一种无功日曲线不良数据识别与修正方法与流程
本发明涉及电力调度自动化技术领域,尤其是指一种无功日曲线不良数据识别与修正方法。
背景技术:
近半个世纪以来,以数字化为特征的计算机和通信技术逐渐在电力系统中得到了普及应用,使得电力系统调度控制的面貌发生了深刻的变革。在高度自动化的电力系统中,电气量和其它各种数据的准确采集与传输是电力系统继电保护和调度决策的基础。
随着电力工业的发展,现代电力系统已由最初围绕电厂展开发展到目前的大电网、大机组、超高压时代。这一新型的、开放发展阶段对支撑电力系统安全经济运行的监视、调度、运行控制和管理决策系统提出了新的挑战,既要求其提供对大型互联电力系统进行灵活、安全、经济和快速的调度控制的能力,又要能及时灵活地为参与电力市场运营的各公司和部门提供涉及电力系统实际运行状态、安全状况及安全裕度、电能报价和电量交易情况、以及日常运行管理情况等各个方面的丰富的数据和信息。为了提高驾驭复杂电网的能力,电力系统的自动化程度不断提高。在电网保护与控制高度自动化的环境下,一旦变电站自动化系统或调度自动化系统接收的数据出错,小则干扰调度员的判断,大则影响调度员做出错误的控制决策,甚至导致保护和控制装置误动,严重影响电网安全。如何从海量的测量和运行数据中准确、快速地辨识出不良数据,已经成为保障电力系统安全的关键问题之一。
电力系统异常数据辨识一直是电力系统分析中的一个难点,复杂的电力网络包含有海量的数据,这些数据的准确与否决定着电力系统运行的安全与可靠性。电力系统中的不良数据可能会影响调度员做出错误的决策,从而影响电力系统的正常运行,甚至可能会威胁整个电力系统的安全。因此,为了确保电力系统稳定安全的运行,检测这些不良数据并把它们从原始数据中提取出来加以修正有着重要意义。
针对这些问题,电力科研人员进行了大量的研究,提出了不少行之有效的措施和方法,如基于网络潮流约束冗余性的状态估计方法和基于时间序列分析的异常数据辨识方法,但仅针对有功功率的不良数据识别。但尚无有关无功日曲线不良数据的识别及修正。随着近几年风、光等新能源发电的大量投产并网及电网交直流互联,无功补偿和电压问题较为突出。由于变电站内高压侧和低压侧的有功、无功和电压之间的耦合关系,如果在日计划编制时,未考虑无功补偿问题,将可能产生某些负荷节点电压越限,影响电网实时调度运行安全。因此,迫切需要在日前发电计划编制时,采用电网交流潮流闭环安全校核,在校验支路有功限值的同时,对电网节点的无功缺额和电压越限问题进行全面的校核,即无功数据的不良数据辨识及修正,并为调度部门提供闭环的校正辅助服务策略,全面提高日前发电计划和电网运行的安全稳定水平。
现有的交流潮流安全校核只能进行线路有功潮流计算和越限校验,无法进行无功和电压校验,难以满足当前调度安全校核的需求。已有研究(陈波,李保全,李亚红,刘配配,刘媛媛.电压无功控制中的不良数据辨识.武汉大学学报,2010)根据无功负荷曲线相似性和平滑性的两个重要特征,采用改进的BP神经网络模型,通过对影响无功负荷的主要因素进行离线训练,实现对无功负荷曲线拟合,进而实现对无功负荷的预测。然而该方法仅对无功不良数据进行辨识,并无数据修正方法,难以满足交流潮流闭环安全校核的日前发电计划。
