道路交通事故预警方法与流程
本发明涉及一种道路交通事故预警方法。
背景技术:
交通是城市经济发展的基础,是经济社会活动中最活跃的因素,与居民的生活息息相关;伴随着经济社会的飞速发展、城市化的快速推进以及机动化程度的迅速发展,道路交通需求显著增加,道路交通安全问题日益凸显;因此,迫切需要基于交通大数据挖掘的交通事故成因分析,对事故高发人群预估、事故发生地点、时间、天气的预判;实现交通事故未发先防、发后快处、处理客观的目标;
目前,研究交通事故成因分析方面所在的观察角度、侧重对象、研究方法上各有不同,但总的来说都是从驾驶人、驾驶车辆、道路路况、环境因素这几个方面来分析事故成因。内容上大同小异,大部分研究结果都侧重于事故中司机年龄、驾龄、性别以及受伤部位的统计分析,而对于如何结合事故发生地点、时间等环境因素进行司机驾驶多维度、差异化分析,从而做到有针对性的采取措施并未涉及。
技术实现要素:
本发明的目的是提供一种道路交通事故预警方法,从交通违法数据和交通事故数据以及环境变量中得到交通事故成因并应用到实际情况中;对交通事故高发人群预估、交通事故发生类型预判、判断事故多发路段治理的重点和及其优先等级,对交通事故高发时间、天气等的统计规律。实现交通事故未发先防、发后快处、处理客观的目标,解决如何结合事故发生地点、时间等环境因素进行司机驾驶多维度、差异化分析,从而做到有针对性的采取措施的问题。
本发明的技术解决方案是:
一种道路交通事故预警方法,包括以下步骤:
S1、通过司机身份信息关联交通事故数据信息表和交通违法数据信息表;
S2、通过交通事故人员特征分析,得到司机的交通事故与交通违法在数量、类型上的联系,得到司机拥有不同车辆数对事故发生率的影响,得到司机年龄、驾龄与事故发生率的关系,得到司机在事故责任方上的性别差异;
S3、由S2得到的结果,进行交通事故高发人员决策树判断,得到事故高发 人员及其发生的事故类型;
S4、环境变量特征分析,使用K中心聚类的方法,依据路段发生事故类型比例,得到城市路段聚类结果;使用统计的方法,得到事故发生时间、天气、车辆颜色在事故发生率上分布情况;
S5、依据S4所得结果,依据聚类后的各路段类型的聚类中心,判断路段事故种类复杂度,作为第一排序依据;将路段事故数量作为第二排序依据,得到道路类型及处理等级表,得到事故高发时间、天气、车辆颜色规律;
S6、综合步骤S3、S5得到的结果,将S3中得到的事故高发人员及其发生的事故类型,对应到步骤S5的事故高发的环境变量,结合司机自身特点和环境状况进行针对的行车提醒,同时进行事故预警。
进一步地,步骤S1具体为:交通违法数据信息表中的交通违法数据的特征向量为As=[A,H],其中A为违法人员身份信息,H为违法人员的违法内容;交通事故数据信息表中的交通事故数据的特征向量为CS=[C,K,V],其中C为事故信息,包括事故发生类型、时间、地点、天气,K为人员信息,包括司机年龄、性别、责任归属、驾龄、拥有的不同车辆数,V为车辆颜色信息。
进一步地,步骤S2具体为:
S21、使用Sperman等级相关性的方法,检验司机发生交通事故与交通违法在数量、类型上的相关性;
S22、司机拥有不同车辆数对事故发生率的影响进行检验,具体为:从司机交通事故数据中提取其发生多起事故所用到的不同的车辆数,利用Sperman等级相关性检验二者的相关性及其系数大小;
S23、对于司机在事故责任上的性别差异进行检验,具体为:从司机交通事故数据中提取司机发生事故后,责任方的归属及其性别信息,利用x2检验的方法,检验性别在事故责任方上的差异性水平;
S24、使用统计的方法,得到司机年龄、驾龄在事故发生率上的规律。
进一步地,步骤S21中,司机发生交通事故与交通违法在数量、类型上的关系检验方法为:
S211、从交通事故数据和交通违法数据表格中,对应并统计每位司机发生交通事故的次数、交通违法的次数,利用Sperman等级相关性检验二者数量上的相 关性及其系数大小;
S212、按照交通事故类型,分类事故人员;
S213、在交通违法数据里对应出这些事故人员的违法信息,统计每一事故类型司机各类违法次数;
