一种基于数据驱动的机电设备寿命预测方法及系统
1.本发明涉及机电设备寿命预测技术领域,特别是涉及一种基于数据驱动的机电设备寿命预测方法及系统。
背景技术:
2.数据驱动是相对于模型驱动而言的数据处理分析方法。所谓模型驱动是指构建出模型,利用采集到的数据,根据已构建出的模型分析对象,这种方式有赖于构建出的模型的准确性。与之不同,数据驱动分析方法下,并非构建出一个固定不变的模型,而是利用采集到的数据,对模型进行训练,使模型向数据贴合。
3.数据驱动的分析方法对于数据信息具有更高的依赖性,但是对数据的适应性也更高,在一些具有明显趋势以及规律波动的数据分析中,数据驱动的分析方法具有明显优势。
4.机电设备的寿命预测一直是一个研究热点。现有技术提供了一些基于数据驱动的机电寿命的分析方法,这些方法主要从如何挖掘数据信息的角度着手的,例如增加模型深度,使用不同的特征提取方法等,然后,数据驱动的分析方法本身的一个问题是对数据的依赖性太高,如何使数据随机而又能够包含尽可能多的实际情况,是在数据分析时需要解决的问题。
技术实现要素:
5.基于此,有必要针对上述的问题,提供一种基于数据驱动的机电设备寿命预测方法及系统。
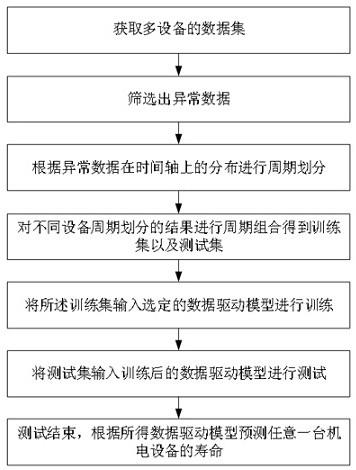
6.本发明实施例是这样实现的,一种基于数据驱动的机电设备寿命预测方法,所述基于数据驱动的机电设备寿命预测方法包括:获取多设备的数据集;筛选出异常数据;根据异常数据在时间轴上的分布进行周期划分;对不同设备周期划分的结果进行周期组合得到训练集以及测试集;将所述训练集输入选定的数据驱动模型进行训练;将测试集输入训练后的数据驱动模型进行测试;测试结束,根据所得数据驱动模型预测任意一台机电设备的寿命。
7.在其中一个实施例中,本发明提供了一种基于数据驱动的机电设备寿命预测系统,所述基于数据驱动的机电设备寿命预测系统包括:数据采集装置,所述数据采集装置与各设备连接,用于各设备运行参数的实时采集;以及计算机设备,所述计算机设备与所述数据采集装置连接,用于执行如本发明所述的基于数据驱动的机电设备寿命预测方法。
8.本发明实施例提供的基于数据驱动的机电设备寿命预测方法通过异常数据的筛
选,将数据进行划分,而后将多设备数据的划分结果进行重新组合,使异常数据在组合所得的数据中分布更为均匀,提高了有效数据在训练集以及测试集中的占比,使训练以及测试的过程能够更好地针对异常情况,避免了数据驱动模型训练集与测试集存在较大差异导致的结果偏离较大的问题,提高了模型对真实情况的适应性,可以降低训练及测试时对数据量的要求。
附图说明
9.图1为一个实施例提供的基于数据驱动的机电设备寿命预测方法的流程图;图2为一个实施例提供的计算机设备的内部结构框图。
具体实施方式
10.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
11.可以理解,本发明所使用的术语“第一”、“第二”等可在本文中用于描述各种元件,但除非特别说明,这些元件不受这些术语限制。这些术语仅用于将第一个元件与另一个元件区分。举例来说,在不脱离本发明的范围的情况下,可以将第一xx脚本称为第二xx脚本,且类似地,可将第二xx脚本称为第一xx脚本。
12.如图1所示,在一个实施例中,提出了一种基于数据驱动的机电设备寿命预测方法,所述基于数据驱动的机电设备寿命预测方法包括:获取多设备的数据集;筛选出异常数据;根据异常数据在时间轴上的分布进行周期划分;对不同设备周期划分的结果进行周期组合得到训练集以及测试集;将所述训练集输入选定的数据驱动模型进行训练;将测试集输入训练后的数据驱动模型进行测试;测试结束,根据所得数据驱动模型预测任意一台机电设备的寿命。
