一种有效避开对深度学习模型的所有权检测方法
1.本发明涉及深度学习及安全技术领域,具体地说是一种有效避开对深度学习模型的所有权检测方法。
背景技术:
2.随着人工智能的发展和普及,机器学习在图像与语音识别、自动驾驶、自然语言处理及网络安全检测等领域展示出了巨大的优势。训练一个表现良好的深度学习模型需要大量的计算资源和时间,有时模型所有者会将他们的模型上传到向公众提供服务的云服务器上。在大多数情况下,模型参数和结构对用户是不可见的,用户只能得到与其输入对应的输出(标签或概率),这时一些恶意用户就会通过暴露的界面窃取受害者模型的知识产权(intellectual property,ip),这种威胁被称为模型窃取攻击。由于对手可以获得受害者模型的类似功能复制,因此非常迫切需要保护受害者模型。为了防止模型窃取攻击,大致有两种不同的防御策略。一方面,在受害者模型中添加扰动可以增加模型窃取攻击的成本或完全防止。另一方面,水印被广泛应用于保护模型知识产权。
3.最近,maini等人提出了一种名为数据集推理(dataset inference,di)的方法保护模型的知识产权,该方法利用私有训练数据的独特特性来进行模型所有权验证。实验表明,数据集推理仅通过暴露10个受害者模型的私人训练样本,就可以95%的置信度验证模型被盗。
4.现有技术的di方法成功主要归因于训练集知识带来的模型相似性(如决策边界),一旦对手用一些处理过的数据对自己的模型进行微调,di的检测置信度将会显著下降,然而模型的准确性也会下降。因此,如何找到合适的样本,既可以改变对手模型的决策边界使di失效,又不降低模型精度是一个重要问题。
技术实现要素:
5.本发明的目的是针对现有技术的不足而提供一种有效避开对深度学习模型的所有权检测方法,采用弹性权重巩固方法,找到合适的数据池来微调对手模型的决策边界,使数据集推理置信度下降且不降低模型的精度,使在修改决策边界的同时能控制模型测试精度不会大幅度下降,该方法既可以通过修改模型的决策边界来避开数据集推理的检测,又运用了弹性权重巩固法来缓解灾难性遗忘从而确保模型精度不会大幅度下降,在cifar10、cifar100和imagenet12数据集上的实验结果证明该方法有效,并进一步发展到一个更现实的场合,黑盒设置和高分辨率图像,方法简便,效果显著,具有广泛的应用前景。
6.实现本发明目的的具体技术方案是:一种有效的避开对深度学习模型所有权检测的方法,其特点是该所有权检测方法,采用找到合适的数据池来微调对手模型的决策边界使数据集推理置信度下降且不降低模型的精度,具体包括下述步骤:
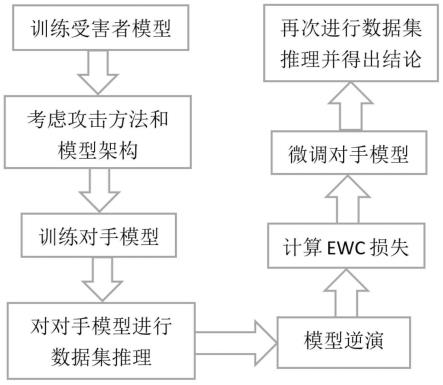
7.步骤1:训练受害者模型
8.选择一个卷积层总数为28,加宽因子为10的残差网络wrn-28-10,数据集选择的是
cifar10、cifar100和imagenet12。cifar10由10类32
×
32的彩色图像组成,每类有50000张训练图像和10000张测试图像。cifar100与cifar10具有相同的分布,有100个类,每个类包含500张训练图像和100张测试图像,总共有6万张图片。imagenet12是imagenet的一个子集。它包含12个类的彩色图像,每个类有1040张训练图像和260张验证图像。
9.步骤2:考虑攻击方法和模型架构
10.根据目标模型的不同权限级别,考虑了六种攻击方法并分别确定了对手模型架构:
11.1)数据可访问攻击(data-accessible attack,)
12.对手可以获得目标模型的数据集,对手可以使用知识蒸馏来训练学生模型或从头开始训练新模型,选择一个简单的模型架构:resnet;
13.2)模型可访问攻击(model-accessible attack,)
14.对手可以访问整个模型,包括目标模型的内部结构、超参数和梯度;对手可以通过零知识精馏来训练复制,或者使用一个本地独立的数据集来微调目标模型;对于零知识蒸馏攻击者,选择cifar10上的wrn-16-1和cifar100上的wrn-16-2;对于微调攻击者,因为是直接对受害者模型进行微调,因此模型架构为wrn-28-10。
