制冷机房能效优化方法、系统、终端及介质与流程
1.本发明涉及高效制冷机房能效优化技术领域,具体地,涉及一种基于数字孪生和智能体深度强化学习的制冷机房能效优化方法、系统、终端及介质,适用于工业企业或建筑等的高效制冷机房能效优化。
背景技术:
2.能效优化算法的历史悠久,主要分为基于机理模型的能效优化算法、基于数据驱动的能效优化算法等。基于机理模型的能效优化算法由于很难对大型高效制冷机房建立精确的数学模型,因此不适用于大规模复杂的制冷机房系统。目前,随着大数据时代的到来,基于数据驱动的能效优化算法成为技术发展的主流方向,它通过对系统运行中产生的大量历史数据进行分析处理和建模,从而识别能效最优的运行策略。
3.鉴于许多高能耗企业的制冷机房的能耗占企业总能耗的近50%,因此,高效制冷机房的能效优化越发重要。近年来,深度强化学习正成为一种领先的策略优化方法,各种深度强化学习算法如深度q学习网络(dqn)、近端策略优化算法(ppo)、优势演员评论算法(a2c)、pdpg和ddpg等在众多任务上取得了令人惊喜的成果,尤其是在ai玩游戏、下围棋等领域。然而上述的方法一般基于一种假设:智能体策略空间中的各种动作可以自由尝试,以便获取足够的《状态、行动、奖励》数据序列;各种序列有明确的开始和结束定义,且潜在收益比较明确。然而,在高能耗工厂的实际环境中,由于不同的生产可靠性和工艺过程要求,导致上述假设在大多数实际工业场景中都不成立。因此,当前上述先进的深度强化学习算法还无法有效地应用到高能耗企业制冷机房的实际能效优化过程中,少数的应用由于数据多样性的不足导致准确率无法满足工程使用要求,大大地制约了深度强化学习方法的推广和工程化。
技术实现要素:
4.本发明针对现有技术中存在的上述不足,提供了一种制冷机房能效优化方法、系统、终端及介质。
5.根据本发明的一个方面,提供了一种制冷机房能效优化方法,包括:
6.构建物理世界制冷机房所对应的机房数字孪生模型,并基于物理世界制冷机房的状态数据在所述机房数字孪生模型上的可视化,对状态数据和优化控制行动进行细粒度表示,以便准确记录采取的行动和环境状态变化,生成优化策略行动轨迹;所述行动轨迹包括多组按照时间顺序执行的《状态、行动、奖励》数据序列;
7.构建近端策略优化深度强化学习模型,并利用所述行动轨迹对所述近端策略优化深度强化学习模型进行训练,得到制冷机房能效优化智能体模型;
8.基于所述制冷机房能效优化智能体模型,将待处理的物理世界制冷机房的状态数据作为输入,得到对应的推荐行动数据,用于对制冷机房能效进行优化。
9.可选地,所述构建物理世界制冷机房所对应的机房数字孪生模型,包括:
10.定义物理世界制冷机房的物理系统;
11.定义每一个所述物理系统的主要状态表征;
12.对所述主要状态表征进行数据采集;
13.基于采集的所述主要状态表征的相应数据,定义每一个所述物理系统的信息虚体,所述信息虚体包括状态向量和行动向量;其中,所述状态向量由所述实时感知的主要状态表征数据组成,所述行动向量由实现每一个所述物理系统可执行的控制行动列表组成;
14.构建所述信息虚体的可视化仿真控制界面,得到机房数字孪生模型;
15.所述生成优化策略行动轨迹,包括:
16.通过所述机房数字孪生模型,执行一对当前状态向量细粒度进行优化控制的行动,并通过物理系统获得行动后的能效值和执行后的状态向量;
17.重复上一个步骤,生成《当前状态、行动、奖励、下一状态》数据序列,并将所述数据序列按照时间顺序排列生成行动轨迹。
18.可选地,还包括:
19.所述物理世界高效制冷机房的物理系统,包括:冷机系统、冷却侧系统、一次侧系统和二次侧系统;
20.所述主要状态表征,包括:开关状态、负荷率、出水温度、进水温度、功率和水流量;
21.所述状态向量,包括:开关状态、负荷率、出水温度、进水温度、功率和水流量;
22.所述行动向量,包括:冷却塔运行台数+/-、冷却塔出水温度+/-、冷却塔风机频率+/-、冷却泵台数+/-和/或冷却泵温差+/-;
23.所述执行一对当前状态向量细粒度进行优化控制的行动,包括:专家系统通过所述信息虚体的可视化仿真控制界面,基于领域知识,执行对当前状态向量细粒度的优化控制。
24.可选地,所述构建近端策略优化深度强化学习模型,并利用所述行动轨迹对所述近端策略优化深度强化学习模型进行训练,得到制冷机房能效优化智能体模型,包括:
