基于有序聚类的信号控制时段分割方法与流程
本发明涉及一种信号控制时段分割的有序聚类方法,可以自动优化聚类数目并输出分割方案,为分时段定时控制提供支撑,属于交通控制研究领域。
背景技术:
虽然多数信号控制系统均具备自适应控制功能,但限于信息完整性的约束,分时段固定式的信号控制依然是最为常见的控制方式之一。目前,对于控制时段的分割多采用传统聚类方法,根据流量自身的属性,用数学方法按照某种相似性或差异性指标,定量描述样本之间的亲疏关系,并按这种亲疏程度对样本完成聚类分析,也即时段划分。现有方法存在如下不足:不能自动优化合理的聚类数目,只能通过枚举的方式寻求最佳方案,其方法的时间复杂度很大。因此,提出一种时间复杂度小且能自动输出聚类数目和方案的方法必然可以大大提升时段划分的速度和结果的可靠度,为多时段固定式信号控制提供技术支撑。
技术实现要素:
本发明的目的在于实现交叉口信号控制时段数目和具体方案的自动优化,其基本思想为:利用交通流量的实际序列规律性波动,将相似性较高的时间序列进行分割聚类,从而得到交通时段的合理划分,界定交通控制时段划分方案。
本发明的基本步骤如下:
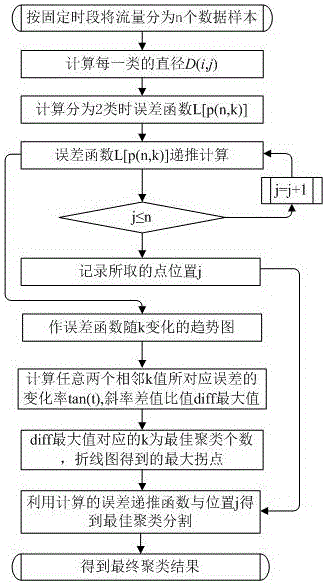
c1、设定聚类个数为k,计算不同k值情况下每个类的直径;
c2、设计不同k值情况下的误差函数;
c3、计算不同k值情况下误差递推值;
c4、由不同k值情况下误差值确定聚类数kop;
c5、根据kop与误差函数得到最佳分类方案。
步骤c1的过程包括:
c11、交叉口的流量统计间隔一般为固定时段T,通常为5分钟、10分钟或者15分钟;假设一天的流量数据共有n个数据样本,则
c12、令一天n个有序数据样本依次为Z1,Z2,…,Zn,类G包含的数据样本有{Zi,Zi+1,…,Zj}(j>i),即G={i,i+1,…,j},计算该类的直径D(i,j)
①计算该类的类均值
式中:为类G的均值;t为时间序列的编号;Zt为序列样本t时间所对应的流量值。
②计算每一类的直径,即类中离差平方和:
式中:D(i,j)为第i、j区段之间的距离;t为时间;Zt为序列样本t时间所对应的流量值;为类G的均值;通过计算直径衡量每一类的离差平方和,用于表示类中数据差异程度,数值越小表示差异越小。
步骤c2的过程包括:
c21、计算聚类总数为k时的误差函数,记具体分类方法为:
G1={i1,i1+1,…,i2-1}
G2={i2,i2+1,…,i3-1}
…
Gk={ik,ik+1,…,n}
其中分点为1=i1<i2<…<ik<n=ik+1-1(即n+1=ik+1)。
其误差函数表达式为:
式中:k为聚类数;b(n,k)为n个数据分为k类的某一种分类方法;L[b(n,k)]为n个数据分为k类的误差函数;t为时间序列编号;D(it,it+1-1)为第it与it+1-1数据的距离值,计算误差函数,用于最佳递归分类。
步骤c3的过程包括:
c31、计算误差函数递推值,并记录最佳分割点的位置j;
式中:p(n,k)为n个数据分为k类使误差函数达到最小的分类方法;L[p(n,2)]为n个区段的流量数据分为2类的误差函数;L[p(n,k)]为n个区段的流量数据分为k类的误差函数;D(j,n)为第j与n个数据之间的直径;当n,k固定时,L[p(n,k)]越小,表示所有类的离差平方和最小,分类合理。因此,由递推式可知计算n个样品分为k类的误差函数达到最小,则需要计算j-1个样品分为k-1类的误差函数达到最小,以此类推。
步骤c4的过程包括:
c41、作L[p(n,k)]随k变化的趋势图,如图2所示;
c42、由趋势图搜索出最大拐点所对应的k值作为最佳聚类数kop;
①计算任意两个相邻k值所对应误差的变化率:
②计算前后的斜率差值,得到前差值diff1、后差值diff2的值:
c43、利用前差值diff1与后差值diff2的比值得到决策图最大拐点,即:
c44、diff值最大时的k值即为最佳聚类个数kop。
步骤c5的过程包括:
c51、根据kop与误差函数得到最佳分割方案:
n个数据样本分为kop类的最优分割,应该建立在j-1个样品分为kop-1类的最优分割的基础上,以此类推。利用计算的误差递推函数,与记录最佳分割点的位置j,分别得到聚为2、3……kop类时的分割情况。
本发明的有益效果:本发明提出了一种基于有序聚类的信号控制时段分割方法,利用交通流量的实际序列规律性波动,将相似性较高的时间序列进行聚类,实现交叉口信号控制时段数目的自动优化,从而得到交通流量的合理分组,以此界定交通控制时段划分方案。
附图说明
图1算法实现过程流程图;
图2最佳聚类数数k趋势图;
图3序列数据聚类结果图。
具体实施方式
以某城市某交叉口某天24小时流量为例,对数据进行分割,见图1。
1、设定类的个数为k,计算不同k值情况下每个类的直径;
(1)一天的流量数据共有1440个数据样本;交叉口的流量统计间隔一般为固定时段T,该固定时段取为5分钟。
(2)记一天288个有序样品时间流量点依次为{Z1,Z2,…,Zn},类Gi包含样品有{Zi,Zi+1,…,Zj}(j>i),记Gi={i,i+1,…,j};
①计算每一类均值
②计算每一类的直径;
2、计算不同k值情况下的误差函数;
(1)计算聚类总数为k时的误差;
记具体分类方法为:
G1={i1,i1+1,…,i2-1}
G2={i2,i2+1,…,i3-1}
…
Gk={ik,ik+1,…,n}
其中分点为1=i1<i2<…<ik<n=ik+1-1。其误差函数表达式为:
3、计算不同k值情况下误差函数的递推公式;
(1)计算误差函数递推公式,并记录所取的点位置j;
4、由误差函数确定聚类数k;
(1)作L[p(n,2)]随k变化的趋势图,如图2所示;
(2)由趋势图搜索出最大拐点所对应的k值;
①计算任意两个相邻k值所对应误差的变化率:
②计算前后的斜率差值,得到前差值diff1、后差值diff2的值:
③利用前差值diff1与后差值diff2的比值得到决策图最大拐点,即:
④diff值最大时的k值即为最佳聚类个数kop。
5、根据kop与误差函数得到最佳聚类分割。
(1)根据kop与误差函数得到最佳聚类分割:
n个数据样本分为kop类的最优分割,应该建立在j-1个样品分为kop-1类的最优分割的基础上,以此类推。利用计算的误差递推函数,与记录最佳分割点的位置j,分别得到聚为2、3……kop类时的分割情况,如图3所示。
- 还没有人留言评论。精彩留言会获得点赞!