路网数据处理方法、装置与设备与流程
本发明涉及数据处理技术领域,尤其涉及一种路网数据处理方法、装置与设备。
背景技术:
随着城市的发展,路网规模越来越大,车辆越来越多,交通路况也变得越来越复杂。有效的路况预测一方面可以帮助出行人员准确预估通行时间,合理规划出行路径;另一方面可以引导车辆通行,减少交通拥堵。因此,对路况预测的研究具有重要意义。
由于路网中的每条道路并不是相互独立的,其路况会受到上下游多条道路的影响,因而目前的路况预测方法大多数是基于时空关联性建立路网预测模型进行路况预测。其中,在建立路网预测模型进行路况预测时,一般都需要对路网进行切分形成多个子路网,然后基于子路网中路段之间的时空关联性建立路网预测模型。目前比较常用的路网切分方法中,一种是基于网格进行路网切分,即根据一些标准的协议将路网按照四方形或其他形状划分成大小相同的若干个网格(即一个网格对应一个子路网);一种是基于道路数量进行路网切分,比如,根据固定的道路数量(例如100条)进行路网切分。
然而,目前这些常用的路网切分方法都无法保证路网道路之间的时空关联性,可能每个子路网中有许多互不相干(如互不连通)的道路,也可能将强相关的两条道路划分到了两个子路网中,这使得基于子路网建立的路况预测模型的复杂度、预测效果和性能都受到了影响。
技术实现要素:
有鉴于此,本发明提供一种路网数据处理方法、装置与设备,用于降低路况预测模型的复杂度,并提升预测效果和性能。
为了实现上述目的,第一方面,本发明实施例提供一种路网数据处理方法,包括:
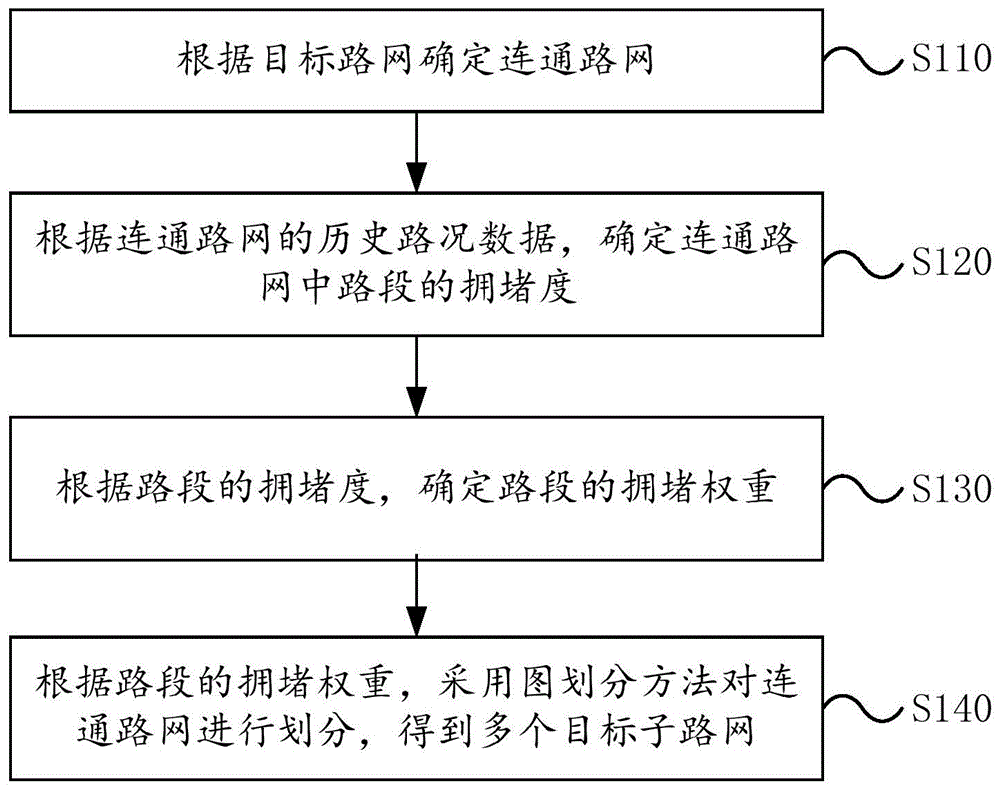
根据连通路网的历史路况数据,确定连通路网中路段的拥堵度;
根据路段的拥堵度,确定路段的拥堵权重;
根据路段的拥堵权重,采用图划分方法对连通路网进行划分,得到多个目标子路网。
作为本发明实施例一种可选的实施方式,所述根据连通路网的历史路况数据,确定连通路网中路段的拥堵度,包括:
将所述连通路网的历史路况数据对应的历史时间段划分为时长相同的子时间段,并确定所述连通路网中路段在每个子时间段内对应的历史路况数据;
根据路段在每个子时间段内对应的历史路况数据中的通行时间数据,确定路段在每个子时间段内的平均通行时长;
根据路段在各个子时间段内的平均通行时长,确定所述路段的拥堵度。
作为本发明实施例一种可选的实施方式,所述根据路段在各个子时间段内的平均通行时长,确定所述路段的拥堵度,包括:
根据所述路段在各个子时间段内的平均通行时长确定所述路段的自由流通行时间;
根据所述路段在每个子时间段内的平均通行时长和所述自由流通行时间,确定所述路段在每个子时间段内的通行状态;
根据所述路段的各个子时间段中通行状态为拥堵状态的子时间段的个数占所述子时间段的总个数的比例确定所述路段的拥堵度。
作为本发明实施例一种可选的实施方式,所述根据所述路段在各个子时间段内的平均通行时长确定所述路段的自由流通行时间,包括:
对所述路段在各个子时间段内的平均通行时长从小到大进行排序;
将排序后的平均通行时长的预设分位数确定为所述路段的自由流通行时间。
作为本发明实施例一种可选的实施方式,所述根据路段的拥堵度,确定路段的拥堵权重,包括:
当所述路段的拥堵度小于预设阈值时,将所述路段的拥堵权重确定为预设权重;
当所述路段的拥堵度大于或等于预设阈值时,根据所述路段的拥堵度采用正相关函数确定所述路段的拥堵权重,其中,采用所述正相关函数确定的任一拥堵权重均大于所述预设权重。
