通勤时间预测方法、通勤时间预测模型的训练方法和装置与流程
本申请涉及信息检索技术领域,特别涉及一种通勤时间预测方法、通勤时间预测模型的训练方法和装置。
背景技术:
在交通出行领域,通勤时间预测是一个重要的课题,其在许多交通服务中扮演了重要的角色,例如地图导航推荐服务和城市物流服务。通勤时间预测指的是给定出发地、目的地以及出发时间,然后预测再出发时间开始从出发地到目的地需要花费多长时间。进一步的,该预测问题可以分为两大类问题:一类是给定路径预测时间,另一类是不给定具体路径预测时间。
相关技术中,对于不给定具体路径的通勤时间预测问题,该问题也叫做od(origin-destination,出发地-目的地)通勤时间预测问题,主要难点在于没有指定从出发地到目的地的路径。其中,一种解决思路是先遍历生成从出发地到目的地的所有路径然后利用轨迹通勤时间预测的现有方法预测所有路径对应的通勤时间,最后计算这些预测时间的均值作为最终的预测结果。但是,这种方法需要生成路径,这在大规模路网上显得十分低效,所以不能完成od通勤时间的在线预测。
为了解决这个问题,一些研究者通过检索具有相似起始点的历史轨迹来估算通勤时间,但是这种方法在数据稀疏的情况下无法得到合理的预测结果。随着深度学习技术的普及和发展,一些研究人员致力于设计神经网络模型将od输入直接端到端地生成预测值。例如,kdd18上的一篇相关文章利用了多任务学习的方法同时预测通勤时间和通勤距离等来强化预测的准确性。但是,给定od输入,其对应的通勤时间应该和选择的路径有关系。因此,如果将od输入和选择的路径绑定起来但是又不用去实际遍历生成所有路径成为解决od通勤时间预测问题的挑战。
技术实现要素:
本申请旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本申请提出一种通勤时间预测方法,能够充分利用历史数据中包含的轨迹信息,提高通勤时间预测的准确性。
本申请提出一种通勤时间预测模型的训练方法。
本申请提出一种通勤时间预测装置。
本申请提出一种通勤时间预测模型的训练装置。
本申请一方面实施例提出了一种通勤时间预测方法,包括:
接收出发地、目的地和出发时间;
根据预设时空输入编码模块对出发地和目的地进行处理,得到路网路段序号和路段偏移量;
根据时空输入编码模块对出发时间映射进行处理,得到时间片序号和时间片偏移量;
根据预设轨迹编码模块对路网路段序号、路段偏移量、时间片序号和时间片偏移量进行编码得到定长向量;
根据预设时间预测模块对定长向量进行处理,输出目标通勤时间。
本申请另一方面实施例提出了一种通勤时间预测模型的训练方法,包括:
获取历史轨迹数据样本,对所历史轨迹数据样本进行分析,获取出发地样本、目的样本、出发时间样本、外部信息样本和通勤时间样本;
通过地图匹配技术将出发地样本和目的样本对应的空间点映射到路段上,然后使用路段序号以及映射点的路段偏移量,将出发时间样本对应的时间戳映射到时间片上,然后使用时间片序号以及映射后的时间偏移量,对外部信息样本进行编码生成外部特征编码;
根据所述出发地样本、目的地样本、出发时间样本和外部信息样本对应的编码对时空输入编码模块进行训练;
将出发地样本、目的地样本、出发时间样本和外部信息样本对应的编码拼接起来,并利用一个两层的全连接神经网络编码为定长向量,根据所述定长向量对轨迹编码模块进行训练;
根据所述定长向量和所述通勤时间样本对时间预测模块进行训练。
本申请又一方面实施例提出了一种通勤时间预测装置,包括:
接收模块,用于接收出发地、目的地和出发时间;
第一处理模块,用于根据预设时空输入编码模块对出发地和目的地进行处理,得到路网路段序号和路段偏移量;
第二处理模块,用于根据时空输入编码模块对出发时间映射进行处理,得到时间片序号和时间片偏移量;
编码模块,用于根据预设轨迹编码模块对路网路段序号、路段偏移量、时间片序号和时间片偏移量进行编码得到定长向量;
预测模块,用于根据预设时间预测模块对定长向量进行处理,输出目标通勤时间。
本申请再一方面实施例提出了一种通勤时间预测模型的训练装置,包括:
获取模块,用于获取历史轨迹数据样本,对所述历史轨迹数据样本进行分析,获取出发地样本、目的样本、出发时间样本、外部信息样本和通勤时间样本;
