基于子特征融合的轻量化安全帽检测方法
1.本发明涉及图像识别与计算机视觉领域,具体涉及一种基于子特征融合的轻量化安全帽检测方法。
背景技术:
2.在建筑工地中,施工人员必须佩戴安全帽保障自身的工作安全性。建筑业是所有行业中较为危险的行业之一,美国劳工统计局(bls) 的数据显示,建筑业的死亡人数远高于其他所有行业,致命伤害率也高于全部行业的全国平均水平。负责人员监管不力,施工人员没有严格遵守建筑工地的相关安全规定,佩戴安全帽和安全背心等安全防护设备,导致安全事故频繁发生。美国职业安全与健康管理局(osha)要求所有在施工现场的工作人员佩戴安全帽,以最大限度地减少安全事故的发生或降低安全事故导致的伤害。美国国家职业安全与健康研究所(niosh)的一份报告显示,在2003年至2010年期间,全美共有2,210人因脑外伤(tbi)死亡,占同期建筑业所有死亡人数的25%。在工业生产过程中,脑外伤事故发生的最常见原因是工人从高处坠落或物体掉落砸伤工人头部,佩戴安全帽可以最大程度地减少头部受到的伤害。研究表明,如果工人在工作时佩戴安全帽,可以避免大多数安全事故的发生。
3.目前,对于以上安全帽佩戴情况的识别主要以人工检查的方式为主。人工检查容易被各种各样的因素干扰降低效率,并且无法实行全天候监控且浪费人力资源,所以这种方法效率比较低下,各安全监管部门的实际需求无法得到充分满足。通过监控摄像头等设备,并利用基于机器视觉的检测算法对工人的安全帽佩戴情况进行自动识别,可以实现实时监控,避免人工检测中由于各种主观因素造成的漏检和误检等问题,在节省人力资源的同时还可以提高监管的效率及自动化水平。由于深度学习模型的体积和计算量过于庞大,难以直接在监控摄像头、无人机等互联网边缘设备上使用,且现有的大多数检测模型检测速度较慢,无法满足实时检测需求。
技术实现要素:
4.有鉴于此,本发明的目的在于提供一种基于子特征融合的轻量化安全帽检测方法,能够有效减少检测模型的模型大小,并且对工人是否佩戴安全帽进行精准检测。
5.为实现上述目的,本发明采用如下技术方案:
6.一种基于子特征融合的轻量化安全帽检测方法,包括以下步骤:
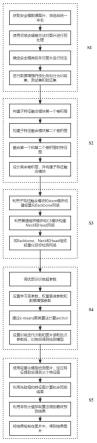
7.步骤s1:获取安全帽数据图片,并预处理,构建安全帽检测数据集;
8.步骤s2:构建子特征融合的轻量化网络模块,通过低代价卷积操作生成子特征图并与初始特征图进行融合;
9.步骤s3:利子特征融合的轻量化网络模块和stem模块构建轻量化backbone网络,利用普通卷积模块和c3模块构建neck和head,再将轻量化backbone网络,neck和head组成一个轻量化目标检测网络;
10.步骤s4:对yolov5目标检测算法的训练超参数进行调优,利用安全帽检测数据集训练轻量化目标检测网络得到安全帽检测模型;
11.步骤s5:根据安全帽检测模型对输入图片进行检测,获取初步检测结果,对初步检测结果进行解码后采用改进的非极大值抑制算法筛选出最终的检测结果,将检测结果绘制在原图中。
12.进一步的,所述步骤s1,具体为:
13.步骤s11;获取安全帽相关的数据图片,筛选图片并统一命名;
14.步骤s12:采用邻域去噪、中值滤波对图片进行处理;
15.步骤s13:确定安全帽图片中的物体类别,使用labelimg标注工具对预处理后的数据图片进行标注,得到并保存标注信息;
16.步骤s14:使用几何变换对标注后的数据图片进行数据增强,然后根据yolov5模型要求制作数据集,将所有数据按比例分为训练集,验证集和测试集,根据包含图片数据标注信息的xml文件生成训练模型所需的txt文件。
17.进一步的,所述子特征融合的轻量化网络模块包括第一卷积层、深度可分离卷积层和第二卷积层;
18.所述第一卷积层,实际输出通道数设为传入输出通道参数值的一半,对输入特征图进行卷积操作后生成输出特征图;
19.所述第二卷积层,同样将该卷积层的实际输出通道数设为传入输出通道参数值的一半,该卷积层将第一卷积层的输出特征图作为输入特征图,进行卷积之后生成子特征图作为输出特征图;