此外,随着大量高压直流输电线路接入电网,直流换流站对近区母线电压幅值非常敏感,而直流近区波动需要大量的无功吞吐。随着直流线路的不断增多,迫切需要考虑交流潮流闭环安全校核的日前发电计划,在精细化考虑电网安全约束的基础上,实现有功、无功、电压的协调统筹优化,进而实现对交直流电网潮流的精确把控。
技术实现要素:
为了解决上述技术问题,本发明提供一种无功日曲线不良数据识别与修正方法。
本发明是以如下技术方案实现的:
第一方面,一种无功日曲线不良数据识别方法,包括:
获取待处理数据集;所述待处理数据集包括无功日曲线数据;
获取参考数据以及偏差限;
根据所述参考数据对所述待处理数据集进行粗识别以获取第一不良数据;
去除所述第一不良数据以得到第一预处理数据集;
根据所述参考数据和所述偏差限对所述第一预处理数据集进行精细识别以获取第二不良数据;
去除所述第二不良数据以得到第二预处理数据集。
进一步地,所述获取参考数据以及偏差限包括:
求取所述参考数据的平均值,并以这个值为基准对参考数据进行标幺化处理,得到标幺化参考数据组。
进一步地,所述根据所述参考数据对所述待处理数据集进行粗识别以获取第一不良数据包括:
对所述待处理数据集中的数据进行线性变换;
将所述线性变换的结果与所述标幺化参考数据组进行线性拟合;
根据所述线性拟合的结果得出所述待处理数据集与所述标幺化参考数据组的偏差数值集;
获取所述偏差数值集的的偏差平均值;
根据所述偏差平均值计算偏差异常判断系数;
根据所述偏差平均值和所述偏差异常判断系数判断第一不良数据。
进一步地,所述根据所述参考数据和所述偏差限对所述第一预处理数据集进行精细识别以获取第二不良数据包括:
对所述第一预处理数据集进行线性变换;
将所述线性变换的结果与所述标幺化参考数据组进行线性拟合;
根据所述线性拟合的结果得出所述第一预处理数据集与所述标幺化参考数据组的偏差数值集;
根据所述偏差限和所述偏差数据集判断第二不良数据。
进一步地,所述去除所述第二不良数据以得到第二预处理数据集之后,还包括:
对所述第二预处理数据集进行连续性识别以获取第三不良数据。
进一步地,还包括:
对第一不良数据、第二不良数据和/或第三不良数据进行修正以得到修正后的修正数据。
进一步地,在所述对第一不良数据、第二不良数据和第三不良数据进行修正之后还包括:
获取有功功率数据;
根据所述有功功率数据和所述修正数据计算功率因数;
判断所述功率因数是否位于预设范围之内;
若是,则判定修正数据正确;
若否,则继续对所述修正数据进行修正。
第二方面,一种无功日曲线不良数据识别装置,包括:
待处理数据集获取模块,用于获取待处理数据集;所述待处理数据集包括无功日曲线数据;
参考获取模块,用于获取参考数据以及偏差限;
粗识别模块,用于根据所述参考数据对所述待处理数据集进行粗识别以获取第一不良数据;
第一预处理模块,用于去除所述第一不良数据以得到第一预处理数据集;
精细识别模块,用于根据所述参考数据和所述偏差限对所述第一预处理数据集进行精细识别以获取第二不良数据;
第二预处理模块,用于去除所述第二不良数据以得到第二预处理数据集。
进一步地,还包括:
标幺模块,用于求取所述参考数据的平均值,并以这个值为基准对参考数据进行标幺化处理,得到标幺化参考数据组。
进一步地,还包括:
连续性识别模块,用于对所述第二预处理数据集进行连续性识别以获取第三不良数据;
