基于DNA发夹变异的GWO优化Elman的电力负荷预测方法
基于dna发夹变异的gwo优化elman的电力负荷预测方法
技术领域
1.本发明属于智能优化技术改进领域,尤其涉及一种基于dna发夹变异的gwo优化elman的电力负荷预测方法。
背景技术:
2.电力系统主要由电网、电力用户共同组成,其任务是为用户提供符合标准的、可靠的电能,以满足各类负荷需求,为人们生活、社会生产提供动力。各类用户对电力的需求是动态变化的,并且电能的特殊性使得其难以被大量储存,这就要求电力的生产与系统负荷要维持动态平衡,满足用户需求的同时,使得系统稳定高效的运行。因此,有必要发展电力负荷系统预测技术,它是电力分配调度的基础,也是未来电网规划建设、计划用电管理、电力市场营销等的重要依据。电力负荷预测的核心是建立高精度的数学模型。为此,如何基于历史的用电数据,运用先进的科学预测理论和先进的计算机技术,做出符合需求的预测,以对未来的用电量进行科学合理的管理尤为重要。
3.随着经济的不断发展,电力系统的结构也日趋复杂,同时,电力负荷变化的不确定性和时变、非线性性等特点也越发明显。传统的预测方法很难满足这些复杂性需求,因此,预测结果与实际系统存在较大偏差。
4.人工神经网络凭其强大的非线性映射和自学习能力,已经在电力系统负荷模型预测中取得许多成功的应用案例,推动了电力负荷预测由传统预测向智能化预测方向发展。在各种人工神经网络中,elman神经网络作为典型的反馈式网络,具有输入延时,适合于电力系统的特点。预测的关键是使得神经网络的输入和输出能够准确的反应系统的运行规律,而网络参数的选择对神经网络的性能影响较大。因此,对网络模型的参数进行优化是获得高精度预测的关键。
5.灰狼算法(gray wolf optimizer, gwo)是由mirjalili于2014年提出的一种新的群智能优化算法,该算法模拟了生物界狼群的社会等级关系和集体狩猎行为,即狼群通过跟踪、探索、追捕、攻击实现对猎杀目标的寻优过程。gwo算法自提出以来,由于具有结构简单、参数少、易于实现的优良性能,已经被成功应用于神经网络系统、模糊控制系统、水资源分配等领域。
6.然而,与其他元启发式算法类似,基本的gwo也存在一些棘手的问题。例如,在求解精度和寻优效率上存在不足。在优化复杂问题至寻优后期,狼群逐渐趋向于头狼所在位置或周围,极容易陷入局部最优,导致算法无法跳出局部极值来获取全局最优解。
7.遗传算法是一种较早的智能优化算法,其全局搜索能力较强,但算法容易陷入局部最优,出现早熟现象。随着分子生物学的不断发展,人们发现dna分子结构与遗传信息的表达密切相关,加之对遗传算法中交叉和变异思想的深刻理解,王康泰、张丽等提出基于dna的遗传算法以及相关的改进算法。
8.本发明受遗传算法变异思想和dna分子操作的启发,设计一种基于dna发夹变异操作的灰狼优化算法,变异操作有效的改善了种群多样性,提高搜索效率和精度,并将所提出
方法应用到电力负荷系统神经网络模型参数寻优,最终获得较好的预测精度。
技术实现要素:
9.针对以上现有技术的不足,本发明提出一种基于dna发夹变异的gwo优化elman的电力负荷预测方法,该方法将dna分子进行发夹变异,并作用于灰狼算法,以维持种群多样性,提高算法的局部搜索能力,并将改进的gwo应用于elman神经网络模型参数估计,获得最优解,从而建立电力负荷系统神经网络预测模型。该方法所得预测模型能够较好的反应实际系统的非线性特性。
10.本发明所采用的具体技术方案如下:基于dna发夹变异的gwo优化elman的电力负荷预测方法,是构建elman电力负荷预测模型并利用改进的灰狼算法对elman电力负荷预测模型的参数进行寻优,所述改进的灰狼算法为采用dna发夹变异作用于灰狼算法上。
