基于强化学习的兵棋多实体异步协同决策方法和装置
1.本技术涉及智能决策技术领域,特别是涉及基于强化学习的兵棋多实体异步协同决策方法和装置。
背景技术:
2.兵棋推演是一种利用兵棋进行模拟战争活动的过程。兵棋玩家使用代表环境和军事力量的棋盘和棋子,依据特定的军事规则和概率论原理,模拟战争对抗,对作战方案进行过程推演和评估优化。国防大学兵棋团队研制了战略战役兵棋系统,并指出了人工智能技术应用到兵棋推演中需要解决的关键性问题——智能态势感知。早期的兵棋智能体设计主要利用人类高水平玩家推演经验形成知识库,进而实现给定状态下的行为决策,称之为规则智能体。利用ooda环是设计规则智能体一种方式,在ooda环中的决策模块通常基于行为树或有限状态机等框架编程实现。
3.随着智能体在游戏领域战胜了人类高水平玩家后,部分兵棋推演领域的研究人员开始思考如何将现有的人工智能技术迁移到兵棋推演中,设计能够对抗甚至超越人类玩家的兵棋智能体。2017年,在全国兵棋推演大赛中,中科院自动化所研究的casia先知1.0系统以7:1的成绩击败了人类八强选手。在2020年,中国科学院自动化所研究的alphawar引入了监督学习和自博弈技术实现了联合策略的学习,并且在与人类选手的对抗中通过了图灵测试。深度强化学习兼具深度学习的感知能力和强化学习的决策能力,近年来,部分学者开始尝试将深度强化学习算法应用到兵棋智能体的设计中。
4.在兵棋推演中,需要多个异构算子相互配合最大化集体得分,完成兵棋推演的最终任务。兵棋类似于游戏,近年来以深度强化学习为基础的游戏ai(artificial intelligence)alphago、alphastar战胜了人类高水平玩家,因此,在兵棋推演与人工智能的交叉研究领域,基于强化学习的兵棋智能决策方法成为了热门研究问题。
5.综上,基于强化学习的兵棋智能决策技术取得了诸多研究成果,但是在实际应用过程中存在两类需要解决的关键性问题:其一,兵棋推演中是多实体共同参与对抗,目前大多数兵棋智能决策算法都是基于单智能体强化学习算法设计。在兵棋对抗环境中,多算子协同问题缺乏统一的决策流程框架。
6.其二,兵棋中多实体的异构性导致多智能体协作的异步性,即不同智能体的基本动作执行时长不一致。这种异步性导致现有的多智能体强化学习算法难以有效的解决兵棋多实体异步协作问题。
技术实现要素:
7.基于此,有必要针对上述技术问题,提供一种基于强化学习的兵棋多实体异步协同决策方法和装置,能够基于强化学习算法,实现兵棋推演中多实体异步协同的决策。
8.基于强化学习的兵棋多实体异步协同决策方法,包括:
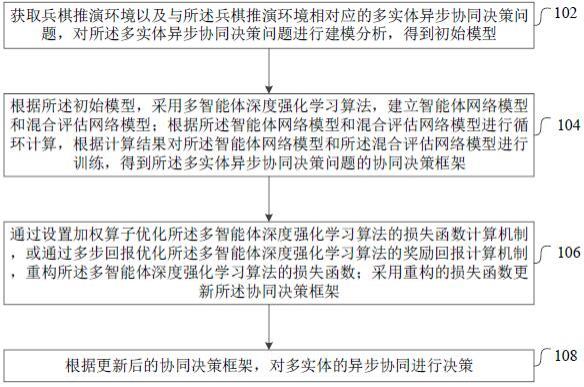
获取兵棋推演环境以及与所述兵棋推演环境相对应的多实体异步协同决策问题,对所述多实体异步协同决策问题进行建模分析,得到初始模型;根据所述初始模型,采用多智能体深度强化学习算法,建立智能体网络模型和混合评估网络模型;根据所述智能体网络模型和混合评估网络模型进行循环计算,根据计算结果对所述智能体网络模型和所述混合评估网络模型进行训练,得到所述多实体异步协同决策问题的协同决策框架;通过设置加权算子优化所述多智能体深度强化学习算法的损失函数计算机制,或通过多步回报优化所述多智能体深度强化学习算法的奖励回报计算机制,重构所述多智能体深度强化学习算法的损失函数;采用重构的损失函数更新所述协同决策框架;根据更新后的协同决策框架,对多实体的异步协同进行决策。