25.采用标准的n层全连接神经网络搭建所述近端策略优化深度强化学习模型,包括:输入层、多个隐含层和输出层,利用所述行动轨迹对所述近端策略优化深度强化学习模型进行训练;其中:
26.所述输入层用于输入所述行动轨迹中的状态向量数据或状态向量数据的子集;
27.多个所述隐含层用于将输入数据的特征,抽象到另一个维度空间,可展现更抽象的特征;
28.所述输出层采用softmax激活函数作为分类器,用于输出优化策略行动轨迹中每个行动的概率;
29.对所述制冷机房能效优化智能体模型的目标函数进行设计,完成对所述制冷机房能效优化智能体模型的构建。
30.可选地,还包括:
31.所述输入层的输入宽度等于输入的状态向量数据的长度;所述输入层的输出宽度为输入宽度的任意倍数;
32.所述近端策略优化深度强化学习模型的第n层神经网络的输出宽度为行动向量数据的长度。
33.可选地,所述制冷机房能效优化智能体模型采用基于策略对的深度强化学习模型,其目标函数的设计方法,包括:
[0034][0035]
或者
[0036][0037]
其中,n为第n条执行轨迹,为近端策略优化ppo算法目标函数,tn为第n条执行轨迹的长度,π
θ
为当前优化策略函数,π
θ
′
为原优化策略函数,a
t
为第t 步所执行的行动,s
t
为第t步的状态,θ为当前优化策略,θ
′
为原优化策略,λ为可调节的算法超参数,kl为kl散度,为近端策略优化ppo2算法目标函数,ε为任意的较小值,为算法的可训练超参数;函数的含义是当则结果为1+ε;当则结果为1-ε;否则为
[0038]
为与策略θ
′
相关的优势函数,其定义如下所示:
[0039][0040]
其中,为状态的状态价值函数值,可由单独的神经网络获得;γ
t
′‑
t
为衰减系数,为算法的可训练超参数,为t
′
时刻的奖励值;
[0041]
公式(1)中的λ和公式(3)中的γ分别采用ppo算法中的缺省方式确定;
[0042][0043]
其中,cop为能效比,q为总系统总瞬时冷量,p为总系统总功率,f为总管瞬时流量,δt为回水总管水温与供水总管水温的差值,k为系数。
[0044]
根据本发明的另一个方面,提供了一种制冷机房能效优化系统,包括:
[0045]
机房数字孪生模型模块,该模块构建物理世界制冷机房所对应的机房数字孪生模型,并基于物理世界制冷机房的状态数据在所述机房数字孪生模型上的可视化,对状态数据和优化控制行动进行细粒度表示,以便准确记录采取的行动和环境状态变化,生成优化策略行动轨迹;所述行动轨迹包括多组按照时间顺序执行的《状态、行动、奖励》 数据序列;;
[0046]
制冷机房能效优化智能体模型模块,该模块构建近端策略优化深度强化学习模型,并利用所述行动轨迹对所述近端策略优化深度强化学习模型进行训练,得到制冷机房能效优化智能体模型;基于所述制冷机房能效优化智能体模型,将待处理的物理世界制冷机房的状态数据作为输入,得到对应的推荐行动数据,用于对制冷机房能效进行优化。
[0047]
可选地,所述近端策略优化深度强化学习模型,采用标准的n层全连接神经网络,包括:
[0048]
输入层,用于输入所述行动轨迹中的状态向量数据或状态向量数据的子集;
[0049]
多个所述隐含层用于将输入数据的特征,抽象到另一个维度空间,可展现更抽象
的特征;
[0050]
输出层,采用softmax激活函数作为分类器,用于输出优化策略行动轨迹中每个行动的概率。
[0051]
根据本发明的第三个方面,提供了一种终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时可用于执行上述中任一项所述的方法,或,运行上述中任一项所述的系统。
[0052]
根据本发明的第四个方面,提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时可用于执行上述中任一项所述的方法,或,运行上述中任一项所述的系统。
[0053]
由于采用了上述技术方案,本发明与现有技术相比,具有如下至少一项的有益效果:
[0054]