11.进一步的,所述的dna发夹变异为:随机选择一个dna序列作为父代个体,定义第一个碱基的序列号为c1=1,从序列号为c1+1开始遍历,直到找到第一个序列号为c1的碱基互补的碱基,定义其序列号为c2,如果找不到c2,则重新选择dna序列,直到找到为止;然后,将位于c1和c2之间的所有碱基位进行逆序排列,最后,将逆序得到的碱基位分别用其对应的互补碱基代替;最后,令c1= c2+1,重复执行以上步骤,直至遍历完所有的c1;至此,得到变异后新的子代个体。
12.进一步的,所述方法包括如下步骤:步骤1:获取电力负荷数据集:步骤1.1 对电力负荷样本数据进行预处理优选的,对于样本中缺失的数据或异常数据可以采用线性插值法进行填充和替换。假设t时刻和时刻的采样点值分别为pl
t
和,若时刻的数据丢失,则用式,j<i计算得到。
13.步骤1.2 将步骤1.1处理后的数据集划分为两部分:电力负荷训练数据集和电力负荷测试数据集。
14.步骤1.3 对样本数据进行最大最小归一化处理,其计算公式为:。
15.其中,xn表示归一化后的值,x是原始数据值,x
max
和x
min
表示样本数据的最大和最小值,t
max
和t
min
分别表示目标数据的最大值和最小值。
16.步骤1.3 将经过归一化后的数据集划分为两部分:电力负荷训练数据集和电力负荷测试数据集。
17.步骤2:建立电力负荷elman神经网络模型,确定神经元的输入和输出数据;步骤3:确定电力负荷elman神经网络的隐含层神经元个数;步骤4:初始化寻优参数。即设置步骤3所确定elman神经网络的初始权值和阈值为待寻优参数;步骤5:确立适应度函数,即优化算法的评价函数,优选的,将其定义为:elman神经
网络训练得到的输出与样本实际值之间的误差平方和的算术平方根;步骤6:将训练数据集代入elman神经网络模型训练,并采用dna发夹变异操作灰狼算法对参数进行优化,得到最优的权值和阈值。
18.步骤7:将测试数据集代入步骤6训练调整好的神经网络模型中,得到测试集对应的预测值。
19.进一步的, 所述步骤2中,电力负荷样本数据包括5个输入和一个输出数据。输入的形式如下:式中,p(t)表示t时刻的温度,h(t)表示t时刻的湿度,r(t)表示t时刻的降水量,l(t-1)、l(t-2)和l(t-3)分别表示t-1、t-2和t-3时刻的电力负荷值。
20.输出为t时刻的电力负荷数据。
21.进一步的,本方法中构建电力负荷预测模型采用elman神经网络学习算法,如下:式中,k表示时刻,xc(k),u(k-1),x(k),y(k)分别表示m维反馈状态向量,n维输入向量,m维隐含层节点向量,1维输出向量;,和分别表示承接层到隐含层、输入层到隐含层、隐含层到输出层的连接权值矩阵; b1和b2分别是输入层和隐含层的阈值;f为隐含层的传递函数,常取s函数,g为隐含层输出的线性组合表达式。
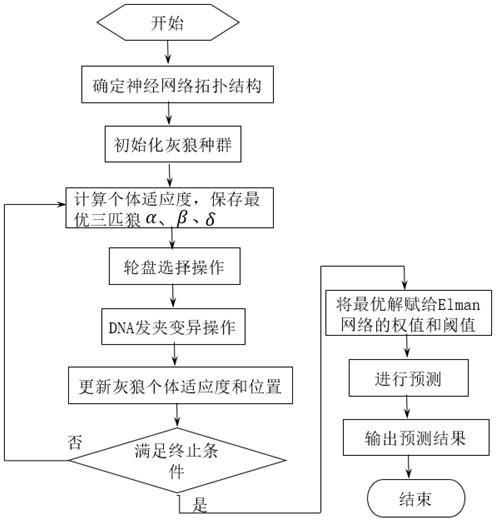
22.进一步的,所述步骤6中基于dna发夹变异操作灰狼算法的具体步骤如下:步骤6.1:设置dna发夹变异操作灰狼算法的运行参数,包括:种群个数n,最大进化代数g,个体编码长度l,变量的个数m,变异概率pm,算法迭代的终止条件,一般为达到最大迭代次数或设定的寻优精度;步骤6.2:对要进行寻优的m个权值和阈值进行编码,随机生成大小为n个的初始种群,每个参数被编码为长度为l的子序列,且由整数集{0,1,2,3}表示,则每个个体被编码后的dna序列长度为l
×
