基于用户体验分析的深度强化学习式智能门锁系统及装置的制作方法
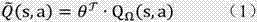
本发明涉及一种基于用户体验分析的深度强化学习式智能门锁系统及装置,尤其涉及无人工参与下的智能学习式门锁开关系统,属于人工智能决策领域。
背景技术:
随着5g无线系统的发展和应用,机器-对-机器(machinetomachine)的世界也即将在强“人工智能+”时代的催生下涌现在人们的日常生活中如:智能家居、车联网、无人机、时控机器人等,无线世界已经实现了与人类的互联互通,自动化和智能化已被视为是面向行业应用一种新趋势。例如,由谷歌深灵(deepmind)公司打造出的具有深度强化学习技术的围棋冠军alphago,其智能化的学习技术为人工智能时代带来新的契机,其实现了类似人脑的功能:智能的实现学习。因此这种学习式的方法对智能门锁系统展现出巨大的潜力和应用价值。
目前,现有的门锁系统有存的弊端如下:
(1)采用钥匙手动开锁的门锁系统,本身不依赖与电子系统,使用的时间较长,然而,其潜藏着钥匙易丢、易盗和易复制的安全隐患,是安全系数较低的一种锁具,并且用户出门携带钥匙,用户体验质量较差。随着科技化、智能化的逆袭,以及人们对家居智能化的体验要求与日俱增,因此此种门锁系统将会逐渐淡出应用市场。
(2)采用人脸识别/指纹/密码手动开锁的门锁系统,此种形式的门锁系统已经在市场上屡见不鲜,但目前的人脸识别或指纹或密码的形式开锁仍然需要门锁主人或者预先设定的门锁家属或者已知密码的家人手动开锁,其仍然具有手动性质即:开锁者需要点击相应的锁具开锁按钮,人为的参与其识别验证等开锁过程,并且若为密码验证,还需要记住设定的密码等,这种形式的门锁系统,不免有费时费心之嫌,用户体验质量的评价自然不高。
(3)采用wifi的远程控制终端app进行开锁的门锁系统,此种形式因为需要周期性的更换电池或者给电池充电,一定程度上依赖于装有开锁app的设备。在断网的情况下遥控开锁或者远程终端开锁则在系统上不起作用,并且仍然需要用户随身携带和保管,易丢失和窃取之嫌。用户体验质量自然会大打折扣。
目前,没有相关工作考虑带有用户体验质量(qoe)分析的智能学习式的开/关门锁系统及装置。该系统是具有qoe分析的线上线下式的学习算法,实现了智能学习式开关锁系统,避免了人工干预的开锁的繁琐过程。
技术实现要素:
技术问题:本发明针对上述方案中尚存的空白,提出了一种基于用户体验分析的深度强化学习式智能门锁系统及装置。该系统是具有用户体验质量(qoe)分析的线上线下式的学习算法,对用户行为进行综合判断,智能决策,并设计出智能门锁系统的装置,从而实现多元化、智能化学习式的开/关锁系统。增强用户的体验质量。
技术方案:本发明提出一种基于用户体验分析的深度强化学习式智能门锁系统及装置。首先,我们设计智能门锁系统的强化学习模型,并提出改进的线上线下强化学习算法,该算法对用户的qoe分析,通过分析将搜索空间:状态-行为对的空间降维;此外,为克服强化学习带有的延迟奖励或者惩罚,而影响到后续学习过程,即根据此奖励或者惩罚计算下一时刻状态的值函数或者根据此奖励或者惩罚决定下一时刻行为的选择,为此,我们采用带有临时记录功能的资格迹进行信用评分,从而避免强化学习中具有的延迟赏罚的弊端。最后,该算法作为核心模块,设计出智能门锁系统的装置,从而实现多元化、智能化学习式的开/关锁系统。增强用户的体验质量。
进一步地,所述的强化学习模型,其是在没有指导的情况下,通过探索和利用进行不断地累计经验的学习,尽管会遇到各种环境的各种不确定性。整个学习过程是通过经验回放池对经验数据进行存储,从而增加先验知识。这个过程也称为带有延迟奖励或者惩罚的试错学习。
所述的基于用户体验分析的深度强化学习式智能门锁系统及装置,包括微处理器、环境识别模块、智能学习模块、供电模块、语音通信模块、带人脸/指纹/密码锁芯、步进电机和反锁臂。其特征在于:环境识别模块,用于对环境的感知和检测,如开锁人的人脸、语音以及指纹等信息的识别和记录,以及周围环境的探测,将开锁人的行为传入到智能学习模块。
