基于全局在线启发式动态规划永磁同步电机矢量控制方法与流程
本发明涉及到永磁同步电机智能控制技术领域,具体涉及到一种基于全局在线启发式动态规划永磁同步电机矢量控制方法。
背景技术:
永磁同步电机(PMSM)具有功率密度高、结构简单、体积小、可靠性强等优点,被广泛的应用于数控机床、航空航天和机器人的机械手控制等领域。永磁同步电机自身也是一个强耦合、非线性的控制系统,存在参数变化和外部扰动的问题。因此,针对永磁同步电机的可靠控制方法一直是国内外研究重点。近几年出现了很多针对永磁同步电机的非线性控制方法,国外的S.Barkat学者(S.Barkat,A.and H.Nouri,“Noninteracting Adaptive Control of PMSM Using Interval Type-2Fuzzy Logic Systems,”IEEE Trans.Fuzzy Syst.,vol.19,no.5,pp.925-936,Oct.2011.)将模糊控制方法应用于永磁同步电机的控制。但是模糊控制方法的隶属函数需要人为的经验设置,在实际应用中使用较为困难。在PMSM高速长时间运行时,电机参数(如:交直轴电感,电阻,永磁体磁链等参数)变化很大,传统的PI、模糊、滑模等控制方法对电机参数的依赖性较强,当参数变化时,会影响其控制效果。
单神经元PI控制方法,相对于传统的控制方法可以在线的整定比例、积分参数,近几年受到国外学者的广泛关注,加拿大的C.B.Butt博士(C.B.Butt and M.A.Rahman,“Intelligent Speed Control of Interior Permanent Magnet Motor Drives Using a Single Untrained Artificial Neuron,”IEEE Trans.Ind.Appl.,vol.49,no.4,pp.1836-1843,Jul.2013.)将单神经元PI用于内嵌式永磁同步电机(IPMSM)的速度控制,并取得了较好的控制效果。但是,单神经元PI算法虽然可以在线的实时整定比例、积分参数,其折扣因子K,需要经验来设置,设置过大,会引起系统震荡,设置过小,又会导致系统响应过慢。
传统滑模变结构控制(SMC)方法,其滑动模态可以进行设计且与对象参数及扰动无关,这就使得SMC控制具有快速响应、对应参数变化及扰动不灵敏、无需系统在线辨识、物理实现简单等优点。但是传统SMC控制在进入滑模面后,会存在“抖振”现象,将其用于永磁同步电机矢量控制系统电流内环,容易引起永磁同步电机转矩脉动。
技术实现要素:
技术问题:本发明提供一种基于全局在线启发式动态规划永磁同步电机矢量控制方法,实现了永磁同步电机矢量控制系统的智能在线控制,减小了永磁同步电机高速运行中的速度波动,同时减小了电流的抖振,抑制了系统运行的转矩脉动,增强控制系统的鲁棒性和稳定性。
技术方案:本发明的基于全局在线启发式动态规划永磁同步电机矢量控制方法,包括以下步骤:
步骤1:初始化单神经元全局在线启发式动态规划算法的目标网络学习率、评价网络学习率、单神经元PI算法参数,根据系统的跟踪误差,设计外部强化学习信号;
步骤2:通过神经网络正向传输,计算评价网络的输出和目标网络的输出,所述评价网络的输出为性能指标函数J(t),所述目标网络的输出为内部强化学习信号S(t),其中t表示当前时刻;
步骤3:计算目标网络误差和评价网络误差,通过计算出的误差分别对目标网络和评价网络的权值进行在线调整;
步骤4:通过求解最优性能指标函数,得到单神经元PI算法K值,通过得到的K值调节单神经元PI控制算法的输出,即永磁同步电机系统q轴电流的参考值iq*;