m;步骤6.3:将种群中的个体解码为对应的elman神经网络寻优的权值和阈值,采用elman神经网络对样本数据训练,依据步骤5,将得到的电力负荷预测数据与实际数据的误差平方和的平方根作为dna发夹变异gwo寻优的适应度函数;步骤6.4:计算所有个体的适应度函数值,轮盘赌选择个体,并将选中的个体按适应度函数值进行排序,适应度较优的前70%的个体为优质个体,排名后30%的个体为有害个体,并且取前三个最优的个体,标记为,,。
23.步骤6.5:随机生成概率,以此决定有害个体是否参与变异,具体为:a) 若r>pm,则不进行变异操作,直接计算该个体可能更新的位置,具体为:a1) 分别计算该个体距离三匹头狼,,的距离dk,,个体当前位置为x,
a2) 根据dk计算个体可能更新的位置,计算公式为:,其中,式中,,a随着迭代次数增加,由2线性衰减到0。
24.b) 若r<pm,则执行变异操作,具体步骤为:b1) 定义该个体第一个碱基的序列号为c1=1;b2) 从序列号为c1+1开始遍历,找到第一个与序列号为c1的碱基互补的碱基,定义其序列号为c2;b3) 将位于c1和c2之间的所有碱基位进行逆序排列;b4) 将逆序得到的碱基位分别用其对应的互补碱基代替,最后,令c1=c2+1,重复执行以上步骤,直至遍历完所有的c1;至此,得到变异后新的子代个体;b5) 分别计算该新个体距离三匹头狼,,的距离dk,,β,,个体当前位置为位置为b6) 根据dk计算个体可能更新的位置,计算公式为:,其中,式中,,a随着迭代次数增加,由2线性衰减到0。
25.步骤6.6 若当前种群达到迭代次数或达到要求的精度,则获得最优的elman网络权值和阈值,否则,返回步骤6.2。
26.本发明受dna分子结构特性和遗传变异思想的启发,设计一种基于dna发夹变异的灰狼优化算法,并将算法用于电力负荷elman神经网络模型的参数寻优,取得了良好的预测效果。
27.与已有技术相比,本发明的有益效果是:1、本发明对原始的灰狼算法进行改进,将分子生物学与gwo优化算法相结合,所设计的变异算子,使得算法具有跳出局部最优的能力、并且收敛速度和收敛精度均有所提高;2、相比静态网络,elman神经网络通过内部反馈机制使其具备较强的动态映射特性,从而具有更强的适应时变特性的能力,满足预测精度的同时提高了电力负荷预测的速度。
附图说明
28.图1是本发明中dna发夹变异操作灰狼算法优化elman神经网络的流程图;图2是elman神经网络的结构图;图3是dna发夹变异操作示意图;图4是改进的gwo-elman神经网络输出、原始elman预测以及实际值之间的对比图;图5是改进的gwo-elman神经网络与原始elman预测误差对比图;图6是原始的灰狼算法与改进的灰狼算法的收敛曲线对比图。
具体实施方式
29.下面将结合本发明的附图,对发明实施例中的技术方案进行完整地、详细的描述和讨论。所列实例仅为本发明的一小部分实施例,并不是全部实施例,该领域技术人员在未取得新的创造性成果的条件下所获得的其他实施例,均属于本发明的保护范围。
30.基于dna发夹变异的gwo优化elman的电力负荷预测方法包括如下步骤:步骤1:获取电力负荷数据集:步骤1.1 对电力负荷异常数据进行预处理对于样本中缺失的数据或异常数据采用线性插值法进行填充和替换。假设t时刻和时刻的采样点值分别为pl
t
和,若时刻的数据丢失,则用式,j<i计算得到。
31.步骤1.2 将步骤1.1处理后的数据集划分为两部分:电力负荷训练数据集和电力负荷测试数据集。
32.步骤1.3 对样本数据进行最大最小归一化处理,其计算公式为:。
33.其中,xn表示归一化后的值,x是原始数据值,x
