基于密度峰值聚类的交通流量序列划分方法与流程
本发明涉及一种交通流量序列的划分方法,具体是一种基于密度峰值聚类的交通流量序列划分方法,属于交通控制研究领域。
背景技术:
现有信号控制系统多具备自适应功能,主要依靠线圈检测设备的检测信息实时优化信号控制方案。而在实际应用中,线圈检测器损坏和故障的发生率很高,且其它类型的检测器数据,包括视频、微波、地磁等均很难直接接入现有信号控制系统,致使很多信号控制系统和信号控制器只能被动采用固定式的配时方案。为了尽量提升交叉口的交通流运行效率,定时控制策略下的信号配时方案也必须根据交通流的时变特性进行相应的动态调整,通常以天为基本单元将整个时间长度划分为若干单元,利用每个单元的平均交通流数据优化相应的信号控制方案,即多时段信号控制方案。
目前,信号控制的时段划分多采用传统的聚类方法,即将一天中所有时间区段的流量值看做样本,根据样本自身的属性,用数学方法按照某种相似性或差异性指标,定量地确定样本之间的亲疏关系,并按这种亲疏关系程度对样本进行聚类,存在如下三点问题:1.多数方法不能自动优化合理的聚类数目,需要多次对比实验数据得到最佳结果;2.具备自动输出聚类数目和结果的方法多通过枚举的方式,其计算时间复杂度较大;3.所有方法都仅局限于针对特定天的流量数据确定时段划分方案,而没有考虑不同天之间的流量变化规律亦有相似性,具有相似变化规律的若干天可以采用相同的时段划分方案。因此,如果能够针对较长时间范围内的流量数据,以天为基本单元,首先通过密度峰值聚类的方法实现流量序列分类划分,可以大大节约时段划分的工作量。同时,一种时间复杂度小且能自动输出聚类数目和方案的划分方法必然可以大大提升结果的可靠度。
技术实现要素:
本发明的目的在于针对较长时间范围内的流量数据(一般应包括15天以上的数据),以天为基本单元,将一个长时间序列的流量切片成若干子序列,实现子序列聚类数目和聚类结果的自动优化。
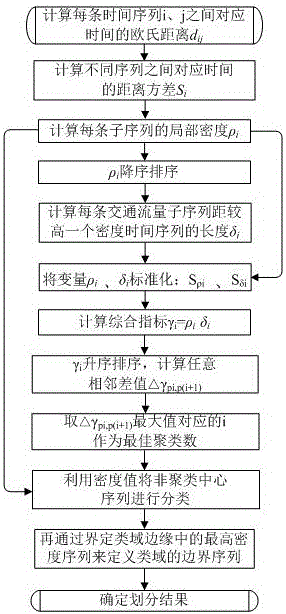
本发明的基本思想主要体现为以下两点:1.每一类的聚类中心其密度值最大;2.聚类中心与其它具有较高密度数据的距离值较大。该方法的核心思想为利用距离方差衡量子序列的相似程度:计算每条子序列的局部密度衡量序列间相互聚集程度,序列间距离用于衡量类分离程度,结合局部密度和序列间距寻求聚类中心;利用密度值将非聚类中心序列进行分类,从而得到交通流量序列的合理分组,最终输出聚类结果。
本发明的基本步骤如下:
c1、计算每条交通流量子序列的局部密度;
c2、按照局部密度对子序列进行排序,计算每条交通流量子序列距离一个较高密度的交通流量子序列的长度;
c3、定义一个综合考虑密度值和距离值的指标,并计算每一个流量子序列下该指标的取值,根据综合指标变化率趋势图得到最佳聚类数和聚类中心;
c4、利用密度值将非聚类中心序列进行分类,再通过界定类域边缘中的最高密度序列来定义类域的边界序列,确定划分结果。
步骤c1的过程包括:
c11、以相等长度为时间间隔(一般取一天,即24小时),将交通流量序列划分为n个子序列,子序列记为X=x1,x2,…,xn;
c12、针对任意一个子序列i,以固定时段为时间间隔将子序列划分成若干区段,通常情况该固定时段取为5分钟、10分钟或者15分钟;区段序列为xi=xi(1),xi(2),…,xi(N).
