一种基于伪影噪声的深度伪造检测方法
1.本发明属于人工智能领域,具体涉及一种基于伪影噪声的深度伪造检测方法。
背景技术:
2.近年来,随着人工智能的逐步发展,深度伪造(deepfakes)技术得到迅速发展并广泛传播应用,成为了人工智能时代下不可避免的风险。深度伪造利用人工智能与生成式深度学习算法,能够逼真地模拟和伪造新闻文字、图像和音视频等多媒体内容。深度伪造因其具备高度的以假乱真性、广泛的适用性以及较低的使用门槛,能够轻易地被恶意用户利用,被用于制造和传播欺诈性极高的虚假信息等活动,其中以ai换脸(face-swap)最具代表性和危害性。ai换脸通过对人物肖像进行替换实现混淆视听,极大地侵害他人权益,甚至能够操纵社会舆论,为社会稳定和网络安全带来严峻挑战。因此,对于以ai换脸为首的相关深度伪造的检测技术受到了广泛研究。
3.在ai换脸深度伪造的拟真度已超越正常人类认知辨别能力且仍在不断高速发展的现状下,以及对ai换脸深度伪造的广泛恶意滥用的现实背景下,伪造检测技术有着广阔的发展前景和必要的现实需求。深度伪造检测领域的相关研究随2017年开源的ai换脸项目在互联网上的广泛传播而井喷式增长,针对伪造视频的检测一方面可以促进对生成对抗网络伪造痕迹以及合成视频伪造痕迹的进一步研究,另一方面也符合当下的大众对于鉴伪现实需求,利用该技术可以对互联网中的视频进行有针对性的检测,从而鉴别其中的虚假信息。
4.深度伪造检测技术主要通过特征提取、模型建立、检测分类等步骤,决定检测性能的关键就在于如何选择可以有效区分真假人脸的相关特征。目前主流的深度伪造检测技术主要是通过寻找伪造制品与真实图像或视频之间肉眼难以观察的像素分布,凭借机器学习来辨别像素级差异来实现检测,一般称这些差异为伪影(artifacts)或者噪声(noise),这些工作都是通过伪造图像与真实图像之间固有的纹理、色彩、亮度等差异有效定位噪声来检测模型的生成;这一方向上更进一步的工作发现实现深度伪造的生成模型会在其生成的内容上留下特定的噪声,这种噪声类似于指纹,不同种类的生成模型和训练生成模型时存在的微小不同都能导致图像中出现不同的指纹特征,因此可以通过对图像或视频生成模型的指纹识别判断是否为深度伪造生成的,鉴于这个特性,不少的工作会通过寻找图像中特定的噪声,以此来判断图像是否由相应的特定模型生成。但是该类方法的泛化性较差,由于无法确定伪造制品的具体生成方式,往往局限于检测特定模型生成的深度伪造;同时现有方法虽然试图寻找这些伪影、噪声和指纹,但是没有办法解释这些区分原始内容与伪造制品的关键特征。导致现有的检测方法存在通用性差,可解释性差,不能有效对各种不同类型的深度伪造图像进行检测等问题。
技术实现要素:
5.本发明的目的在于提供一种基于生成式网络提取噪声替代特征并进行深度伪造
识别的检测方法,本发明用一种通用方法去提取噪声,最终得出结论这些噪声本质上就是一种差异,同时通过深度学习技术去识别提取得到的差异,对差异直接进行分析特征与鉴别,实现对于深度伪造更精准的预测,并且泛化性更强;解决了针对ai换脸等视觉深度伪造检测方法对作为检测关键的伪影噪声的使用不够充分而导致的泛化性差、检测精度低的问题。
6.实现本发明目的的技术解决方案为:一种基于伪影噪声的深度伪造检测方法,包括如下步骤:
7.步骤(1):人脸提取:将读入的视频划分为帧,对每一帧图像f提取人脸部分,保存为only-face的人脸原始图像p;
8.步骤(2):dip生成:将步骤(1)提取出的人脸原始图像p输入dip生成模型,进行迭代拟合,获取新生成的带有特定噪声的图像p
*
;
9.步骤(3):噪声提取:将人脸原始图像p与步骤(2)dip生成的特定噪声图像p