作为本发明实施例一种可选的实施方式,所述根据路段的拥堵权重,采用图划分方法对连通路网进行划分,得到多个目标子路网,包括:
根据路段的拥堵权重采用多层次k路图划分方法对连通路网对应的有向图进行划分,得到多个目标子路网;其中,有向图中以连通路网中路段的起点和终点为顶点,以连通路网中的路段为边。
作为本发明实施例一种可选的实施方式,在所述根据连通路网的历史路况数据,确定连通路网中路段的拥堵度之前,所述方法还包括:
根据目标路网确定连通路网。
作为本发明实施例一种可选的实施方式,所述根据目标路网确定连通路网,包括:
根据目标路网的拓扑关系检查目标路网的连通性;
当目标路网为连通路网时,将所述目标路网确定为连通路网;
当目标路网为非连通路网时,将所述目标路网中的最大连通子路网确定为连通路网,所述最大连通子路网为所述目标路网中路段数量最多的连通子路网。
作为本发明实施例一种可选的实施方式,所述方法还包括:
基于所述多个目标子路网对所述连通路网中的路段进行路况预测。
第二方面,本发明实施例提供一种路网数据处理装置,包括:
拥堵度确定模块,用于根据连通路网的历史路况数据,确定连通路网中路段的拥堵度;
拥堵权重确定模块,用于根据路段的拥堵度,确定路段的拥堵权重;
划分模块,用于根据路段的拥堵权重,采用图划分方法对连通路网进行划分,得到多个目标子路网。
作为本发明实施例一种可选的实施方式,所述拥堵度确定模块具体用于:
将所述连通路网的历史路况数据对应的历史时间段划分为多个时长相同的子时间段,并确定所述连通路网中每个路段在每个子时间段内对应的历史路况数据;
根据路段在每个子时间段内对应的历史路况数据中的通行时间数据,确定所述路段在每个子时间段内的平均通行时长;
根据路段在各个子时间段内的平均通行时长确定所述路段的拥堵度。
作为本发明实施例一种可选的实施方式,所述拥堵度确定模块具体用于:
根据所述路段在各个子时间段内的平均通行时长确定所述路段的自由流通行时间;
根据所述路段在每个子时间段内的平均通行时长和所述自由流通行时间,确定所述路段在每个子时间段内的通行状态;
根据所述路段的各个子时间段中通行状态为拥堵状态的子时间段的个数占所述子时间段的总个数的比例确定所述路段的拥堵度。
作为本发明实施例一种可选的实施方式,所述拥堵度确定模块具体用于:
对所述路段在各个子时间段内的平均通行时长从小到大进行排序;
将排序后的平均通行时长的预设分位数确定为所述路段的自由流通行时间。
作为本发明实施例一种可选的实施方式,所述拥堵权重确定模块具体用于:
当所述路段的拥堵度小于预设阈值时,将所述路段的拥堵权重确定为预设权重;
当所述路段的拥堵度大于或等于预设阈值时,根据所述路段的拥堵度采用正相关函数确定所述路段的拥堵权重,其中,采用所述正相关函数确定的任一拥堵权重均大于所述预设权重。
作为本发明实施例一种可选的实施方式,所述划分模块具体用于:
根据路段的拥堵权重采用多层次k路图划分方法对连通路网对应的有向图进行划分,得到多个目标子路网;其中,有向图中以连通路网中路段的起点和终点为顶点,以连通路网中的路段为边。
作为本发明实施例一种可选的实施方式,所述装置还包括:
路网确定模块,用于在所述拥堵度确定模块根据连通路网的历史路况数据,确定连通路网中每个路段的拥堵度之前,根据目标路网确定连通路网。
作为本发明实施例一种可选的实施方式,所述路网确定模块具体用于:
根据目标路网的拓扑关系检查目标路网的连通性;
当目标路网为连通路网时,将所述目标路网确定为连通路网;