S214、根据统计后的各类违法数量,舍弃违法数量小于p次的违法类型;得到司机发生交通事故类型-司机交通违法类型表格;
S215、将所得司机发生交通事故类型-司机交通违法类型表格中的每一类型交通事故对应的各种交通违法的次数,比上每一类型交通违法的总次数,得到司机发生交通事故类型-司机交通违法类型比例的表格;计算公式如下:
交通事故A={a1,a2,a3…am},am为交通事故类型;
事故人数K={k1,k2,k3…km},km为发生交通事故类型am的人数;
违法类型B={b1,b2,b3…bn},bn为交通违法类型;
违法人数kmbn为司机交通事故类型是am的,其发生违法类型为bn的次数;
司机违法总次数
司机违法类型比例矩阵
S216、以司机交通违法的比例为纵坐标,司机交通违法类型为横坐标,将各类型交通事故的司机所发生的各类交通违法的比例绘制在此坐标系中,通过观察司机各类违法的比例,进而判断其发生的事故的类型。
进一步地,所述步骤S24中检验司机年龄、驾龄在事故发生率上的差异,具体为:
S241、从司机交通事故数据中提取事故责任方司机的年龄和驾龄,统计事故责任方的司机年龄、驾龄分布频次,得到责任方司机发生交通事故的频次-司机年龄、驾龄频数表;
S242、以事故发生频次为纵坐标,司机年龄和驾龄为横坐标,将各年龄、驾 龄段的司机发生的交通事故频次绘制在该坐标系上,判断事故高发司机其驾龄、年龄分布段。
进一步地,步骤S3中事故高发人员决策树判断具体为:根据步骤S2中结论,由交通事故人员的事故数量、违法次数、拥有不同的车辆数、驾龄、年龄信息,使用决策树模型的CHAID算法进行事故高危人群分类判断,得到事故高发人员及其发生的事故类型。
进一步地,步骤S4中事故多发路段事故类型聚类分析步骤为:
S411、在交通事故数据中提取事故地点、事故类型、事故数量,筛选出事故数大于等于n次的事故高发地点;
S412、计算出事故地点发生的每一类交通事故类型在所有交通事故类型中的比例,得到事故地点-发生各类事故类型数量的百分比表;
S413、使用K中心聚类的方法,将城市路段分成3类,得到城市路段事故类型聚类表。
进一步地,步骤S4中事故发生时间分析的步骤为:
S421、从事故数据中提取事故发生日期、时间,其中日期分为工作日、休息日;
S422、以一小时为时间段,统计该时间短内的交通事故次数,得到每一天24小时内,每小时的事故比例表;
S423、以事故数量比例为纵坐标,以事故发生时间为横坐标,建立坐标系,绘制统计时间段内,不同日期类型的24小时的事故发生的数量比例;通过图表对比,得到交通事故发生与日期、时间的关系。
进一步地,步骤S4中事故发生天气分析步骤为:
S431、从交通事故数据中提取事发时天气类型;
S432、计算事发时各类型天气发生事故次数在所有事故次数中的比例分布;
S433、对照组数据,使用事发时各类型天气,在统计时段内,所有事发天气上的分布比例;
S434、计算步骤S432与步骤S433的差值;计算公式如下:
统计时段内,各类交通事故天气出现的次数KA={ka1,ka2,ka3…kam},
am为天气类型;
各类交通事故天气下,发生的交通事故数量KB={kb1,kb2,kb3…kbn},bn为交通事故天气类型;
S435、以百分比为纵坐标,天气类型为横坐标建立坐标系,将步骤S432与步骤S433的差值绘制在该坐标系中,直观的展现出事故易发天气类型。
进一步地,步骤S4中事故车辆颜色分析步骤为:
S441、从事故数据中提取事故车辆颜色信息、是否为肇事车辆信息;
S442、计算出肇事车辆颜色在所有车辆颜色中的比例分布;
S443、计算出非肇事车辆颜色在所有车辆颜色中的比例分布;
S444、计算非肇事车辆的百分比与肇事车辆的百分比差值;
S445、以车辆颜色为横坐标,百分比为纵坐标,建立坐标系,绘制非肇事车辆颜色百分比与肇事车辆颜色百分比的差值图;得到车辆颜色在交通事故发生率上的规律。
进一步地,步骤S5中得到事故高发天气、时间、车辆颜色规律,具体为:依据S423、S435、S445得到的统计图表,定量化确定事故高发天气、时间、路段及车辆颜色规律。