max
和x
min
表示样本数据的最大和最小值,t
max
和t
min
分别表示目标数据的最大值和最小值。
34.步骤2:建立电力负荷elman模型,确定神经元的输入和输出数据;步骤3:确定电力负荷elman神经网络的隐含层神经元个数;步骤4:初始化寻优参数。设置步骤3所确定elman神经网络的初始权值和阈值为寻优参数;步骤5:确立适应度函数,即优化算法的评价函数由经过elman神经网络训练得到的输出与样本实际输出值之间的绝对值之和确定。
35.elman神经网络学习算法如下:式中,k表示时刻,xc(k),u(k-1),x(k),y(k)分别表示m维反馈状态向量,n维输入
向量,m维隐含层节点向量,1维输出向量;,和分别表示承接层到隐含层、输入层到隐含层、隐含层到输出层的连接权值矩阵; b1和b2分别是输入层和隐含层的阈值;f为隐含层的传递函数,常取s函数,g为隐含层输出的线性组合表达式。
36.步骤6:将训练数据集代入elman神经网络模型训练,并采用dna发夹变异操作灰狼算法对参数进行寻优,得到最优的权值和阈值。
37.如图3所示,dna发夹变异操作内容描述为:随机选择一个dna序列作为父代个体,定义第一个碱基的序列号为c1=1,从序列号为c1+1开始遍历,直到找到第一个序列号为c1的碱基互补的碱基,定义其序列号为c2,如果找不到c2,则重新选择dna序列,直到找到为止;然后,将位于c1和c2之间的所有碱基位进行逆序排列,最后,将逆序得到的碱基位分别用其对应的互补碱基代替;最后,令c1= c2+1,重复执行以上步骤,直至遍历完所有的c1。至此,得到变异后新的子代个体。
38.如图1所示,为本发明中dna发夹变异操作灰狼算法优化elman神经网络的流程图;所述的步骤6利用dna发夹变异操作灰狼算法对电力负荷神经网络模型中的权值和阈值寻优的步骤如下:步骤6.1:设置dna发夹变异操作灰狼算法的运行参数,包括:种群个数n,最大进化代数g,个体编码长度l,变量的个数m,变异概率,算法迭代的终止条件,一般为达到最大迭代次数或设定的寻优精度。
39.步骤6.2:对要进行寻优的m个权值和阈值进行编码,随机生成大小为n个的初始种群,每个参数被编码为长度为l的子序列,且由整数集{0,1,2,3}表示,则每个个体被编码后的dna序列长度为l
×
m。
40.步骤6.3:将种群中的个体解码为对应的elman神经网络寻优的权值和阈值,采用elman神经网络对样本数据训练,依据步骤5,将得到的电力负荷预测数据与实际数据的误差平方和的平方根作为dna发夹变异操作gwo优化算法的适应度函数。
41.步骤6.4:计算所有个体的适应度函数值,轮盘赌选择个体,并将选中的个体按适应度函数值进行排序,适应度较优的前70%的个体为优质个体,排名后30%的个体为有害个体,并且取前三个最优的个体,标记为,,。
42.步骤6.5:随机生成概率,以此决定有害个体是否参与变异,具体为:a) 若r>pm,则不进行变异操作,直接计算该个体可能更新的位置,具体为:a1) 分别计算该个体距离三匹头狼,,的距离dk,,个体当前位置为x,a2) 根据dk计算个体可能更新的位置,计算公式为:,其中,式中,,a随着迭代次数增加,由2线性衰减到0。
43.b) 若r<pm,则执行变异操作,具体步骤为:b1) 定义该个体第一个碱基的序列号为c1=1;b2) 从序列号为c1+1开始遍历,找到第一个与序列号为c1的碱基互补的碱基,定义其序列号为c2;b3) 将位于c1和c2之间的所有碱基位进行逆序排列;b4) 将逆序得到的碱基位分别用其对应的互补碱基代替,最后,令c1=c2+1,重复执行以上步骤,直至遍历完所有的c1;至此,得到变异后新的子代个体;b5) 分别计算该新个体距离三匹头狼,,的距离dk,,β,,个体当前位置为位置为b6) 根据dk计算个体可能更新的位置,计算公式为:,其中,式中,,a随着迭代次数增加,由2线性衰减到0。