13.在本实施例中,机电设备包括但不限于生产制造中的机床(车床、铣床等)等设备,温控系统中的风机、水泵等设备,还可以包括其它类型的专用或者通用设备。这些设备均存在使用年限,但是使用年限与具体的使用情况以及维护情况有关,本发明即用于这些设备使用过程中的寿命预测,从而实现设备的数字化管理维护。
14.在本实施例中,这里的多设备是指同型号的多台设备,对于单一设备的寿命预测往往因为数据量不足准确性很低,本发明通过综合多设备的数据可以提高预测的准确性。需要说明的是,设备寿命可以通过其使用时的具体工作参数进行衡量,例如随着使用年限的增加,设备的精度下降,当精度下降到无法修正的程度时,可以认为设备报废。实际的寿命预测即是预测一些关键参数随时间的变化情况,预估设备的报废时间,对每个参数可以单独预测,本发明以多设备就同一参数的变化进行预设来说明。需要说明的是,这里的数据集是多台设备的某一参数的值随时间变化的情况,可以是连续采样也可以是离散采集,不同的采集方式可以得到不同的数据类型。
15.在本实施例中,异常数据是指波动较大的数据,本发明给出了异常数据具体如何确定的方法。在本实施例中,由于所采集的数据是随时间分布的,可以将时间轴进行周期划分,则每一个周期对应一部分数据,可以将每个周期对应的数据作为一个数据整体输入模型进行训练或者测试。在本实施例中,进行周期划分之后还包括不同设备间数据的重新组合以得到训练集以及测试集。
16.在本实施例中,对于数据驱动模型的训练以及测试过程可以参考现有技术,本发明不涉及此部分内容的改进。测试结束后,根据设备当前的运行参数可以实现设备寿命的预测。
17.本发明实施例提供的基于数据驱动的机电设备寿命预测方法通过异常数据的筛选,将数据进行划分,而后将多设备数据的划分结果进行重新组合,使异常数据在组合所得的数据中分布更为均匀,提高了有效数据在训练集以及测试集中的占比,使训练以及测试的过程能够更好地针对异常情况,避免了数据驱动模型训练集与测试集存在较大差异导致的结果偏离较大的问题,提高了模型对真实情况的适应性,可以降低训练及测试时对数据量的要求。
18.作为本发明的一个可选实施例,所述确定一个筛选范围,根据确定出的筛选范围筛选出异常数据,包括:确定数据类型,所述数据类型包括连续型以及离散型;对于连续型,根据均值回归确定筛选出异常数据;对于离散型,根据线性回归筛选出异常数据。
19.在本实施例中,对于不同类型的数据采用不同的方法找出异常数据。
20.作为本发明的一个可选实施例,所述根据均值回归筛选出异常数据,包括:选定时间窗宽度,在时间轴上以时间窗宽度为步距移动时间窗,计算时间窗每次移动所在位置连续型数据的积分中值,得到连接型数据的系列积分中值;以时间窗每次移动所在位置的中点为横坐标,以对应连续型数据的积分中值为纵坐标,得到系列中值点;由系列中值点确定一条贝塞尔曲线;将所述贝塞尔曲线向上侧平移第一距离得到上边界,将所述贝塞尔曲线向下侧平移第二距离得到下边界;将位于所述上边界与所述下边界所夹范围之外的数据标记为异常数据。
21.在本实施例中,可以理解,这时的时间窗是用于数据筛选的一个时间窗口的长度,本质是一个特定的时间长度,每次处理时仅对该段时间内的数据进行处理,故称之为时间窗。在本实施例中,在时间轴上以时间窗宽度为步距移动时间窗,则相邻两个时间窗的距离为0,时间轴被时间窗划分为若干个区域。
22.在本实施例中,积分中值由下式计算:其中,为积分中值,a、b分别为时间窗的起点以及终点横坐标,b-a为时间
窗的宽度。
23.在本实施例中,每个时间窗可以计算得到一个积分中值,以时间窗每次移动所在位置的中点为横坐标,以对应连续型数据的积分中值为纵坐标,得到系列中值点。
24.在本实施例中,由系列中值点可以确定一条贝塞尔曲线,对于其计算方法可以参考现有技术,本发明实施例对此不再赘述。在此基础上,通过将贝塞尔曲线分别向上下两侧平移可以得到上边界以及下边界,超出上边界与下边界所夹区域的数据标记为异常数据。异常数据是相对的,对于数据驱动模型,异常数据是影响数据驱动模型参数的主要数据,本发明并不涉及对异常数据本身的改变,而是通过将异常数据进行拆分重新组合得到训练集以及测试集,以提高训练集以及测试集中数据对于模型训练以及测试的有效性。