9.在其中一个实施例中,通过设置加权算子优化所述多智能体深度强化学习算法的损失函数计算机制,或通过多步回报优化所述多智能体深度强化学习算法的奖励回报计算机制,重构所述多智能体深度强化学习算法的损失函数包括:将所述混合评估网络模型设计为第一子网络和第二子网络,分别通过所述第一子网络和所述第二子网络,计算更新目标和联合状态动作估计值并比较,得到加权算子;根据所述加权算子,重构所述多智能体深度强化学习算法的损失函数。
10.在其中一个实施例中,通过设置加权算子优化所述多智能体深度强化学习算法的损失函数计算机制,或通过多步回报优化所述多智能体深度强化学习算法的奖励回报计算机制,重构所述多智能体深度强化学习算法的损失函数还包括:将多步回放数据结合得到多步回报,通过多步回报计算更新目标;根据所述更新目标,重构所述多智能体深度强化学习算法的损失函数。
11.在其中一个实施例中,获取兵棋推演环境以及与所述兵棋推演环境相对应的多实体异步协同决策问题,对所述多实体异步协同决策问题进行建模分析,得到初始模型包括:获取兵棋推演环境以及与所述兵棋推演环境相对应的多实体异步协同决策问题,通过马尔科夫决策过程,对所述多实体异步协同决策问题进行建模分析,得到一元组;根据所述兵棋推演环境,对所述一元组进行更新,得到初始模型。
12.在其中一个实施例中,根据所述智能体网络模型和混合评估网络模型进行循环计算包括:根据所述智能体网络模型,输入当前观测和上一时刻动作信息,输出每个实体的状态动作价值函数,并得到每个实体的执行动作对应的状态动作值;根据所述混合评估网络模型,输入所述状态动作值,输出当前时刻联合状态动作价值。
13.在其中一个实施例中,根据计算结果对所述智能体网络模型和所述混合评估网络模型进行训练,得到所述多实体异步协同决策问题的协同决策框架包括:将计算结果存入经验池,在所述经验池中采样,通过最小化损失函数和计算回报对所述智能体网络模型和所述混合评估网络模型进行训练,得到所述多实体异步协同决策问题的协同决策框架。
14.在其中一个实施例中,根据所述智能体网络模型和混合评估网络模型进行循环计算还包括:
根据所述兵棋推演环境中返回的战场态势信息执行状态掩码操作,得到实体的观测,并将所述观测输入所述智能体网络模型。
15.在其中一个实施例中,根据所述智能体网络模型和混合评估网络模型进行循环计算还包括:兵棋推演环境接收并执行各个实体的联合动作,然后返回下一时间步战场态势信息、即时奖励以及游戏终止判定标志符号;根据所述战场态势信息执行状态掩码操作,得到实体的观测,并将所述观测输入所述智能体网络模型;所述智能体网络模型输出各个实体的联合动作至兵棋推演环境并进行循环计算。
16.基于强化学习的兵棋多实体异步协同决策装置,包括:获取模块,用于获取兵棋推演环境以及与所述兵棋推演环境相对应的多实体异步协同决策问题,对所述多实体异步协同决策问题进行建模分析,得到初始模型;建模模块,用于根据所述初始模型,采用多智能体深度强化学习算法,建立智能体网络模型和混合评估网络模型;根据所述智能体网络模型和混合评估网络模型进行循环计算,根据计算结果对所述智能体网络模型和所述混合评估网络模型进行训练,得到所述多实体异步协同决策问题的协同决策框架;重构模块,用于通过设置加权算子优化所述多智能体深度强化学习算法的损失函数计算机制,或通过多步回报优化所述多智能体深度强化学习算法的奖励回报计算机制,重构所述多智能体深度强化学习算法的损失函数;采用重构的损失函数更新所述协同决策框架;决策模块,用于根据更新后的协同决策框架,对多实体的异步协同进行决策。
17.上述基于强化学习的兵棋多实体异步协同决策深度强化学习的兵棋多实体异步协同决策方法和装置,采用了多智能体强化学习算法,对多实体(即多智能体)设置了不同的动作步长,因此能够实现兵棋推演中多实体异步协同的决策。而且,通过设置加权算子或通过多步回报,优化了多智能体强化学习算法的损失函数计算机制或奖励回报计算机制,从而重构损失函数,并对混合评估网络模型进行更新,最终得到每个实体的联合动作价值函数进而进行决策;在优化过程中,学习速度快、最终胜率高且战斗效率高。