步骤5:矢量控制系统中的d轴电流内环采用改变趋近率的滑模变结构控制器,通过d轴给定参考值id*=0和实际电流id的差,来调节d轴电压ud;
矢量控制系统中的q轴电流内环采用改变趋近率的滑模变结构控制器,通过步骤4得到的q轴电流的参考值iq*和实际电流iq的差,来调节q轴电压uq。
进一步的,本发明方法中,所述步骤1中按照下式设计外部强化学习信号r(t):
r(f)=0.98*e(t)+0.02*e(t-1),e(t)=ω*(t)-ω(t)
其中,t表示当前时刻,t-1表示上一时刻,ω*(t)为目标转速,ω(t)为实际转速,e(t)为当前时刻转速差,e(t-1)为上一时刻转速差。
进一步的,本发明方法中,所述步骤2中的性能指标函数为:
其中,为评价网络激活函数,为当前时刻评价网络输入向量,ck(t)为当前时刻t的评价网络输入向量中的第k个元素,k的取值范围为1到5,t-1为上一时刻,l为评价网络隐层节点序号,l取值范围为1到Nc,Nc为评价网络隐层节点数,Nf为目标网络隐层节点数,u(t)为当前时刻t的控制量,u(t-1)为上一时刻控制量,e(t)为当前时刻t的系统误差,e(t-1)为上一时刻系统误差,S(t)为当前时刻t的内部强化学习信号,为当前时刻t的评价网络输入层到隐层权值矩阵第l行,第k列元素,zl(t)为当前时刻t的评价网络隐层输出向量的第l个元素,为当前时刻t的评价网络隐层到输出层的权值矩阵第l个元素,J(t)为当前时刻t的性能指标函数。
进一步的,本发明方法中,所述步骤2中的内部强化学习信号S(t)为:
其中,为目标网络的激活函数,aj(t)为当前时刻t的目标网络输入向量中的第j个元素,j的取值范围为1到4,t表示当前时刻,t-1表示上一时刻,i的取值范围为1到Nf,Nf为目标网络隐层节点数,i为目标网络隐层节点序号,u(t)为当前时刻t的控制量,u(t-1)为上一时刻控制量,e(t)为当前时刻t的系统误差,e(t-1)为上一时刻系统误差,为当前时刻t的目标网络输入层到隐层的权值矩阵第i行,第j列元素,qi(t)为当前时刻t的目标网络隐层输出向量的第i个元素,为当前时刻t的目标网络隐层到输出层权值矩阵第i个元素,S(t)为当前时刻t的内部强化学习信号。
进一步的,本发明方法中,所述步骤3中根据下式计算目标网络误差:
ef(t)=αS(t)-[S(t-1)-r(t-1)]
其中,α为目标网络折扣因子,其取值范围为0<α<1,S(t)为t时刻的内部强化学习信号,S(t-1)为上一时刻的内部强化学习信号,r(t-1)为上一时刻的外部强化学习信号,ef(t)为当前时刻t的目标网络误差。
进一步的,本发明方法中,所述步骤3中根据下式计算评价网络误差:
ec(t)=γJ(t)-[J(t-1)-S(t)]
其中,γ为评价网络折扣因子,其取值范围为0<γ<1,J(t)为当前时刻t的性能指标,J(t-1)为上一时刻性能指标,S(t)为当前时刻t的内部强化学习信号,ec(t)为当前时刻t的评价网络误差。
进一步的,本发明方法中,所述步骤3中根据以下调整规则对目标网络的权值进行在线调整:
隐层到输出层:
其中,
输入层到隐层:
其中,
其中,aj(t)为当前时刻t的目标网络输入向量中的第j个元素,lf(t)是当前时刻t的目标网络学习率,ef(t)为当前时刻t的目标网络误差,Ef(t)是当前时刻t的目标网络误差的平方,为当前时刻t的目标网络隐层到输出层权值矩阵第i个元素的增量,为当前时刻t的目标网络输入层到隐层权值矩阵第i行,第j列元素的增量,为目标网络的激活函数,qi(t)为当前时刻t的目标网络隐层输出向量的第i个元素,S(t)为当前时刻t的内部强化学习信号,为当前时刻t的目标网络输入层到隐层的权值矩阵第i行,第j列元素,为当前时刻t的目标网络隐层到输出层权值矩阵第i个元素,α为目标网络折扣因子。
