通用文本OCR的训练数据生成方法及系统与流程
通用文本ocr的训练数据生成方法及系统
技术领域
1.本发明涉及文字识别方法技术领域,特别涉及一种通用文本ocr的训练数据生成方法及系统。
背景技术:
2.随着机器学习和深度学习的发展,在光学字符识别(ocr)领域,深度学习算法的不断迭代更新,学习能力不断提高,由于深度学习是靠数据驱动的,所以结合数据生成算法生成大量的数据,可以获得很好的识别效果。
3.但是通用ocr领域涉及的场景非常多而且非常复杂,主要是体现在图像中文本行在不同场景下的放置角度变化很大(横向,纵向,倾斜等各种角度);背景图片越来越复杂(各种图案,颜色混合等复杂背景);图片中含有各类字体的文字混合,导致现有的数据生成算法达不到要求。具体来说,现有方法存在以下问题:其一,现有的数据生成算法主要是解决横向文本的训练数据生成,没有对竖直文本和倾斜角度较大的文本数据进行生成,导致这类数据(比如名称牌匾,广告牌等)在实际场景中识别效果很差;其二,现有的数据生成算法背景是由特定场景图片背景或者单一的纯色背景,对通用场景任务中包括各类图案,混合的颜色等等的复杂背景下的图片识别效果很差;其三,现有的数据生成算法字体采用特定字体或者指定字体,对数据图片(比如网页截图,广告牌等)中混合多种字体的情况的图片识别效果很差;其四,图片和文本融合的时候采用颜色差值算法决定文本颜色和背景颜色,现在的数据大多包含复杂的背景和各种颜色的文本,并且文本颜色和背景颜色有很好的对比度,颜色差值算法适用于颜色单一的背景来融合图片,面对复杂的背景生成的图片中文本和背景的对比度就很差,导致文本很模糊,识别效果较差。
4.为了避免上述不足,成都无糖信息技术有限公司的《一种基于机器学习的通用ocr的训练数据生成系统及方法》(公开号:cn112418224a),公开了如下技术方案:一种基于机器学习的通用ocr的训练数据生成方法,其包括以下步骤:文字信息生成:从语料库中随机抽取5-10个文字作为文字信息;字体信息生成:从字体库中随机选择字体生成字体信息;背景图片的选取、尺寸处理:从图片库中随机抽取背景图片,依据通过字体信息生成的文字信息对图片进行裁剪;文字颜色选取:1)判断裁剪出的背景图片的尺寸是否符合要求,否则对背景图片进行尺寸转换;2)对背景图片预处理转换成颜色序列数据;3)初始化聚类算法,然后对背景图片进行聚类分析,计算每个类别有多少数据并获取多个聚类中心;4)获取多个聚类中心所属的背景颜色值和到各个聚类中心的差值并对差值从大到小进行排序;5)从收集的文本文字颜色库中随机选取500个颜色作为候选颜色;6)根据背景颜色的差值排序结果,设置多个聚类中心的距离计算权重,排序越靠前的权重越大,依次计算每个随机选取的候选颜色到每个聚类中心的差值,将差值进行求和,获取候选颜色到背景颜色的差值,将每个候选颜色计算的差值进行从大到小排序;7)从候选颜色到背景颜色的差值距离计算结果中选取最大的200个颜色,然后从200个颜色中随机选择1-3种作为文本颜色;图片生成:将文字信息、字体信息、背景图片、文字颜色进行结合,生成一张可直接用于文本识别模型训
练的图片,并保存该图片的文本信息为标签数据。
5.通过上述方案,虽然能够实现ocr训练数据的生成,但由于其通过复杂的算法实现文字颜色的选取,导致其生成数据集的速度很慢。对于待训练的模型来说,用于训练的数据集样本数量动辄几十万、几百万,通过上述算法生成训练样本时,需要耗费非常多的时间。
技术实现要素:
6.本发明的首要目的在于提供一种通用文本ocr的训练数据生成方法,能够快速生成ocr训练数据样本。
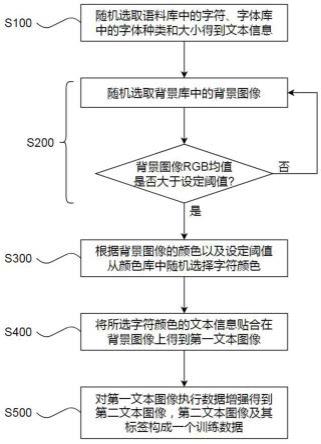
7.为实现以上目的,本发明采用的技术方案为:一种通用文本ocr的训练数据生成方法,包括如下步骤:s100、随机选取语料库中的字符、字体库中的字体种类和大小得到文本信息;s200、随机选取背景库中的背景图像,并判断背景图像的rgb均值pix_mean是否大于等于阈值k,,若是则执行下一步,否则重新随机选取背景图像;s300、根据背景图像的rgb均值pix_mean计算出字符颜色的取值范围,并从颜色库中随机选取满足该取值范围的字符颜色font_color;s400、将文本信息按照选取的字符颜色font_color贴合在背景图像上得到第一文本图像;s500、对第一文本图像执行数据增强得到第二文本图像,第二文本图像及其标签构成一个训练数据,所选取的字符内容即为第二文本图像的标签。
8.本发明的另一个目的在于提供一种通用文本ocr的训练数据生成系统,能够快速生成ocr训练数据样本。