编码模块,用于通过地图匹配技术将出发地样本和目的样本对应的空间点映射到路段上,然后使用路段序号以及映射点的路段偏移量,将出发时间样本对应的时间戳映射到时间片上,然后使用时间片序号以及映射后的时间偏移量,对外部信息样本进行编码生成外部特征编码;
第一训练模块,用于根据所述出发地样本、目的地样本、出发时间样本和外部信息样本对应的编码对时空输入编码模块进行训练;
第二训练模块,用于将出发地样本、目的地样本、出发时间样本和外部信息样本对应的编码拼接起来,并利用一个两层的全连接神经网络编码为定长向量,根据所述定长向量对轨迹编码模块进行训练;
第三训练模块,用于根据所述定长向量和所述通勤时间样本对时间预测模块进行训练。
本申请实施例所提供的技术方案可以包含如下的有益效果:
通过收出发地、目的地和出发时间;将出发地和目的地映射到路网上,得到路网路段序号和路段偏移量;将出发时间映射到时间片上,得到时间片序号和时间片偏移量;根据时空输入编码模块对路网路段序号、路段偏移量、时间片序号和时间片偏移量进行编码得到定长向量;根据时间预测模块对定长向量进行处理,输出目标通勤时间。由此,提高出发地到目的地通勤时间预测的准确性。
附图说明
本申请上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1为本申请实施例所提供的一种通勤时间预测方法的流程示意图;
图2为本申请实施例所提供的一种通勤时间预测模型的训练方法的流程示意图;
图3为本申请实施例所提供的构造并训练通勤时间预测模型的流程图;
图4为本申请实施例所提供的一种通勤时间预测模型的结构图;
图5为本申请实施例所提供的路网以及经过路网匹配后的轨迹示例图;
图6为本申请实施例所提供的改造后的路网示例图;
图7为本申请实施例所提供的时间片连接图的构造示例图;
图8为本申请实施例所提供的时间区间编码子模块结构图;
图9为本申请实施例所提供的轨迹编码模块结构图;
图10为本申请实施例所提供的通勤时间模型进行预测的流程图;
图11为本申请实施例所提供的一种通勤时间预测装置的结构示意图;
图12为本申请实施例所提供的一种通勤时间预测模型的训练装置的结构示意图。
具体实施方式
下面详细描述本申请的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本申请,而不能理解为对本申请的限制。
下面参考附图描述本申请实施例的通勤时间预测方法、通勤时间预测模型的训练方法和装置。
本申请实施例的通勤时间预测方法,在传统端到端的预测模块的基础上设计了辅助模块:轨迹编码模块。通过该模块的加入,可以在训练阶段利用历史轨迹辅助传统端到端预测模块的训练,使得模型对于od输入的编码绑定到历史选择轨迹的编码。由此解决将od输入和选择的路径绑定起来但是又不用去实际遍历生成所有路径的问题。
本申请实施例中,利用历史收集的数据进行训练得到模型的参数,最后使用训练好的模型预测通勤时间,模型包含三大模块:时空输入编码模块,轨迹编码模块和时间预测模块。
首先,在空间维度,利用地图匹配算法将出发地和目的地映射到路段上,然后利用路段的嵌入向量和偏移量来联合表示出发地和目的地;同理,在时间维度,本发将连续时间划分成时间片并将出发时间映射到时间片上,然后利用时间片的嵌入向量和偏移量来联合表示出发时间;此外,为了保证路段在路网上的拓扑性质以及时间的连续和周期性质,分别利用图嵌入技术初始化路网以及时间片的嵌入向量表示;至此,可以获得出发地-目的地输入的时空编码,时间预测模块使用了多层感知器模型将其转换为预测的时间。
此外,为了利用历史轨迹提升预测效果,该方法设计了轨迹编码模块。首先,分别通过地图匹配技术和差值技术将轨迹点的经纬度和时间戳映射到路段和时间片上,因此可将轨迹点序列表示为路段序列以及时间片序列,最后使用深度序列编码模型得到轨迹的最终编码。其中,历史的轨迹信息只存在于训练数据中,所以在实际预测中没有轨迹数据的参与。也就说是,轨迹编码模块只用于辅助其他两个模块的训练,在实际预测过程中使用的模块只包含时空输入编码模块和时间预测模块。