c13、计算每条子序列的局部密度ρi;
①假设i,j表示任意两条子序列,则子序列i和j之间的欧氏距离dij:
式中:dij为第i、j序列之间对应时间的欧氏距离;r为时段序号;xi(k)为第i个子序列中第r个区段的流量值,N为每个子序列所包含的区段数。欧氏距离时间复杂度相对小,但对噪声数据敏感。如果只需要知道相似程度或排序,无需单调函数平方根。
②计算不同子序列之间的距离方差:
式中:Si为i子序列与其它子序列之间所对应距离的方差;m为距离数,其值为n*(n-1)/2;为所有子序列距离的平均值,表达式为:
③计算每条子序列的局部密度:
式中:ρi为第i个子序列的局部密度;dc为截断距离参数,其取值应使得序列的平均邻居数是数据集中序列总数的1-2%。将计算得到m个距离数据dij,按大小进行排序;假设得到db1≤db2≤…≤dbm,取dc=df(mt),其中f(mt)表示对mt四舍五入得到的整数,t是数据集中序列总数的百分比,一般取1-2%;距离dij小于截断距离dc的数值越多,密度值ρi越大,则子序列i周围所聚集的子序列越多,以此衡量序列间相互聚集程度。
步骤c2的过程包括:
c21、将子序列的局部密度ρi按照大小进行排序ρq1≥ρq2≥,…,≥ρqi≥ρq(i+1)≥,…,≥ρqn,计算每条子序列距离一个较高密度子序列的长度:
式中:δqi为ρi按大小排序后,第qi个区段流量距离一个较高密度子序列的长度;dqiqj为ρi按大小排序后,第qi与qj个子序列之间的距离。当子序列xqi具有最大密度时,δqi表示所有子序列中与xqi的最大距离值;当子序列xqi的最大密度值小于最大密度时,δqi表示在所有局部密度大于xqi的子序列中,所有子序列与xqi之间的最小距离。
步骤c3的过程包括:
c31、将变量ρqi和δqi标准化:
式中:和分别表示变量ρqi和δqi标准化后结果;分别表示变量ρqi和δqi的平均值;σρ和σδ分别表示变量ρqi和δqi的标准差。
c32、引入一个将密度值和距离值综合考虑的指标,其计算方法为:
式中:γqi为综合考虑ρqi和δqi值的指标。
c33、将γqi按升序排序,令其排序为γp1≤γp2≤,…,≤γpi≤γp(i+1)≤,…,≤γpn,计算随着数据不断增大时数值任意相邻γpi的差值,其计算方法为:
△γpi,p(i+1)=γp(i+1)-γpi (1-i)
式中,△γpi,p(i+1)为升序排序后第pi和p(i+1)个子序列的综合指标差值;γp(i+1)和γpi分别表示升序排序后第p(i+1)和pi个子序列的综合指标值。
c34、针对第pi个升序排序的综合指标,可用pi与p(i-1)和p(i+1)之间的变化率比值作为衡量γpi稳定性的指标,即:
式中,ηpi为按照综合指标升序排序后,第pi个子序列的稳定性系数。
c35、用ηpi衡量综合指标的稳定性,并取稳定性系数最大值所对应的pi作为最佳聚类数kop。
c36、选取前kop个综合指标最大的子序列作为聚类中心。
步骤c4的过程包括:
c41、利用密度值将非聚类中心序列进行分类:将每个非聚类中心子序列的密度值ρqi按照从大到小的顺序进行排序,每个子序列被分到一个具有较高密度值的最近相邻子序列所在的类当中。
c42、通过界定类域边缘中的最高密度子序列来定义类域的边界子序列:分配到该类中但与其他类中序列的距离小于dc的序列,计算两者的密度平均值,取平均值中最高密度定义为ρz,类中密度高于ρz的序列作为类的核心部分,其余作为类边缘部分,也称作噪声。
本发明的有益效果:本发明提出了一种基于密度峰值聚类的交通流量序列分类方法,以天为基本时间单元,将一个长时间的交通流量切割成若干子序列,并实现子序列的自动、高效分类。同一类中的子序列均可采用相同的时段划分方案和信号控制方案,在确保交通流运行效率的前提下,减少了定时控制策略下时段划分和信号优化的工作量。