9.为实现以上目的,本发明采用的技术方案为:一种通用文本ocr的训练数据生成系统,包括语料库、字体库、背景库、颜色库、数据生成模块以及数据增强模块;所述的语料库用于保存具有连续语义的文字数据,字体库、背景库、颜色库分别用于保存真实文本场景中的常用字体、背景图像、字符颜色;数据生成模块从语料库中随机选取字符、从字体库中随机选取字体及大小得到文本信息;数据生成模块随机选取背景库中的背景图像,并判断背景图像的rgb均值pix_mean是否大于等于阈值k,,若不是则重新随机选取背景图像,否则根据背景图像的rgb均值pix_mean计算出字符颜色的取值范围,并从颜色库中随机选取满足该取值范围的字符颜色font_color;数据生成模块将文本信息按照选取的字符颜色font_color贴合在背景图像上得到第一文本图像;数据增强模块对第一文本图像执行数据增强得到第二文本图像,第二文本图像及其标签构成一个训练数据,所选取的字符内容即为第二文本图像的标签。
10.与现有技术相比,上述方法和系统存在以下技术效果:本发明中,通过计算背景图像的rgb均值pix_mean以及设定的阈值k,首先排除掉深色的背景图像,尽量模拟真实文本场景;其次,根据pix_mean和k通过简单的加减计算出字符颜色的取值范围,最后从颜色库中随机选择满足该取值范围的字符颜色即可确定最终的文字颜色,该计算过程非常的巧妙,只有简单的判断、加减,耗时非常短;在此基础上,也使得训练数据的生成速度非常的快,经过我们的实测,训练100万张样本图片只需要短短的3个小时,而采用对比文件1的方案,则需要4.5~6个小时。
附图说明
11.图1是本发明的流程图;图2是本发明中随机生成的训练数据;图3是背景图像选取流程图;图4是文本贴合流程图;图5是本发明的结构框图。
具体实施方式
12.下面结合图1至图5,对本发明做进一步详细叙述。
13.参阅图1,本发明公开了一种通用文本ocr的训练数据生成方法,包括如下步骤:s100、随机选取语料库中的字符、字体库中的字体种类和大小得到文本信息;s200、随机选取背景库中的背景图像,并判断背景图像的rgb均值pix_mean是否大于等于阈值k,,若是则执行下一步,否则重新随机选取背景图像;s300、根据背景图像的rgb均值pix_mean计算出字符颜色的取值范围,并从颜色库中随机选取满足该取值范围的字符颜色font_color;s400、将文本信息按照选取的字符颜色font_color贴合在背景图像上得到第一文本图像,假设我们随机选择的字符颜色font_color为10,在贴合时,字符图像也是rgb格式的图像,其r=g=b=font_color=10;s500、对第一文本图像执行数据增强得到第二文本图像,第二文本图像及其标签构成一个训练数据,所选取的字符内容即为第二文本图像的标签。通过计算背景图像的rgb均值pix_mean以及设定的阈值k,首先排除掉深色的背景图像,尽量模拟真实文本场景;其次,根据pix_mean和k通过简单的加减计算出字符颜色的取值范围,最后从颜色库中随机选择满足该取值范围的字符颜色即可确定最终的文字颜色,该计算过程非常的巧妙,只有简单的判断、加减,耗时非常短;在此基础上,也使得训练数据的生成速度非常的快。
14.以生成1万张样本图片为例,我们进行了五次实测,其耗时分别为:106.3856s、105.4782s、105.9245s、106.1278s、105.8427s,平均生成1万张样本图片耗时:105.9518s;按此时间,生成100万张样本图片需要10595秒,也即2小时56分,约3个小时。当采用对比文件1中的方案时,平均生成1万张样本图片耗时150~200秒,按此时间,生成100万张样本图片约需要4.5~6个小时。
15.进一步地,所述的步骤s500中,数据增强包括添加边框、旋转、添加随机数学图形、细节增强滤波或高斯滤波、添加随机点噪声、形态学操作中的一种或多种。生成第一文本图像后,继续对其执行数据增强得到第二文本图像,通过执行数据增强以后,所生成的第二文本图像更加符合真实文本场景中的包含文字的图像,利用此数据训练得到的ocr识别模型进行识别时准确率也自然得到提升;同时,这里的数据增强方式多样,可以应对不同场景下的文字识别,比如通过添加边框,可以增强对表格中文字的识别准确率。
16.进一步地,所述的添加边框为在文字的上、下、左、右四个方位中任意一个或多个方位中添加随机长度、随机宽度的线段,这种线段就是用于模拟表格的边框,通过添加边框对训练数据进行增强以后,利用该训练数据对ocr识别模块进行训练,该识别模块采用crnn+ctcloss结构构造,采用传统的训练数据对该识别模块进行训练后得到的模型,进行表格文字的ocr识别,准确率只有81.5633%,通过本发明中经过数据增强的训练数据对该识别模
块进行训练后得到的模型,进行表格文字的ocr识别,准确率上升到89.8592%。