15.3)仅查询攻击(query-only attack,)
16.对手通过查询api来获得对目标模型的知识,根据api返回的表单,有两种类型的攻击:仅标签攻击(label-only attack)和仅日志攻击(logit-only attack)。选择cifar10上的wrn-16-1和cifar100上的wrn-16-2。
17.步骤3:训练对手模型
18.根据攻击的类型采用不同的训练方法:
19.1)对于数据可访问攻击
20.直接在原始训练数据集上训练两个模型,进行100个迭代周期;
21.2)对于零知识蒸馏攻击
22.使用了无数据的对抗性蒸馏方法,并对该模型进行了500个迭代周期训练;3)对于微调攻击
23.使用未标记的tinyimages,它在5个训练周期后接近cifar;
24.4)对于仅查询攻击,使用未标记的tinyimages,但训练周期是20个。
25.步骤4:对对手模型进行数据集推理
26.数据集推理(dataset inference,di)的具体步骤如下:
27.1)首先考虑一个n类的任务,对于训练数据集中的每个样本(x,y),di首先生成它到每个类的距离。基于受害者对目标模型内部梯度的访问,di执行两种生成方法:mingd和blind walk,分别代表白盒和黑盒。在mingd中,di通过min
δ
d(x,x+δ)s.t.f(x+δ)=m获得到目标类m的最小距离δm;在blind walk中,di首先选定一个初始方向δ,并沿着这个方向走k步直到f(x+kδ)=m,δm=kδ表示y到m的距离。一般来说,度量(δ1,δ2,
…
,δn)为嵌入到目标模型中的特征。
28.2)接着受害者从其私有训练数据集和公共数据集中随机选择相同数量的样本,并计算其自身模型的嵌入向量,标记为-1或1(在私有训练数据集中表示为1,否则为-1),用来训练一个二值分类器。在验证阶段,受害者从私人和公共数据集中选择相同数量的样本,计
算其对手模型的特征向量,并将其输入二值分类器,计算置信度得分μv和μ。受害者进行零假设h0:μ《μv,得到p值。如果p值低于显著水平α,则拒绝h0,并将对手模型标记为被盗;
29.步骤5:对手模型进行模型逆演,生成与原始训练样本相似的合成图像
30.通过输入与训练数据大小相同的初始随机噪声和目标标签y,从对手模型fa中恢复的图像通过优化来合成。λ1、λ2和λ3分别为分类损失批处理规范化正则化和对抗性损失的惩罚系数。
31.合成图像和私有训练样本之间仍存在差距,本发明选择最相似的合成图像,为了判断相似性,提出了一个度量q来定量分析合成图像与原始训练样本之间的差异,所述度量q由下述(a)式计算:
[0032][0033]
其中,分子表示交叉熵损失,分母表示合成图像在预测向量中的最大置信值。
[0034]
相似度矩阵与合成图像和真实样本之间的间隙成正比,q值越低说明合成图像和真实样本之间的差异越小。
[0035]
由上述(a)式可以看出,损失值低,对目标类的预测概率高的两种合成图像具有较低的相似度度量。将合成图像按度量进行非降序排序,选取前k个样本作为最相似的样本,将它们表示为核心集dc,另一部分表示为do。给定预先训练过的对手模型,将其进行逆演,得到50000个合成图像,根据排序后的相似度矩阵,选择前10000个图像到核心集dc。
[0036]
步骤6:计算ewc损失
[0037]
为了使测试精度尽量不下降,采用弹性权重巩固,一种缓解特定模型参数学习速度的方法,其需要部分原始训练数据来计算费雪信息矩阵f,从对手模型反演得到的与私有训练数据相似的数据池。因此,可以选择概率最高的样本来近似费雪信息矩阵。
[0038]
计算之前任务的费雪信息矩阵f=[f
ij
]n×n,其f
ij
由下述(b)式计算:
[0039][0040]