本发明针对高效制冷机房过于复杂且工业场景中不能自由控制导致数据多样性不足的问题,通过搭建物理世界制冷机房的机房数字孪生模型,实现复杂物理系统的随需简化,通过行动轨迹对近端策略优化模型训练,突破了物理系统优化策略空间自由尝试行动的限制,实现机房数字孪生模型的自由控制,进一步解决了深度强化学习模型训练所需的数据多样性的问题,可以提升数据多样性5倍以上。
[0055]
本发明针对现有深度强化学习算法准确率不满足工程级使用要求的问题,通过近端策略优化(例如ppo、ppo2)深度强化学习模型的训练,实现了随着高效制冷机房运行过程中日益增加的高质量数据集,能够持续提升算法精度,从而满足工程级智能能效优化应用的准确性要求。
[0056]
本发明基于数字孪生和智能体深度强化学习进行高效制冷机房人工智能能效优化,采用近端策略优化(ppo或者ppo2)的智能体深度强化学习模型进行智能体训练,实现了随着高效制冷机房运行过程中日益增加的高质量数据集,提升能效 10%以上,实际工程化发展意义重大。
附图说明
[0057]
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
[0058]
图1为本发明一实施例中制冷机房能效优化方法的工作流程图。
[0059]
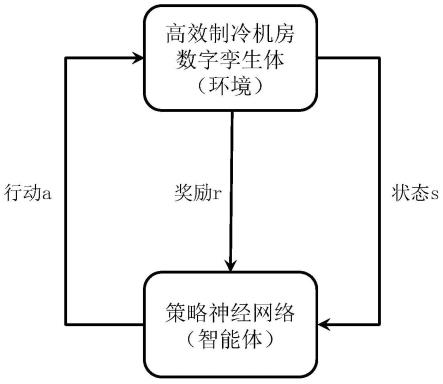
图2为本发明一优选实施例中制冷机房能效优化的工作示意图。
[0060]
图3为本发明一优选实施例中机房数字孪生模拟环境示意图。
[0061]
图4为本发明一实施例中制冷机房能效优化系统的组成模块示意图。
具体实施方式
[0062]
下面对本发明的实施例作详细说明:本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
[0063]
图1为本发明一实施例提供的制冷机房能效优化方法的工作流程图。
[0064]
如图1,该实施例提供的制冷机房能效优化方法,可以包括如下步骤:
[0065]
s100,构建物理世界制冷机房所对应的机房数字孪生模型,并基于物理世界制冷机房的状态数据在机房数字孪生模型上的可视化,对状态数据和优化控制行动进行细粒度表示,以便准确记录采取的行动和环境状态变化,生成优化策略行动轨迹,行动轨迹包括多组按照时间顺序执行的《状态、行动、奖励》数据序列;
[0066]
s200,构建近端策略优深度强化学习模型,并利用行动轨迹对近端策略优深度强化学习模型进行训练,得到制冷机房能效优化智能体模型;
[0067]
s300,基于制冷机房能效优化智能体模型,将待处理的物理世界制冷机房的状态数据作为输入,得到对应的推荐行动数据,用于对制冷机房能效进行优化。工作示意图如图2所示。
[0068]
在s100的一优选实施例中,构建机房数字孪生模型以及生成优化策略行动轨迹,可以包括如下步骤:
[0069]
s101,定义物理世界制冷机房的物理系统;
[0070]
s102,定义每一个物理系统的主要状态表征;
[0071]
s103,对主要状态表征进行数据采集;
[0072]
s104,基于采集的主要状态表征的相应数据,定义每一个物理系统的信息虚体,信息虚体包括状态向量和行动向量;其中,状态向量由实时感知的主要状态表征数据组成,行动向量由实现每一个物理系统可执行的控制行动列表组成;
[0073]
s105,构建信息虚体的可视化仿真控制界面,得到机房数字孪生模型;
[0074]
s106,通过机房数字孪生模型,执行一对当前状态向量细粒度进行优化控制的行动,并通过物理系统获得行动后的能效值和执行后的状态向量;
[0075]
s107,重复上一个步骤,生成《当前状态、行动、奖励、下一状态》数据序列,并将数据序列按照时间顺序排列生成行动轨迹。
[0076]
在s100的一具体应用实例中,还包括如下内容:
[0077]
物理世界高效制冷机房的物理系统,可以包括:冷机系统、冷却侧系统、一次侧系统和二次侧系统;
[0078]
主要状态表征,可以包括:开关状态、负荷率、出水温度、进水温度、功率和水流量;
[0079]
状态向量,可以包括:开关状态、负荷率、出水温度、进水温度、功率和水流量;
[0080]
行动向量,可以包括:冷却塔运行台数+/-、冷却塔出水温度+/-、冷却塔风机频率+/-、冷却泵台数+/-和/或冷却泵温差+/-;
[0081]