20.将第一个卷积层的输出特征图和第二个卷积层生成的子特征图进行融合,作为最终的输出特征图。
21.进一步的,所述步骤s3,具体为:
22.步骤s31:利用子特征融合模块和stem模块构建轻量化 backbone网络,backbone网络的第一层使用stem模块;
23.步骤s32:利用普通卷积模块和c3模块构建neck和head,普通卷积模块和c3模块交叉搭建构成neck和head网络;
24.步骤s33:将backbone,neck和head网络组成一个轻量化目标检测网络,其中backbone和neck之间进行多尺度特征融合,提高检测网络精度。
25.进一步的,所述c3模块由三个卷积层和一个标准瓶颈层组成,
26.进一步的,所述步骤s4,具体为:
27.步骤s41:根据预设实验得出超参数的最优值,调优超参数将使训练模型达到最优;
28.步骤s42:将标注文件中的标注框参数作为输入数据,使用k-means聚类算法根据标注框计算数据集的先验框anchor;
29.步骤s43:设置训练迭代次数为n,设置数据图片读取批次 batch-sizes,训练完成后得到安全帽检测模型。
30.进一步的,所述步骤s42具体为:
31.步骤s421:使用数据集图像的宽高w
img
,h
img
对标注框boundingbox 的宽高w
box
,h
box
做归一化,具体为:
[0032][0033]
其中,w
normalize
,h
normalize
为归一化后的宽和高;
[0034]
步骤s422:令anchor=(w
anchor
,h
anchor
),box=(w
box
,h
box
),w
anchor
,h
anchor
为先验框anchor的宽和高,使用交并比iou作为度量,其计算方式如下:
[0035][0036]
iou的取值在0到1之间,两个box重合度越高则iou值越大, d为最终度量,其计算公式为:
[0037]
d=1-iou(box,anchor)
[0038]
步骤s423:在数据集中随机选取box_k个bounding box作为初始先验框anchor,然后计算每个标注框和这些anchor的iou度量,将每个bounding box分配给与其距离最近的anchor,遍历所有 boundingbox后,计算每个簇中所有boundingbox宽和高的均值,更新anchor,重复以上步骤直到anchor不再变化或者达到了最大迭代次数。
[0039]
进一步的,所述步骤s5具体为:
[0040]
步骤s51:利用安全帽检测模型进行检测任务,输入的数据图片经过特征提取网络处理后将得到三个不同尺寸的特征图;
[0041]
步骤s52:利用特征图和通过k-means聚类算法计算得到的先验框anchor计算预测框的大小和位置信息,得到图片的初步预测结果;
[0042]
步骤s53:使用非极大值抑制算法处理初步预测结果,在所有预测框中寻找每一类别中置信度最大的预测框并抑制其他预测框;
[0043]
步骤s54:经过非极大值抑制后得到最终的检测框,将检测框绘制在原图中,得到结果图片。
[0044]
进一步的,所述步骤s52具体为:
[0045]
步骤s521:将图片划分为s
×
s个网格,然后把根据k-means算法聚类得到的先验框anchor调整到图片中;
[0046]
步骤s522:从网络预测结果中获取预测框信息x
offest
,y
offset
,其分别表示预测框相对其对应的先验框在x、y轴的偏移值,同时获取对应先验框的宽、高w
anchor
,h
anchor
;
[0047]
步骤s523:使用网格对应的先验框的中心点坐标和偏移量 x
offest
,y
offset
计算得到预测框的中心点坐标,再利用先验框的宽高 w
anchor
,h
anchor
计算得到预测框的宽和高,最终得到预测框的大小和位置信息。
[0048]
进一步的,所述步骤s53具体为:
[0049]
步骤s531:使用非极大值抑制算法将对所有预测框进行处理,首先将属于不同物体类别的预测框按置信度从大到小进行排序,然后取出每个类别中置信度最高的预测框分别与其余预测框计算iou;
[0050]