进一步的,本发明方法中,所述步骤3中根据以下调整规则对评价网络的权值进行在线调整:
隐层到输出层:
其中,
输入层到隐层:
其中,
其中,ck(t)为当前时刻t的评价网络输入向量中的第k个元素,lc(t)为当前时刻t的评价网络学习率,ec(t)为当前时刻t的评价网络误差,Ec(t)为当前时刻t的评价网络误差的平方,为当前时刻t的评价网络隐层到输出层权值矩阵第l个元素的增量,为当前时刻t的评价网络输入层到隐层权值矩阵第l行,第k列元素的增量,为目标网络的激活函数,qi(t)为当前时刻t的目标网络隐层输出向量的第i个元素,为评价网络的激活函数,zl(t)为当前时刻t的目标网络隐层输出向量的第l个元素,J(t)为当前时刻t的性能指标,为当前时刻t的目标网络输入层到隐层的权值矩阵第i行,第j列元素,为当前时刻t的目标网络隐层到输出层权值矩阵第i个元素,γ为评价网络折扣因子。
进一步的,本发明方法中,所述步骤4中按照如下方法求解最优性能指标函数:
其中,
K(t)=K(t-1)+ΔK(t)
其中,la(t)为当前时刻t的单神经元PI折扣因子学习率,ea(t)为当前时刻t的单神经元PI折扣因子学习反传误差,Ea(t)为当前时刻t的单神经元PI折扣因子学习反传误差的平方,ΔK(t)为当前时刻t的K值增量,Δu(t)为当前时刻t的控制信号的增量,u(t)为当前时刻t的控制信号,为当前时刻t的目标网络输入层到隐层权值矩阵第i行,第3列元素,为当前时刻t的评价网络输入层到隐层权值矩阵第l行,第4列元素,为当前时刻t的评价网络输入层到隐层权值矩阵第l行,第1列元素,为目标网络的激活函数,qi(t)为当前时刻t的目标网络隐层输出向量的第i个元素,为评价网络的激活函数,zl(t)为当前时刻t的目标网络隐层输出向量的第l个元素,J(t)为当前时刻t的性能指标,为当前时刻t的目标网络隐层到输出层权值矩阵第i个元素,为当前时刻t的评价网络隐层到输出层的权值矩阵第l个元素,S(t)为当前时刻t的内部强化学习信号,K(t-1)为上一时刻单神经元PI算法K值,K(t)为当前时刻t的K值。
本发明方法通过构建永磁同步电机id=0矢量控制系统,基于全局在线启发式动态规划算法设计近似最优性能指标函数,求解最优控制率,单神经元PI控制器的折扣因子K值,调节控制器输出永磁同步电机系统的q轴参考电流维持永磁同步电机矢量控制系统速度稳定。当电机参数改变时,全局在线启发式动态规划算法可以在线学习电机参数的变化,求解当前的最优K值,实现永磁同步电机矢量控制系统的智能在线控制,减小了永磁同步电机高速运行中的速度波动,同时联合改进趋近率的SMC电流内环控制器,减小了电流的抖振,抑制了系统运行的转矩脉动,增强控制系统的鲁棒性和稳定性。
有益效果:本发明与现有技术相比,具有以下优点:
传统的永磁同步电机矢量控制系统的电流环大多采用PI控制算法,PI控制算法实现现简单,运用广泛,但是PI控制算法存在经典控制理论的固有缺陷,对系统参数变化和外界扰动过于敏感,很难满足永磁同步电机的控制需求。滑模变结构控制(SMC)是一种特殊的非线性控制方法,具有较强的抗外界扰动能力,但是传统的滑模变结构控制存在固有的抖振问题,在提高了永磁同步电机的电流环的抗扰动能力的同时,又产生了电流抖振现象,导致了永磁同步电机的转矩脉动问题,本发明提出的永磁同步电机矢量控制系统的电流内环采用新型趋近律的SMC控制器,相对于现有的SMC控制器,该控制器可以有效地减弱永磁同步电机电流抖振现象,减弱了永磁同步电机实际运行中的转矩脉动。