当目标路网为非连通路网时,将所述目标路网中的最大连通子路网确定为连通路网,所述最大连通子路网为所述目标路网中路段数量最多的连通子路网。
作为本发明实施例一种可选的实施方式,所述装置还包括:
路况预测模块,用于基于所述多个目标子路网对所述连通路网中的路段进行路况预测。
第三方面,本发明实施例提供一种路网数据处理设备,包括:存储器和处理器,存储器用于存储计算机程序;处理器用于在调用计算机程序时执行上述第一方面或第一方面的任一实施方式所述的方法。
第四方面,本发明实施例提供一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述第一方面或第一方面的任一实施方式所述的方法。
本发明实施例提供的路网数据处理方法、装置与设备,在进行路网切分时,先根据连通路网的历史路况数据确定连通路网中路段的拥堵度,然后根据路段的拥堵度确定路段的拥堵权重;最后根据路段的拥堵权重采用图划分方法对连通路网进行划分,得到多个目标子路网。即本发明实施例中基于路网的拥堵程度和连通性进行路网切分,这样可以保证路网道路之间的时空关联性,使得切分后的每个子路网内部道路的时空关联性较强,子路网之间的时空关联性较弱,从而可以有效降低路况预测模型的复杂度,并提升预测效果和预测性能。
附图说明
图1为本发明实施例提供的路网数据处理方法的流程示意图;
图2为本发明实施例提供的确定连通路网的流程示意图;
图3为本发明实施例提供的确定路段拥堵度的流程示意图;
图4为本发明实施例提供的有向图的结构示意图;
图5为本发明实施例提供的图划分过程示意图;
图6为本发明实施例提供的路网数据处理装置的结构示意图;
图7为本发明实施例提供的路网数据处理设备的结构示意图。
具体实施方式
针对目前的路网切分方法无法保证路网道路之间的关联性,而影响路况预测模型的复杂度、预测效果和性能的技术问题,本发明实施例提供一种路网数据处理方法、装置与设备,在进行路网切分时,先根据连通路网的历史路况数据确定连通路网中路段的拥堵度,然后根据路段的拥堵度确定路段的拥堵权重;最后根据路段的拥堵权重采用图划分方法对连通路网进行划分,得到多个目标子路网。即本发明实施例中基于路网的拥堵程度和连通性进行路网切分,以保证路网道路之间的时空关联性,使得切分后的每个子路网内部道路的时空关联性较强,子路网之间的时空关联性较弱,从而有效降低路况预测模型的复杂度,并提升预测效果和预测性能。同时,本发明实施例提供的方法亦可以用于城市道路交通管理。
下面以具体地实施例对本发明的技术方案进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例不再赘述。
图1为本发明实施例提供的路网数据处理方法的流程示意图,如图1所示,本实施例提供的方法可以包括如下步骤:
s110、根据目标路网确定连通路网。
具体的,路网由一系列的路段组成,本实施例中,路段可以是作为已知路网的基本道路单元的路链(link),也可以是对路链进行重构而获得的路链集合,即路段可以包括两个以上的路链;路段还可以是路网中一个路口到另一个路口的道路段,具体实现时可以根据实际需要设置路段,本实施例对此不做特别限定。
连通路网中的任意两个路段之间直接或者间接连通(连通是指从一个路段可以通行到另一路段),非连通路网中存在与其他路段不连通的路段。考虑到不连通的路段之间不存在时空关联性,为了提高数据处理效率,本实施例中,在进行路网切分和路况预测时,针对连通路网进行处理。