25.作为本发明的一个可选实施例,第一距离与第二距离比值的范围为0.8~1.4,且异常数据对应的时间长度占总时间长度的比例为5%~15%。
26.在本实施例中,通过选定第一距离与第二距离的比值以及异常数据对应时间长度占总时间长度的比例,可以得到计算得到第一距离与第二距离各自的值。例如取第一距离与第二距离的比值为1,异常数据对应的时间长度占总时间长度的比例取10%,同时向上下两侧移动贝塞尔曲线,实时计算位于上边界与下边界之外的数据对应的时间长度占总时间长度的比例,直到该比例从100%降至10%时停止,得到上边界与下边界,并可以筛选出异常数据。
27.作为本发明的一个可选实施例,所述根据线性回归筛选出异常数据,包括:将离散型数据划分为若干个组;计算每一个组内所有离散点的回归直线;分别计算每个组内各个离散点到回归直线的平均距离;对于任意一个离散点,若其到对应回归直线的距离达到所在组内各离散点到回归直线平均距离的1.5倍,则将之记为异常数据。
28.在本实施例中,这里的分组是将相邻的若干个离散型数据作为一组进行划分的,划分的主要目的是将变化较大的数据分离出来,使这些对数据驱动模型具有重要影响的数据更为均匀地分布于训练集以及测试集中。
29.在本实施例中,对于n个系列离散点(xi,yi),i为正整数且1≤i≤n,设其回归方程为,有:其中,为系列离散点横坐标的均值,为系列离散点纵坐标的均值。
30.由点与直线的公式可以计算每个组内各个离散点到回归直线的距离,并可以计算
平均距离。
31.作为本发明的一个可选实施例,所述将离散型数据划分为若干个组,包括:计算所有相邻两个离散型数据所在直线与时间轴正方向的夹角的绝对值;对于任意一个离散型数据,若其与前一个离散型数据所确定的直线与时间轴正方向的夹角、与后一个离散型数据所确定的直线与时间轴正方向的夹角均大于设定阈值,则将该离散型数据标记为独立数据;对于任意一个离散型数据,若其与前一个离散型数据所确定的直线与时间轴正方向的夹角、与后一个离散型数据所确定的直线与时间轴正方向的夹角有且仅有一个大于设定阈值,则将所确定的直线与时间轴正方向的夹角大于设定阈值的对应两个离散型数据标记为边界数据;根据设定的每组元素的上限值、所述独立数据以及所述边界数据将离散型数据划分为若干个组。
32.在本实施例中,这里的设定阀值可以视离散型数据的变化情况由用户自行设定,例如可以设定为70度、85度等。
33.在本实施例中,设定每组元素的上限值为m(视数据量的大小,m可以取总离散型数据的百万分之一,万分之一等),沿着时间轴的方向,每m个离散型数据作为一个组,每遇到边界数据,则提前结束一组,使边界数据作为下一组的起始数据,每遇到独立数据,则将独立数据本身作为一个独立的组。由此可以将所有离散型数据进行分组。
34.作为本发明的一个可选实施例,所述根据异常数据在时间轴上的分布进行周期划分,包括:对于连续型数据:选取时间跨度最长的一个异常数据对应的时间作为周期初始值;根据所述周期初始值将连续型数据进行周期划分;判断划分所得的各个周期时间段内,异常数据是否唯一,若否,取周期初始值的1/n重新进行划分直至划分所得的各个周期时间段内异常数据唯一,若是,完成周期划分;对于离散型数据:选取时间跨度最长的若干个相邻异常数据对应的时间作为周期初始值;根据所述周期初始值将离散型数据进行周期划分;判断划分所得的各个周期时间段内,异常数据是否唯一,若否,取周期初始值的1/n重新进行划分直至划分所得的各个周期时间段内异常数据唯一,若是,完成周期划分;其中:n为周期划分的次数。