按照交并比iou寻找局部最大值的过程,设两个检测框b1和b2,则二者之间的交并比如下:
[0051][0052]
步骤s532:若计算结果大于所设定阈值则该预测框被抑制,不会作为结果输出,计算完所有预测框后,取出剩余预测框中拥有最大置信度的预测框。
[0053]
本发明与现有技术相比具有以下有益效果:
[0054]
1、本发明构建的基于子特征融合的轻量化安全帽检测方法,相较于其他现有方法,检测模型非常轻量且能够实现对安全帽的实时检测;
[0055]
2、本发明对卷积神经网络参数量和计算量巨大的问题,提出子特征融合方法,融合父特征图和子特征图,能够以较小的代价取得几乎和原始网络相同的检测效果;
[0056]
3、本发明能够实现在移动端部署。
附图说明
[0057]
图1是本发明方法流程示意图。
具体实施方式
[0058]
下面结合附图及实施例对本发明做进一步说明。
[0059]
请参照图1,本发明提供基于子特征融合的轻量化安全帽检测方法,包括以下步骤:
[0060]
步骤s1:获取安全帽数据图片,筛选图片并统一命名,然后根据yolov5目标检测算法要求构建安全帽检测数据集;
[0061]
步骤s2:利用普通卷积模块设计子特征融合,通过低代价卷积操作生成子特征图并与初始特征图进行融合,设计基于子特征融合的轻量化网络模块,可以显著减少检测模型的参数量和计算量;
[0062]
步骤s3:利用子特征融合模块和stem模块构建轻量化 backbone网络,利用普通卷积和其他网络模块构建neck和head,再将backbone,neck和head组成一个轻量化目标检测网络;
[0063]
步骤s4:对yolov5目标检测算法的训练超参数进行调优,利用安全帽检测数据集训练轻量化网络模型得到安全帽检测模型;
[0064]
步骤s5:根据训练后得到的安全帽检测模型对输入图片进行检测,获取初步检测结果,对初步检测结果进行解码后采用改进的非极大值抑制算法筛选出最终的检测结果,将检测结果绘制在原图中。
[0065]
在本实施例中,步骤s1,具体为:
[0066]
步骤s11:获取安全帽相关的数据图片,筛选图片并统一命名;
[0067]
步骤s12:采用包括邻域去噪、中值滤波等方法对图片进行预处理;
[0068]
步骤s13:确定安全帽图片中的不同物体类别,使用labelimg 标注工具对预处理后的数据图片进行标注,得到并保存标注信息;
[0069]
步骤s14:使用几何变换对图片进行数据增强,然后根据yolov5 模型要求制作数据集,将所有数据按比例分为训练集,验证集和测试集,根据包含图片数据标注信息的xml文件生成训练模型所需的txt 文件。
[0070]
在本实施例中,步骤s2,具体为:
[0071]
步骤s21:设计第一个卷积层,将该卷积层的实际输出通道数设为传入输出通道参数值的一半,对输入特征图进行卷积操作后生成输出特征图;
[0072]
步骤s22:设计第二个卷积层,同样将该卷积层的实际输出通道数设为传入输出通道参数值的一半,该卷积层将第一个卷积层的输出特征图作为输入特征图,进行卷积之后生成子特征图作为输出特征图;
[0073]
步骤s23:将第一个卷积层的输出特征图和第二个卷积层生成的子特征图进行融合,作为最终的输出特征图;
[0074]
步骤s24:构建子特征融合模块,该模块分为三部分,第一部分和第三部分由上述的两个卷积层构成,第二部分由深度可分离卷积层构成。
[0075]
在本实施例中,步骤s3,具体为:
[0076]
步骤s31:利用子特征融合模块和stem模块构建轻量化 backbone网络,backbone网络的第一层使用stem模块,可以使用卷积和池化两条路径提取不同特征,在没有增加过多计算耗时的同时,提高网络的特征表达能力,其余网络层利用子特征模块构建,减少网络计算量和参数量;
[0077]
步骤s32:利用普通卷积模块和c3模块构建neck和head,其中c3模块由三个卷积层和一个标准瓶颈层组成,普通卷积模块和c3 模块交叉搭建构成neck和head网络;
[0078]
