一种三相负荷不平衡边缘侧治理方法和系统与流程
本发明涉及低压配电领域,具体涉及一种三相负荷不平衡边缘侧治理方法和系统。
背景技术:
低压配电台区作为电力系统的终端部分,直接面向电力用户,而家庭用户接入的大部分是单相电,由于负载不均衡以及用电时刻不同,造成了配电台区中的三相负荷不平衡现象较为严重。配电台区的三相负荷不平衡对配电网供电安全、供电质量和经济运行均会产生不良影响,是配电网运行薄弱环节的主要体现之一。
目前,针对低压配电台区三相负荷不平衡治理方法主要有两种不同的解决方案。一是采用增强型设备,依托传统电力电子型svg或svg无功补偿技术,结合成熟的控制算法,使其同时具备无功补偿和抑制三相不平衡的功能。但是,此类设备通常安装在配电变压器的低压侧,已达到集中补偿的目的。虽然能够有效地调节变压器出口电能质量,改善变压器运行工况,但沿线路不确定分布的三相不平衡现象依然没有得到有效调节,低电压状况依旧存在。二是采用智能换向开关。智能换向开关是一种自动调节供电电源相位的开关设备,其源端为三相输入,出线端为单相,运行工况为无论何时仅有一相位工作相,另外两相为分断状态,可根据控制指令实现电位的切换。此方案从根本上解决了三相负荷不平衡的问题,相比svg无功补偿的方案,能够有效快速调节低压配电台区中三相负荷状态。
虽然智能换相开关技术实现了用电相位的在线切换,但在实际应用过程中,面对配电网中大量的智能换向开关动作协调调整仍较为困难。一方面调整的时间不宜过长,防止出现三相负荷不平衡状态对配电网的安全造成影响,这就要求协调算法的复杂度不能太高;另一方面,要尽量降低调节换向开关的数量,以最小的调整数量尽快达到三相负荷平衡状态,既保证了调整的可靠性,又增加了换向开关的使用寿命。
实际电网运行中存在大量台区,若将每个台区的运行状态集中传送到云端,由云端依次处理,这必将影响台区三相不平衡治理的响应时间,且安全性也存在隐患。现有的换向开关协调调整算法多采用迭代算法进行调整,算法的复杂度和计算时间较高,很难满足实际低压配电台区规模较大的换向开关的调整。
因此,如何降低基于智能换向开关的三相负荷不平衡算法复杂度,实现调整时间短,调整数量少,快速稳定解决低压配电台区的三相不平衡是主要研究的问题。
技术实现要素:
鉴于上述,本发明实施例提供了一种三相负荷不平衡边缘侧治理方法和系统,快速准确地实现对三相负荷不平衡的实时治理。
本发明实施例提供的一种三相负荷不平衡边缘侧治理方法,包括以下步骤:
获得低压配电台区中变压器输出的三相电流数据;
在依据三相电流数据计算的三相负荷不平衡度不符合预设标准时,采用基于强化学习构建的强化学习模型依据三相电流数据计算得到智能换向开关调整策略并发送至智能换向开关;
智能换向开关依据接收的调整策略调整智能换向开关状态,实现对三相负荷不平衡的实时治理。
其中一个实施例,基于强化学习构建的强化学习模型时,以智能换向开关电流大小及相位作为强化学习的环境状态,,以智能换向开关调整策略作为强化学习产生的动作,以根据强化学习输出的智能换向开关调整策略完成智能换向开关调整后,重新计算的新三相负荷不平衡度和统计智能换向开关调整策略下调整的智能换向开关数量,并将新三相负荷不平衡度和调整的智能换向开关数量作为强化学习的奖励标准。
其中一个实施例,所述智能换向开关调整策略包括智能换相开关要切换的相电流,优选地,每个智能换向开关采用强化学习输出的2个动作值组成的动作对表示,当动作对为(0,0)时,智能换向开关保持当前相序,当动作对为(1,0)时,表示智能换向开关切换到a相序,当动作对为(0,1)时,表示智能换向开关切换到b相序,当动作对为(1,1)时,表示智能换向开关切换到c相序。
其中一个实施例,所述将新三相负荷不平衡度和调整的智能换向开关数量作为强化学习的奖励标准包括:
依据新三相负荷不平衡度和调整的智能换向开关数量定义强化学习的奖励r为:
其中,β表示调整智能换向开关数量tn所占的权重,σ为用来调整奖惩的大小的参数,m为预设不平衡度标准,ρi表示新三相负荷不平衡度。