35.在本实施例中,选取时间跨度最长的一个异常数据对应的时间作为周期初始值,需要理解,由于数据是连续型的,这里的一个是指超出边界范围的部分连续数据构成的一段曲线(该段曲线除端点外完全位于边界区域外,且该段曲线的两个端点在边界线上),而不是一个数据点,这里是将连续的部分异常数据点作为一个整体来描述,故每个异常数据(曲线段)都对应一个时间跨度。
36.在本实施例中,根据所述周期初始值将连续型数据进行周期划分,可以理解,将选定的时间跨度最大的异常数据对应的时间作为周期初始值,并使该具有最大时间跨度的异常数据处于一个完整的周期初始值内,以该具有最大时间跨度的异常数据的横轴中点为中
心,向横轴左右两侧扩展进行周期划分。
37.若任意一个划分所得的时间周期内异常数据不唯一,则通过缩小周期初始值的方式重新划分,直至每个周期内最多有一个异常数据。可以理解,对于没有非异常数据同样进行了划分,划分所得的每个周期内,可以全部为异常数据,也可以没有部分为异常数据,部分为非异常数据,还可以全部为非异常数据。
38.对于离散型数据,与连续型数据的不同仅在于,周期初始值的确定是通过选取时间跨度最长的若干个相邻异常数据确定的,例如点(x3,y3)、(x4,y4)以及(x5,y5)为三个具有最长时间跨度的连续的异常离散点,三个点对应的横轴时间跨度(即x5‑ꢀ
x3)为8个时间单位(分、秒、小时、天等,根据不同参数选用的时间单位确定),则周期初始值选定为8个时间单位。
39.作为本发明的一个可选实施例,所述对不同设备周期划分的结果进行周期组合得到训练集以及测试集,包括:对同一型号的不同设备的同一参数,判断各设备的异常数据在时间轴上是否存在重叠,若是,将重叠的异常数据的一半划分为训练子集一,另一半划分为测试子集一;对于非重叠部分的异常数据,根据其在时间轴上的先后顺序,奇数划分为训练子集二,偶数划分为测试子集二;对于非异常数据,根据其在时间轴上的先后顺序,奇数划分为训练子集三,偶数划分为测试子集三;将训练子集一、训练子集二以及训练子集三进行组合得到训练集;将测试子集一、测试子集二以及测试子集三进行组合得到测试集。
40.在本实施例中,可以理解,将不同设备的同一参数均置于同一时间轴上进行处理,对于连续型数据,这里的重叠是指周期划分之后的曲线段存在相交的情况,则两个周期对应的数据存在重叠(需要注意,不同设备的同一参数的周期长度一般不相同),将重叠的数据按其所在的周期进行划分。对于离散型数据,仅当两个数据点重合时才判断为重叠。
41.在本实施例中,组合得到训练集或者组合得到测试集,是将多个子集进行合并的过程,对数据本身并没有改动。
42.作为本发明的一个可选实施例,所述数据驱动模型选自神经网络模型、elm算法、支持向量机以及bk模型中的一种。
43.在本实施例中,神经网络模型可以选用卷积神经网络(convolutional neural networks,cnn)、循环神经网络(recurrent neural network,rnn)等;elm算法即extreme learning machine,极限学习机算法;bk(bp-knn)模型是bp神经网络与k-最近邻算法(knn)相耦合所建立的一种数据驱动模型。本发明不涉及模型本身的改进,对于各模型的训练以及测试的具体步骤,可以参考现有技术。
44.需要说明的是,当数据驱动模型仅能处理离散型数据时,对于本技术中的连续型数据,可以在处理完成后,通过密集采样的方式得到能够输入模型的数据点,采样频率可以选用常用的4.2 mhz、5.5 mhz、5.6mhz等,通常低于4ghz均可。
45.本发明实施例还提供了一种基于数据驱动的机电设备寿命预测系统,所述基于数据驱动的机电设备寿命预测系统包括:数据采集装置,所述数据采集装置与各设备连接,用于各设备运行参数的实时采
集;以及计算机设备,所述计算机设备与所述数据采集装置连接,用于执行如本发明所述的基于数据驱动的机电设备寿命预测方法。
46.在本实施例中,对于机电设备本身记录的数据,这里的数据采集装置可以采用传输线替代,由机电设备直接输出其记录的数据即可;对于机电设备无法直接记录的数据,可以通过相应的传感器进行采集,例如采用温度传感器采集设备的温度数据等。
