基于riscv的指令访存地址自动计算方法及系统与流程
1.本发明涉及处理器技术领域,具体涉及一种基于riscv的指令访存地址自动计算方法及系统。
背景技术:
2.众所周知,vector扩展是riscv指令集最重要的扩展之一,它在人工智能方面发挥着明显的优势,由于vector指令的配置灵活,功能强大,导致他的实现非常复杂。
3.vector load/store指令主要用于向量寄存器和内存间的数据传送,主要分为unit-stride,strided和indexed三大类,其中每类还分别含有segment类型,再结合vlen,vsew,vlmul,nf等配置的影响,使得此类指令的访存地址计算变得非常困难。
4.因此本文根据不同配置和指令类型自动计算出指令所有元素的访存地址,提供一种高效灵活地计算算法方案,可作于基于riscv的 vector load/store指令访存地址计算标准模型,适用于验证平台驱动的模拟和检查器的构造当中。
技术实现要素:
5.针对现有技术的不足,本发明公开了一种基于riscv的指令访存地址自动计算方法及系统,用于解决现有技术手动计算,逻辑繁琐,控制复杂,且不易实现。实现代码量大,逻辑冗余率高,效率极低。不能根据指令配置进行自适应调整计算,可移植性差的问题。
6.本发明通过以下技术方案予以实现:
7.第一方面,本发明提供了一种基于riscv的指令访存地址自动计算方法,所述方法对unit-stride类型从基地址开始连续操作地址内存中的元素;对于strided类型首先操作基地址内存中的元素,后续依次操作由基地址加上rs2寄存器提供的偏移量增量的地址内存中的元素;对于indexed类型将基地址加上vs2提供的每个元素的偏移量,作为每个元素的操作地址,操作每个元素地址内存中的元素;对于 segment类型将内存中的多个连续字段移动到连续编号的向量寄存器中的元素上,或者将连续编号的向量寄存器中的元素移动到内存中的多个连续字段上,最后对每个类型的每个元素的地址进行自动计算。
8.更进一步的,所述方法中,向量load/store指令操作地址自动计算的方法包括以下步骤:
9.s1进行算法输入项;
10.s2进行算法准备项;
11.s3生成算法主体方案。
12.更进一步的,所述方法中,算法输入项包括:
13.向量寄存器最大位宽vlen,用来计算单个向量寄存器的元素个数;
14.32bit指令码,用于从指令码中获取指令本身的属性;
15.vtype寄存器,提供指令的sew,lmul等配置信息;
16.源寄存器操作数,用来获取操作地址的基址和偏移量,计算得到有效操作地址。
stride类型从基地址开始连续操作地址内存中的元素;对于strided类型首先操作基地址内存中的元素,后续依次操作由基地址加上rs2寄存器提供的偏移量增量的地址内存中的元素;对于indexed类型将基地址加上vs2提供的每个元素的偏移量,作为每个元素的操作地址,操作每个元素地址内存中的元素;对于segment 类型将内存中的多个连续字段移动到连续编号的向量寄存器中的元素上,或者将连续编号的向量寄存器中的元素移动到内存中的多个连续字段上,最后对每个类型的每个元素的地址进行自动计算。
35.本实施例根据不同配置和指令类型自动计算出指令所有元素的访存地址,提供一种高效灵活地计算算法方案,可作于基于riscv的 vector load/store指令访存地址计算标准模型,适用于验证平台驱动的模拟和检查器的构造当中。
36.本实施例高效灵活地计算算法方案,可作于基于riscv的vectorload/store指令访存地址计算标准模型,适用于验证平台驱动的模拟和检查器的构造当中。
37.实施例2
38.在具体实施层面,本实施例对vector load/store指令主要类型进行说明。
39.本实施例提供一种unit-stride类型,vector unit-stride操作,从基地址开始连续操作地址内存中的元素如图1所示。
40.如图1所述,vle8操作会依次将内存地址 0x8000,0x8001,0x8002,
…
,0x800f中的元素数据分别加载到向量寄存器vd的元素位置e0,e1,e2,
…
,e15上。
41.本实施例提供一种strided类型,vector strided操作,首先操作基地址内存中的元素,后续依次操作由基地址加上rs2寄存器提供的偏移量增量的地址内存中的元素。
42.如上2所示,vlse8操作会将内存地址0x8000中的元素数据分别加载到向量寄存器vd的元素位置e0上,将地址0x8002(0x8000+0x2) 中元素加载到e1上,将地址0x8004(0x8002+0x2)中元素加载到e2上,以此类推。
43.本实施例提供一种indexed类型,vector indexed操作,将基地址加上vs2提供的每个元素的偏移量,作为每个元素的操作地址,从而操作每个元素地址内存中的元素。
44.如图3所示,vlxei8操作会将内存地址0x8001(0x8000+0x1)中的元素数据分别加载到向量寄存器vd的元素位置e0上,将地址 0x8002(0x8000+0x2)中元素加载到e1上,将地址0x8004(0x8000+0x4) 中元素加载到e2上,将地址0x8007(0x8000+0x7)中元素加载到e3上,以此类推。