附图说明
18.图1为一个实施例中基于强化学习的兵棋多实体异步协同决策方法的流程示意图;图2为一个实施例中基于强化学习的兵棋多实体异步协同决策方法的示意图;图3为一个实施例中多实体异步的协同决策框架的示意图;图4为一个实施例中macdf-w混合网络结构的示意图;图5为一个实施例中四种算法与规则智能体对抗训练的以胜率为指标的效果对比图;图6为一个实施例中四种算法与规则智能体对抗训练的以单局时长为指标的效果对比图;图7为一个实施例中基于强化学习的兵棋多实体异步协同决策装置的结构框图。
具体实施方式
19.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
20.如图1所示,本技术提供的一种基于强化学习的兵棋多实体异步协同决策方法,在一个实施例中,包括以下步骤:步骤102,获取兵棋推演环境以及与所述兵棋推演环境相对应的多实体异步协同决策问题,对所述多实体异步协同决策问题进行建模分析,得到初始模型。
21.具体的,获取兵棋推演环境以及与所述兵棋推演环境相对应的多实体异步协同决策问题,通过马尔科夫决策过程,对所述多实体异步协同决策问题进行建模分析,得到一元组;根据所述兵棋推演环境,对所述一元组进行更新,得到初始模型。
22.如何通过马尔科夫决策过程对问题进行建模分析得到一元组属于现有技术,在此不再赘述。
23.步骤104,根据所述初始模型,采用多智能体深度强化学习算法,建立智能体网络模型和混合评估网络模型;根据所述智能体网络模型和混合评估网络模型进行循环计算,根据计算结果对所述智能体网络模型和所述混合评估网络模型进行训练,得到所述多实体异步协同决策问题的协同决策框架。
24.多智能体强化学习算法(qmix)包括构建智能体网络模型以及超网络模型两个部分,均是现有技术。根据初始模型,先采用智能体网络模型对每个实体的环境交互数据进行描述,得到每个实体的动作和状态,再采用超网络进行评估,超网络的更新是通过最小化损失函数进行的。
25.根据所述兵棋推演环境中返回的战场态势信息执行状态掩码操作,得到实体的观测,并将所述观测输入所述智能体网络模型。
26.根据所述智能体网络模型,输入当前观测和上一时刻动作信息,输出每个实体的状态动作价值函数,并得到每个实体的执行动作对应的状态动作值;根据所述混合评估网络模型,输入所述状态动作值,输出当前时刻联合状态动作价值。
27.兵棋推演环境接收并执行各个实体的联合动作,然后返回下一时间步战场态势信息、即时奖励以及游戏终止判定标志符号;根据所述战场态势信息执行状态掩码操作,得到实体的观测,并将所述观测输入所述智能体网络模型;所述智能体网络模型输出各个实体的联合动作至兵棋推演环境并进行循环计算。
28.将计算结果存入经验池,在所述经验池中采样,通过最小化损失函数和计算回报对所述智能体网络模型和所述混合评估网络模型进行训练,得到所述多实体异步协同决策问题的协同决策框架。
29.步骤106,通过设置加权算子优化所述多智能体深度强化学习算法的损失函数计算机制,或通过多步回报优化所述多智能体深度强化学习算法的奖励回报计算机制,重构所述多智能体深度强化学习算法的损失函数;采用重构的损失函数更新所述协同决策框架。
30.具体的,将所述混合评估网络模型设计为第一子网络和第二子网络,分别通过所述第一子网络和所述第二子网络,计算更新目标和联合状态动作估计值并比较,得到加权
算子;根据所述加权算子,重构所述多智能体深度强化学习算法的损失函数。