47.本发明实施例提供的基于数据驱动的机电设备寿命预测系统通过异常数据的筛选,将数据进行划分,而后将多设备数据的划分结果进行重新组合,使异常数据在组合所得的数据中分布更为均匀,提高了有效数据在训练集以及测试集中的占比,使训练以及测试的过程能够更好地针对异常情况,避免了数据驱动模型训练集与测试集存在较大差异导致的结果偏离较大的问题,提高了模型对真实情况的适应性,可以降低训练及测试时对数据量的要求。
48.图2示出了一个实施例中计算机设备的内部结构图。该计算机设备具体可以是本发明实施例提供的基于数据驱动的机电设备寿命预测系统中的计算机设备。如图2所示,该计算机设备包括该计算机设备包括通过系统总线连接的处理器、存储器、网络接口、输入装置和显示屏。其中,存储器包括非易失性存储介质和内存储器。该计算机设备的非易失性存储介质存储有操作系统,还可存储有计算机程序,该计算机程序被处理器执行时,可使得处理器实现本发明实施例提供的基于数据驱动的机电设备寿命预测方法。该内存储器中也可储存有计算机程序,该计算机程序被处理器执行时,可使得处理器执行本发明实施例提供的基于数据驱动的机电设备寿命预测方法。计算机设备的显示屏可以是液晶显示屏或者电子墨水显示屏,计算机设备的输入装置可以是显示屏上覆盖的触摸层,也可以是计算机设备外壳上设置的按键、轨迹球或触控板,还可以是外接的键盘、触控板或鼠标等。
49.本领域技术人员可以理解,图2中示出的结构,仅仅是与本发明方案相关的部分结构的框图,并不构成对本发明方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
50.在一个实施例中,提出了一种计算机设备,所述计算机设备包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现以下步骤:获取多设备的数据集;筛选出异常数据;根据异常数据在时间轴上的分布进行周期划分;对不同设备周期划分的结果进行周期组合得到训练集以及测试集;将所述训练集输入选定的数据驱动模型进行训练;将测试集输入训练后的数据驱动模型进行测试;测试结束,根据所得数据驱动模型预测任意一台机电设备的寿命。
51.在一个实施例中,提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,计算机程序被处理器执行时,使得处理器执行以下步骤:获取多设备的数据集;筛选出异常数据;
根据异常数据在时间轴上的分布进行周期划分;对不同设备周期划分的结果进行周期组合得到训练集以及测试集;将所述训练集输入选定的数据驱动模型进行训练;将测试集输入训练后的数据驱动模型进行测试;测试结束,根据所得数据驱动模型预测任意一台机电设备的寿命。
52.应该理解的是,虽然本发明各实施例的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,各实施例中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一非易失性计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,本发明所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(synchlink) dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
53.以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
54.以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1