式中,f(x|θ)为输入为x;参数为θ的模型的输出;d为整个训练数据集;为第i层参数的梯度变化值的期望。
[0041]
为了测量每个参数的贡献,ewc选择了由下述(c)式计算先前任务的费雪信息矩阵f的对角线fi:
[0042][0043]
式中,f(x|θ)为输入为x;参数为θ的模型的输出;d为整个训练数据集;为第i层参数的梯度变化值的期望;θ
*
为先前任务的模型参数。
[0044]
当预先训练的模型面对新任务时,为了保持对之前任务的记忆,模型参数θ
[0045]
应接近之前的参数θ
*
。因此,设置了一个惩罚项,它与模型参数θ和(与fi相关的)θ
*
之间的间隙成正比。在损失函数中添加一个正则化项来训练一个新的任务,所述损失函数由下述(d)式计算:
[0046]
[0047]
其中,为优化新任务的交叉熵损失;λ是一个控制先前任务重要性的参数;fi代表了参数θ
*
在先前任务上的重要性,也就是先前任务的费雪信息矩阵的对角线,i表示每个参数。
[0048]
步骤7:运用ewc方法和do数据集对对手模型进行微调
[0049]
在步骤5中获得了dc和do两个数据集,它们类似于私人训练数据集,与do相比,dc和受害者训练集更相似。由于缺少先前任务的原始训练集,选择dc来近似费雪信息矩阵f,在微调阶段,更新了所有层的权重。
[0050]
步骤8:对微调后的对手模型进行数据集推理并得出结论
[0051]
数据集推理过程在步骤4中给出,若对于微调后的对手模型,数据集推理的结果是未被盗,则该方法有效,否则该方法无效,不能避开数据集推理的检测。
[0052]
本发明与现有技术相比具有通过修改模型的决策边界来避开数据集推理的检测,又运用了弹性权重巩固法来缓解灾难性遗忘从而确保模型精度不会大幅度下降,由于数据集推理的成功归因于训练集知识带来的模型相似性(如决策边界),因此微调对手模型就能使数据集推理置信度下降。本发明还运用了弹性权重巩固方法,使在修改决策边界的同时能控制模型测试精度不会大幅度下降,在cifar10、cifar100和imagenet12数据集上的实验结果证明该方法有效,并进一步发展到一个更现实的场合:黑盒设置和高分辨率图像,方法简便,效果显著,具有广泛的应用前景。
附图说明
[0053]
图1为本发明流程图;
[0054]
图2为微调前后暴露40个样本进行数据集推理得到的p值对比示意图。
具体实施方式
[0055]
以下结合附图对本发明进行详细说明。应当理解的是,此处描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
[0056]
参阅图1,本发明采用弹性权重巩固方法,找到合适的数据池来微调对手模型的决策边界,使数据集推理置信度下降且不降低模型的精度,使在修改决策边界的同时能控制模型测试精度,采用找到合适的数据池来微调对手模型的决策边界使数据集推理置信度下降且不降低模型的精度,具体包括下述步骤:
[0057]
步骤1:训练受害者模型
[0058]
选择一个卷积层总数为28,加宽因子为10的残差网络wrn-28-10,数据集选择的是cifar10、cifar100和imagenet12。cifar10由10类32
×
32的彩色图像组成,每类有50000张训练图像和10000张测试图像。cifar100与cifar10具有相同的分布,有100个类,每个类包含500张训练图像和100张测试图像,总共有6万张图片。imagenet12是imagenet的一个子集。它包含12个类的彩色图像,每个类有1040张训练图像和260张验证图像。
[0059]
步骤2:考虑攻击方法和模型架构
[0060]
根据目标模型的不同权限级别,考虑了六种攻击方法并分别确定了对手模型架构:(1)数据可访问攻击(data-accessible attack,)——对手可以获得目标模型的数据集。对手可以使用知识蒸馏来训练学生模型或从头开始训练新模型。我们选择了一个简