在具体实现时,可以直接选取连通路网进行路网切分,此时则无需执行步骤s110;为了方便用户使用,本实施例中,也可以对任意地理区域的路网(比如全国路网或者北京市的路网、河北省的路网或者保定市的路网或者北京市朝阳区的路网等等)进行切分,在切分前先根据待处理的路网(此处称为目标路网)确定出连通路网,然后对连通路网再进行切分。
具体的,目标路网可能是路段连通的路网,也可能是存在不连通路段的路网,需要根据目标路网的连通性来确定连通路网,具体实现方法可以参见图2。图2为本发明实施例提供的确定连通路网的流程示意图,如图2所示,该方法可以包括如下步骤:
s111、根据目标路网的拓扑关系检查目标路网的连通性。
本实施例中,可以预先获取目标路网的拓扑关系,拓扑关系中包括目标路网中路段之间的连接关系;然后可以根据拓扑关系中路段之间的连接关系来检查目标路网的连通性,即检查目标路网是否为连通路网。
在具体实现时,可以根据目标路网的拓扑关系建立对应的有向图,其中,有向图可以以目标路网中路段的起点和终点为节点、以目标路网中的路段为边。本实施例中,拓扑关系具体也可以是以目标路网中路段的起点和终点为节点、以目标路网中的路段为边的图结构,此时可以直接将该拓扑关系作为待处理的有向图。
在具体检查目标路网的连通性时,可以基于有向图采用广度优先搜索算法或者深度优先搜索算法搜索出目标路网中的所有连通子路网,若连通子路网的数量等于1,则说明目标路网是连通路网;若连通子路网的数量大于1,则说明目标路网是非连通路网。为了提高处理效率,也可以基于有向图采用广度优先搜索算法或者深度优先搜索算法搜索出目标路网中的一个连通子路网,检查是否遍历完所有顶点,即检查该连通子路网是否包含目标路网中的所有路段,若是则说明目标路网是连通路网,若否则说明目标路网是非连通路网。
s112、当目标路网为连通路网时,将目标路网确定为连通路网。
如果目标路网是连通路网,则可以直接将目标路网确定为连通路网,进行后续的路网切分处理。
s113、当目标路网为非连通路网时,将目标路网中的最大连通子路网确定为连通路网。
目标路网中可能由于一些断路等情况而出现一些小的与主路网(目标路网中路段数量最多的连通子路网,即最大连通子路网)不连通的子路网,这些小的子路网对最大连通子路网的路况预测没有贡献,因此,若目标路网为非连通路网,则去除目标路网中这些小的子路网,将目标路网中的最大连通子路网确定为连通路网。
在具体实现时,可以采用上述广度优先搜索算法或者深度优先搜索算法搜索出目标路网中的所有连通子路网,然后根据各个连通子路网中的路段数量从各个连通子路网中选出最大连通子路网作为连通路网,即将目标路网中路段数量最多的连通子路网确定为连通路网。
s120、根据连通路网的历史路况数据,确定连通路网中路段的拥堵度。
本实施例中,根据连通路网中路段的拥堵程度(即拥堵度)来进行路网切分。具体的,路段的拥堵度可以根据连通路网的历史路况数据来确定,其中,历史路况数据中可以通过对连通路网的历史路况进行监控并记录获得,也可以通过其他数据源平台获取,具体获取方式本实施例对此不做特别限定。历史路况数据中包括连通路网中各路段在一定时间(此处称为历史时间段)内的通行时间数据,其中,每个路段的通行时间数据具体可以包括该历史时间段内出现在该路段上的每个车辆驶过该路段的通行时间数据。
在具体确定拥堵度时,对于每个路段,可以根据该路段在历史时间段内的平均通行时长来确定该路段的拥堵程度。考虑到同一个路段在一天中不同时间段的路况数据差别可能较大,为了提高确定拥堵度的准确性,本实施例中,可以将每个路段的历史路况数据按等时间间隔划分为多个批次,根据各个批次的平均通行时长来确定该路段的拥堵度,具体实现时,可以采用图3所示的方法实现。图3为本发明实施例提供的确定路段拥堵度的流程示意图,如图3所示,该方法可以包括如下步骤:
s121、将连通路网的历史路况数据对应的历史时间段划分为多个时长相同的子时间段,并确定连通路网中路段在每个子时间段内对应的历史路况数据。
具体的,可以根据实际需要确定划分的时间间隔,例如:时间间隔可以选取5分钟,则一天可以划分为288个子时间段;假设连通路网的历史路况数据对应的历史时间段为一周,则该历史时间段可以划分为2016(288*7)个子时间段。可以从每天的0点开始划分,即00:00-00:05为每天的第一个子时间段,当然也可以从历史时间段的起始时间进行划分,本实施例对此不做特别限定;根据划分的每个子时间段对应的时间,即可确定出连通路网中各路段在每个子时间段内对应的历史路况数据。
s122、根据路段在每个子时间段内对应的历史路况数据中的通行时间数据,确定该路段在每个子时间段内的平均通行时长。
具体的,对于某个路段的某个子时间段来说,该子时间段内的通行时间数据中包括该子时间段内出现在该路段上的每个车辆驶过该路段的通行时间数据,根据各个车辆的通行时间数据即可确定出该路段在该子时间段内的平均通行时长。
例如:某路段在某个子时间段(x日y时00分-x日y时05分)内的历史路况数据中包括3辆车的通行时间数据,其中,第一辆车的通行时间数据为x日y时01分10秒-x日y时01分30秒,即通行时长为20秒;第二辆车的通行时长为30秒,第三辆车的通行时长为10秒,则该路段在该子时间段内的平均通行时长为(20+30+10)/3=20秒。当然,此处只是一种示例,并非用于限定本发明。
s123、根据路段在各个子时间段内的平均通行时长,确定该路段的拥堵度。
具体的,在确定出路段在各个子时间段内的平均通行时长后,可以根据该路段的各平均通行时长与预设的时长阈值(自由流通行时间)来确定该路段的拥堵度。考虑到不同路段的通行能力不同,本实施例中,可以根据每个路段的各个平均通行时长来分别确定每个路段的自由流通行时间,进而确定每个路段的拥堵度,具体实现方法如下:
步骤a、根据路段在各个子时间段内的平均通行时长,确定该路段的自由流通行时间。
具体的,对于某一个路段,可以对该路段在各个子时间段内的平均通行时长从小到大进行排序;然后将排序后的平均通行时长的预设分位数确定为路段的自由流通行时间。
其中,该预设分位数具体可以根据实际情况确定,例如可以为15%分位数。举例说明,假设某路段一共2016(288*7)个子时间段,各个子时间段的平均通行时间中,有1000个为10秒,800个为12秒,216个为20秒;将这2016个平均通行时间从小到大排列,15%分位数就是第302(2016*0.15)个子时间段,为10秒,该10秒即为自由流通行时间。
当然,自由流通行时间也可以采用其他方法确定,例如可以根据每个路段的各子时间段的平均通行时长的均值确定,具体的确定方法本实施例不做特别限定。
步骤b、根据路段在每个子时间段内的平均通行时长和自由流通行时间,确定路段在每个子时间段内的通行状态确定为拥堵状态。
具体的,在确定出自由流通行时间后,可以根据自由流通行时间确定一拥堵时间阈值,例如可以将自由流通行时间的1.5倍对应的时间确定为拥堵时间阈值;然后将该路段在每个子时间段内的平均通行时长与该拥堵时间阈值进行比较,确定该路段在每个子时间段内的通行状态。
继续以上述举例为例,那么拥堵状态的划分标准(即拥堵时间阈值)就是15秒,则2016个子时间段中,有216个子时间段的通行状态为拥堵状态。