*
作差得到伪影噪声d;
10.步骤(4):分类检测:将步骤(3)提取得到的伪影噪声d输入分类卷积神经网络进行训练,得到训练好的分类模型m;
11.步骤(5):模型测试推理:将测试视频按照步骤(1)-(3)相同的方法提取伪影噪声d,将得到的伪影噪声输入到步骤(4)训练好的分类模型m中,得到深度伪造检测的分类结果。
12.进一步的,步骤(2)具体为:
13.将提取出的only-face的人脸原始图像p缩放为固定尺寸(x,y),缩放后的每张图像p∈r
x
×y×3不经过人工加噪声直接输入dip生成模型;
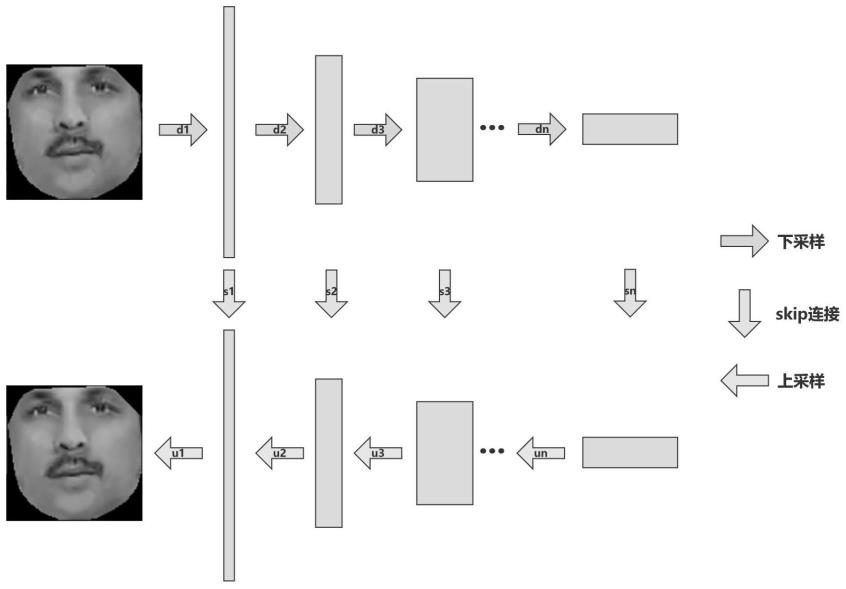
14.dip网络中主干部分使用hourglass结构,生成模型将图像经过多层的下采样和skip结构提取图像本身的先验特征进行编码,并通过上采样与卷积的解码器重建生成图像,具体的公式如下:
15.θ
*
=mine(f
θ
(z);p)
[0016][0017]
其中θ
*
是基于机初始化的网络参数,通过训练得来的参数最优解,p是输入的原始图像p,z是最初输入网络的一组固定的随机编码,与图像p相同大小,通道不一致,采用gan模型的思想,p
*
是最后的输出,即带有特定噪声的图像p
*
;
[0018]
在每次迭代过程中,评估p与p
*
的相似度并更新参数,生成带有特定噪音的图像p
*
代替无法获取的真实图像p0;
[0019]
按照学习率lr=0.01,使用生成的带有特定噪声的图像p
*
和only-face的人脸原始图像p的mse作为损失函数,在adam优化器下进行迭代拟合,获取新生成的带有特定噪声的图像,并对数据进行打包为npz文件包;
[0020]
进一步的,步骤(3)具体为:
[0021]
读取步骤(2)打包的npz文件包,读取时根据打包时的具体deepfake类别为每一个包分配标签,组织成类别-{原始图像,dip生成图像,图像编号}的字典;
[0022]
根据上述字典,将人脸原始图像p与dip生成带有特定噪声的图像p
*
作差得到噪声d(p,p
*
)作为特征x,用类别为每个图像的特征打上标签y,制作训练集、验证集和测试集,使
用dataset类创建数据集,并用dataloader进行封装。
[0023]
进一步的,步骤(4)具体为:
[0024]
将包含了提取的伪影噪声的训练集和验证集输入分类卷积神经网络进行训练,使用交叉熵损失函数,leaky relu作为激活函数,经过4层卷积获得一个8维的特征向量,放入分类器中得到结果,以lr=10-3
训练1000个epoch,得到训练好的分类模型。
[0025]
进一步的,步骤(5)具体为:
[0026]
将测试集样本特征按照步骤(4)训练集相同的处理,输入到训练好的分类模型中,得到深度伪造检测的分类结果,鉴别是否为伪造制品。
[0027]
本发明与现有技术相比,其显著优点在于:
[0028]
(1)本发明具体分析了伪造制品与真实内容,提出了伪造制品与真实内容的之间的差异即是一种伪影噪声的结论,为深度伪造检测任务主要应该研究分析的对象(即伪影噪声)提供了定性解释;同时,本方法也得出了这种作为差异的伪影噪声是进行分类鉴别的关键特征的结论;本方法提出的解释以及结论可推动在深度检测任务上进一步注重针对伪影噪声的研究。
[0029]
(2)本发明以伪影噪声是进行深度伪造检测的关键特征为出发点,提出了通过dip模型生成的图像作为基准图像,代替待测图像计算差异,提取伪影噪声的替代品实现精准深度伪造检测的方法,并证明了该方法的合理性;由于本发明输入分类模型的伪影噪声特征d是能够区分真伪的关键标识性特征,因此能够进一步提高分类模型的学习能力,提升深度伪造检测的精准性;同时本方法的检测模型不需要去寻找特定模型的特定差异,而是根据提取出差异特征判断,具有较强的泛化性。