所述的智能学习模块,包括深度强化学习单元和用户体验质量分析决策单元构成。其采用深度强化学习机制,通过用户行为、当前时刻门锁系统的状态和移动边缘云的状态,即学习环境的q函数值,反馈给深度强化学习单元,根据用户对所采取的行为(开/关锁)反馈,采用线上线下学习算法对下一时刻的动作进行预测评估,如下次智能开/关门锁会得到期望的回报,通过在经验池中经验数据的搜索学习,找到最优的q函数值,从而对打开/关闭门锁进行决策,并将信息反馈给微处理器,由微处理器发出指令,驱动步进电机,由电机执行开/关门锁的动作。
所述的q函数值,即强化学习中的q学习的函数值,其目标是在某个策略(学习机制)π下,将学习环境的状态转换成最优的行为,从而对不同用户的状态,在这种状态-动作空间做出开/关锁的智能决策。q函数目标函数值表示为式(1):
其中,θ表示qω(s,a)函数的权重,qω(s,a)表示改进的低维度的q函数,
其中,ξ是q函数更新的学习率,ξ∈[0,1),其根据经典的贝尔曼方程(3)可以得到ξ的经验值,ξ=0.99。
e[.]表示从长期看,所获得的期望的奖励。r是在下一时刻(t+1)的立即回报,s′是下一状态。pr(.)是转移概率。q函数是当系统处于状态s,采用相应的行为a的期望折扣累计代价(或者回报)。
所述的(2)式中δ表示:时间差分误差(tderror),即下一时刻的近似q函数的近似值与当前值的差,其通常用式(5)进行估计:
所述的(2)式中的
我们用
其中,l∈[0,1),表示迹-延迟参数。l=0,它将更新为当前达到的q值。
所述的改进的线上线下学习算法的步骤如下:
1)线上学习阶段:
s1:初始化参数
s2:若t<t;其中t表示一个周期,即最大的时隙数,t∈{1,2,…,t};若成立,则转t3,若不成立,则转t8,
s3:
利用概率ε贪婪选择下一时刻的行为。获得相应的回报和下一时刻的状态信息;
s4:观测学习环境状态和即刻代价或者回报r(t);
s5:将四元组(s,a,r(t),s′)保存到经验回放池;
s6:判断q函数是否收敛,若没有收敛,则根据式(7)更新q函数,转s7;若收敛,则转到r1;
s7:返回q函数值;
s8:从新进入下一周期。
2)线下学习阶段:
r1:权重参数赋初值;
r2:计算mec端累计折扣回报或者代价r;
r3:判断经验池样本是否为空;若为空,转r4;若不为空,根据式(2)、(5)和(6)计算当前时刻误差权重值,并利用最小二乘法迭代更新下一时刻的权重误差函数值;
r4:判断权重误差是否小于收敛阈值,若是,则转r5;若不是,则转r6。
r5:利用梯度下降法更新参数集ω,计算并返回q函数值。
r6:根据式(5)和(6)更新资格迹和td误差,根据式(8)更新q函数。转r7;
所述的式(8)如下:
r7:t++;转s2。
有益效果:本发明对一种基于用户体验分析的深度强化学习式智能门锁系统及装置。该系统是具有用户qoe分析的线上线下式的学习算法,对学习环境进行综合判断,智能决策,并设计出智能门锁系统的装置,从而实现多元化、智能化学习式的开/关锁系统。增强用户的体验质量。
附图说明
图1为基于用户体验分析的深度强化学习式智能门锁系统及装置的结构示意图;
图2为智能学习模块的结构示意图;
图3为智能学习模块学习机制示意图;
图4为低复杂度的线上线下学习算法流程图。
具体实施方式
下面结合附图和具体实施方式,对本发明作进一步说明。
基本思想:本发明基于用户体验分析的深度强化学习式智能门锁系统及装置。首先,我们设计智能门锁系统的强化学习模型,并提出改进的线上线下强化学习算法,该算法对用户的qoe分析,通过分析将搜索空间:状态-行为对的空间降维;此外,为克服强化学习带有的延迟奖励或者惩罚,而影响到后续学习过程,即:根据此奖励或者惩罚计算下一时刻状态的值函数或者根据此奖励或者惩罚决定下一时刻行为的选择,为此,我们采用带有临时记录功能的资格迹进行信用评分,从而避免强化学习中具有的延迟赏罚的弊端。最后,该算法作为核心模块,设计出智能门锁系统的装置,从而实现多元化、智能化学习式的开/关锁系统。避免了用户用人脸/指纹/密码开锁的费时费心的操作,增强门锁的智能化和人性化。
所述的基于用户体验分析的深度强化学习式智能门锁系统及装置的结构示意图,如图1所示,该系统包括微处理器1,环境识别模块2,智能学习模块9,供电模块6、语音通信模块13、存储装置12、人脸/指纹/密码锁芯19、步进电机21和反锁臂20组成。
