的不对称关系来确定出人体偏转角,通过所得偏转角来纠正人体姿态点二维坐标信息,得到正面人体姿态点二维坐标信息;
11.s5,异常行为识别:根据正面人体姿态点二维坐标信息统计得到人体关节数据序列,基于lstm网络构建骨架行为识别模型,采用骨架行为识别模型对指定阶段内的人体关节数据序列进行处理,对其中包含的异常行为进行识别分析。
12.进一步地,步骤s1中,图像预处理的过程包括以下步骤:
13.s11,加载原始rgb彩色图像s(x,y),将其转化为hsi颜色模型,得到对应的强度图像si(x,y);
14.s12,提高强度图像si(x,y),具体地:
15.s121,估计强度的光照分量s
il
(x,y):
[0016][0017]
式中,和都是以像素i为中心的wi窗口中的线性系数,i=1,2,3...n,n为窗口总个数;
[0018]
s122,使用自适应伽马函数校正光照分量:
[0019]silg
(x,y)=s
il
(x,y)
φ(x,y)
;
[0020][0021]
通过光照分量各个像素点的灰度值计算得到自适应系数a的表达式:
[0022][0023]
式中,s
ilg
(x,y)为纠正后的照明分量,φ(x,y)为伽马矫正函数,m和n为图像的高度和宽度,参数a由灰度值自适应导出;
[0024]
s13,采用下述公式执行全局线性拉伸:
[0025][0026]
式中,min(s
ilg
(x,y))和max(s
ilg
(x,y))分别是图像中的最小和最大像素值;
[0027]
s14,采用下述公式计算反射分量:
[0028]sir
(x,y)=si(x,y)/s
il
(x,y);
[0029]
s15,使用wgif去噪反射组件去除图像噪声:
[0030][0031]
s16,进行图像融合操作:
[0032]
s161,采用下述公式计算增强的强度图像:
[0033]sie
(x,y)=s
ilgf
(x,y)s
irh
(x,y);
[0034]
s162,利用s-双曲正切函数提高融合图像的亮度:
[0035][0036][0037]
式中,b*是s
ie
的平均强度;
[0038]
s17,进行颜色恢复,具体地:
[0039]
s171,计算亮度增益系数α(x,y):
[0040]
α(x,y)=s
ief
(x,y)/si(x,y);
[0041]
s172,通过线性颜色恢复将增强的hsi图像转换为rgb:
[0042]
r1(x,y)=α(x,y)r0(x,y);
[0043]
g1(x,y)=α(x,y)g0(x,y);
[0044]
b1(x,y)=α(x,y)b0(x,y);
[0045]
式中,原始和增强彩色图像的rgb通道分别表示为[r0,g0,b0]和[r1,g1,b1]。
[0046]
进一步地,步骤s2中,目标检测模型的损失函数为:
[0047][0048]
式中,m为所有正样本的集合,|m|为正样本数,b表真实目标,b
′
表示目标框,b∩表示两者之间的交集区域,b∪b
′
分别表示两者之间并集区域,f
piou
函数的计算公式如下:
[0049][0050]
式中,sb∩表示经损失函数内核函数处理后,目标b和目标框b
′
交集的像素量数;sb∪表示两者并集的像素量数。
[0051]
进一步地,在目标检测模型中,fpn聚合相邻特征图层的方式公式如下:
[0052][0053]
式中,f
inner
是1*1的卷积操作实现通道匹配,f
upsample
代表2倍上采样操作实现特征图大小匹配,利用数据集的统计信息计算平衡因子
[0054][0055]
式中,n
pi+1
和n
pi
分别代表p
i+1
和pi层的数量。
[0056]
进一步地,步骤s2中,采用dcpose框架对各个人体区域矩形框中的人体姿态进行估计,提取出人体骨骼关键点;
[0057]
所述dcpose框架包括姿态时间合并模块、姿态残差融合模块和姿态矫正模块;
[0058]
所述姿态时间合并模块用于定位关键点的搜索范围,定位过程包括以下步骤:
[0059]