步骤s33:将backbone,neck和head网络组成一个轻量化目标检测网络,其中backbone和neck之间进行多尺度特征融合,提高检测网络精度。
[0079]
在本实施例中,步骤s4具体包括以下步骤:
[0080]
步骤s41:根据多次实验得出相关训练文件中超参数的最优值,调优超参数将使训练模型达到最优;
[0081]
步骤s42:在yolov5的训练配置文件中将初始学习率lr设为 0.01,动量梯度下降中的动量参数momentum设为0.937;
[0082]
步骤s43:根据数据集设置数据增强参数,将图片缩放系数scale 和图片旋转系数translate分别设置为0.5和0.1,将mosaic和mixup 两种数据增强方法的参数分别设为0.9和0.5;
[0083]
步骤s44:将标注文件中的标注框参数作为输入数据,使用k-means聚类算法根据标注框计算数据集的先验框anchor。使用数据集图像的宽高w
img
,h
img
对标注框boundingbox的宽高w
box
,h
box
做归一化,具体为:
[0084][0085]
其中,w
normalize
,h
normalize
为归一化后的宽和高;
[0086]
令anchor=(w
anchor
,h
anchor
),box=(w
box
,h
box
),w
anchor
,h
anchor
为先验框anchor 的宽和高,使用交并比iou作为度量,其计算方式如下:
[0087][0088]
iou的取值在0到1之间,两个box重合度越高则iou值越大, d为最终度量,其计算
公式为:
[0089]
d=1-iou(box,anchor)
[0090]
在数据集中随机选取box_k个bounding box作为初始先验框 anchor,然后计算每个标注框和这些anchor的iou度量,将每个 boundingbox分配给与其距离最近的anchor,遍历所有bounding box 后,计算每个簇中所有boundingbox宽和高的均值,更新anchor,重复以上步骤直到anchor不再变化或者达到了最大迭代次数;
[0091]
步骤s45:设置训练迭代次数为600,设置数据图片读取批次 batch-sizes为32,训练完成后得到安全帽检测模型。
[0092]
在本实施例中,步骤s5具体为:
[0093]
步骤s51:利用训练得到的模型检测图片,输入数据图片经过特征提取网络处理后将得到三个不同尺寸的特征图;
[0094]
步骤s52:利用特征图和通过k-means聚类算法计算得到的先验框anchor计算预测框的大小和位置信息,得到图片的初步预测结果。将图片划分为s
×
s个网格,然后把根据k-means算法聚类得到的先验框anchor调整到图片中;从网络预测结果中获取预测框信息 x
offest
,y
offset
,其分别表示预测框相对其对应的先验框在x、y轴的偏移值,同时获取对应先验框的宽、高w
anchor
,h
anchor
;使用网格对应的先验框的中心点坐标和偏移量x
offest
,y
offset
计算得到预测框的中心点坐标,再利用先验框的宽高w
anchor
,h
anchor
计算得到预测框的宽和高,最终得到预测框的大小和位置信息;
[0095]
步骤s53:使用非极大值抑制算法处理初步预测结果,在所有预测框中寻找每一类别中置信度最大的预测框并抑制其他预测框。使用非极大值抑制算法将对所有预测框进行处理,首先将属于不同物体类别的预测框按置信度从大到小进行排序,然后取出每个类别中置信度最高的预测框分别与其余预测框计算iou;
[0096]
按照交并比iou寻找局部最大值的过程,设两个检测框b1和b2,则二者之间的交并比如下:
[0097][0098]
步骤s532:若计算结果大于所设定阈值则该预测框被抑制,不会作为结果输出,计算完所有预测框后,取出剩余预测框中拥有最大置信度的预测框;
[0099]
步骤s54:经过非极大值抑制后得到最终的检测框,将检测框绘制在原图中,得到结果图片。
[0100]
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1