31.或,将多步回放数据结合得到多步回报,通过多步回报计算更新目标;根据所述更新目标,重构所述多智能体深度强化学习算法的损失函数。
32.通过设置加权算子重构损失函数,可以更好的判断损失函数的拟合趋势,更精确地减小损失函数的误差,进而在通过重构的损失函数更新协同决策框架时,能够更加准确的表示联合状态动作价值,最终实现算法速度的提高,且提升了胜率和战斗效率。
33.通过多步回报重构损失函数,新的更新目标比原本macdf模型中单步时序差分预测目标能够更加精确的拟合目标值。
34.步骤108,根据更新后的协同决策框架,对多实体的异步协同进行决策。
35.上述基于强化学习的兵棋多实体异步协同决策深度强化学习的兵棋多实体异步协同决策方法和装置,采用了多智能体强化学习算法,对多实体(即多智能体)设置了不同的动作步长,因此能够实现兵棋推演中多实体异步协同的决策。而且,通过设置加权算子或通过多步回报,优化了多智能体强化学习算法的损失函数计算机制或奖励回报计算机制,从而重构损失函数,并对混合评估网络模型进行更新,最终得到每个实体的联合动作价值函数进而进行决策;在优化过程中,学习速度快、最终胜率高且战斗效率高。
36.应该理解的是,虽然图1的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图1中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
37.如图2所示,在一个具体的实施例中,基于强化学习的兵棋多实体异步协同决策深度强化学习的兵棋多实体异步协同决策方法包括:202:获取兵棋推演环境以及与所述兵棋推演环境相对应的多实体异步协同决策问题,对所述多实体异步协同决策问题进行建模分析,得到初始模型。具体的:2021:获取兵棋推演环境以及与所述兵棋推演环境相对应的多实体异步协同决策问题,使用一种简单战术兵棋环境,其中包含兵棋推演中常见的三种算子(坦克、战车、步兵),通过将不同算子的动作执行周期设置为不一致得到多实体异步协同决策问题实例。具体的,将坦克和战车算子向相邻六角格移动一格时间周期设置为5s,将步兵算子向相邻六角格移动一格时间周期设置为1s,兵棋想定的具体信息见下表1。
38.表1兵棋想定的具体信息
2022:通过马尔科夫决策过程,对所述多实体异步协同决策问题进行建模分析,得到一元组。
39.即将兵棋推演问题形式化定义为分布式部分可观察马尔科夫决策过程(dec-pomdps),表示为一元组;其中:表示战术兵棋环境状态空间,表示兵棋环境中三类智能体的联合动作空间,表示状态转移函数,表示奖励函数,表示智能体观测函数,表示智能体的观测空间,表示智能体的个数,此处设置为3,表示折扣因子。
40.2023:根据所述兵棋推演环境,对所述一元组进行更新,得到初始模型。
41.在兵棋推演环境的基础上,设计了每个实体的具体状态空间信息,状态空间信息包含了我方算子特征信息和敌方算子特征信息,两方的算子单元都是由坦克,战车,步兵组成。由于战场迷雾的存在,敌方算子的相关状态信息只能在被观察到后才能获取,为了模拟真实环境,算子在被观察后也只能获取部分信息,如下表2所示。在具体特征信息中,除了能否通视标志、能否攻击标志用三个编码表示之外,其它都用一个编码表示,基于下表2,状态空间的纬度为:维。
42.表2算子在被观察后获取的部分信息
各智能体的动作空间决策信息包括移动动作(6个方向的移动)、射击动作(对三个不同目标的射击)和停止动作,具体见下表3,故动作空间的纬度是维。
43.表3移动动作和射击动作的具体信息根据多实体异步协同决策问题实例,战术兵棋环境接收并执行坦克、战车和步兵算子的联合动作,然后返回下一时间步战场态势信息和即时奖励,同时返回游戏终止判定标志符号done。