将前一帧、这一帧和后一帧的预测热图结合得到新的热图,根据时间分配权重,得
到初始的权重,时间上更接近当前帧的帧显式分配更高的权重:
[0060][0061]
式中hi(p)、hi(c)和hi(n
*
)表示初始关键点热图,p、c和n
*
表示帧索引;
[0062]
利用神经网络对权值进行调整,对于每个关节,仅包括其自己特定时间信息的关键点热图,将15个关节点得到的热图进行拼接生成最后的热图:
[0063][0064]
式中,表示连接操作,上标j索引第j个关节,总共n个关节;
[0065]
将热图输入到3*3的残差模块中,得到合并后的热图:
[0066]
φi(p,c,n
*
)
→
φi(p,c,n
*
);
[0067]
所述态残差融合模块用于计算帧间关键点偏移,计算过程包括以下步骤:
[0068]
计算姿态残差,将计算得到的姿态残差用作时间相关的线索,计算姿态残差特征的公式如下:
[0069][0070][0071][0072][0073]
式中,表示原始姿态残差及其加权版本;
[0074]
将热图输入到3*3的残差模块中,得到合并后的热图:
[0075][0076]
所述姿态矫正模块用于对姿态进行矫正,矫正过程包括以下步骤:
[0077]
将合并的关节点热图和姿态残差特征两组特征合并,姿势校正网络用于细化初始关键点热图估计hi(c),产生调整后的最终关节点热图;
[0078][0079]
将合并的关节点热图φi(p,c,n
*
)和偏移量输入到卷积层,获得五组mask;通过可变形卷积v2网络在各种膨胀系数d下实现姿态校正模块;
[0080]
输出人i的姿势热图:
[0081]
(φi(p,c,n
*
),o
i,d
,m
i,d
)
→hi,d
(c)。
[0082]
进一步地,步骤s3中,根据下述公式进行姿态预筛选:
[0083]
[0084][0085]
式中,i(p
*
)为p
*
的指示函数,表示p
*
是否忽略;k为p
*
中关键点的个数;表示p
*
的第k个关键点是否缺失,缺失为1,否则为0;x1和y1分别为人体脖子姿态点的横坐标和纵坐标,xi和yi分别为人体姿态点的横、纵坐标,i=0,1,...,n-1。
[0086]
进一步地,步骤s4中,正面人体姿态点二维坐标信息计算的过程包括以下步骤:
[0087]
s41,利用双目立体相机来估计人体骨架深度信息:
[0088][0089]
式中,对应于第t帧图像中人体第i个姿态点与左摄像头连线在成像图中的点,对应于第t帧图像中人体第i个姿态点与右摄像头连线在成像图中的点,b是为两个摄像头之间的距离,f为摄像头平面与成像平面之间的距离,是在第t帧图像中人体第i个姿态点的深度信息;
[0090]
s42,通过人体两侧姿态点深度信息得到的不对称关系来确定出人体偏转角:
[0091][0092][0093][0094][0095][0096]
式中,为第t帧图像中人体第i个姿态点的横坐标,为第t帧图像中人体第i个姿态点的纵坐标,为对应于在人体另一侧的横坐标,为对应于在人体另一侧的纵坐标,坐标,为偏转角对应的人体姿态点连接而成的封闭三角形的三边,为人体横截面与x轴的夹角,为摄像头与人体姿态点连线与y轴的夹角;
[0097]
s43,通过所得偏转角来纠正人体姿态点二维坐标信息:
[0098][0099][0100]
式中,为纠正后的人体姿态点横坐标,为纠正后的人体姿态点纵坐标,为纠正后的人体姿态点纵坐标,
[0101]
进一步地,步骤s5中,骨架行为识别模型包括依次连接的局部卷积神经网络、基于注意的lstm网络和分类模块;
[0102]
所述局部卷积神经网络基于输入序列x=(x1,x2,...xn),执行时空卷积网络,得到每个短期骨架序列的时空关系,获得n个特征值f=[f1,f2,...fn];xi代表在i阶段的人体关节数据,为一t
×m×
d维矩阵,d是人体关节数据的维度,m表示骨架关节的数量,t表示骨架序列的帧数量;
[0103]
所述基于注意的lstm网络对局部卷积神经网络输出的每个短期骨架序列的时空关系进行处理,得到相应的时间特征图,再对所有时间特征图进行平均,获得全局特征图:
[0104][0105]hi
=g(fi),i∈(1,n);
[0106]
q=[h1,h2,...,hn];
[0107]
α=softmax(w
t
tanh(q));
[0108]
r=qα
t
;
[0109]
式中,s是整个骨架序列的全局特征表示,h是lstm网络输出的时空特征图,k是输入骨架序列的人数;g函数表示lstm网络的特征提取过程,q是lstm网络输出的所有时间特征图的组合输出结果,使用时间序列的局部特征作为lstm的输入,lstm遗忘门意味着移除前一时间段中的无用段,并且输入门增加当前时间段中的有用段,lstm门表示骨架序列中的选择过程,保留有用的时间段特征,并丢弃无用的时间段特征,以获得骨架序列中最有用的计时特征,α表示lstm输出中n个特征的注意,w表示注意力学习的加权矩阵,r表示lstm输出时的加权注意力总和,在这个等式中,更重要的特征会引起更高的关注;
[0110]
所述分类模块包括全连接层和softmax层,全连接层与分类总类别相适配,对基于注意的lstm网络输出的全局特征进行识别,得到相应的行为分类结果。
[0111]
有益效果:
[0112]
第一,与常用的图像增强算法相比,本发明的物联网边缘服务环境下深度感知的人体行为分析方法,使用了一种基于伽马函数的自适应图像对比度调整方法,避免了光线不足或不均匀的情况时拍摄的图像显示亮度低、对比度差、局部细节模糊、颜色保真度差、亮度突然变化等问题。
[0113]
第二,与已有的常用的目标检测算法yolov3相比,本发明的物联网边缘服务环境下深度感知的人体行为分析方法,使用的yolov5检测速度快,检测精度高,鲁棒性强,有较好的可扩展性,既满足检测精度要求,又满足检测速度要求。
[0114]
第三,本发明的物联网边缘服务环境下深度感知的人体行为分析方法,提出一种基于姿态点置信度的自适应姿态预筛选方法对人体姿态进行预筛选,减少了识别模型的工作量,增加了识别准确性。
[0115]
第四,本发明的物联网边缘服务环境下深度感知的人体行为分析方法,提出一种基于双目摄像机的深度感知姿态点矫正算法得到目标姿态点深度信息,有效应对姿态遮挡等问题。
附图说明
[0116]
图1为本发明实施例的物联网边缘服务环境下深度感知的人体行为分析方法流程图。
[0117]
图2为ptm空间信息结构图。
[0118]
图3为prf时间信息结构图。
[0119]
图4为pcn矫正模块结构图。
[0120]
图5为基于时空关系的骨架行为识别网络模型图。
具体实施方式
[0121]
下面的实施例可使本专业技术人员更全面地理解本发明,但不以任何方式限制本发明。
[0122]
参见图1,本发明公开了一种物联网边缘服务环境下深度感知的人体行为分析方法,该人体行为分析方法包括:首先进行图像预处理,对采集到的视频流转化为图像帧,并提出一种基于伽马函数的自适应图像对比度调整方法,针对不同环境下图像各个像素点灰度值的变化对图像对比度做出自适应调整;其次进行姿态点提取,首先使用改进的yolov5s模型进行目标检测,识别出图像中的人体目标,并标记各个人体区域矩形框,之后使用dcpose框架对人体姿态进行估计,提取出人体骨骼关键点;然后进行姿态预筛选,提出一种基于姿态点置信度的自适应姿态预筛选方法对人体姿态进行预筛选;然后使用一种基于双目摄像机的深度感知姿态点矫正算法得到目标姿态点深度信息后,通过人体两侧姿态点深度信息得到的不对称关系来确定出人体偏转角,通过所得偏转角来纠正人体姿态点二维坐标信息,得到正面人体姿态点二维坐标信息;最后使用一种基于时空卷积和基于注意的lstm的骨架行为识别模型对异常行为进行识别分析。本发明主要针对在物联网边缘服务环境下当光线不足或不均匀的情况时拍摄的图像显示亮度低、对比度差、局部细节模糊,以及视频散焦或姿势遮挡、检测目标过小等问题,可以对人体行为进行有效分析
[0123]
下面结合附图和实施例对本发明的技术方案作进一步的说明。本发明的物联网边缘服务环境下深度感知的人体行为分析方法整体设计图如图1所示,包括以下步骤:
[0124]
步骤1,采集视频并将其转化为图像帧,使用一种基于伽马函数的自适应图像对比度调整方法进行图像增强。具体地,基于伽马函数的自适应图像对比度调整方法如下:
[0125]
首先加载原始rgb彩色图像s(x,y),将其转化为hsi颜色模型,选择强度图像si(x,y)。
[0126]
其次提高强度图像:
[0127]
(1)使用wgif估计强度的光照分量:
[0128][0129]
上式中,和都是以像素i为中心的wi窗口中的线性系数,n为窗口总个数。
[0130]
(2)使用自适应伽马函数校正光照分量:
[0131]silg
(x,y)=s
il
(x,y)
φ(x,y)
;
[0132]
[0133]
由于在不同光照条件下图像对比度不断变化,我们通过将图像光照分量各个像素点的灰度值与中间像素点灰度值之差的总和与像素点平均灰度值之比来得到自适应系数a的表达式:
[0134][0135]
上式中,s
ilg
(x,y)为纠正后的照明分量,φ(x,y)为伽马矫正函数,m和n为图像的高度和宽度,参数a由灰度值自适应导出,当光照较强时,a会变小,当光照较暗时,a会变大,从而使图像对比度维持在一定范围之内。
[0136]
(3)执行全局线性拉伸:
[0137][0138]
上式中,min(s
ilg
(x,y))和max(s
ilg
(x,y))分别是图像中的最小和最大像素值。
[0139]
(4)计算反射分量:
[0140]sir
(x,y)=si(x,y)/s
il
(x,y)。
[0141]
(5)使用wgif去噪反射组件:
[0142][0143]
(6)进行图像融合操作:
[0144]
(6.1)计算增强的强度图像:
[0145]sie
(x,y)=s
ilgf
(x,y)s
irh
(x,y);
[0146]
(6.2)利用s-双曲正切函数提高融合图像的亮度:
[0147][0148][0149]
上式中b*是s
ie
的平均强度,m和n分别是s
ie
的高度和宽度。
[0150]
(7)最后进行颜色恢复:
[0151]
(7.1)计算亮度增益系数:
[0152]
α(x,y)=s
ief
(x,y)/si(x,y);
[0153]
(7.2)通过线性颜色恢复将增强的hsi图像转换为rgb:
[0154][0155]
b1(x,y)=α(x,y)b0(x,y);
[0156]
上式中,原始和增强彩色图像的rgb通道分别表示为[r0,g0,b0]和[r1,g1,b1]。
[0157]
步骤2,通过yolov5s模型对图像进行检测,识别出图像中的人体目标,采用dcpose算法对人体骨骼关键点进行提取。
[0158]
其中yolov5模型优化方法如下:
[0159]
(1)损失函数的改进
[0160]
该函数通过设置了一个旋转参数,可旋转的矩形边界框能够更紧凑的贴合
[0161]
倾斜与密集的物体,该损失函数使用“数像素点”的方法来计算两旋转框之间的iou,因此其可以使用在水平框和旋转矩形框的场景上,其对于旋转框的定位具有较好的优化作用,特别是高纵横比的情况下。
[0162]
piou损失计算公式如下:
[0163][0164]
公式中,m为所有正样本的集合,|m|为正样本数,b表真实目标,b
′
表示目标框,b∩表示两者之间的交集区域,b∪分别表示两者之间并集区域,f
piou
函数的计算公式如下:
[0165][0166]
公式中,sb∩表示经损失函数内核函数处理后,目标b和目标框b
′
交集的像素量数,sb∪则表示两者并集的像素量数。
[0167]
(2)增加平衡因子
[0168]
fpn聚合相邻特征图层的方式公式如下:
[0169][0170]
其中,f
inner
是1*1的卷积操作实现通道匹配,f
upsample
代表2倍上采样操作实现特征图大小匹配,平衡因子在fpn中默认为1,我们基于统计的解决方法,利用数据集的统计信息计算的计算公式如下所示,其中n
pi+1
和n
pi
分别代表p
i+1
和pi层的数量:
[0171][0172]
dcpose算法中的框架主要包含三个模块:
[0173]
(1)姿态时间合并模块(ptm):定位关键点的搜索范围
[0174]
首先将前一帧、这一帧和后一帧的预测热图结合得到新的热图,根据时间分配权重,得到初始的权重,时间上更接近当前帧的帧显式分配更高的权重:
[0175][0176]
式中hi(p)、hi(c)和hi(n
*
)表示初始关键点热图,p、c和n
*
表示帧索引;
[0177]
利用神经网络对权值进行调整,对于每个关节,仅包括其自己特定时间信息的关键点热图,将15个关节点得到的热图进行拼接生成最后的热图:
[0178][0179]
式中,表示连接操作,上标j索引第j个关节,总共n个关节;
[0180]
将热图输入到3*3的残差模块中,得到合并后的热图:
[0181]
φi(p,c,n
*
)
→
φi(p,c,n
*
);
[0182]
所述态残差融合模块用于计算帧间关键点偏移,计算过程包括以下步骤:
[0183]
计算姿态残差,将计算得到的姿态残差用作时间相关的线索,计算姿态残差特征的公式如下:
[0184][0185][0186][0187][0188]
式中,表示原始姿态残差及其加权版本;
[0189]
将热图输入到3*3的残差模块中,得到合并后的热图:
[0190][0191]
所述姿态矫正模块用于对姿态进行矫正,矫正过程包括以下步骤:
[0192]
将合并的关节点热图和姿态残差特征两组特征合并,姿势校正网络用于细化初始关键点热图估计hi(c),产生调整后的最终关节点热图;
[0193][0194]
将合并的关节点热图φi(p,c,n
*
)和偏移量输入到卷积层,获得五组mask;通过可变形卷积v2网络在各种膨胀系数d下实现姿态校正模块;
[0195]
输出人i的姿势热图:
[0196]
(φi(p,c,n
*
),o
i,d
,m
i,d
)
→hi,d
(c)。
[0197]
步骤3,采用一种基于姿态点置信度的自适应姿态预筛选方法对人体姿态进行预筛选。
[0198]
具体地,基于姿态点置信度的自适应姿态预筛选方法如下:
[0199]
由于在姿态点提取过程中,某些无效的姿态点会造成识别模型工作量的加大以及造成相关姿态对于人体行为分析无效,因此采用一些方法来对人体姿态进行有效筛选是必要的,具体实施步骤如下:
[0200]
对于某个人体姿态p来说,当其所有关键点置信度为0的数目大于设定的阈值n时,即关键点缺失超过设定的阈值n时,忽略此人体姿态,我们将n定义为人体各个姿态点与脖子的欧氏距离与这些姿态点个数之比的最小值,n表示为完整表示这个人体姿态的需要的除脖子之外的最小姿态点个数,如下公式所示:
[0201][0202]
[0203]
式中,i(p
*
)为p
*
的指示函数,表示p
*
是否忽略;k为p
*
中关键点的个数;表示p
*
的第k个关键点是否缺失,缺失为1,否则为0;x1和y1分别为人体脖子姿态点的横坐标和纵坐标,xi和yi分别为人体姿态点的横、纵坐标,i=0,1,...,n-1。
[0204]
步骤4,使用一种基于双目摄像机的深度感知姿态点矫正算法来得到目标姿态点深度信息,根据所得深度信息来纠正人体姿态点二维坐标信息。具体地,基于双目摄像机的深度感知姿态点矫正算法如下:
[0205]
由于在拍摄过程中不能保证拍摄的是人体正面视角,不可避免地会造成姿态遮挡以及判决结果的不准确,因此我们可以利用得到的深度信息来确定人体的这种不对称性,然后求得人体偏转角,反推得到姿态点的正面视角二维坐标。
[0206]
该方法利用双目立体相机来估计人体骨架深度信息,如下公式所示:
[0207][0208]
上式中对应于第t帧图像中人体第i个姿态点与左摄像头连线在成像图中的点,类似地对应于第t帧图像中人体第i个姿态点与右摄像头连线在成像图中的点,b是为两个摄像头之间的距离,f为摄像头平面与成像平面之间的距离,是在第t帧图像中人体第i个姿态点的深度信息。
[0209]
通过人体两侧姿态点深度信息得到的不对称关系来确定出人体偏转角,如下公式所示:
[0210][0211][0212][0213][0214][0215]
上式中为第t帧图像中人体第i个姿态点的横坐标,为第t帧图像中人体第i个姿态点的纵坐标,为对应于在人体另一侧的横坐标,为对应于在人体另一侧的纵坐标,坐标,为偏转角对应的人体姿态点连接而成的封闭三角形的三边,为人体横截面与x轴的夹角,为摄像头与人体姿态点连线与y轴的夹角。
[0216]
通过所得偏转角来纠正人体姿态点二维坐标信息,如下公式所示:
[0217][0218]
[0219]
上式中为纠正后的人体姿态点横坐标,为纠正后的人体姿态点纵坐标,为纠正后的人体姿态点纵坐标,
[0220]
步骤5,使用一种基于时空卷积和基于注意的lstm的骨架行为识别模型对异常行为进行识别分析。具体地,基于时空卷积和基于注意的lstm的骨架行为识别模型如下:
[0221]
在st-cnn部分,基于输入数据执行时空卷积网络,通过该网络,可以得到每个短期骨架序列的时空关系,骨架序列被分成n个连续的组,这些组是网络的输入,我们把输入序列设为x=(x1,x2,...xn),xi代表在i阶段的人体关节数据,这是一个t
×m×
d维矩阵,d是人体关节数据的维度,因为输入是2d骨骼数据,所以我们将d设置为2,m表示骨架关节的数量,t表示骨架序列的帧数量。滤波器的维数为3
×3×
t,其中t是内核的时间深度,第一个池层的大小设置为3
×3×
1,其余为3
×3×
3,最后一个数字是时间深度,将其设置为1意味着在单个帧上共享,这将有助于保留时间功能。
[0222]
对于注意网络,我们首先将x重塑为另一个表示形式y=[y1,y2,...ym],其中yi∈r
nk
然后,我们采用前馈神经网络为每个关节生成注意权重ai,如下式所示:
[0223][0224]
其中σ(.)表示激活函数,wa和表示注意学习的加权矩阵和偏差项,注意被表示为s
att
=[s1,s2,...sm],以匹配输入x的形状,x∈rn×m×k,复制注意图k次,得到最终的注意图a∈rn×m×k,最后,我们通过元素相乘获得加权特征:
[0225]fn
=a
·
x;
[0226][0227]
式中fnn是前馈神经网络,是骨架序列的加权特征。
[0228]
在基于注意的lstm部分,我们通过局部卷积神经网络获得n个特征值,并将其设置为f=[f1,f2,...fn],并将n个特征用作att-lstm网络的输入,每次att-lstm接收到时空特征图时,att-lstm的前半部分是lstm网络,每个输入时刻都有一个高级特征图可用,组合lstm输出的所有时间特征图,可以用以下公式表示:
[0229]hi
=g(fi),i∈(1,n);
[0230]
q=[h1,h2,...,hn];
[0231]
α=softmax(w
t
tanh(q));
[0232]
r=qα
t
;
[0233]
式中,g函数表示lstm的特征提取过程,q是lstm输出的所有时间特征图的组合输出结果,使用时间序列的局部特征作为lstm的输入,lstm遗忘门意味着移除前一时间段中的无用段,并且输入门增加当前时间段中的有用段,lstm门表示骨架序列中的选择过程,保留有用的时间段特征,并丢弃无用的时间段特征,以获得骨架序列中最有用的计时特征,α表示lstm输出中n个特征的注意,w表示注意力学习的加权矩阵,r表示lstm输出时的加权注意力总和,在这个等式中,更重要的特征会引起更高的关注。
[0234]
为了使网络平均获得所有有用信息,att-lstm设计对所有输出进行平均,以获得作为网络后半部分的全局特征图,公式如下式所示:
[0235][0236]
式中,s是整个骨架序列的全局特征表示,h是lstm网络输出的时空特征图,k是输入骨架序列的人数。
[0237]
网络的第三部分通过softmax连接到完全连接的层,完全连接层的大小是要分类的类别的大小,全局特征映射被输入到零件中以获得最终行为分类的结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1