本发明的有益效果是:该种道路交通事故预警方法,将事故高危司机和事故高发路段结合,加入时间、天气等环境因素的影响,以达到事故高发司机判断、司机发生事故类型判断、多发事故路段对应特定司机类型,将事故人员、事故类型、事故路段有机结合的目的,从而实现有针对化的行车提醒,同时能够实现让交通管理部门进行事故预警;能够作为市政管理部门进行道路管养的参考。
附图说明
图1为本发明实施例道路交通事故预警方法的流程示意图。
图2为实施例中事故类型及其对应的违法类型的示意图。
图3为实施例中司机拥有的不同类型的车辆(异车率)对其故发生次数的影响的示意图。
图4为实施例中事故责任方司机驾龄分布直方图。
图5为实施例中事故责任方司机年龄分布直方图。
图6为实施例中事故高危人群判断树形图。
图7为实施例中事故数量在不同日期类型的一天内的分布的示意图。
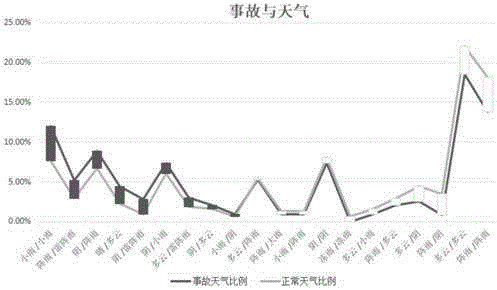
图8为实施例中事故天气与正常天气种类分布比例差值的示意图。
图9为实施例中被肇事车辆颜色百分比与肇事车辆颜色百分比差值的示意图。
具体实施方式
下面结合附图详细说明本发明的优选实施例。
实施例
实施例的方法中所做的数据分析处理,主要使用EXCEL和IBM SPSS Statistics 22.0统计分析软件。涉及到EXCEL的筛选、比对、数据透视表等基础处理手段以及SPSS中的χ2检验、聚类分析、斯皮尔曼等级相关性检验、曲线估计、决策树模型等数据统计分析方法;
如图1所示,一种道路交通事故预警方法,该方法包括如下步骤。
S1、通过司机身份信息关联交通事故数据信息表和交通违法数据信息表,交通违法数据的特征向量为As=[A,H],其中A为违法人员身份信息,H为违法人员的违法内容。交通事故数据的特征向量为CS=[C,K,V],其中C为事故信息,包括事故发生类型、时间、地点、天气,K为人员信息,包括司机年龄、性别、责任归属、驾龄、拥有的不同车辆数,V为车辆颜色信息。
其中,交通违法数据包括违法人员身份信息、违法人员的违法内容;交通事故数据包括:事故发生类型、时间、地点、天气,司机身份信息、年龄、性别、责任归属、驾龄、拥有的不同车辆数、车辆颜色信息。
实施例案例数据包含了某市2015年上半年的18042起交通事故数据以及2014—2016间的61473起交通违法数据。涉及人员70324人,其中属于事故责任方且在2014—2016期间内违法的共计14436人。其中事故数据主要包括涉及事故人员身份信息,即身份证号、性别、出生日期、初次领证日期、事故发生地点、事故发生时间、事发当天天气状况、事故发生类型、事故责任归属情况、事故车辆牌照。违法数据包括驾驶证号(身份证号)、违法行为、违法内容。经过 数据二次处理将事故数据和违法数据比对得到事故人员违法次数及类型、事故人员发生事故次数及类型、事故中所使用的不同的车辆数。
S2、交通事故人员特征分析,使用Sperman等级相关性的方法,检验司机交通事故与交通违法在数量上相关性,确定其相关性大小;使用统计的方法,得到司机交通事故与交通违法在类型上的相关性;使用Sperman等级相关性的方法,检验司机拥有不同车辆数对事故发生率的相关性影响及其大小;使用χ2检验的方法,得到司机在事故责任方上的性别差异;使用统计的方法,得到司机年龄、驾龄在事故发生率上的规律。
在步骤S2中,通过司机身份证信息,关联交通事故数据信息表和交通违法数据信息表后,得到事故责任方在一段时间内的事故发生次数及其在更长时间内的违法次数。在Excel第一列输入驾驶员身份证号,第二列输入该驾驶员事故次数,第三列输入该驾驶员违法次数,导入表格到IBM SPSS Statistics 22.0中,使用sperman等级相关性检验,检验结果如表1所示:
表1.事故频数与违法次数斯皮尔曼等级相关性检验表
表1中,**.相关性在0.01级别显著(双尾)。
结果显示:交通事故发生频数和交通违法次数在显著性水平为0.01标准下,渐进显著性水平为0,具有等级相关性。