单的模型架构:resnet;(2)模型可访问攻击(model-accessible attack,)——对手可以访问整个模型,包括目标模型的内部结构、超参数和梯度。对手可以通过零知识精馏来训练复制,或者使用一个本地独立的数据集来微调目标模型。对于零知识蒸馏攻击者,选择cifar10上的wrn-16-1和cifar100上的wrn-16-2;对于微调攻击者,因为是直接对受害者模型进行微调,因此模型架构为wrn-28-10;(3)仅查询攻击(query-only attack,)——对手通过查询api来获得对目标模型的知识。根据api返回的表单,有两种类型的攻击:仅标签攻击(label-only attack)和仅日志攻击(logit-only attack)。我们选择cifar10上的wrn-16-1和cifar100上的wrn-16-2。
[0061]
步骤3:训练对手模型
[0062]
根据攻击的类型采用不同的训练方法:(1)对于数据可访问攻击,直接在原始训练数据集上训练两个模型,进行100个迭代周期;(2)对于零知识蒸馏攻击,使用了无数据的对抗性蒸馏方法,并对该模型进行了500个迭代周期训练;对于微调攻击,使用未标记的tinyimages,它在5个训练周期后接近cifar;(3)对于仅查询攻击,也使用未标记的tinyimages,但训练周期是20个。
[0063]
步骤4:对手模型的数据集推理
[0064]
数据集推理(dataset inference,di)的具体步骤如下:
[0065]
首先考虑一个n类的任务,对于训练数据集中的每个样本(x,y),di首先生成它到每个类的距离。基于受害者对目标模型内部梯度的访问,di执行两种生成方法:mingd和blind walk,分别代表白盒和黑盒。在mingd中,di通过min
δ
d(x,x+δ)s.t.f(x+δ)=m获得到目标类m的最小距离δm;在blind walk中,di首先选定一个初始方向δ,并沿着这个方向走k步直到f(x+kδ)=m,δm=kδ表示y到m的距离。一般来说,度量(δ1,δ2,
…
,δn)为嵌入到目标模型中的特征。
[0066]
接着受害者从其私有训练数据集和公共数据集中随机选择相同数量的样本,并计算其自身模型的嵌入向量,标记为-1或1(在私有训练数据集中表示为1,否则为-1),用来训练一个二值分类器。在验证阶段,受害者从私人和公共数据集中选择相同数量的样本,计算其对手模型的特征向量,并将其输入二值分类器,计算置信度得分μv和μ。受害者进行零假设h0:μ《μv,得到p值。如果p值低于显著水平α,则拒绝h0,并将对手模型标记为被盗;
[0067]
步骤5:对手模型进行模型逆演生成与原始训练样本相似的合成图像
[0068]
接着对手模型进行模型逆演,生成与原始训练样本相似的合成图像:通过输入与训练数据大小相同的初始随机噪声和目标标签y,从对手模型fa中恢复的图像通过优化来合成。λ1、λ2和λ3分别为分类损失批处理规范化正则化和对抗性损失的惩罚系数。合成图像和私有训练样本之间仍存在差距,我们选择最相似的合成图像。
[0069]
为了判断相似性,提出了一个度量q来定量分析合成图像与原始训练样本之间的差异,所述度量q由下述(a)式计算:
[0070][0071]
其中,分子表示交叉熵损失;分母表示合成图像在预测向量中的最大置信值。
[0072]
相似度矩阵与合成图像和真实样本之间的间隙成正比,q值越低说明合成图像和
真实样本之间的差异越小。由上述(a)式可以看出,损失值低,对目标类的预测概率高的两种合成图像具有较低的相似度度量。将合成图像按度量进行非降序排序,选取前k个样本作为最相似的样本。将它们表示为核心集dc,另一部分表示为do。给定预先训练过的对手模型,将其进行逆演,得到50000个合成图像。根据排序后的相似度矩阵,我们选择前10000个图像到核心集。
[0073]
步骤6:计算ewc损失
[0074]
计算ewc损失,首先计算之前任务的费雪信息矩阵f=[f
ij
]n×n,f的计算方法由下述(b)式表示为:
[0075][0076]