44.使用的即时奖励为我方算子单元和敌方算子单元损失血量的差值,即时奖励具体设计为:其中,表示敌方算子上一时刻血量、表示敌方当前时刻血量、表示我方算子上一时刻血量,表示我方当前时刻血量。
45.done表示游戏是否终止,1表示游戏结束,0表示游戏还记继续。
46.204:根据所述初始模型,采用多智能体深度强化学习算法qmix,建立智能体网络模型和混合评估网络模型;根据所述智能体网络模型和混合评估网络模型进行循环计算,根据计算结果对所述智能体网络模型和所述混合评估网络模型进行训练,得到所述多实体异步协同决策问题的协同决策框架macdf。具体的:2041:根据所述初始模型,采用多智能体深度强化学习算法,建立智能体网络模型和混合评估网络模型。
47.设计了智能体网络agentnetwork用于多实体决策;设计了混合评估网络hanetwork用于评估多实体联合动作。
48.2042:根据所述兵棋推演环境中返回的战场态势信息执行状态掩码操作,得到实体的观测,并将所述观测输入所述智能体网络模型。
49.将战术兵棋环境返回的战场态势信息执行状态掩码操作,即进行兵棋环境mask设计,每个智能体智能获取环境局部观测并做出行动,即得到智能体的观测,这种设置保证了该兵棋环境的智能体是基于非完美信息进行行为决策的:。
50.在本实施例中,mask的具体操作方式是将不可通视的算子特征信息的编码置为空,将可通视算子的不可获取特征信息(见表2)的编码置为空。
51.2043:根据所述智能体网络模型,输入当前观测和上一时刻动作信息,输出每个实体的状态动作价值函数,并得到每个实体的执行动作对应的状态动作值。
52.设计智能体网络(动作网络)模型结构用于多实体决策,智能体网络模型初始化,设智能体网络为agentnetwork,设计了三个相同结构的智能体网络agentnetwork,这里我们以步兵算子智能体agent(i)举例说明,将处理后的步兵算子智能体观测和上一时间步动作信息输入智能体网络agent(i),得到步兵算子智能体的状态动作价值和动作决策信息,该决策信息控制步兵算子的下一时间步执行新的动作。另外两个智能体网络坦克智能体agent(t)和战车智能体agent(c)使用同样的技术手段,3个智能体网络的输出拼接在一起形成联合动作信息。
53.具体的,智能体输入当前的观测和上一时刻动作信息,输出状态动作价值函数,则有:再经过贪婪策略输出当前时刻执行动作和其对应的状态动作值,以平衡探索和利用,即:;优选地,智能体网络模型初始化设计为深度循环q网络(drqn),循环神经网络的设计有利于提升在部分可观察环境下的兵棋决策能力。网络结构为门控循环单元和多层感知器构成。具体结构见图3。
54.2044:根据所述混合评估网络模型,输入所述状态动作值,输出当前时刻联合状态动作价值。
55.设计混合评估网络模型用于评估多实体联合动作,设混合评估网络为hanetwork,混合网络模型初始化,输入当前时刻全局态势信息和每个智能体网络的输出,网络通过全局态势信息对当前时刻的动作进行评估,输出联合状态动作价值;
;混合评估网络可以使用一个超网络,有效融合(输入)全局态势信息,得到混合网络的权值矩阵和偏置。
56.然后,将各个智能体网络输出作为hanetwork的输入(a分别表示坦克、战车、步兵),混合评估网络可以通过前向计算得到全局联合状态动作价值;。
57.2045:兵棋推演环境接收并执行各个实体的联合动作,然后返回下一时间步战场态势信息、即时奖励以及游戏终止判定标志符号;根据所述战场态势信息执行状态掩码操作,得到实体的观测,并将所述观测输入所述智能体网络模型;所述智能体网络模型输出各个实体的联合动作至兵棋推演环境并进行循环计算。