进一步地,所述的微处理器1是有cpu芯片,flash缓存等构成,用于协调并控制各个模块的运营;所述的环境识别模块2,由环境感知单元3,语音输入单元4,人脸检测单元5构成,其作为输入模块,为智能学习模块提供数据源;所述的智能学习模块9,由深度强化学习单元10和用户体验质量分析决策单元11构成。其用于对用户的一些日常开锁行为和语言行为的判断和处理,并根据用户的信息状态给予的反馈,在不需要用户人工干预的情况下,智能地对开/关锁功能进行决策。
进一步地,所述的语音通信系统13由zigbee芯片、gsm器件18和网关设备接口16构成。zigbee芯片单元15集成zigbeerf前段,flash存储器和对应的线路板。gsm单元14用于断网的情况下智能的向存储器中有关家人的手机号发送短信。网关设备接口是rj-45标准接口或者usb接口,用于连接网线的水晶插头。采用有线或无线两种通信技术与移动边缘计算云(mec)23、智能手机22等连接。无线技术采用5g通信协议,当没有网络的情况下,依然可采用手机通信协议进行发送短信进行开锁或者关锁;
进一步地,所述的供电模块6包括单晶硅光能蓄电单元8、可充电锂电池、低压差线性稳压装置7以及太阳能蓄电板18。所述的单晶硅光能蓄电单元8贴附于微处理器1外壳表面,其导线与太阳能蓄电板18的第一接口连接,所述的太阳能蓄电板18的第二接口与低压差线性稳压装置7连接,所述的低压差线性稳压装置7与可充电锂电池的正极连接,可充电锂电池的负极与太阳能蓄电板18的第三个接口连接。低压差线性稳压装置7用于保护电路。紧急情况:如在断网断电情况下,采用太阳能板蓄电单元可进行自行蓄电。
进一步地,所述的存储装置12,用于对智能学习模块,学习后的样本数据的存储,并作为语音通信模块13的语音播报装置17的数据源。
所述的智能学习模块的结构如图2所示,智能学习模块9是采用强化学习中的q学习机制。学习机制001相当于智能体,其通过与学习环境002(学习对象)不断的交互,观测当前t时刻,学习环境的状态006:用户行为004和门锁系统状态005以及mec003的状态,这三个状态分别附加以不同的权重θ,并对三种对象分别记录相应的状态值,在采取某个策略下将所获得的即时奖励007,比如用户体验质量qoe上升,同时,计算下一时刻采取某个动作008,如在下一时刻,某种场景(样本中的学习环境的相似状态值)下,进行开/关门锁,分别能够获得的期望的累计最大收益,如qoe的平均提升多少个量级等。则采用相应的行为008。并同时形成控制指令通过链路发送给微处理器1,微处理器1发送控制指令给步进电机21或者反锁臂20,由电机21执行是否开/关锁。
所述的智能学习模块的学习机制过程如图3所示:学习机制001观察学习环境101的当前时刻的状态s和采取某个策略的即刻奖励值(s,r)102,将当前时刻的行为a和状态s对:(s,a)114保存到经验回放池112中,并将下一时刻的元组(s,a,r(t),s′)113,保存到113中,从113中计算当前q值
所述的低复杂度的线上线下学习算法流程图如图4所示。该算法线上采用一步更新模式,线下进行调整学习的参数,从而降低线上边学习边调整参数这种传统学习模式的复杂度。在线上阶段,首先检测当前时刻的时间t是否小于预设定的周期t,否则,则重新开始下一个周期;若是,则采用贪婪算法选择下一时刻的动作a,获得相应的即时回报r(t)和下一时刻的状态s′信息,观察环境状态和即刻回报或者代价r(t),将四元组(a,s,r(t),s′)样本保存到经验回放池。判断q函数是否收敛,若否,根据式(7)更新q函数,返回q函数值;若是,转到线下学习阶段:对于权重参数赋初值,计算mec端的总代价或者总回报r。判断经验池样本是否为空,若是,返回当前的q函数值;否则,根据式(2)、(5)和(6)计算当前时刻误差权重值,利用最小二乘法,迭代更新下一时刻的权重误差函数值。判断权重误差是否小于收敛阈值,若是,利用梯度下降法更新参数ω,否则,根据式(5)和(6)更新资格迹和td误差,根据式(8)和更新低复杂度的q函数,t++,重新判断,回到步骤t<t的判断。
上述描述仅作为本发明可实施的技术方案提出,不作为对其技术方案本身的单一限制条件。
- 还没有人留言评论。精彩留言会获得点赞!