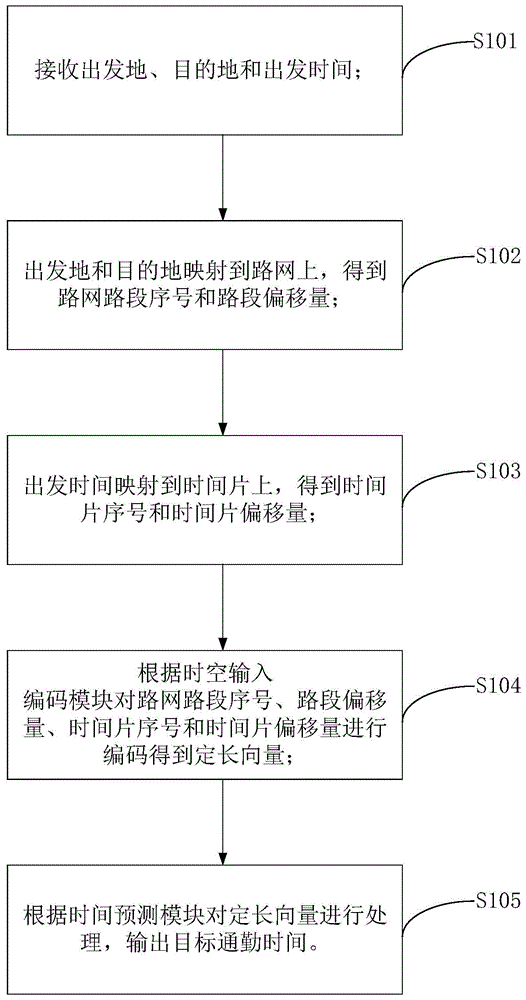
图1为本申请实施例所提供的一种通勤时间预测方法的流程示意图。
如图1所示,该方法包括以下步骤:
步骤101,接收出发地、目的地和出发时间;
在本申请的一个实施例中,出发地和目的地指的是空间点,用经纬度表示,出发时间指的是时间戳,用一个浮点数表示。
具体地,接收出发地的经纬度坐标、目的地的经纬度坐标以及出发时间,本申请的通勤时间预测方法可以预测从出发地到目的地大概需要花费多长时间。
步骤102,将出发地和目的地映射到路网上,得到路网路段序号和路段偏移量;
步骤103,将出发时间映射到时间片上,得到时间片序号和时间片偏移量。
步骤104,根据时空输入编码模块对路网路段序号、路段偏移量、时间片序号和时间片偏移量进行编码得到定长向量。
在本申请的一个实施例中,获取历史轨迹数据样本,根据历史轨迹数据样本和深度神经网络模型训练生成时空输入编码模块,具体的训练过程参见后续实施例的描述。
在本申请的一个实施例中,时空输入编码模块是一个将od输入编码成隐向量表示的深度神经网络模型,其中,时空输入编码模块包含路段编码子模块、时间片编码子模块和外部特征编码子模块。时空输入编码模块使用了地图匹配技术将od输入中的出发地和目的地对应的空间点映射到路段上,然后使用路段的序号以及映射点在路段上的偏移量来联合表示原来的空间点。其中,路段编码指的是将路段的独热编码通过全连接神经网络转换为分布式向量表示;路段编码使用了图嵌入技术对编码网络的参数进行初始化以保证路段编码后的分布式向量表示之间的路网拓扑性质。图嵌入技术将路网图改造成以路段作为节点以路段间的连接关系作为边,并且根据历史轨迹连续经过相邻的两条路段的次数作为边权重的有向图,然后利用现有的图嵌入方法“node2vec”得到每个节点的表示,即路段的初始化表示,最后用该表示去初始化编码网络的参数。
在本申请的一个实施例中,将出发时间对应的时间戳映射到时间片上,然后使用时间片的序号以及映射后的偏移量来联合表示原来的时间戳。
具体地,时间片指的是每隔十分钟的时间片段。考虑到时间片的有限性以及交通状态的周期性,只需要将一周的时间每隔十分钟划分为一个时间片,所以一周共有7*24*6=1008个时间片。时间片编码指的是将时间片的独热编码通过全连接神经网络转为分布式向量表示。时间片编码使用了图嵌入技术对编码网络的参数进行初始化以保证时间片编码后的分布式标志之间的时间连续性和周期性。图嵌入技术将一周的1008个时间片构造成时间片连接图,其中节点是每个时间片,边有两类:相邻的时间片的连接边和相邻天的相同时间的连接边;然后利用现有的图嵌入方法“node2vec”得到每个节点的表示,即时间片的初始化表示,最后用该表示去初始化编码网络的参数。
在本申请实施例中,获取外部输入信息,并对外部输入信息进行编码处理得到外部特征编码,根据时间预测模块对定长向量进行处理,输出预测时间,包括:根据时间预测模块对定长向量和外部特征编码进行处理,输出目标通勤时间。
进一步地,外部输入信息指的是预测时的上下文信息,比如天气、交通状态等。因为上下文信息对于预测的结果有影响,所以如果能够获得外部信息的情况下需要获取外部特征编码,外部特征编码指的是将预测时上下文信息通过神经网络编码成向量表示。其中,天气信息是通过全连接神经网络将代表天气类型的独热编码转为分布式向量表示;交通状态信息通过划分城市的交通状态为矩阵并利用卷积神经网络编码为向量表示;时空输入编码模块将出发地、目的地、出发时间和外部信息对应的编码拼接起来,并利用一个两层的全连接神经网络编码为定长向量,该定长向量即是od输入的整体编码表示。其中,出发地和目的地的对应编码包含匹配的路段的编码以及在路段上的偏移,出发时间的对应编码包含匹配的时间片的编码以及在时间片上的偏移。
步骤105,根据时间预测模块对定长向量进行处理,输出目标通勤时间。
在本申请的一个实施例中,获取历史轨迹数据样本,根据历史轨迹数据样本和深度神经网络模型训练生成时间预测模块,具体的训练过程参见后续实施例的描述。
在本申请的一个实施例中,时间预测模块包含一个全连接神经网络模型,该模型能够将od输入编码后的向量转化为预测的通勤时间。