通过EXCEL表格处理将事故发生类型为同一类的司机及其违法类型数据合并提取,得到发生某类事故的司机其常发性违法类型情况;依据某种违法类型的发生数量将200种违法数据筛选到20种,具体分布情况如图2所示。
对比事故中负有责任的驾驶员与其两年内违法情况发现,其违法类型集中在 某几类;并且发现不同的事故类型对应着不同的违法高发类型,即发生某一类交通事故的人经常性的违法某一种类型;图2显示了发生9类交通事故类型的司机对应的发生20类高发交通违法类型所占的比例;比如说发生追尾事故的人其发生”进入导向车道、不按规定方向行驶的”这一违法类型就比其他违法类型都要高(占比22.29%);事故发生类型是违反交通信号的司机,其发生“驾驶机动车在高速公路、城市快速路以外的道路上不按规定车道行驶的”这一事故类型占比高达60.66%是否可以通过司机违法行为预先判断可能发生的事故类型,以便有针对性的防范交通事故的发生;综合以上两种研究方法我们可以做到事先预判事故高发人群的高发事故类型。
驾驶员在多起事故中所驾驶的不同车辆数也会影响交通事故发生率。利用斯皮尔曼等级相关性检验如表2所示:交通事故发生频数与交通违法次数具有显著相关性(sig=0),并且相关系数=0.620,具有较强的相关性;
表2.异车率与事故发生次数斯皮尔曼等级相关性检验表
表2中,**.相关性在0.01级别显著(双尾).
根据表2得到的结论是:发生交通事故数量≥2次的,其事故车辆拥有率大致随着事故次数而增加。即驾驶人驾驶不同类型的车辆数越多,交通事故的发生频率也越高;具体分布如图3所示:随着交通事故率的增加,平均每人拥有的不同车辆数(异车率)也在增加。
对步骤2中事故责任方司机性别差异的检验如下,首先对36082位交通事故涉及人员的事故责任归属先用EXCEL进行简单的统计,之后用spss中χ2检验的方法确定了在事故责任方上,存在着显著的性别差异,得到表3、表4;如表3所示:皮尔逊卡方渐进显著性<0.05;因此,在事故责任方上存在显著的性别差异;具体差异情况见表4。
表3.性别*事故责任情况卡方检验表
表3中,a.0个单元格(0.0%)具有的预期计数少于5。最小预期计数为1171.84。b.仅为2x2表格计算。
表4可以看出:在交通事故中,事故责任方上存在显著的性别差,渐进显著性为0;表现为事故中男性是责任方的概率更大;而女性为责任方的概率更小。
表4.性别*事故责任情况交叉表
对步骤S2中事故责任方的年龄、驾龄Excel统计结果如图4。
从图4可得:驾龄在1—12年的,其事故发生次数随着驾龄的增长而增长,到12年达到最大值,其后,随着驾龄的增加,事故发生次数不断降低;事故高发驾龄区间为8—15年和3—5年。
从事故责任方年龄分布直方图5来看,因为不同年龄段拥有的车辆基数不同,因此不具有重要的统计意义。
S3、由S2得到的结果,使用决策树对交通事故高发人员判断,得到事故高发人员及其发生的事故类型。
对上述步骤S3中关于事故高发人群的特征进行决策树分析,利用SPSS中分类-树模型,分析结果如下:
表5.模型摘要
使用CHAID(chi-squared automatic interaction detection,卡方自动交互检测)决策树算法进行树生长,因为CHAID会防止数据被过度套用并让判定树停止分割,依据的衡量标准是计算节点中类别的P值大小,以此决定判定是否继续分割,所以不需要做树剪枝。模型中因变量是事故发生次数,其赋值如上表所示;自变量是司机年龄、驾龄、性别、违法次数、司机名下的车辆数(异车率)。利用交叉验证的方法对风险评估有效性验证;模型结果显示:司机名下车辆数(异车率)、违法次数、司机驾龄三个自变量被选入并按重要性依次递减;其余自变量对模型没有显著贡献,自动从模型中排出;
表6.风险评估与分类
表6中,生长法:CHAID。因变量:事故发生次数:0=不负责任的、1=事故责任1-2次;2=事故责任3-5次。
从表6的风险评估表中可以看出,0.283风险估计表示按照模型(无事故责任、事故责任1-2次、事故责任3-5次),预测分类错误率为28.3%;分类表中给 出的结果与风险估计一致;分类表显示司机正确的分类约为72%;