修正模块,用于对第一不良数据、第二不良数据和/或第三不良数据进行修正以得到修正后的修正数据。
本发明的有益效果是:
本发明提供了一种无功日曲线不良数据识别与修正方法以及其相应地装置,能够在日前发电计划编制中精细化考虑无功潮流对电网的影响,在校验支路有功限值的同时,对电网节点的无功缺额问题进行全面的校核,为实现电网交流潮流闭环安全校核的目标提供坚实的基础。
本发明基于特征提取的方法,对无功不良数据进行辨识,将所获取的不良数据进行修正,输出结果作为电网无功功率的预测值,可应用于日前计划制定和方式安排。本发明提出的无功不良数据识别及修正方法,不仅能够准确的预测电网的无功功率,有效满足实际调度工作的需求,还可实现对交直流电网潮流的精确把控。
本发明具有计算高效准确、预测精度高度的特点,能够为未来交易安全校核奠定坚实基础,具有重大的经济和社会效益,为电网公司获得考虑无功交流潮流的日前发电计划提供依据,合理控制和经济调度电网发电资源,同时满足电网安全和潮流优化的实际需求,达到资源优化配置和节能减排的目标。
附图说明
图1是本发明一种无功日曲线不良数据识别方法流程图;
图2是本发明第一不良数据获取方法流程图;
图3是本发明第二不良数据获取方法流程图;
图4是本发明修正方法流程图;
图5是本发明一种无功日曲线不良数据识别装置框图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合附图及实施方式对本发明作进一步详细的说明。应当理解,此处所描述的具体实施方式可用以解释本发明,但并不限定本发明。
本发明提供的一种无功日曲线不良数据识别与修正方法以及其相应地装置可以应用于电网无功功率不良数据辨识与修正。无功不良数据辨识与修正是指对电力系统调度中心接受到的前日母线负荷96点无功数据进行不良数据辨识,先进行粗辨识,将识别出的不良数据剔除,在此基础上对正确数据进行精细辨识,将识别出的不良数据剔除,对正确数据进行扫尾辨识,将所判断出的不良数据进行修正,同时引入正确的有功功率数据,判断电网的功率因数是否符合要求,通过电网功率因数对无功修正结果进行验证,最终的修正结果作为日前发电计划的母线负荷无功预测数据。
如图1所示,本发明是以如下技术方案实现的,一种无功日曲线不良数据识别方法,具体包括下述步骤:
S101.获取待处理数据集;所述待处理数据集包括无功日曲线数据。
所述待处理数据集由无功日曲线数据构成,所述无功日曲线数据即无功功率数据,具体是指前日电网母线负荷96点无功数据。
S102.获取参考数据以及偏差限。
所述参考数据组是指母线负荷96点无功预测值,对引入的参考数据组将取其平均值,并以平均值为基准,对参考数据组进行标幺化处理,得到标幺化参考数据组。
S103.根据所述参考数据对所述待处理数据集进行粗识别以获取第一不良数据。
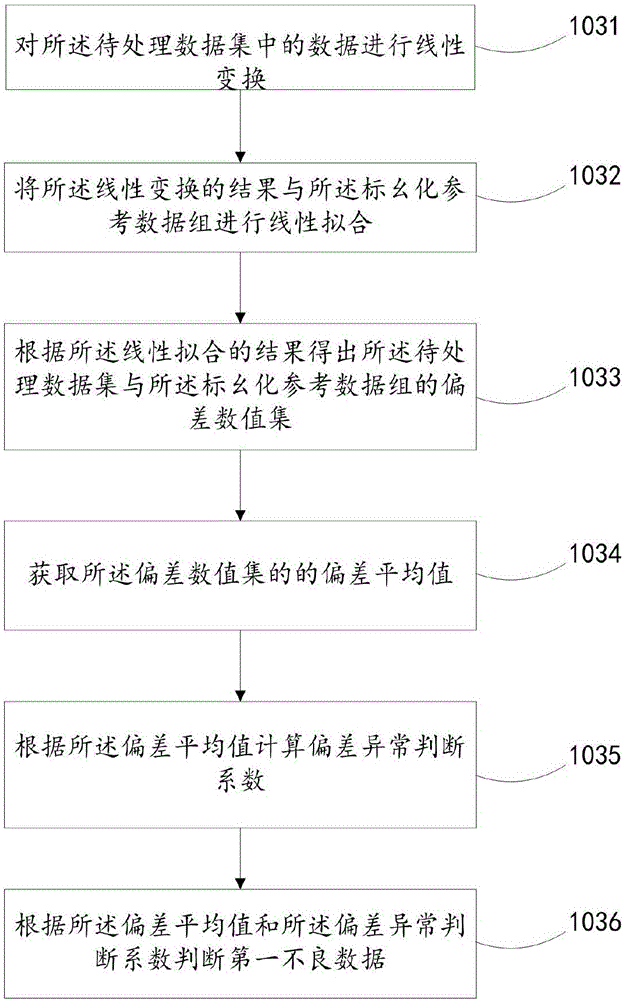
具体地,如图2所示,S103包括:
S1031.对所述待处理数据集中的数据进行线性变换。
以待处理数据集中的无功功率数据为例,线性变换表达式为xi'=axi+b,其中,式中xi为无功数据组,xi'为S1031中线性变换结果。y′i为标幺化参考数据组,Δ=nsxx-(sx)2。