44.步骤6.6 若当前种群达到迭代次数或达到要求的精度,则获得最优的elman网络权值和阈值,否则,返回步骤6.2。
45.步骤7:将测试数据集代入步骤6训练调整好的神经网络模型中,用于对电力负荷值进行预测。
46.实施例步骤1:获取电力负荷数据集:实验数据来源于第九届电工数学建模竞赛试题a题提供的电力系统短期负荷数据。该数据记录了地区1从2009年1月1日至2015年1月10日的所有电力负荷数据以及对应的气象因素数据。本实施例中选取数据采集时间为2015年1月1日至2015年1月15日,每15分钟一个采样点,每日99个采样点数据(包括96个电力负荷数据,3个气象影响因素值),共15组1485个数据。
47.步骤1.1 对于样本中缺失的数据或异常数据采用线性插值法进行填充和替换。假设t时刻和时刻的采样点值分别为pl
t
和,若时刻的数据丢失,则用式,j<i计算得到。
48.步骤1.2 将步骤1.1处理后的数据集划分为两部分:电力负荷训练数据集和电力负荷测试数据集。训练数据和测试数据由以下规则确定:将前3天的数据作为elman神经网络输入,第4天的值作为目标值,这样可以得到12组训练样本,第15天的数据为测试样本。
49.步骤1.3 对样本数据进行最大最小归一化处理,其计算公式为:
。
50.其中,xn表示归一化后的值,x是原始数据值,x
max
和x
min
表示样本数据的最大和最小值,t
max
和t
min
分别表示目标数据的最大值和最小值。
51.步骤2:建立电力负荷elman模型,该模型包括5个输入和一个输出数据。输入的形式如下:式中,p(t)表示第t天的温度,h(t)表示第t天的湿度,r(t)表示第t时刻的降水量,l(t-1)、l(t-2)和l(t-3)分别表示第t-1、t-2和t-3天的电力负荷值。
52.输出为第t天对应的电力负荷数据。
53.步骤3:确定电力负荷elman神经网络的隐含层神经元个数为18。
54.步骤4:初始化寻优参数。设置步骤3所建立elman神经网络的初始权值和阈值为寻优参数。
55.步骤5:确立适应度函数,即优化算法的评价函数,由elman神经网络训练得到的输出与样本实际输出值之间的绝对值之和确定,可以表示为:式中,yi表示经过elman网络训预测得到的预测电力负荷值,表示实际的归一化后的电力负荷值。
56.如图2所示,elman神经网络学习算法如下:式中,k表示时刻,xc(k),u(k-1),x(k),y(k)分别表示m维反馈状态向量,n维输入向量,m维隐含层节点向量,1维输出向量;,和分别表示承接层到隐含层、输入层到隐含层、隐含层到输出层的连接权值矩阵; b1和b2分别是输入层和隐含层的阈值;f为隐含层的传递函数,常取s函数,g为隐含层输出的线性组合表达式。
57.步骤6:将训练数据集代入elman神经网络模型训练,并采用dna发夹变异操作灰狼算法对参数进行优化,得到最优的权值和阈值。
58.如图3所示,dna发夹变异操作内容描述为:随机选择一个dna序列作为父代个体,定义第一个碱基的序列号为c1=1,从序列号为c1+1开始遍历,直到找到第一个序列号为c1的碱基互补的碱基,定义其序列号为c2,如果找不到c2,则重新选择dna序列,直到找到为止;然后,将位于c1和c2之间的所有碱基位进行逆序排列,最后,将逆序得到的碱基位分别用其对应的互补碱基代替;最后,令c1= c2+1,重复执行以上步骤,直至遍历完所有的c1。至此,得到变异后新的子代个体。