由此,能够充分利用历史数据中包含的轨迹信息,提高od通勤时间预测的准确性。
图2为本申请实施例所提供的一种通勤时间预测模型的训练方法的流程示意图。
如图2所示,该方法包括以下步骤:
步骤201,获取历史轨迹数据样本,对历史轨迹数据样本进行分析,获取出发地样本、目的样本、出发时间样本、外部信息样本和通勤时间样本。
步骤202,通过地图匹配技术将出发地样本和目的样本对应的空间点映射到路段上,然后使用路段序号以及映射点的路段偏移量,将出发时间样本对应的时间戳映射到时间片上,然后使用时间片序号以及映射后的时间偏移量,对外部信息样本进行编码生成外部特征编码。
步骤203,根据出发地样本、目的地样本、出发时间样本和外部信息样本对应的编码对时空输入编码模块进行训练。
步骤204,将出发地样本、目的地样本、出发时间样本和外部信息样本对应的编码拼接起来,并利用一个两层的全连接神经网络编码为定长向量,根据定长向量对轨迹编码模块进行训练。
步骤205,根据定长向量和通勤时间样本对时间预测模块进行训练。
本申请的一个实施例中,历史轨迹数据样本指的是全球定位系统采样的时空点的序列,每个点由经度、纬度和时间戳三个维度构成,以及获取外部信息;
本申请的一个实施例中,路段序号指的是将路段的独热编码通过全连接神经网络转换为分布式向量表示;时间片序号指的是将时间片的独热编码通过全连接神经网络转为分布式向量表示;外部特征编码指的是将预测时上下文信息通过神经网络编码成向量表示。
本申请的一个实施例中,轨迹编码模块将轨迹数据看成路段和时间区间的序列;轨迹编码模块利用时间区间编码子模块将时间区间序列编码为定长向量表示序列;利用时空输入编码模块中的路段编码模型将路段序列编码为定长向量表示序列;将上述两个序列中的元素一一拼接得到新的序列;利用深度序列编码模型将该新序列编码为隐向量表示;将该隐向量与轨迹的首尾点在路段上的偏移量拼接起来得到新的向量;最后使用一个两层全连接神经网络将该新向量编码为最终的轨迹定长向量。
本申请的一个实施例中,根据预测通信时间和通勤时间样本之间的均方误差,以及输入编码得到的向量和轨迹编码得到的向量之间的平均绝对误差对所述时间预测模块进行调整。
具体地,路网指的是一个城市的道路系统,其可表示为有向图的形式。其中,路网的路段表示为有向图的边,路段和路段的交叉口表示为有点图的节点。
具体地,历史轨迹数据指的是gps(globalpositionsystem)采样的时空点的序列,每个点由经度、纬度和时间戳三个维度构成。一般而言,网约车系统等可以收集到很多历史轨迹数据,一条历史轨迹数据对应了一个od通勤时间预测的输入(出发地、目的地和出发时间)和输出(轨迹的通勤时间)。
本申请训练的模型包括:时空输入编码模块、时间预测模块和轨迹编码模块。
具体地,时空输入编码模块是一个将od输入编码成隐向量表示的深度神经网络模型,其中,包含路段编码子模块、时间片编码子模块和外部特征编码子模块。
具体地,时空输入编码模块使用了地图匹配技术将od输入中的出发地和目的地对应的空间点映射到路段上,然后使用路段的序号以及映射点在路段上的偏移量来联合表示原来的空间点。其中,地图匹配技术使用的是现有的方法。
其中,路段编码指的是将路段的独热编码通过全连接神经网络转换为分布式向量表示;路段编码使用了图嵌入技术对编码网络的参数进行初始化以保证路段编码后的分布式向量表示之间的路网拓扑性质。
其中,图嵌入技术将路网图改造成以路段作为节点以路段间的连接关系作为边,并且根据历史轨迹连续经过相邻的两条路段的次数作为边权重的有向图,然后利用现有的图嵌入方法“node2vec”得到每个节点的表示,即路段的初始化表示,最后用该表示去初始化编码网络的参数。
具体地,时空输入编码模块将出发时间对应的时间戳映射到时间片上,然后使用时间片的序号以及映射后的偏移量来联合表示原来的时间戳。所述时间片指的是每隔十分钟的时间片段。考虑到时间片的有限性以及交通状态的周期性,只需要将一周的时间每隔十分钟划分为一个时间片,所以一周共有7*24*6=1008个时间片。
其中,时间片编码指的是将时间片的独热编码通过全连接神经网络转为分布式向量表示。