传统的永磁同步电机矢量控制系统的速度环大多也采用PI控制算法,如上所述,PI控制算法对系统参数变化和外界扰动过于敏感,很难满足永磁同步电机的速度控制需求。单神经元PI控制算法可以自适应的调整比例、积分参数,将其用于永磁同步电机的速度控制,可以显著的提高永磁同步电机的速度稳定性,但是,单神经元PI算法虽然可以在线的实时整定比例、积分参数,其折扣因子K,需要经验来设置,设置过大,会引起系统震荡,设置过小,又会导致系统响应过慢。本发明将全局在线启发式动态规划算法和单神经元PI算法重新整合,提出了单神经元全局在线启发式动态规划永磁同步电机速度控制器,引入了机器学习的思想,可以使永磁同步电机速度控制器根据环境特征不断地自学习,增强永磁同步电机运行的速度稳定性和鲁棒性。
本发明提出的永磁同步电机矢量控制方法,联合改进趋近率滑模变结构电流控制器、单神经全局在线启发式动态规划算法速度控制器,显著了提高了永磁同步电机的电流响应速度、减小了永磁同步电机转矩脉动、增强了电流环抗扰动能力,增强了速度环稳定性和鲁棒性。该方法具有实现成本低、扩展性强的优点,既可以用于小功率永磁同步电机系统,例如:伺服系统、小功率医疗器械等领域,也可以用于大功率的永磁同步电机系统,例如:电动汽车电机控制、大型机械加工等领域。
附图说明
图1为永磁同步电机矢量控制系统结构示意图。
图2为单神经元全局在线启发式动态规划算法结构示意图。
图3为目标网络结构示意图。
图4为评价网络结构示意图。
图5为单神经元PI结构示意图。
图6为硬件实施结构示意图。
具体实施方式
下面详细描述本发明的实施方式,所述实施方式的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
基于全局在线启发式动态规划永磁同步电机矢量控制方法,其实施具体包括以下步骤:
步骤1:初始化单神经元全局在线启发式动态规划算法的目标网络学习率、评价网络学习率、单神经元PI算法参数,根据系统的跟踪误差,设计外部强化学习信号;
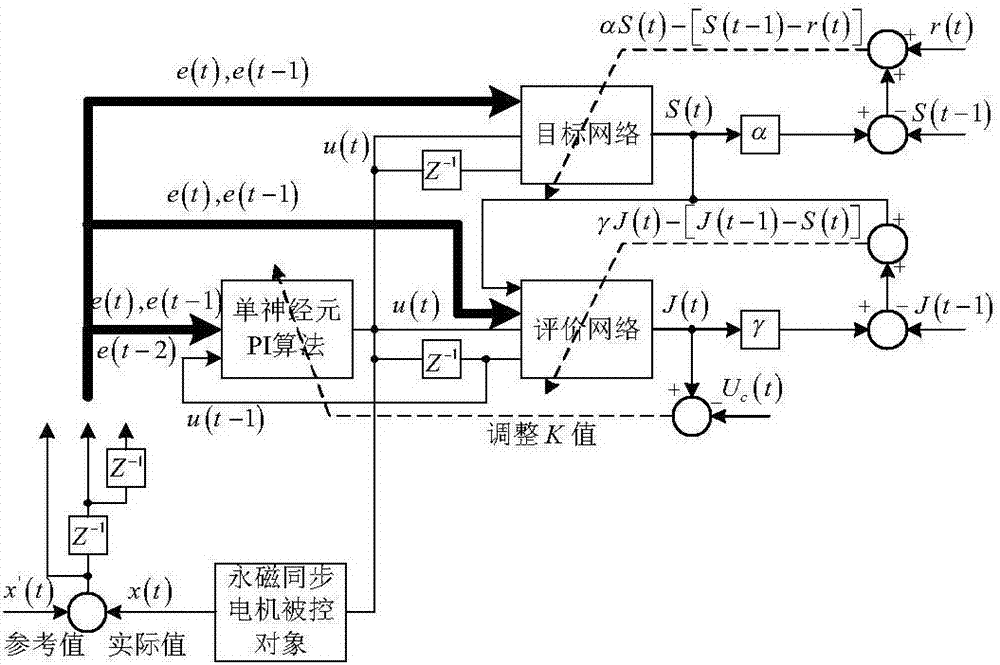
构建永磁同步电机矢量控制系统。图1为永磁同步电机矢量控制系统结构示意图,包括三相全桥电压源型逆变器、编码器采集模块、SVPWM算法模块、Park变换模块、Clark变换模块和逆Park变换模块、两个电流内环SMC控制器、和一个速度外环SAN-GRHDP控制器。首先建立系统的整体硬件平台,具体实施如图6所示,永磁同步电机、三相全桥电压源型逆变器、编码器及其采集电路、整流电路、PC电脑、DSP28335等都为外部硬件结构,SVPWM算法模块、Park变换模块、Clark变换模块和逆Park变换模块、两个电流内环SMC控制器、和一个速度外环SAN-GRHDP控制器这些属于软件部分,均采用TI公司的DSP28335进行实现。初始化SAN-GRHDP算法的目标网络学习率、评价网络学习率、单神经元PI算法等参数如表1所示,表1为单神经元全局在线启发式动态规划算法参数设置表。
表1
SAN-GRHDP方法的参数设置
外部强化学习信号的定义如下所示:
r(t)=0.98*e(t)+0.02*e(t-1),e(t)=ω*(t)-ω(t)
其中,t表示当前时刻,t-1表示上一时刻,ω*(t)为目标转速,ω(t)为实际转速,e(t)为当前时刻转速差,e(t-1)为上一时刻转速差。
步骤2:通过神经网络正向传输,计算评价网络的输出和目标网络的输出,所述评价网络的输出为性能指标函数J(t),所述目标网络的输出为内部强化学习信号S(t);
目标网络正向计算过程具体实施如图3所示:其中a(t)=[e(t),e(t-1),u(t),u(t-1)]T为输入向量。