58.即重复步骤2042-2044,实现智能体与战术兵棋环境的交互过程。
59.2046:将计算结果存入经验池,在所述经验池中采样,通过最小化损失函数和计算回报对所述智能体网络模型和所述混合评估网络模型进行训练,得到所述多实体异步协同决策问题的协同决策框架。
60.在交互过程中,将战术兵棋环境的战场态势信息、环境针对该联合动作反馈的即时奖励、游戏终止标志符done、智能体观测信息、智能体联合动作信息按照(done)的结构存放在回放经验池replay memory中。
61.采样经验池设计,记录智能体模型对战数据,定义为:其中,表示经验池的大小。
62.当经验池中的回放数据样本到达规定的可以训练的数量后,从经验池中采样一批样本数据对macdf模型中的神经网络(包含智能体网络和混合评估网络)进行整理的统一回传更新,得到训练后的网络模型。
63.也就是说,智能体与环境交互产生对战数据回放记录存入经验池,通过采样经验池中的样本数据,对智能体网络和混合评估网络进行网络参数更新,训练macdf中的神经网络,在规定时间步长后停止智能体的训练并得到最终训练好的智能体模型。
64.在网络训练的过程中,网络更新通过最小化以下损失函数实现,其中,表示数据采样的batch size,表示更新目标,通过计算回报得到,即:
。
65.其中表示目标网络的参数。
66.206:通过设置加权算子优化所述多智能体深度强化学习算法的损失函数计算机制,或通过多步回报优化所述多智能体深度强化学习算法的奖励回报计算机制,重构所述多智能体深度强化学习算法的损失函数;采用重构的损失函数更新所述协同决策框架。具体的:2061:将所述混合评估网络模型设计为第一子网络和第二子网络,分别通过所述第一子网络和所述第二子网络,计算更新目标和联合状态动作估计值并比较,得到加权算子;根据所述加权算子,重构所述多智能体深度强化学习算法的损失函数。
67.在macdf中的混合评估网络中设计了两个子网络,分别是网络和网络,如图4所示;网络,使用的是与macdf相同的网络,包括了局部的智能体drqn网络和混合网络,网络通过最小化以下损失函数更新:式中,表示为更新目标target,即:表示为更新目标target,即:网络,和macdf类似,只不过去掉了单调性约束部分,表达能力比网络更强,网络通过最小化以下损失函数更新:设置一个加权算子重构损失函数的计算方式,具体表示如下:其中,表示用网络计算出来的更新目标target,表示网络的联合状态动作估计值;基于加权算子,重构后的损失函数为:。
68.通过设置一个加权算子w重构了macdf框架中神经网络的损失函数计算方式;加权算子w的作用在于精确地拟合三类兵棋算子最优联合状态动作价值。
69.2062:将多步回放数据结合得到多步回报,通过多步回报计算更新目标;根据所述更新目标,重构所述多智能体深度强化学习算法的损失函数。
70.将多步回放数据结合得到多步回报,更加精确的计算当前价值,缓解了奖励稀疏问题,提高了网络学习效率。
71.定义状态的n-step return为:基于n-step return可以定义macdf的目标回报为:通过目标回报重构损失函数的过程为:2063:采用重构的损失函数更新所述协同决策框架。
72.第一种优化机制为,通过设置一个加权算子w重构了macdf框架中神经网络的损失函数计算方式;加权算子w的作用在于精确地拟合三类兵棋算子最优联合状态动作价值,记优化的macdf模型为macdf-w。
73.第二种优化机制为,通过引入强化学习中的一种目标预测方式——n 步时序差分预测(n-step td),将n 步时序差分预测的结果作为macdf模型中神经网络的更新目标,进而重构了神经网络的损失函数计算方式。新的更新目标比原本macdf模型中单步时序差分预测目标能够更加精确的拟合目标值,记优化后的macdf模型为macdf-n。