其中,时间片编码使用了图嵌入技术对编码网络的参数进行初始化以保证时间片编码后的分布式标志之间的时间连续性和周期性。所述图嵌入技术将一周的1008个时间片构造成时间片连接图,其中节点是每个时间片,边有两类:相邻的时间片的连接边和相邻天的相同时间的连接边;然后利用现有的图嵌入方法“node2vec”得到每个节点的表示,即时间片的初始化表示,最后用该表示去初始化编码网络的参数。
具体地,外部输入信息指的是预测时的上下文信息,比如天气、交通状态等。因为上下文信息对于预测的结果有影响,所以如果能够获得外部信息的情况下需要将外部输入信息进行编码,外部特征编码指的是将预测时上下文信息通过神经网络编码成向量表示。其中,天气信息是通过全连接神经网络将代表天气类型的独热编码转为分布式向量表示,交通状态信息通过划分城市的交通状态为矩阵并利用卷积神经网络编码为向量表示。
具体地,时空输入编码模块将出发地、目的地、出发时间和外部信息对应的编码拼接起来,并利用一个两层的全连接神经网络编码为定长向量,该向量即是od输入的整体编码表示。其中,出发地和目的地的对应编码包含匹配的路段的编码以及在路段上的偏移,出发时间的对应编码包含匹配的时间片的编码以及在时间片上的偏移。
具体地,时间预测模块包含一个全连接神经网络模型,该模型能够将od输入编码后的向量转化为预测的通勤时间。
具体地,轨迹编码模块将轨迹数据看成路段和时间区间的序列。其中,首先利用现有的地图匹配算法将轨迹匹配到路段上,从而使得轨迹在空间上被表示为路段的序列;然后利用差值的算法计算匹配后的每条路段在该轨迹上对应的时间区间,即经过路段首尾点的时间,从而使得轨迹在时间上被表示为时间区间的序列。
具体地,轨迹编码模块包含一个时间区间编码子模块,该子模块首先将时间区间转化为时间片序列以及首位时间戳在时间片上的偏移;然后利用od输入编码模块中的时间片编码模型将此处的时间片序列转换为向量表示序列;进而将得到的向量表示序列看成矩阵并利用深度卷积网络编码得到时间片序列的定长向量表示;接着通过拼接该定长向量和首尾时戳在时间片上的偏移得到新的向量;最后通过一个两层全连接网络将新向量转化为最终的时间区间定长向量表示。
具体地,轨迹编码模块利用时间区间编码子模块将时间区间序列编码为定长向量表示序列;利用od输入编码模块中的路段编码模型将路段序列编码为定长向量表示序列;将上述两个序列中的元素一一拼接得到新的序列;利用深度序列编码模型将该新序列编码为隐向量表示;将该隐向量与轨迹的首尾点在路段上的偏移量拼接起来得到新的向量;最后使用一个两层全连接神经网络将该新向量编码为最终的轨迹定长向量。
具体地,通勤时间预测算法考虑两个损失函数,一个是预测的时间和真实时间之间的平均绝对误差,一个是od输入编码得到的向量和轨迹编码得到的向量之间的欧氏距离。
在本申请的一个实施例中,定义相关概念以及问题:路网,历史轨迹和od通勤时间预测问题,同时明确模型的输入和输出;基于pytorch深度学习框架实现时空输入编码模块,该时空输入编码模块包含时间片编码子模块和路网路段编码子模块;基于pytorch深度学习框架实现时间预测模块,该模块为两层的全连接神经网络;基于pytorch深度学习框架实现轨迹编码模块,该模块包含时间区间编码子模块;实现损失函数并利用历史数据训练模型。
如图3所示,包括:
步骤301:形式化定义od通勤时间预测问题,明确问题的输入输出;
步骤302:设计od时空输入编码模块,利用图嵌入技术初始化路网和时间片的向量表示;
步骤303:设计基于多层感知器的时间预测模块;
步骤304:设计轨迹编码模块,利用地图匹配和差值技术将轨迹表示成序列再编码;
步骤305:收集历史数据训练s102和s104中的模型。
其中,步骤s301形式化定义od通勤时间预测问题时,明确了问题的输入和输出分别如下:输入指的是出发地、目的地和出发时间,此外如果外部输入信息(例如天气和交通状态)可以被获取,输入应该也包括外部信心;输出就是通勤时间。训练过程中使用的数据是历史数据,而历史数据每个输入对应了一条路网上的轨迹,因此训练时每个输入包含一条轨迹信息。但是,在使用训练好的模型预测未来通勤时间的时候,输入并不包含轨迹信息。因此,本问题的核心是设计的模型需要解决训练和实际使用时输入不一致的问题。