执行一对当前状态向量细粒度进行优化控制的行动,可以包括如下步骤:专家系统通过信息虚体的可视化仿真控制界面,基于领域知识,执行对当前状态向量细粒度的优化控制。
[0082]
机房数字孪生模拟环境如图3所示。
[0083]
在s200的一优选实施例中,构建近端策略优化深度强化学习模型,并利用行动轨迹对近端策略优化深度强化学习模型进行训练,得到制冷机房能效优化智能体模型,可以包括如下步骤:
[0084]
s201,采用标准的n层全连接神经网络搭建近端策略优化深度强化学习模型,,包括:输入层、多个隐含层和输出层组成,并利用行动轨迹对近端策略优化深度强化学习模型
进行训练;其中:
[0085]
输入层用于输入行动轨迹中的状态向量数据或状态向量数据的子集;
[0086]
多个隐含层用于将输入数据的特征,抽象到另一个维度空间,可展现更抽象的特征;
[0087]
输出层采用softmax激活函数作为分类器,用于输出优化策略行动轨迹(优化策略空间)中每个行动的概率;
[0088]
s202,对制冷机房能效优化智能体模型的目标函数进行设计,完成对制冷机房能效优化智能体模型的构建。
[0089]
在s200的一具体应用实例中,还包括如下内容:
[0090]
输入层的输入宽度等于输入的状态向量数据的长度;输入层的输出宽度为输入宽度的任意倍数;
[0091]
近端策略优化深度强化学习模型的第n层神经网络的输出宽度为行动向量数据的长度。
[0092]
在s202的一具体应用实例中,制冷机房能效优化智能体模型采用基于策略对的深度强化学习模型,其中,对制冷机房能效优化智能体模型的目标函数进行设计,可以包括如下步骤:
[0093][0094]
或者
[0095][0096]
其中,n为第n条执行轨迹,为近端策略优化ppo算法目标函数,tn为第n条执行轨迹的长度,π
θ
为当前优化策略函数,π
θ
′
为原优化策略函数,a
t
为第t 步所执行的行动,s
t
为第t步的状态,θ为当前优化策略,θ
′
为原优化策略,λ为可调节的算法超参数,kl为kl散度,为近端策略优化ppo2算法目标函数,ε为任意的较小值,为算法的可训练超参数;函数的含义是当则结果为1+ε;当则结果为1-ε;否则为
[0097]
为与策略θ
′
相关的优势函数,其定义如下所示:
[0098][0099]
其中,为状态的状态价值函数值,可由单独的神经网络获得;γ
t
′‑
t
为衰减系数,为算法的可训练超参数,为t
′
时刻的奖励值;
[0100]
公式(1)中的λ和公式(3)中的γ分别采用ppo算法中的缺省方式确定;
[0101][0102]
其中,cop为能效比,q为总系统总瞬时冷量,p为总系统总功率,f为总管瞬时流量,δt为回水总管水温与供水总管水温的差值,k为系数。
[0103]
图4为本发明一实施例中制冷机房能效优化系统的组成模块示意图。
[0104]
如图4所示,该实施例提供的制冷机房能效优化系统,可以包括如下模块:
[0105]
机房数字孪生模型模块,该模块构建物理世界制冷机房所对应的机房数字孪生模型,并基于物理世界制冷机房的状态数据在机房数字孪生模型上的可视化,对状态数据和优化控制行动进行细粒度表示,以便准确记录采取的行动和环境状态变化,生成优化策略行动轨迹;行动轨迹包括多组按照时间顺序执行的《状态、行动、奖励》数据序列;
[0106]
制冷机房能效优化智能体模型模块,该模块构建近端策略优化深度强化学习模型,并利用行动轨迹对近端策略优化深度强化学习模型进行训练,得到制冷机房能效优化智能体模型;基于制冷机房能效优化智能体模型,将待处理的物理世界制冷机房的状态数据作为输入,得到对应的推荐行动数据,用于对制冷机房能效进行优化。
[0107]
在制冷机房能效优化智能体模型模块的一优选实施例中,近端策略优化深度强化学习模型,可以包括如下结构层:
[0108]
输入层,用于输入行动轨迹中的状态向量数据或状态向量数据的子集;
[0109]
输出层,采用softmax激活函数作为分类器,用于输出优化策略行动轨迹(优化策略空间)中每个行动的概率。
[0110]
需要说明的是,本发明提供的方法中的步骤,可以利用系统中对应的模块等予以实现,本领域技术人员可以参照方法的技术方案实现系统的组成,即,方法中的实施例可理解为构建系统的优选例,在此不予赘述。