S1032.将所述线性变换的结果与所述标幺化参考数据组进行线性拟合。
S1033.根据所述线性拟合的结果得出所述待处理数据集与所述标幺化参考数据组的偏差数值集。
S1034.获取所述偏差数值集的的偏差平均值。
将所述线性变换的结果与所述标幺化参考数据组进行线性拟合,得出偏差数值集z′i=|x′i-y′i|,对所有偏差值进行平均,得到偏差平均值
S1035.根据所述偏差平均值计算偏差异常判断系数。
S1036.根据所述偏差平均值和所述偏差异常判断系数判断第一不良数据。
确定偏差异常判断系数k,k值相对z′递减变化,并确定k的上下限,式中c为k值上限,a为对应的偏差限,d为k值下限,b为对应的偏差限。
进一步地,设定一组布尔型变量pi作为数据错误的标识;当z′i≤kz′时,pi=1表示该点为正确数据;当z′i>kz′时,pi=0表示该点为不良数据。
S104.去除所述第一不良数据以得到第一预处理数据集。
所述第一预处理数据集为剔除粗辨识判断出的不良数据后的数据集。
S105.根据所述参考数据和所述偏差限对所述第一预处理数据集进行精细识别以获取第二不良数据。
对第一预处理数据集中的数据进行线性变换,并与标幺化参考数据组线性拟合,得出两组数据的所有点的偏差数值zi,根据输入的偏差限z,当某个点偏差值小于偏差限z时,该点的数据为正确数据,否则为不良数据;具体为如图3所示,包括:
S1051.对所述第一预处理数据集进行线性变换。
线性变换表达式为x″i=a′xi+b′,其中,式中xi为第一预处理数据集中的数据,y′i为标幺化参考数据组,
S1052.将所述线性变换的结果与所述标幺化参考数据组进行线性拟合。
S1053.根据所述线性拟合的结果得出所述第一预处理数据集与所述标幺化参考数据组的偏差数值集。
将所述线性变换的结果与所述标幺化参考数据组进行线性拟合,得出偏差数值集zi=x″i-y′i。
S1054.根据所述偏差限和所述偏差数据集判断第二不良数据。
根据输入的偏差限z:当|zi|<z时,使pi=1,该点为正确数据;当|zi|>z时,使pi=0,该点为不良数据。
S106.去除所述第二不良数据以得到第二预处理数据集。
所述第一预处理数据集与第二预处理数据集均与所述待处理数据集中的数据数量一致,所述第一预处理数据集中第一不良数据的pi为0,其它数据的pi为1;所述第二预处理数据集第一不良数据和第二不良数据的pi为0,其它数据的pi为1。
进一步地,还包括:
S107.对所述第二预处理数据集进行连续性识别以获取第三不良数据。
对辨识出的第二预处理数据集进行扫尾辨识,即若该点与相邻的数据连续性良好,则该点为正确数据,若连续性较差,则归为第三不良数据。
以i=96k(k为自然数)开始,向两端寻找pi=0的点,如出现pi=1则停止。设所寻找到的数据为m个:
(1)如m小于l,则认为没有扫尾现象;
(2)如m大于L,则认为过多坏数据,也不判断扫尾现象,按照没有扫尾现象处理;
(3)如m不小于l且不大于L,则取这m个数据及其两端各多取一个数据,形成m+2个数据,表示为um+2设另一数组vm+1,使vi=ui+1-ui,令如则认为这些数据基本不连续,没有产生扫尾现象,否则,认为这些数据基本联系,产生了扫尾现象。
如产生扫尾现象,则认为数据不需要修正,直接让这部分数据对应的pi=1即可;如没有产生扫尾现象,则为第三不良数据。