步骤c、根据路段的各个子时间段中通行状态为拥堵状态的子时间段的个数占所述子时间段的总个数的比例确定路段的拥堵度。
具体的,在确定出路段在各个子时间段内的通行状态后,可以直接将路段的各个子时间段中通行状态为拥堵状态的子时间段的数量占子时间段的总个数的比例确定为路段的拥堵度。继续以上述举例为例,2016个子时间段中,有216个子时间段的通行状态为拥堵状态,则拥堵度为0.1(216/2016)。当然,也可以采用其他方法确定路段的拥堵度,本实施例对此不做特别限定。
s130、根据路段的拥堵度,确定路段的拥堵权重。
具体的,可以采用一个正相关函数来根据每个路段的拥堵度确定每个路段的拥堵权重;为了放大存在拥堵的路段的权重,本实施例中,也可以确定一预设阈值,对于每个路段,当路段的拥堵度小于预设阈值时,将路段的拥堵权重确定为预设权重;当路段的拥堵度大于或等于预设阈值时,根据路段的拥堵度采用正相关函数确定路段的拥堵权重,其中,采用正相关函数确定的任一拥堵权重均大于预设权重。
其中,预设阈值和预设权重的值均可以根据实际需要选择,例如预设阈值可以为0.02,预设权重可以为1;正相关函数也可以根据实际需要选择,例如可以为1+x+x2,只要可以使拥堵权重显著大于预设权重即可。
s140、根据路段的拥堵权重,采用图划分方法对连通路网进行划分,得到多个目标子路网。
具体的,可以根据连通路网建立对应的有向图,采用图划分方法对有向图进行划分,得到多个目标子路网,其中,有向图中以连通路网中路段的起点和终点为顶点,以连通路网中的路段为边,边的方向即为对应的路段中车辆的行驶方向,边的拥堵权重即为对应的路段的拥堵权重。如前面所述,当连通路网的拓扑关系为以连通路网中路段的起点和终点为节点、以连通路网中路段为边的图结构时,也可以直接将该连通路网的拓扑关系作为待划分的有向图进行划分。
其中,图划分方法具体可以是多层次k路图划分方法,也可以是其他图划分方法,例如多层递归二分算法。以多层次k路图划分方法为例,其划分过程包括三个阶段:粗化阶段(coarseningphase)、初始划分阶段(initialpartitioningphase)和细化阶段(uncoarseningphase)。
其中,粗化阶段是将原始图的规模进行压缩,使原始图经过粗化得到较小规模的粗化图,以便划分算法在较小规模图上进行快速有效的划分。在此过程中,为了得到较高质量的划分结果,需要在较短时间内不断隐藏权重较大的边,使其得到一个暴露的边权重较小的小规模图。
初始划分阶段是对粗化图进行k划分。其中,划分原则为:保证划分后每个粗化子图内的节点为时空关联性较强的,粗化子图内的边应权重相对较大,以保证粗化子图内的高内聚性;并保证划分后的各子图间的割边数量尽可能少,且尽量保证粗化子图间割边的边权重也尽可能小,从而使得下一细化阶段局部调整次数减少,提高细化阶段的效率。所述割边是指用于切割出子图的边。
细化阶段是对粗化阶段中压缩合并的节点逐层还原,将对粗化图的k划分映射到对原始图的k划分。
举例说明,图4为本发明实施例提供的有向图的结构示意图,如图4所示,假设连通路网对应的有向图中包括顶点集合{v1,v2,v3,v4,v5,v6,v7,v8,v9,v10}。图5为本发明实施例提供的图划分过程示意图,如图5所示,在进行图划分时,先在粗化阶段中基于边权重(即边对应的路段的拥堵权重)将原始图转化为小规模的粗化图,其中,v1,2表示粗化图中v1和v2合并为一个顶点v1,2,其他顶点表示的意思类似,此处不再详述;然后在初始划分阶段中将粗化图划分为两个粗化子图,其中一个粗化子图中包括顶点v1,2、v3,4和v6,8,另一个粗化子图(灰色顶点所形成的图)中包括顶点v5,9和v7,10;最后在细化阶段将对粗化图的划分结果映射到原始图中,得到两个子图:{v1,v2,v3,v4,v6,v8}和{v5,v7,v9,v10}。