[0111]
本发明上述实施例提供的制冷机房能效优化方法和系统,对机房数字孪生模型进行定义,包括了状态向量和行动向量定义;采用ppo和ppo2算法对制冷机房能效优化智能体模型进行训练建模;解决了由于高效制冷机房过于复杂且工业场景中不能自由控制,导致数据多样性不足,且现有人工智能算法准确率不满足工程级使用要求的问题。
[0112]
下面对本发明上述两个实施例的具体实施方案进一步说明。
[0113]
本发明上述实施例提供的技术方案主要包括两部分:机房数字孪生模型部分和制冷机房能效优化智能体模型部分。
[0114]
对于机房数字孪生模型部分,所采用的技术方案为:
[0115]
步骤1,定义物理世界高效制冷机房的主要组成部分(物理系统),例如可能包括冷机系统、冷却侧系统、一次侧系统和二次侧系统。
[0116]
步骤2,定义物理世界每个物理系统的主要状态表征(state)。例如,冷机的状态表征函数可以定义为f冷机=(开关状态,负荷率,冷冻水出水温度,冷冻水进水温度,冷却水出水温度,冷却水进水温度,功率,冷冻水流量,冷却水流量);
[0117]
步骤3,实现物理系统主要状态表征的数据采集。例如,为了实现冷机的开关状态、负荷率信息,则需要从冷机的设备控制器的相关点位采集数据;为了实现冷机的冷冻水流量,冷却水流量的数据,则需要在相应的位置加装流量计。
[0118]
步骤4,定义物理世界每个物理系统的信息虚体,信息虚体中包含物理实体主要状态表征(state)实时感知数据组成的“状态向量”。例如,冷机的状态向量可以定义为v冷机=(开关状态,负荷率,冷冻水出水温度,冷冻水进水温度,冷却水出水温度,冷却水进水温度,功率,冷冻水流量,冷却水流量)。
[0119]
步骤5,定义物理世界实现物理系统控制可执行的行动(actions)列表,将它定义
为信息虚体的“行动向量”。例如,高效制冷机房信息虚体的行动向量=f(冷却塔运行台数+/-,冷却塔出水温度+/-,冷却塔风机频率+/-,冷却泵台数+/-,冷却泵温差+/-)。
[0120]
步骤6,实现高效制冷机房信息虚体的2维或3维可视化仿真控制界面,界面上可以包含控制物理设备行动的控制手柄,当控制手柄执行某个行动后,可视化的信息虚体上要实时反应状态的变化,形成机房数字孪生模型。
[0121]
步骤7,在高效制冷机房的调适阶段或给定的能效优化期间,专家系统(领域专家)通过制冷机房信息虚体的可视化仿真控制界面,基于领域知识执行某一行动,并获得行动后的能效值和执行后的状态向量。
[0122]
步骤8,重复步骤7的能效优化过程,生成训练深度强化学习算法所需的《状态、行动、奖励》数据序列。该过程可以由同一个领域专家在不同时间进行,也可以由多个领域专家在不同的时间完成。生成的数据序列可以按照合适的时间步长生成训练算法所需的行动轨迹(trajectory)。
[0123]
制冷机房能效优化智能体模型部分,所采用的技术方案为:
[0124]
该智能体模型所采用的策略神经网络,可以是全连接网络,也可以是卷积神经网络等。
[0125]
采用标准的n层全连接神经网络搭建近端策略优化深度强化学习模型,包括:输入层、多个隐含层和输出层,利用行动轨迹对近端策略优化深度强化学习模型进行训练;其中:
[0126]
步骤一,搭建输入层。该层的输入为待处理的物理世界高效制冷机房的数字孪生系统状态数据向量,也可以根据训练需要只输入它的一个子集。激活函数推荐 relu。
[0127]
具体地:该层的输入为待处理的物理世界高效制冷机房的数字孪生系统状态数据向量,也可以根据训练需要只输入它的一个子集。输入层的宽度等于输入的状态数据向量的长度,输出宽度可以是输入的任意倍数。状态数据向量{冷机运行台数,冷机冷冻水出水温度,冷机冷冻水进水温度,冷却塔运行台数,冷却塔出水温度,冷却塔风机频率,冷却泵台数,冷却泵温差,二次泵运行台数,二次泵压差,二次泵频率,二次侧供水温度,二次侧回水温度,一次泵运行台数,一次泵压差,一次泵频率}等。
[0128]
步骤二,搭建多个隐含层,用于将输入数据的特征,抽象到另一个维度空间,可展现更抽象的特征;
[0129]