17.进一步地,旋转的角度为,通过旋转对数据进行增强;随机数学图形中的数学图形为三角形、正方形、直线中的一种或多种;之所以选择细节增强滤波或高斯滤波,是由于卷积计算对高频部分较敏感,所以不要使用:模糊滤波、双边/中值/均值滤波、平滑滤波,这样可以突出图像的宽大区域、低频成分、主干部分,抑制图像噪声和干扰高频成分,使图像亮度平缓渐变,减小突变梯度,改善图像质量;形态学操作为常见的膨胀和/或腐蚀处理,具体包括膨胀处理、腐蚀处理、先膨胀后腐蚀处理或者先腐蚀后膨胀处理。
18.参阅图2,通过这些处理,可以明显的看出,增加了数据增强模块后,生成的训练数据与真实文本场景更加接近,基于此训练数据训练出来的模型进行ocr识别时也更加准确,且能适应更多的场景。
19.参阅图3,进一步地,所述的步骤s200中包括如下步骤:s210、随机选取背景库中的背景图像;s220、对背景图像进行剪裁,剪裁后的背景图像尺寸满足如下公式:式中,height和width是裁剪后背景图像的高和宽,n_max为所选取字符个数的最大值,height_font_max和width_font_max为所选取的最大字体的高和宽,为预留的边缘尺寸;剪裁成这样的尺寸,可以针对任何随机选择的字符,在贴合在剪裁后的背景图像上时,四周至少都能预留出的预留尺寸,并且剪裁后的背景图像尺寸更小,处理起来速度更快。s230、判断剪裁后的背景图像的rgb均值pix_mean是否大于等于阈值k,;若是则执行下一步,否则重新随机选取背景图像或重新剪裁背景图像。这里之所以需要对pix_mean进行判定,是当pix_mean较小时,背景图像的颜色较深,上面的文字很难看清,在真实文本场景中也几乎不存在这种深色的背景图像,因此,我们舍弃掉颜色特别深的背景图像。
20.参阅图4,进一步地,所述的步骤s400中包括如下步骤:s410、按如下公式随机选取文字贴合的起始坐标(x,y):式中,width_font和height_font是所选取的字体的宽和高,n为所选取的字符个数;s420、将文本信息按照选取的字符颜色font_color和贴合坐标(x,y)贴合在剪裁的背景图像上得到第一文本图像。这里所说的坐标,都是以剪裁后背景图像的左上角点为原点、以横向向右为x轴正方向、以纵向向下为y轴正方向构成的二维坐标系为参考的,起始坐标(x,y)即贴合时文字的左上角点坐标,通过上述公式计算得到的起始坐标(x,y),一方面可以保证所有文字都会完全显示在剪裁后的背景图像上,另一方面可以保证文字在贴合以后,与被剪裁的背景图像边缘留有一定的间隙,方便执行后续的数据增强。
21.进一步地,所述的语料库通过选择符合字频表统计数据以及具有连续语义的文字数据构建;所述的字体库通过真实文本场景中的常用字体及其统计频率构建;所述的背景库通过真实文本场景中的背景图像构建;所述的颜色库通过真实文本场景中的字符颜色构建。语料库、字体库、背景库以及颜色库中的数据可以随时增减,这里面的数据越多,随机生
成的训练样本差异越大,因此,应尽可能的提高各库里的数据量。
22.进一步地,所述的随机选取语料库中的字符、字体库中的字体种类和大小得到文本信息步骤中:选取的字符个数为5-10个,也即n_max等于10;字体大小为17-27,也即height_font_max和width_font_max对应的是27号字体的长和宽。
23.参阅图5,本发明还公开了一种通用文本ocr的训练数据生成系统,包括语料库、字体库、背景库、颜色库、数据生成模块以及数据增强模块;所述的语料库用于保存具有连续语义的文字数据,字体库、背景库、颜色库分别用于保存真实文本场景中的常用字体、背景图像、字符颜色;数据生成模块从语料库中随机选取字符、从字体库中随机选取字体及大小得到文本信息;数据生成模块随机选取背景库中的背景图像,并判断背景图像的rgb均值pix_mean是否大于等于阈值k,,若不是则重新随机选取背景图像,否则根据背景图像的rgb均值pix_mean计算出字符颜色的取值范围,并从颜色库中随机选取满足该取值范围的字符颜色font_color;数据生成模块将文本信息按照选取的字符颜色font_color贴合在背景图像上得到第一文本图像;数据增强模块对第一文本图像执行数据增强得到第二文本图像,第二文本图像及其标签构成一个训练数据,所选取的字符内容即为第二文本图像的标签。该系统具有和上述方法相同的优点和技术效果,此处不再重复赘述。
24.本发明还公开了一种计算机可读存储介质和一种电子设备。其中,一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现前述的通用文本ocr的训练数据生成方法。一种电子设备,包括存储器、处理器及存储在存储器上的计算机程序,所述处理器执行所述计算机程序时,实现前述的通用文本ocr的训练数据生成方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1