正向计算隐层节点输出:
正向计算输出层:
为目标网络隐层激活函数。
aj(t)为当前时刻t的目标网络输入向量中的第j个元素,当前时刻t的目标网络输入向量为a(t)=[e(t),e(t-1),u(t),u(t-1)]T,j的取值范围为1到4,t表示当前时刻,t-1表示上一时刻,i的取值范围为1到Nf,Nf为目标网络隐层节点数,i为目标网络隐层节点序号,u(t)为当前时刻t的控制量,u(t-1)为上一时刻控制量,e(t)为当前时刻t的系统误差,e(t-1)为上一时刻系统误差,为当前时刻t的目标网络输入层到隐层的权值矩阵第i行,第j列元素,qi(t)为当前时刻t的目标网络隐层输出向量的第i个元素,为当前时刻t的目标网络隐层到输出层权值矩阵第i个元素,S(t)为当前时刻t的内部强化学习信号。
评价网络正向计算过程具体实施如图4所示:其中
c(t)=[S(t),e(t),e(t-1),u(t),u(t-1)]T为输入向量。
正向计算隐层节点输出:
正向计算输出层:
为评价网络隐层激活函数。
ck(t)为当前时刻t的评价网络输入向量中的第k个元素,当前时刻t的目标网络输入向量为c(t)=[S(t),e(t),e(t-1),u(t),u(t-1)]T,k的取值范围为1到5,t-1为上一时刻,l为评价网络隐层节点序号,l取值范围为1到Mc,Nc为评价网络隐层节点数,Nf为目标网络隐层节点数,u(t)为当前时刻t的控制量,u(t-1)为上一时刻控制量,e(t)为当前时刻t的系统误差,e(f-1)为上一时刻系统误差,S(t)为当前时刻t的内部强化学习信号,为当前时刻t的评价网络输入层到隐层权值矩阵第l行,第k列元素,zl(t)为当前时刻t的评价网络隐层输出向量的第l个元素,为当前时刻t的评价网络隐层到输出层的权值矩阵第l个元素,J(t)为当前时刻t的性能指标函数。
步骤3:计算目标网络误差和评价网络的误差,通过计算出的误差分别对目标网络和评价网络的权值进行在线调整;
目标网络误差定义为:ef(t)=αS(t)-[S(t-1)-r(t-1)]
权值调整规则为:
隐层到输出层:其中,
输入层到隐层:其中,
评价网络权值误差定义为:ec(t)=γJ(t)-[J(t-1)-S(t)]
权值调整规则为:
隐层到输出层:其中,
输入层到隐层:其中,
其中,α为目标网络折扣因子,其取值范围为0<α<1,S(t)为f时刻的内部强化学习信号,S(t-1)为上一时刻的内部强化学习信号,r(t-1)为上一时刻的外部强化学习信号,ef(t)为当前时刻t的目标网络误差。
其中,γ为评价网络折扣因子,其取值范围为0<γ<1,J(t)为当前时刻t的性能指标,J(t-1)为上一时刻性能指标,S(t)为当前时刻t的内部强化学习信号,ec(t)为当前时刻t的评价网络误差。
其中,aj(t)为当前时刻t的目标网络输入向量中的第j个元素,lf(t)是当前时刻t的目标网络学习率,ef(t)为当前时刻t的目标网络误差,Ef(t)是当前时刻t的目标网络误差的平方,为当前时刻t的目标网络隐层到输出层权值矩阵第i个元素的增量,为当前时刻t的目标网络输入层到隐层权值矩阵第i行,第j列元素的增量,为目标网络的激活函数,qi(t)为当前时刻t的目标网络隐层输出向量的第i个元素,为当前时刻t的目标网络输入层到隐层的权值矩阵第i行,第j列元素,为当前时刻t的目标网络隐层到输出层权值矩阵第i个元素。