步骤三,输出层用于输出优化策略空间中每个行动的概率,输出层使用softmax 激活函数作为分类器,给出推荐的行动。第n层的输出宽度为行动向量的长度。进一步地,基于策略神经网络训练的智能体可以训练针对单个设备的智能体,也可以训练针对所有的设备或其中部分设备的智能体。
[0130]
步骤四,定义目标函数,实现策略神经网络推荐最优行动,实现能效最优化的目标。
[0131]
具体地:
[0132][0133]
或者
[0134]
[0135]
其中,n为第n条执行轨迹,为近端策略优化ppo算法目标函数,tn为第n条执行轨迹的长度,π
θ
为当前优化策略函数,π
θ
′
为原优化策略函数,a
t
为第t 步所执行的行动,s
t
为第t步的状态,θ为当前优化策略,θ
′
为原优化策略,λ为可调节的算法超参数,kl为kl散度,为近端策略优化ppo2算法目标函数,ε为任意的较小值,为算法的可训练超参数;函数的含义是当则结果为1+ε;当则结果为1-ε;否则为
[0136]
为与策略θ
′
相关的优势函数,其定义如下所示:
[0137][0138]
其中,为状态的状态价值函数值,可由单独的神经网络获得;γ
t
′‑
t
为衰减系数,为算法的可训练超参数,为t
′
时刻的奖励值;
[0139]
公式(1)中的λ和公式(3)中的γ分别采用ppo算法中的缺省方式确定;
[0140][0141][0142]
其中,cop为能效比,q为总系统总瞬时冷量,p为总系统总功率,f为总管瞬时流量,δt为回水总管水温与供水总管水温的差值,k为系数。
[0143]
本发明一实施例提供了一种终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时可用于执行上述实施例中任一项的方法,或,运行上述实施例中任一项的系统。
[0144]
可选地,存储器,用于存储程序;存储器,可以包括易失性存储器(英文:volatilememory),例如随机存取存储器(英文:random-access memory,缩写:ram),如静态随机存取存储器(英文:static random-access memory,缩写:sram),双倍数据率同步动态随机存取存储器(英文:double data rate synchronous dynamic random accessmemory,缩写:ddr sdram)等;存储器也可以包括非易失性存储器(英文:non-volatilememory),例如快闪存储器(英文:flash memory)。存储器用于存储计算机程序(如实现上述方法的应用程序、功能模块等)、计算机指令等,上述的计算机程序、计算机指令等可以分区存储在一个或多个存储器中。并且上述的计算机程序、计算机指令、数据等可以被处理器调用。
[0145]
上述的计算机程序、计算机指令等可以分区存储在一个或多个存储器中。并且上述的计算机程序、计算机指令、数据等可以被处理器调用。
[0146]
处理器,用于执行存储器存储的计算机程序,以实现上述实施例涉及的方法中的各个步骤。具体可以参见前面方法实施例中的相关描述。
[0147]
处理器和存储器可以是独立结构,也可以是集成在一起的集成结构。当处理器和存储器是独立结构时,存储器、处理器可以通过总线耦合连接。
[0148]
本发明一实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时可用于执行上述实施例中任一项的方法,或,运行上述实施例中任一项的系统。
[0149]
本发明上述实施例提供的制冷机房能效优化方法、系统、终端及介质,基于数字孪
生和智能体深度强化学习,通过物理世界制冷机房的数字孪生模拟环境的搭建,突破了物理系统优化策略空间自由尝试行动的限制,解决了深度强化学习模型训练所需的数据多样性的问题;通过近端策略优化(ppo或ppo2)的深度强化学习算法的智能体训练,实现了随着高效制冷机房运行过程中日益增加的高质量数据集,能够持续提升算法精度,从而满足工程级智能能效优化应用的准确性要求。
[0150]
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
[0151]
本发明上述实施例中未尽事宜均为本领域公知技术。
[0152]
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1