在进行图划分时,由于经常发生拥堵的路段权重都很大,不会被分割,每个目标子路网之间的边界边(即割边的边)都是很少发生拥堵的路段,因此路网切分后能够保证路网道路之间的时空关联性,使得切分后的每个目标子路网内部道路的时空关联性较强,目标子路网之间的时空关联性较弱。
本实施例中,在进行路网切分后,就可以基于多个目标子路网对连通路网中的路段进行路况预测。路况预测的结果与划分的目标子路网的时空关联性密切相关,由于本实施例中基于路网的拥堵程度和连通性进行路网切分,因而可以保证路网路段之间的时空关联性,使得切分后的每个目标子路网内部路段的时空关联性较强,目标子路网之间的时空关联性较弱,进而也就可以有效的降低路况预测模型的复杂度,并提升预测效果和预测性能。
具体的路网中的路况预测方法可以采用目前常用的基于时空关联性建立路网预测模型进行路况预测的方法,即可以根据各个目标子路网的历史路况数据建立路网预测模型,然后将各个目标子路网的实时路况数据输入建立的路网预测模型,以对各个目标子路网的路况进行预测。
本实施例提供的路网数据处理方法,在进行路网切分时,先根据连通路网的历史路况数据确定连通路网中路段的拥堵度,然后根据路段的拥堵度确定路段的拥堵权重;最后根据路段的拥堵权重采用图划分方法对连通路网进行划分,得到多个目标子路网。即本发明实施例中基于路网的拥堵程度和连通性进行路网切分,这样可以保证路网道路之间的时空关联性,使得切分后的每个子路网内部道路的时空关联性较强,子路网之间的时空关联性较弱,从而可以有效降低路况预测模型的复杂度,并提升预测效果和预测性能。
基于同一发明构思,作为对上述方法的实现,本发明实施例提供了一种路网数据处理装置,该装置实施例与前述方法实施例对应,为便于阅读,本装置实施例不再对前述方法实施例中的细节内容进行逐一赘述,但应当明确,本实施例中的装置能够对应实现前述方法实施例中的全部内容。
图6为本发明实施例提供的路网数据处理装置的结构示意图,如图6所示,本实施例提供的装置包括:
拥堵度确定模块110,用于根据连通路网的历史路况数据,确定连通路网中路段的拥堵度;
拥堵权重确定模块120,用于根据路段的拥堵度确定路段的拥堵权重;
划分模块130,用于根据路段的拥堵权重,采用图划分方法对连通路网进行划分,得到多个目标子路网。
作为本发明实施例一种可选的实施方式,拥堵度确定模块110具体用于:
将连通路网的历史路况数据对应的历史时间段划分为多个时长相同的子时间段,并确定连通路网中每个路段在每个子时间段内对应的历史路况数据;
根据路段在每个子时间段内对应的历史路况数据中的通行时间数据,确定该路段在每个子时间段内的平均通行时长;
根据路段在各个子时间段内的平均通行时长确定该路段的拥堵度。
作为本发明实施例一种可选的实施方式,拥堵度确定模块110具体用于:
对于每个路段,根据路段在各个子时间段内的平均通行时长确定路段的自由流通行时间;
根据路段在每个子时间段内的平均通行时长和自由流通行时间,确定路段在每个子时间段内的通行状态;
根据路段的各个子时间段中通行状态为拥堵状态的子时间段的个数占子时间段的总个数的比例确定路段的拥堵度。