图6是本决策树模型的具体树表,主要是因变量在每个分类中个案的数量和百分比;从图6中可以得到因变量的预测分类。可以看到司机名下的车辆数,显著影响交通事故发生次数的百分比;因此,第一次分类指标就是司机名下车辆数,在两种不同的类别里,司机事故发生比例具有明显的差异,依次类推。最终得到的结果必然是完全分类后司机事故次数差异化最明显。
S4、环境变量特征分析,使用K中心聚类的方法,依据路段发生事故类型比例,得到城市路段聚类结果;使用统计的方法,得到事故发生时间、天气、车辆颜色在事故发生率上分布情况。其中,环境变量包括研究时段内事故发生地的天气数据。
S5、应用S4的结果,依据聚类后的各路段类型的聚类中心,判断路段事故种类复杂度,作为第一排序依据;将路段事故数量作为第二排序依据;得到道路类型及处理等级表;得到事故高发时间、天气、车辆颜色规律。
对于步骤S4中的事故地点聚类分析,将事故高发地发生的事故类型进行EXCEL统计后,筛选出事故发生数量≥20次的地点;依据该地点事故发生类型比例,进行聚类分析,结果如表7。
表7.事故高发地发生事故类型聚类ANOVA方差分析表
根据ANOVA分析表可得:事故因素是“逆行的”、“开关车门的”、“违反交通信号的”这三类对于事故地点聚类结果没有显著性影响。
表8.事故高发地发生事故类型最终聚类中心及聚类数
根据最终聚类中心表8可得:对于所有路段来说,事故类型为“追尾的”和“未按规定让行的”是其主要事故发生类型;路段1、2、3的事故类型为“追尾的”的比例依次递增,与此同时事故类型为“未按规定让行的”的比例依次递减;对于路段1和2来说事故发生主要类型是“未按规定让行的”;对于路段3来说,事故发生主要类型是“追尾的”;因此可以集中精力解决某一路段的主要事故发生类型。
相比来说,路段2的事故发生类型相对路段1和3较全面多样;因此推测路段2的道路状况更加复杂,治理难度相对较大,而路段1和路段3的事故发生类型更加单一,所以治理难度相对较小;
根据事故类型复杂度,路段治理难度排序为1、3、2依次递增。再按照各地点事故发生次数,将该市部分路段交通事故采取预防措施优先等级列出表9以供交通管理人员参考。
表9贵阳市事故常发性路段分类及优先等级
对步骤S4中事故发生时间的分析,实施例中统计2015年1月2日到2015年5月30日内的不同日期类型一天内的事故数量,从图7可以看出,工作日和休息日的事故时间分布存在着显著的差异,工作日的事故发生高峰期在早上八点到九点之间,对应着上班高峰期;次高峰出现在17点到18点左右,对应着下班高峰期;而节假日事故发生时段较分散,集中在9点到18点之间。
这期间内总计151天,发生事故18151起,劳动节、清明节共计6天,发生事故858起;其中假日时间占总时间3.97%,假日事故数量占总数量4.73%;因此,假日期间是事故高发时间。
对于步骤S4中事故发生天气的分析,本例中统计2015年1月2日到2015年5月30日内的18151起事故发生时的天气分布情况,与期间内天气分布对比,用事故发生时的天气分布比例减去实际天气分布比例,再按大小进行排序,得到图8;图8显示,前十种天气类型下,事故发生比例比不发生事故的比例要高,并且逐次递减至多云/阵雨,从此种天气后往后的天气下,不发生事故的比例要比发生事故的比例高并且逐次递增至阵雨转阵雨的天气达到最大值。
对于步骤S4中事故发生车辆颜色的分析,本例中统计2015年1月2日到2015年5月30日内的18151起事故的36302辆车,剔除坏数据,最终剩下36060辆车,其中包括18873辆肇事车辆和17187辆被肇事车辆,涉及车辆颜色9种;我们用被肇事车辆颜色的百分比分布减去肇事车辆颜色的百分比分布;如图9所示:在事故中,白色、银色、红色的车辆更多的是肇事车辆,更少的是被肇事车辆。而现实中,司机发生交通事故与否与自身驾驶的车辆颜色无关,而与对方车辆的颜色有一些关系;所以,车身颜色为白色、银色、红色的车辆相对较安全,不容易被肇事。
S6、综合步骤S3、S5得到的结论,结合司机自身特点及其所处的环境状况,有针对化的行车提醒,同时让交通管理部门进行事故预警;作为市政管理部门进行道路管养的参考。
- 还没有人留言评论。精彩留言会获得点赞!