附图说明
[0030]
图1是本发明的dip流程图。
[0031]
图2是本发明的dip下采样、skip连接和上采样结构图。
[0032]
图3是本发明的人脸原图、掩膜、生成图像和差异展示图。
[0033]
图4是本发明的分类检测模型。
[0034]
图5是本发明的总体流程图。
具体实施方式
[0035]
下面结合附图对本发明作进一步详细描述。
[0036]
本发明的主要思路:
[0037]
假定自然界中原始图像为p,那么当它转换到计算机中时就已经经过多次处理——包含raw图像的离散化、色彩插值和jpeg压缩等,这一系列的处理统称为δ。一张原始图像在经过处理后,呈现到用户面前时的图像已经为处理图像p
′
,处理图像可以视为原始图像添加处理,有p
′
=p+δ。人一般无法发现原始图像与处理图像的差异,因而可以自然推导得到二者相似度很高,有p
′
≈p。而它们的差异d(p
′
,p)则被定义为噪声或者指纹。一种最简单的噪声定义方法为处理图像与原始图像之差,即:d(p
′
,p)=p
′‑
p。
[0038]
在深度伪造领域,任何用于生成伪造制品的生成模型g(此处为广义定义,包含生成结果的一系列操作),都是想要生成与原始图像p更接近的结果pg。但是,由于模型自身的
限制(如卷积核的感受野大小受限、无法建立整体的像素间关联或者是卷积参数限制),必然会放弃一些不必要的信息,生成模型得到的pg只能无限接近p,有pg≈p,但又无法与p完全相同,于是,pg=g(ω)中也必然存在噪声,可以表示为d(pg,p)。
[0039]
对于不同的生成模型g1与g2,它们生成的伪造图像分别为p
g1
和p
g2
,由于其实现方式不同,它们产生的噪声也有偏差,且同一生成模型的噪声往往类似,因而这种噪声偏差可以视为识别模型的指纹,于是就有了
[0040]
本发明想要基于1~3中阐述的噪声差异进行深度伪造检测,但是要提取待测图像p
t
与其原始图像p的差异d(p
t
,p)是不现实的,因为无法获得未经任何处理的原始图像p,因此本发明选择使用差异的替代表示来代替无法获取的差异进行深度伪造检测。
[0041]
本发明将待测图像p
t
输入dip(deep image prior)生成模型,得到基准图像pd。dip本质上也是一种类似于深度伪造模型的生成模型,相应的,p
t
与pd之间也有其特定的差异d(p
t
,pd)。
[0042]
在相减的噪声定义下,待测图像p
t
与基准图像pd的差异可以表示为:待测图像与原始图像的差异d(pg,p)以及基准图像与原始图像的差异之差d(pd,p),即d(p
t
,pd)=d(p
t
,p)-d(pd,p)。而由于所有的pd都由我们已知的dip模型生成,所以本发明认为待测图像与基准图像的差异和待测图像与原始图像的差异呈正相关关系,即有d(p
t
,pd)~d(p
t
,p)。因而,得出结论:可以用d(p
t
,pd)代替d(p
t
,p),即通过dip可以提取噪声的替代表示。
[0043]
提取差异后,本方法使用d(p
t
,pd)作为分类所需的鉴别性特征,建立分类模型区分深度伪造与真实图像。
[0044]
实施例
[0045]
本发明的具体实施主要包含1)伪影噪声的抽取;2)根据伪影噪声区分真伪,具体步骤如下:
[0046]