59.所述的步骤6利用dna发夹变异操作灰狼算法对电力负荷神经网络模型中的权值和阈值寻优的步骤如下:
步骤6.1:设置dna发夹变异操作灰狼算法的运行参数,包括:种群个数n=30,最大进化代数g=15,个体编码长度l=50,变量的个数m=5,变异概率pm=0.2,算法迭代的终止条件,为达到最大迭代次数50或设定的寻优精度δ=10-4
。
60.步骤6.2:对要进行寻优的个权值和阈值进行编码,随机生成大小为个的初始种群,每个参数被编码成长度为的子序列,且由整数集{0,1,2,3}表示,则每个个体被编码后的dna序列长度为。
61.步骤6.3:将种群中的个体编码序列解码为对应的待寻优的权值和阈值,采用elman神经网络对样本数据训练,依据步骤5,寻优的适应度函数表达式为:步骤6.4:计算所有个体的适应度函数值,轮盘赌选择个体,并将选中的个体按适应度函数值进行排序,适应度较优的前70%的个体为优质个体,排名后30%的个体为有害个体,并且标记前三个最优的个体分别为,,。
62.步骤6.5:随机生成概率,以此决定有害个体是否参与变异,具体为:a) 若r>pm,则不进行变异操作,直接计算该个体可能更新的位置,具体为:a1) 分别计算该个体距离三匹头狼,,的距离dk,,个体当前位置为x,a2) 根据dk计算个体可能更新的位置,计算公式为:,其中,式中,,a随着迭代次数增加,由2线性衰减到0。
63.b) 若r<pm,则执行变异操作,具体步骤为:b1) 定义该个体第一个碱基的序列号为c1=1;b2) 从序列号为c1+1开始遍历,找到第一个与序列号为c1的碱基互补的碱基,定义其序列号为c2;b3) 将位于c1和c2之间的所有碱基位进行逆序排列;b4) 将逆序得到的碱基位分别用其对应的互补碱基代替,最后,令c1=c2+1,重复执行以上步骤,直至遍历完所有的c1;至此,得到变异后新的子代个体。
64.b5) 分别计算该新个体距离三匹头狼,,的距离dk,,β,,个体当前位置为位置为b6) 根据dk计算个体可能更新的位置,计算公式为:
,其中,式中,,a随着迭代次数增加,由2线性衰减到0。
65.步骤6.6 若当前种群达到迭代次数或达到要求的精度,则获得最优的elman网络权值和阈值,否则,返回步骤6.2。
66.步骤7:经过以上步骤训练得出电力负荷elman神经网络预测模型,将测试数据集代入进行测试。测试结果如图4-6所示。
67.图4为本发明提供的基于改进的gwo-elman预测、原始的elman预测值及真实值之间的比较图。如图所示,基于改进的gwo-elman的预测结果与实际值基本吻合。
68.图5为本发明方法提供的基于改进的gwo-elman和原始的elman预测得到的绝对误差比较图。结果表明基于dna发夹变异操作的gwo优化的elman网络模型预测绝对误差远小于原始的elman预测误差。
69.图6为原始灰狼算法与本发明方法对比得到的收敛曲线图。结果表明基于本发明所改进的灰狼算法的收敛速度明显高于原始灰狼算法。从而可以验证基于本发明的elman电力负荷预测速度要比原始灰狼的预测速度要快。
70.测试结果表明,本发明提出的一种基于dna发夹变异的灰狼算法电力负荷elman网络模型预测方法具有优的预测性能,更加接近系统的非线性特性,这是因为基于dna发夹变异的灰狼算法对elman网络的权值和阈值进行了更加高效的优化,从而表现出更高的预测精度和速度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1