步骤s302-s303阐述了本申请设计的模型的三个主要模块,即时空编码模块、时间预测模块和轨迹编码模块。如图4所示,这三个模块分别被表示成mo、me和mt。首先,mo模块接受od输入出发地g[1]、目的地g[-1]、出发时间t和外部特征f,并编码生成向量code。然后,me模块接受mo模块的输出code,并产生预测的通勤时间。此处,本申请使用均方误差函数计算预测通勤时间和真实的通勤时间的不同,并记做mainloss,然后模型在训练时可以通过最小化该不同训练参数。最后,模块mt作为辅助模块用于将一条轨迹编码成一个向量表示stcode,同时计算code和stcode之间的不同,并记做auxiliaryloss,最后模型在训练时通过最小化该不同将每个训练集中的od输入的编码绑定到对应的历史轨迹上。
在上述步骤s302中,本申请设计的od时空输入编码模块将od输入编码成定长向量code。第一,该模块将输入中的出发地g[1]、目的地g[-1]和出发时间t进行了预处理操作。对于出发地g[1]和目的地g[-1],使用现有的地图匹配技术将他们映射到路网的路段上,然后用映射到的路段(e1,en)和在路段上的相对偏移量(r[1],r[-1])来表示他们。其中,偏移量指的是映射到路段上的点离路段起点的距离占整条路段长度的比例。如图5所示,每条轨迹对应了一个出发地和一个目的地。以轨迹t1为例,其出发地被映射到路段<v12,v13>上,而且相对偏移量计算为
如图6的示例所示,左子图展示了一个包含7个节点和8条边的路网图以及两条历史轨迹,右子图展示了改造后的路网:先将原路网的路段记为节点,然后将路段在原路网中的前后相连关系记为边,最后根据历史轨迹统计同时经过两条相邻路段的次数记为边的权重。在该示例中,改造后的路网有一条边<v46,v63>及其权重2,这是因为原路网中有路段<v4,v6>和<v6,v3>,而且两条历史轨迹都同时经过这两条路段。最后,本申请针对改造后的路网使用图嵌入技术“node2vec”得到每条路段的表示后初始化矩阵ws的参数。同理,时间片编码子模块也包含了一个转换矩阵wt,然后通过公式
如图7的示例所示,该图包含了2016个点和7×288+2016=4032条边,其中7×288=2016条边表示的是相邻两天的同一时间的连接边,另外的2016条边表示的是相邻时间片的边。最后,本申请针对时间片连接图使用了图嵌入技术“node2vec”得到每个时间片的表示后初始化矩阵wt的参数。第三,本申请设计了外部信息编码模块用于将外部特征(如天气和交通状态)编码成一个定长向量。具体来说,本申请考虑了天气和交通状态两种外部信息。首先,天气根据类型(例如:晴天、阴天等)可以表示为独热编码owea。然后,交通状态可以使用一个区域内的平均速度来表示。本申请将整座城市划分成200m×200m的不相交区域,每个区域在每个时间片计算平均速度作为交通状态,然后选择离出发时间最近的时间片对应的交通状态并使用一层卷积神经网络进行编码得到定长向量编码dtraf。最后,拼接上述两个编码owea和dtraf并使用两层全连接神经网络得到最终的外部信息编码ocode,其公式如下:
在上述步骤s303中,本申请在时间预测模块me中使用了多层感知器模型mlp2将步骤s302编码得到的向量code进一步编码成预测的通勤时间。本申请在此处使用的多层感知器模型是一个两层全连接神经网络模型,其编码公式如下:
在上述步骤s304中,本申请在设计了轨迹编码模块用于将历史轨迹编码成定长向量表示。第一,原始轨迹由gps三维点构成,本申请使用了现有的地图匹配工具“valhalla”将轨迹映射到路网上,在空间上由路网的路段序列来表示。如图5的例子所示,该例子显示了3条轨迹被映射到路网上后的情况。
其中,轨迹t1对应映射后的路段序列为:
[<v12,v13>→<v13,v9>→<v9,v10>→<v10,v14>];
轨迹t2对应映射后的路段序列为:
[<v12,v5>→<v5,v9>→<v9,v6>→<v6,v7>→<v7,v2>→<v2,v1>];
轨迹t3对应映射后的路段序列为:
[<v2,v3>→<v3,v4>→<v4,v11>→<v11,v14>→<v14,v13>]。
此外,每条轨迹首尾点在路段上的相对偏移量也被记录下来。第二,针对路段序列中的每个路段,本申请使用了差值技术计算得出每条路段对应的时间区间,然后再设计时间区间编码模块将每个时间区间编码成定长向量表示。
如图8所示,一个时间区间指的是两个首尾时间点之间的所有时间片序列,其表示为[tp[1],tp[1]+1,...,tp[-1]],其中首尾点经过映射后对应的时间片分别为tp[1]和tp[-1],此外还需要记录首尾点在时间片上的相对偏移量tr[1]和tr[-1]。接着,该时间片序列对应到时间片的独热编码序列
在上述步骤s305中,本申请利用如下所示的算法训练s302-s304步骤中设计的模型。
模型学习算法:
输入:路网图g=<v,e>,时间片大小δt,训练集输入x,训练集输出y,轨迹编码模块mt,od时空输入编码模块mo,时间预测模块me,学习率lr,训练轮数i,批量大小bs,附件损失函数的权重w。
输出:路段编码和时间片编码矩阵ws和wt,模块mo、mt和me中的其他参数θo、θt和θe。
(1)初始化路段编码矩阵ws:ws0=node2vec(g);
(2)利用δt构造时间片连接图g’=<v‘,e’>;
(3)初始化时间片编码矩阵wt:wt0=node2vec(g′);
(4)利用标准正态分布初始化模型mo、mt和me中的其他参数θo、θt和θe;
(5)循环执行下面的调用命令i轮
·modeltrain(x,y,mo,mt,me,lr,bs,w);
(6)返回模型的参数ws、wt、θo、θt和θe。
modeltrain函数:
输入:x,y,mo,mt,me,lr,bs,w
(1)计算需要迭代训练的次数:i‘=|x|/bs;
(2)将x,y中数据的顺序进行洗牌,增加随机性,降低数据的排序对预测的影响
(3)从x,y中顺序抽取bs个数据:x[(i-1)*bs:i*bs],y[(i-1)*bs:i*bs]
(4)将x看成出发地、目的地、出发时间、外部信息特征以及轨迹数据的集合:[(g[1],g[-1],t,f,t)]=x[(i-1)*bs:i*bs];
(5)从y中抽出真实的通勤时间集合:[y]=y[(i-1)*bs:i*bs];
(6)利用模块mo编码od输入得到编码集合:
[code]=mo([(g[1],g[-1],t,f)]);
(7)利用模块mt编码轨迹输入得到编码集合:[stcode]=mt([t]);
(8)利用模块me编码[code]得到预测的结果:
(9)利用欧氏距离计算code编码和stcode编码之间的差异,该差异记为额外损失函数auxiliaryloss:
(10)利用绝对值平均误差计算预测结果和真实结果的差异,该差异记为主要损失函数mainloss:
(11)计算整体的损失函数:loss=w×auxiliaryloss+(1-w)×mainloss;
(12)利用adam优化器最小化loss,得到模型参数的更新值δθ:
δθ=adamopt([ws,wt,θo,θt,θe],loss,lr;
(13)利用δθ更新模型的所有参数;
(14)重复上述(3)到(13)步i‘次。
图9为本申请实施例所提供的轨迹编码模块结构图。
在本申请的一个实施例中,轨迹编码模块将轨迹数据看成路段和时间区间的序列。其中,首先利用现有的地图匹配算法将轨迹匹配到路段上,从而使得轨迹在空间上被表示为路段的序列;然后利用差值的算法计算匹配后的每条路段在该轨迹上对应的时间区间,即经过路段首尾点的时间,从而使得轨迹在时间上被表示为时间区间的序列。
具体地,轨迹编码模块包含一个时间区间编码子模块,该子模块首先将时间区间转化为时间片序列以及首位时间戳在时间片上的偏移;然后利用od输入编码模块中的时间片编码模型将此处的时间片序列转换为向量表示序列;进而将得到的向量表示序列看成矩阵并利用深度卷积网络编码得到时间片序列的定长向量表示;接着通过拼接该定长向量和首尾时戳在时间片上的偏移得到新的向量;最后通过一个两层全连接网络将新向量转化为为最终的时间区间定长向量表示。