45.本实施例提供一种segment类型,segment操作将内存中的多个连续字段移动到连续编号的向量寄存器中的元素上,或者将连续编号的向量寄存器中的元素移动到内存中的多个连续字段上。
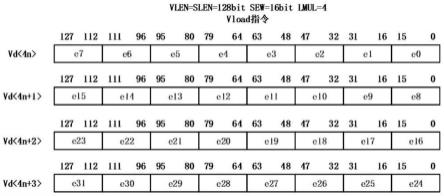
46.如图4所示,unit-stride segment指令vlseg4e8操作会将内存地址 0x8000~0x8003中的数据分别加载到向量寄存器vd~vd+3的元素位置 e0上,将地址0x8001~0x8004中数据加载到vd~vd+3的e1上,将地址0x8002~0x8005中数据加载到vd~vd+3的e2上,以此类推。
47.实施例3
48.在具体实施层面,本实施例提供了一种向量load/store指令操作地址自动计算算法,具体如下:
49.本实施例提供算法输入项:
50.a.向量寄存器最大位宽vlen。
51.用来计算单个向量寄存器的元素个数等。
52.b.32bit指令码。
53.我们可以从指令码中获取指令本身的属性,例如指令操作类型,指令操作数据宽度,指令操作寄存器编号等信息。
54.c.vtype寄存器
55.提供指令的sew(用来设置单个操作元素的位宽),lmul(用来设置多个寄存器组成的每个寄存器组中寄存器的个数)等配置信息。
56.d.源寄存器操作数
57.用来获取操作地址的基址和偏移量,计算得到有效操作地址。
58.本实施例提供算法准备项
59.[0060][0061]
如图5所示,本实施例算法主体方案,eid为每个元素的id号,单个寄存器元素编号为从低位到高位,组寄存器元素编号从连续寄存器号的低到高进行。
[0062]
本实施例算法对不同指令类型(unit-stride,strided,indexed, whole-register,segment等),不同指令配置(vsew,vlmul,nf等)均可以做到自动计算元素地址,而不需要更改任何算法本身。
[0063]
本实施例对于unit_stride指令(whole-register属于unit-stride的一种特殊类型),每个元素的地址自动计算算法为:
[0064]
vec_el_addr=rs1d+ (eid%vec_memdata_vlmax_sreg)*vec_memdata_el_size_byte*vec_nf+ ((eid/vec_memdata_vlmax_sreg)%vec_reg_num_sgrp)* vec_memdata_el_size_byte*vec_nf*vec_memdata_vlmax_sreg+ ((eid/vec_memdata_vlmax_sreg)/vec_reg_num_sgrp)* vec_memdata_el_size_byte;
[0065]
本实施例对于stride指令,每个元素的地址自动计算算法为:
[0066]
vec_el_addr=rs1d+(eid%vec_memdata_vlmax_sreg)*rs2d+ ((eid/vec_memdata_vlmax_sreg)%vec_reg_num_sgrp)*rs2d*vec_memdata _vlmax_sreg+((eid/vec_memdata_vlmax_sreg)/vec_reg_num_sgrp)* vec_memdata_el_size_byte;
[0067]
本实施例对于indexed指令,每个元素的地址自动计算算法为:
[0068]
vec_el_addr=rs1d+ ((vs2d[((eid%(vec_memdata_vlmax_sreg*vec_reg_num_sgrp))/vec_mema ddr_vlmax_sreg)]》》((eid%vec_vlmax_small)*vec_memaddr_el_size_bit)) &{vec_memaddr_el_size_bit{1’b1}})+ (eid/vec_memdata_vlmax_sreg/vec_reg_num_sgrp)*vec_memaddr_el_size _byte;
[0069]
本实施例提供一种算法主体实现,含伪码,使用systemverilog 语言,本实施例的输出结果为三维数组vreg_addr,第一维表示操作的每个向量寄存器编号(编号从小到大),第二维表示每个寄存器的每个元素的编号(编号从低到高),第三维表示每个元素的64bit宽度操作地址,这样从这个算法,我们可以得到不同指令类型,不同指令配置的所有元素的操作地址。
[0070]
实施例4
[0071]
在其他层面,本实施例一种基于riscv的指令访存地址自动计算系统,包括存储器以及存储在所述存储器中的指令,用于实现基于 riscv的指令访存地址自动计算方法。
[0072]
综上,本发明自动计算,逻辑清晰,控制简单,且容易实现。实现代码量小,逻辑简明,效率极高。不需要算法自身任何的更改,便可对不同配置的指令操作地址进行自动计算,可移植性高。高效灵活地计算算法方案,可作于基于riscv的vector load/store指令访存地址计算标准模型,适用于验证平台驱动的模拟和检查器的构造当中。
[0073]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1