其中,ck(t)为当前时刻t的评价网络输入向量中的第k个元素,lc(t)为当前时刻t的评价网络学习率,ec(t)为当前时刻t的评价网络误差,Ec(t)为当前时刻t的评价网络误差的平方,为当前时刻t的评价网络隐层到输出层权值矩阵第l个元素的增量,为当前时刻t的评价网络输入层到隐层权值矩阵第l行,第k列元素的增量,为目标网络的激活函数,qi(t)为当前时刻t的目标网络隐层输出向量的第i个元素,为评价网络的激活函数,zl(t)为当前时刻t的目标网络隐层输出向量的第l个元素,为当前时刻t的目标网络输入层到隐层的权值矩阵第i行,第j列元素,为当前时刻t的目标网络隐层到输出层权值矩阵第i个元素。
步骤4:通过求解最优性能指标函数,得到单神经元PI算法K值,通过得到的K值调节单神经元PI控制算法的输出,即永磁同步电机系统q轴电流的参考值iq*;
K值调整误差为:ea(t)=J(t)
其中,
K(t+1)=K(t)+ΔK(t)
单神经元PI控制算法的输出为如图5,其中,
其中,w1(t)为当前时刻比例权值,w2(t)为当前时刻积分权值,w1(t-1)为上一时刻比例权值,w2(t-1)为上一时刻积分权值。为当前时刻q轴电流参考量,为当前时刻q轴电流增量,上一时刻为q轴电流参考量,x2(t)=e(t)=ω*(t)-ω(t)为转速差,其中,ω*(t)为电机目标转速,ω(t)为电机实际转速。x1(t)为当前转速差和上一时刻转速差的差值。ηP为比例权值调整学习率,ηI为积分权值调整学习率。
其中,la(t)为当前时刻t的单神经元PI折扣因子学习率,ea(t)为当前时刻t的单神经元PI折扣因子学习反传误差,Ea(t)为当前时刻t的单神经元PI折扣因子学习反传误差的平方,ΔK(t)为当前时刻t的K值增量,Δu(t)为当前时刻t的控制信号的增量,u(t)为当前时刻t的控制信号,为当前时刻t的目标网络输入层到隐层权值矩阵第i行,第3列元素,为当前时刻t的评价网络输入层到隐层权值矩阵第l行,第4列元素,为当前时刻t的评价网络输入层到隐层权值矩阵第l行,第1列元素,为目标网络的激活函数,qi(t)为当前时刻t的目标网络隐层输出向量的第i个元素,为评价网络的激活函数,zl(t)为当前时刻t的目标网络隐层输出向量的第l个元素,J(t)为当前时刻t的性能指标,为当前时刻t的目标网络隐层到输出层权值矩阵第i个元素,为当前时刻t的评价网络隐层到输出层的权值矩阵第l个元素,S(t)为当前时刻t的内部强化学习信号,K(t-1)为上一时刻单神经元PI算法K值,K(t)为当前时刻t的K值。
步骤5:矢量控制系统中的d轴电流内环采用改变趋近率的滑模变结构控制器,通过d轴给定参考值id*和实际电流id的差,来调节d轴电压ud;
矢量控制系统中的q轴电流内环采用改变趋近率的滑模变结构控制器,通过q轴给定参考值iq*和实际电流iq的差,来调节q轴电压uq。
基于新型趋近律的滑模变结构控制器,其新型趋近率主要为下式所示:
其中,s为滑模面,为s的导数,sgn(·)为符号函数,k,δ,ε为调整参数,调节规律为:当控制系统离趋紧面较远时,s很大,e-δ|s|很小,分母近似等于ε,趋近律公式近似等价于此时调节k远大于ε,就能使得运动点快速的趋近于切换面。δ一般取δ>0,k取值远大于ε,k>0,ε>0。
根据实际控制对象,现场调整这三个参数,k>0,δ>0,0<ε<1。x1为状态变量。
令可得到
其中,为q轴电流参考值和实际电流的差,为电流差对时间的导数。A、B、D这三个变量为电机参数,c为滑模变结构控制调整参数。
d轴电流控制器输出为:
q轴电流控制器输出为:
上述实施例仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和等同替换,这些对本发明权利要求进行改进和等同替换后的技术方案,均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!