74.也就是说,更新前的协同决策框架为macdf,更新后的协同决策框架为macdf-w或macdf-n。
75.208:根据更新后的协同决策框架,对多实体的异步协同进行决策。
76.上述基于强化学习的兵棋多实体异步协同决策方法,采用了深度强化学习算法,对多实体设置了不同的动作执行周期,对战术兵棋环境的态势信息执行mask操作得到局部观测用于智能体行为决策,构建了非完美信息下多实体异步协同决策问题实例。在此基础上设计了智能体网络agentnetwork用于多实体决策;设计了混合评估网络hanetwork用于评估多实体联合动作,构建了回放经验池模块保存智能体与环境的交互数据,并通过采样经验池的样本数据完成对神经网络的模型参数更新,最终形成了能够解决非完美信息下多实体异步协同决策问题的兵棋多实体异步协同决策框架即macdf模型。而且,提出了两种macdf的模型改进机制,第一种是通过设置一个加权算子w重构了macdf框架中神经网络的损失函数计算方式;加权算子w的作用在于精确地拟合三类兵棋算子最优联合状态动作价值。我们称优化的macdf模型为macdf-w。第二种是通过引入强化学习中的一种目标预测方式——n 步时序差分预测,将n 步时序差分预测的结果作为macdf模型中神经网络的更新
目标,进而重构了神经网络的损失函数计算方式。新的更新目标比原本macdf模型中单步时序差分预测目标能够更加精确的拟合目标值。我们称这种优化后的macdf模型为macdf-n。使用macdf模型能够解决在简单战术兵棋环境中非完美信息下多实体异步协作问题,在简单训练资源下通过有限的训练次数就能够达到较好的效果。使用优化后的macdf模型收敛速度更快、最终模型胜率更高、战斗效率更高。
77.本技术对四种算法iql、macdf、macdf
ꢀ‑
w以及macdf
ꢀ‑
n分别与内置规则智能体进行对抗训练,期间每隔一段时间测试胜率,结果如图5所示。
78.将训练时长设置为分别记录了iql算法、macdf算法、macdf
ꢀ‑
w算法(改进macdf的损失函数计算方法)和macdf
ꢀ‑
n算法(改进macdf的回报计算方法)与内置的规则智能体进行对战训练20000000(20m)timesteps的胜率情况,并绘制了胜率曲线,在训练过程中每隔10000时间步统计保存智能体模型并统计胜率信息和奖励信息等相关信息。
79.从图5中发现,随着训练时间步长的增多,macdf、macdf
ꢀ‑
w、macdf
ꢀ‑
n算法的胜率曲线稳步上升,经过大约10000000(10m)时间步后,算法胜率超过50%;经过大约12000000(12m)时间步后,算法开始收敛,胜率稳定在90%以上。
80.相比而言,iql算法由于价值计算会导致智能体之间互相影响,智能体难以通过统一的联合动作价值函数协同行动,无法解决兵棋环境下的多智能体异步协同问题。macdf算法能够在一定程度上解决异步协同问题,但是学习引导射击的效率不高,但是有时会低估引导射击动作对全局联合状态动作价值的贡献程度,无法快速的学习到该策略。可以发现macdf
ꢀ‑
n算法相较于macdf算法训练速度有显著的提升;并且macdf
ꢀ‑
w和macdf
ꢀ‑
n算法最终稳定后的胜率都比macdf算法高。
81.从图5中还可以发现,macdf、macdf
ꢀ‑
w、macdf
ꢀ‑
n算法均具有良好的性能,最终训练模型都能够到达一个比较高的胜率。在训练了20m时间步之后,iql算法的测试胜率为33%,macdf算法的测试胜率为91%,macdf
ꢀ‑