其中,f(x|θ)为输入为x;参数为θ的模型的输出;d为整个训练数据集。为了测量每个参数的贡献,ewc选择了下述(c)式表示先前任务的费雪信息矩阵的对角线fi:
[0077][0078]
其中,θ
*
为先前任务的模型参数。当预先训练的模型面对新任务时,为了保持对之前任务的记忆,模型参数θ应接近之前的参数θ
*
。因此,设置了一个惩罚项,它与模型参数θ和(与fi相关的)θ
*
之间的间隙成正比。在损失函数中添加一个正则化项来训练一个新的任务,所述损失函数由下述(d)式计算:
[0079][0080]
其中,为优化新任务的交叉熵损失;λ是一个控制先前任务重要性的参数;fi代表了参数θ
*
在先前任务上的重要性,也就是先前任务的费雪信息矩阵的对角线fi,i表示每个参数。由于缺少先前任务的原始训练集,选择dc来近似费雪信息矩阵f,在微调阶段,更新了所有层的权重。
[0081]
步骤7:运用ewc方法和do数据集对对手模型进行微调
[0082]
上述步骤5中获得了两个数据集,它们类似于私人训练数据集,与do相比,dc和受害者训练集更相似。由于缺少先前任务的原始训练集,选择dc来近似费雪信息矩阵,在微调阶段更新了所有层的权重。
[0083]
步骤8:对微调后的对手模型进行数据集推理并得出结论
[0084]
参阅图2,实验发现在微调之前di均检测出模型被盗,在经过微调过程后对手成功地逃避了检测。然而注意到白盒方法mingd存在一些局限性,对手模型很难将自己完全暴露给受害者以进行所有权检测。因此,进一步发展到一个更现实的场合:黑盒设置和高分辨率图像。本发明采用imagenet12和更现实的黑盒方法:blind walk。考虑到在大规模基准数据集上模型提取的效率较低,假设对手可以完全访问受害者的训练数据来训练模型。训练了4个具有不同架构的模型:resnet34、resnet18、densenet121和vgg16。resnet34被认为是受害者模型,其他的是对手模型。本发明还提取了受害者模型的知识,并将它们转移到学生模型中。与cifar10和cifar100相比,当仅暴露5个样本时,di可以验证模型被盗的可信度大于95%。经过微调处理后,有40个样本的最小p值甚至高于0.1,本发明可以扩展到现实的任务。di捕获模型决策边界的相似性,并通过样本到边界的距离进行验证。然而,即使在同一数据集上训练的不同结构模型的决策边界存在差异,更不用说对不同数据集进行微调后的
结果了。在某些情况下,前者在之前的数据集中取得了很好的性能,但对决策边界进行了相对较大的修改,以规避di。
[0085]
本发明的有效性取决于合成图像的质量和多样性,核心集和私有训练集之间的图像的高相似性有助于抑制灾难性遗忘,从而带来相对较小的精度下降。然而,输出集和私有训练集之间的适当图像间隙使得决策边界充分移动,所以很难生成合适的图像,这会是一个有趣的未来工作。
[0086]
上述实验结果详见下述表1、表2所示的对对手模型进行微调前后的测试精度对比和进行数据集推理后得到的p值(p值越小,说明模型被盗的假设检验的置信度越高):
[0087]
表1 微调前后受害者模型和6个对手模型的测试精度
[0088][0089]
表2 受害者模型和对手模型(仅给出两种)在微调前后暴露40个样本进行数据集推理得到的p值
[0090][0091]
通过上述表1、表2说明了当cifar10上只暴露了40个样本时,数据集推理声称模型被盗的概率超过99%,在对对手模型进行微调后,p值会大幅度增加,此时di不能声称模型被盗的概率超过90%,这意味着两个模型存在显著差异。为了达到同样的验证效果,受害者需要暴露更多的样本,甚至根本不能做出判断,由此证明该方法有效。同时,弹性权重巩固的方法也使模型的测试精度尽可能不下降或小幅度下降。
[0092]
以上只是对本发明作进一步的说明,并非用以限制本专利,凡为本发明等效实施,均应包含于本专利的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1