附图说明
图1算法实现过程流程图;
图2综合指标γpi趋势图;
图3γpi突变点判断图;
图4聚类数决策图;
图5数据聚类决策结果图;
图6序列数据聚类转化为2D平面结果图;
图7序列数据聚类结果图。
具体实施方式
以某城市某交叉口24天的流量序列为例,对这24天的数据进行分类,具体实现流程见图1。
1、将总流量序列以天为单元划分成24个子序列,并计算每条子序列的局部密度:
(1)在24条子序列中,计算每两条子序列之间的相似度,记24个子序列为X=x1,x2,…xn;
(2)针对任意一个子序列i,以固定时段为间隔将子序列划分成若干区段,区段序列为xi=xi(1),xi(2),…,xi(N);通常情况下该固定时段取为5分钟、10分钟或者15分钟。
①计算子序列i、j之间对应的欧氏距离dij:
②计算所有子序列距离的平均值:
③计算子序列i与其它子序列之间欧氏距离的方差:
(3)计算每条时间序列的局部密度
①计算截断距离参数dc,将距离dij排序db1≤db2≤…≤dbm,f(mt)表示对mt四舍五入得到的整数:
dc=df(mt) (1-3)
②计算每条子序列的局部密度:
2、计算每条子序列距离一个较高密度子序列的长度,利用局部密度与距离值画出决策图,如附图4所示。
(1)将ρi进行大小排序ρq1≥ρq2≥,…,≥ρqi≥ρq(i+1)≥,…,≥ρqn,当子序列xqi具有最大密度时,δqi表示所有子序列中与xqi之间的最大距离值:
(2)当子序列xqi没有最大密度时,δqi表示在所有局部密度大于xqi的子序列中,所有子序列与xqi之间的最小距离值,即:
3、计算综合指标值
(1)将变量ρqi、δqi标准化
①分别计算变量ρqi、δqi的平均值以及标准差σρ和σδ:
②分别计算ρqi、δqi的标准化结果和
③计算综合指标大小:
(2)将γqi按升序排序,令其排序为γp1≤γp2≤,…,≤γpi≤γp(i+1)≤,…,≤γpn,计算随着数据不断增大时数值任意相邻γpi的差值,其变化规律如图3所示。
△γpi,p(i+1)=γp(i+1)-γpi (3-8)
(3)计算第pi个子序列的稳定性系数ηpi:
令第pi个子序列的稳定性系数最大,则最佳聚类数目kop为(n-pi+1),如附图3所示;
(4)利用得到的最佳分类数kop在图4中以右上角为起点向左下方向画正方形,直到选择前kop个点为止,所圈出来的点即为ρpi、δpi都明显较大的点,所选择的点如图5,作为聚类中心得到序列数据分类转化为2D平面结果图,见图6。
4、利用密度值将非聚类中心序列进行分类,再通过界定类域边缘中的最高密度序列来定义类域的边界序列。
(1)利用密度值将非聚类中心序列进行分类:将每个非聚类中心序列的密度值ρqi按照从大到小的顺序进行排序,每个序列被分到一个具有较高密度值的最近相邻子序列的类当中;
(2)通过界定类域边缘中的最高密度序列来定义类域的边界序列:分配到该类中但与其他类中序列的距离小于dc的序列,计算两者的密度平均值,取平均值中最高密度定义为ρz,类中密度高于ρz的子序列作为类的核心部分,其余作为类边缘部分,也称作噪声。最终得到最后序列的分类结果,如图7所示。
综上,本发明涉及一种交通流量序列的划分方法,具备划分数目自动优化、计算复杂度较低的特点。本发明可将交叉口长时间的流量序列(连续若干天)以天为基本单位划分成若干类,每一类的不同子序列之间具有相似的流量变化特性,在定时控制策略下可采用相同的时段划分方案,为提高时段划分的智能性与科学性、提升交叉口交通流的运行效率提供技术支持,属于交通控制研究领域。
- 还没有人留言评论。精彩留言会获得点赞!