w算法的测试胜率为95%,macdf
ꢀ‑
n的测试胜率为97%,改进后的两种算法最终的测试胜率更高。macdf
ꢀ‑
w和macdf
ꢀ‑
n算法相较于macdf算法训练速度有显著的提升,macdf在6.4m时间步时模型胜率超过50%,macdf
ꢀ‑
w在9.2m时间步时模型胜率超过50%,macdf
ꢀ‑
n在10.5m时间步时模型胜率超过50%。macdf
ꢀ‑
w和macdf
ꢀ‑
n相比于macdf能够更快的学习到较高的胜率模型,并且最终的胜率都超过了macdf算法,这说明了本技术中改进macdf的有效性。
82.本技术还对四种算法iql、macdf、macdf
ꢀ‑
w以及macdf
ꢀ‑
n分别与内置规则智能体进行对抗训练,期间每隔一段时间测试平均对局时长并记录,结果如图6所示。
83.通过图6可以发现,随着训练时间步长的增多,macdf
ꢀ‑
w、macdf
ꢀ‑
n和macdf都能够在较短的时间步长内全歼敌方作战单元并取得胜利。在最终的模型中,macdf算法大概在平均时间步长205时间步后就能够胜利,macdf
ꢀ‑
n算法大概在平均时间步长181时间步后就能够胜利,macdf
ꢀ‑
w算法大概在平均时间步长148时间步后就能够胜利。由此发现,改进后的macdf算法(包括macdf
ꢀ‑
w和macdf
ꢀ‑
n)行动效率更高,这是由于改进后的macdf算法能够在一开始为引导射击动作做准备,减少了无效的动作步长,提高了战斗效率。macdf
ꢀ‑
w算法的
战斗效率更高,能够更快结束战斗。
84.通过基于强化学习的兵棋多实体异步协同决策深度强化学习的兵棋多实体异步协同决策方法在兵棋环境中解决兵棋智能决策问题的以上对比试验可以发现,改进后的macdf
ꢀ‑
w和macdf
ꢀ‑
n算法都能够表现出较macdf更加优异的性能;其中macdf
ꢀ‑
w训练的模型单局游戏时长最短,相较于macdf提升了27%;macdf
ꢀ‑
n训练的模型最终测试胜率最高,相较于macdf提升了6%。
85.如图7所示,本技术还提供了一种基于强化学习的兵棋多实体异步协同决策深度强化学习的兵棋多实体异步协同决策装置,在一个实施例中,包括:获取模块702、建模模块704、重构模块706和决策模块708,其中:获取模块702,用于获取兵棋推演环境以及与所述兵棋推演环境相对应的多实体异步协同决策问题,对所述多实体异步协同决策问题进行建模分析,得到初始模型;建模模块704,用于根据所述初始模型,采用多智能体深度强化学习算法,建立智能体网络模型和混合评估网络模型;根据所述智能体网络模型和混合评估网络模型进行循环计算,根据计算结果对所述智能体网络模型和所述混合评估网络模型进行训练,得到所述多实体异步协同决策问题的协同决策框架;重构模块706,用于通过设置加权算子优化所述多智能体深度强化学习算法的损失函数计算机制,或通过多步回报优化所述多智能体深度强化学习算法的奖励回报计算机制,重构所述多智能体深度强化学习算法的损失函数;采用重构的损失函数更新所述协同决策框架;决策模块708,用于根据更新后的协同决策框架,对多实体的异步协同进行决策。
86.关于基于强化学习的兵棋多实体异步协同决策装置的具体限定可以参见上文中对于基于强化学习的兵棋多实体异步协同决策方法的限定,在此不再赘述。上述装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
87.以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
88.以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1