实施例2:
本实施例中,进一步地,还可以对第一不良数据、第二不良数据和第三不良数据进行修正以得到修正后的修正数据,如图4所示,所述修正方法包括:
S1.得到不良数据对应的zi,所述zi为待处理数据集进行线性变换x′i=axi+b后,再与标幺化参考数据组进行线性拟合得到的偏差值。
S2.得到不良数据的修正数据。
修正不良数据对应的zi,使zi等于与之最近的两个正确数据对应的zi的平均值。针对每个不良数据,分别向其两端寻找最近的两个正确数据,并对这两个正确数据对应的zi进行线性差值,使这些不良数据对应zi等于所述线性插值的结果。根据下式修正好的zi计算出修正数据xi:
x′i=y′i+zi;
S3.引入有功历史数据样本pi,功率因数上阈值及下阈值计算功率因数。
电网某点的功率因数表达式为
式中,为电网某点的功率因数,pi为该点的有功历史数据,xi为该点修正后的无功历史数据。
S4.通过判断电网功率因数是否符合要求,检验修正数据。
若修正数据对应的功率因数落在阈值内,即则修正数据修正成功;若修正数据对应的功率因数落在阈值外,则修正数据仍然属于不良数据,需要继续进行修正。
具体为:
引入一组反馈调整系数组Δxi,令功率因数基准值为功率因数为时对应的无功值为由可得:
综上所述及式(11),可得最终的修正方程为:
实施例3:
一种无功日曲线不良数据识别装置,如图5所示,包括:
待处理数据集获取模块301,用于获取待处理数据集;所述待处理数据集包括无功日曲线数据;
参考获取模块302,用于获取参考数据以及偏差限;
粗识别模块303,用于根据所述参考数据对所述待处理数据集进行粗识别以获取第一不良数据;
第一预处理模块304,用于去除所述第一不良数据以得到第一预处理数据集;
精细识别模块305,用于根据所述参考数据和所述偏差限对所述第一预处理数据集进行精细识别以获取第二不良数据;
第二预处理模块306,用于去除所述第二不良数据以得到第二预处理数据集。
标幺模块307,用于求取所述参考数据的平均值,并以这个值为基准对参考数据进行标幺化处理,得到标幺化参考数据组;
连续性识别模块308,用于对所述第二预处理数据集进行连续性识别以获取第三不良数据;
修正模块309,用于对第一不良数据、第二不良数据和/或第三不良数据进行修正以得到修正后的修正数据。
由以上具体实施例可见,本发明提出的一种无功日曲线不良数据识别与修正方法以及其相应地装置,可对电网节点的无功缺额问题进行全面的校核,为实现电网交流潮流闭环安全校核提供重要的依据。按照本发明所提供的方法,电网公司可根据获得的无功历史数据,准确的预测未来的无功数据,合理控制和经济调度电网发电资源,同时满足电网安全和潮流优化的实际需求,达到资源优化配置和节能减排的目标。说明本发明能够满足电网公司的实际需要,具有重要的现实意义和良好的应用前景。
此外,本发明所提出的实施步骤中为调度计划专责和调度员提前了解次日电网的运行状态提供了可靠的计算结果,方便调度员提前预知电网的潜在危险,采取安全预控措施消除风险,极大的提高了电网的安全稳定运行水平和调度管理工作的精益化水平。
以上所揭露的仅为本发明较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!