作为本发明实施例一种可选的实施方式,拥堵度确定模块110具体用于:
对路段在各个子时间段内的平均通行时长从小到大进行排序;
将排序后的平均通行时长的预设分位数确定为路段的自由流通行时间。
作为本发明实施例一种可选的实施方式,拥堵权重确定模块120具体用于:
对于每个路段,当路段的拥堵度小于预设阈值时,将路段的拥堵权重确定为预设权重;
当路段的拥堵度大于或等于预设阈值时,根据路段的拥堵度采用正相关函数确定路段的拥堵权重,其中,采用正相关函数确定的任一拥堵权重均大于预设权重。
作为本发明实施例一种可选的实施方式,划分模块130具体用于:
根据路段的拥堵权重采用多层次k路图划分方法对连通路网对应的有向图进行划分,得到多个目标子路网;其中,有向图中以连通路网中路段的起点和终点为顶点,以连通路网中的路段为边。
作为本发明实施例一种可选的实施方式,该装置还包括:
路网确定模块140,用于在拥堵度确定模块110根据连通路网的历史路况数据,确定连通路网中每个路段的拥堵度之前,根据目标路网确定连通路网。
作为本发明实施例一种可选的实施方式,路网确定模块140具体用于:
根据目标路网的拓扑关系检查目标路网的连通性;
当目标路网为连通路网时,将目标路网确定为连通路网;
当目标路网为非连通路网时,将目标路网中的最大连通子路网确定为连通路网,最大连通子路网为目标路网中路段数量最多的连通子路网。
作为本发明实施例一种可选的实施方式,该装置还包括:
路况预测模块150,用于基于多个目标子路网对连通路网中的路段进行路况预测。
本实施例提供的路网数据处理装置可以执行上述方法实施例,其实现原理与技术效果类似,此处不再赘述。
基于同一发明构思,本发明实施例还提供了一种路网数据处理设备。图7为本发明实施例提供的路网数据处理设备的结构示意图,如图7所示,本实施例提供的路网数据处理设备包括:存储器210和处理器220,存储器210用于存储计算机程序;处理器220用于在调用计算机程序时执行上述方法实施例所述的方法。
本实施例提供的路网数据处理设备可以执行上述方法实施例,其实现原理与技术效果类似,此处不再赘述。
本发明实施例还提供一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述方法实施例所述的方法。
本领域技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质上实施的计算机程序产品的形式。
处理器可以是中央处理单元(centralprocessingunit,cpu),还可以是其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现成可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
存储器可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flashram)。存储器是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动存储介质。存储介质可以由任何方法或技术来实现信息存储,信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitorymedia),如调制的数据信号和载波。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!