具体地,轨迹编码模块利用时间区间编码子模块将时间区间序列编码为定长向量表示序列;利用od输入编码模块中的路段编码模型将路段序列编码为定长向量表示序列;将上述两个序列中的元素一一拼接得到新的序列;利用深度序列编码模型将该新序列编码为隐向量表示;将该隐向量与轨迹的首尾点在路段上的偏移量拼接起来得到新的向量;最后使用一个两层全连接神经网络将该新向量编码为最终的轨迹定长向量。
图10为本申请实施例的通勤时间模型进行预测的流程图,包括以下步骤:
s401:给定od时空输入,即出发地、目的地、出发时间和外部信息,该模型利用路网匹配和时间片匹配技术将出发地、目的地和出发时间分别进行预处理,从而将出发地和目的地表示成路段以及在路段上的相对偏移量,同时将出发时间表示成时间片以及在时间片上的相对偏移量;
s402:利用本申请训练好的od时空输入编码模块将s201得到的预处理后的时空数据以及外部信息数据编码成定长的向量;
s403:利用本申请训练好的时间预测模块从s202编码的定长向量得到预测的结果。
为了实现上述实施例,本申请还提出一种通勤时间预测装置。
图11为本申请实施例所提供的一种通勤时间预测装置的结构示意图。
如图11所示,该装置包括接收模块1101、第一处理模块1102、第二处理模块1103、编码模块1104和预测模块1105。
接收模块1101,用于接收出发地、目的地和出发时间;
第一处理模块1102,用于将出发地和目的地映射到路网上,得到路网路段序号和路段偏移量;
第二处理模块1103,第二处理模块,用于将出发时间映射到时间片上,得到时间片序号和时间片偏移量;
编码模块1104,用于根据时空输入编码模块对路网路段序号、路段偏移量、时间片序号和时间片偏移量进行编码得到定长向量;
预测模块1105,用于根据时间预测模块对定长向量进行处理,输出目标通勤时间。
需要说明的是,前述对方法实施例的解释说明也适用于该实施例的装置,此处不再赘述。
本申请实施例的通勤时间预测装置中,根据预设时空输入编码模块对出发地和目的地进行处理,得到路网路段序号和路段偏移量;根据时空输入编码模块对出发时间映射进行处理,得到时间片序号和时间片偏移量;根据预设轨迹编码模块对路网路段序号、路段偏移量、时间片序号和时间片偏移量进行编码得到定长向量;根据预设时间预测模块对定长向量进行处理,输出目标通勤时间。由此,提高出发地到目的地通勤时间预测的准确性。
图12为本申请实施例所提供的一种通勤时间预测模型的训练装置的结构示意图。
如图12所示,该装置包括:获取模块1201、编码模块1202、第一训练模块1203、第二训练模块1204和第三训练模块1205。
获取模块1201,用于获取历史轨迹数据样本,对历史轨迹数据样本进行分析,获取出发地样本、目的样本、出发时间样本、外部信息样本和通勤时间样本;
编码模块1202,用于通过地图匹配技术将出发地样本和目的样本对应的空间点映射到路段上,然后使用路段序号以及映射点的路段偏移量,将出发时间样本对应的时间戳映射到时间片上,然后使用时间片序号以及映射后的时间偏移量,对外部信息样本进行编码生成外部特征编码;
第一训练模块1203,用于根据出发地样本、目的地样本、出发时间样本和外部信息样本对应的编码对时空输入编码模块进行训练;
第二训练模块1204,用于将出发地样本、目的地样本、出发时间样本和外部信息样本对应的编码拼接起来,并利用一个两层的全连接神经网络编码为定长向量,根据定长向量对轨迹编码模块进行训练;
第三训练模块1205,用于根据定长向量和通勤时间样本对时间预测模块进行训练。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本申请的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本申请的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本申请的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本申请的限制,本领域的普通技术人员在本申请的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!