步骤(1):对于一个待测的视频v,对读入的视频v划分为帧(为了提高检测效率,可以选取其中一定数量的帧图像),并使用python人脸识别库dlib提取帧图像f中的人脸轮廓,再根据人脸轮廓对原始帧图像f进行裁剪,保留人脸部分的内容,并且将裁剪后图像仍存在的非人脸部分全部掩盖,以此消除其他非相关区域形成的干扰,最终保存为only-face的图像p;
[0047]
步骤(2):将提取出的仅人脸图像原始图像p缩放为固定尺寸(x,y),如(256,256),缩放后的每张图像p∈r
x
×y×3不经过人工加噪声直接输入dip生成模型。dip网络中主干部分使用如附图1和附图2中所示的hourglass结构,该生成模型是一个如同gan的自编解码器,将图像经过多层的下采样和skip结构提取图像本身的先验特征进行编码,并通过上采样与卷积的解码器重建生成图像,具体的公式如下:
[0048]
θ
*
=mine(f
θ
(z);p)
[0049][0050]
其中θ
*
是基于随机初始化的网络参数,通过训练得来的参数最优解,p是我们输入的原始图像p,z是最初输入网络的一组固定的随机编码(与图像x0相同大小,通道不一致,采用gan模型的思想),p
*
是最后的输出,即我们所需要的生成图像p
*
。
[0051]
在每次迭代过程中,评估p与p
*
的相似度并更新参数,进一步生成与p相似的p
*
。经
过大量的迭代后dip可以生成与待测图像p一致的图像,但本发明的目的是生成带有特定噪音的图像p
*
代替无法获取的真实图像p0,通过d(p,p
*
)~d(p,p0)的关系来获取噪声,因此只需要迭代一定次数即可。
[0052]
按照学习率lr=0.01,使用生成图像p
*
和待测图像p的mse作为损失函数,在adam优化器下进行500次迭代拟合,获取新生成的带有特定噪声的图像,生成图像p
*
连同原图像p、人脸掩膜mask等根据具体的deepfake类型进行打包为npz文件保存用于深度伪造检测。对于每张图片都要执行上述操作;
[0053]
步骤(3):读取dip生成打包的npz文件包,读取时根据打包时的具体deepfake类别为每一个包(图像)分配标签,标签包含:deepfakes、neuraltextures、face2face、faceswap和real,组织成类别-{原始图像,dip生成图像,图像编号}的字典。根据上述字典,将待测图像p与dip生成图像p
*
作差得到噪声d(p,p
*
)作为特征x,用类别为每个图像的特征打上标签y,制作训练集、验证集和测试集,使用dataset类创建数据集,并用dataloader以batch_size=200进行封装。以上步骤(1)~(3)完成了本实验的第一个主要内容,完成了本发明中伪影噪声提取的工作
[0054]
步骤(4):将包含了提取的伪影噪声的训练集和验证集输入分类卷积神经网络进行训练,本发明核心思想就是想利用作为真伪图像核心差异的伪影噪声的直接分析实现高精度的深度伪造检测,使用交叉熵损失函数,leaky relu作为激活函数,经过4层卷积获得一个8维的特征向量,放入分类器中得到结果,以lr=10-3
训练1000个epoch。由于输入的噪声特征是能够区分真伪的关键标识性特征,因此能够进一步提高分类模型的学习能力。
[0055]
步骤(5):将测试集样本特征按照训练集相同的处理,输入到训练好的分类模型中,即可得到深度伪造检测的分类结果,鉴别是否为伪造制品。
[0056]
以上步骤(4)~(5)完成了本实验的第二个主要内容兼主要目标,通过对提取的伪影噪声直接进行特征工程和分类,完成了更高精度的判别。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1