其中一个实施例,采用包含决策网络和目标网络的dqn算法构建强化学习模型时,其中,决策网络和目标网络的均采用全连接网络,激活函数选择relu函数,且在最后一层为保证输出的动作只能取值为0或1,最后一层的激活函数选择sigmoid函数,当神经元输出的值小于0.5时,取值为0,大于等于0.5时,取值为1。
其中一个实施例,强化学习(deepqnetwork,dqn)算法中,采用环境状态与动作对的值函数作为动作选择指标,更新过程为:
q(s,a)=r+γmaxqtarget(s',a)π(s,a)
其中,s表示当环境状态,s'表示在动作a下s状态转移后的环境状态;q(s,a)和qtarget(s',a)表示决策网络和目标网络中的环境状态与动作对的值函数;r为决策网络当前环境状态下选择动作a获得的奖励值;γ为表示未来奖赏的重要程度的折扣引子。
其中一个实施例,在获得智能换向开关调整策略之后,还需要对智能换向开关调整策略进行三相负荷不平衡度的计算校验,当计算校验结果满足不平衡度标准范围时,则发送智能换向开关调整策略至智能换向开关。
其中一个实施例,当计算校验结果不满足不平衡度标准范围时,进行情况上报,由专家人员对智能换向开关进行远程操作调整,并将此次调整作为专家经验数据用于对强化学习模型的训练。
其中一个实施例,智能换向开关依据接收的调整策略调整智能换向开关状态后,依据调整后的新智能换向开关状态进行三相负荷不平衡度的计算校验,完成对三相负荷不平衡的实时治理。
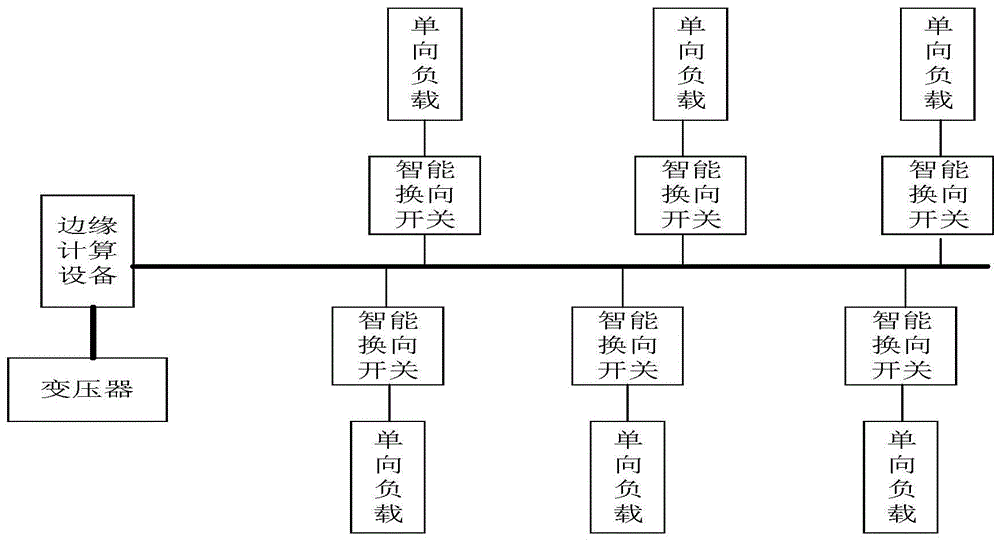
本发明实施例提供了一种三相负荷不平衡边缘侧治理系统,包括低压配电台区的变压器、设置在变压器边缘的边缘计算设备、多个向负载输送电能的智能换向开关,边缘计算设备分别与变压器、智能换向开关通信连接;
所述边缘计算设备获取变压器输出的三相电流数据;
所述边缘计算设备在依据三相电流数据计算的三相负荷不平衡度不符合预设标准时,采用基于强化学习构建的强化学习模型依据三相电流数据计算得到智能换向开关调整策略后,发送智能换向开关调整策略至智能换向开关;
所述智能换向开关依据接收的调整策略调整智能换向开关状态,实现对三相负荷不平衡的实时治理。
实施例提供的三相负荷不平衡边缘侧治理方法和系统,通过在低压配电台区边缘侧部署训练好的强化学习模型,避免了采用迭代算法较高的复杂度和时间计算成本,同时,考虑实际环境,采用边缘计算架构,利用边缘计算设备、物联网通讯手段以及智能换向开关在低压配电台区本地实现低压三相负荷不平衡治理,实时响应速度快,安全性高,减轻了云端网络的压力。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根据这些附图获得其他附图。
图1是一实施例中三相负荷不平衡边缘侧治理系统的结构示意图;
图2是一实施例中三相负荷不平衡边缘侧治理方法的流程图;
图3是一实施例中强化学习模型的训练流程图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
面对实际低压配电台区三相负荷不平衡治理要求算法复杂度低,实时响应高,调整换向开关数量少等特点,实施例提供了一种三相负荷不平衡边缘侧治理方法和系统,结合边缘计算,物联网,强化学习等技术,在台区边缘侧利用边缘计算设备部署的基于强化学习构建的强化学习模型动态实时监测低压配电台区的三相负荷情况,当出现三相负荷不平衡时,强化学习模型可借助物联网通讯手段,及时向智能换相开关下发调整指令,在低压台区边缘侧完成三相负荷不平衡的治理。
图1是一实施例中三相负荷不平衡边缘侧治理系统的结构示意图。如图1所示,实施例提供在低压配电台区场景中的三相负荷不平衡边缘侧治理系统,包括变压器、边缘计算设备、智能换向开关和单向负载。其中,边缘计算设备是部署在台区本地的具有计算机功能的设备,能够运行算法模型,读取计算存储数据,与云端网络进行通信及控制边缘侧设备等功能。其通过rs485/wifi/lora/4g/5g等物联网通讯手段连接台区变压器、各支路的智能换向开关,能够实时获取变压器出口侧a,b,c相的电流数值以及各支路的智能换相开关a,b,c三相电路的导通状态及电流大小,每个智能换向开关与每个单向负载相连,通过控制向单向负载输电。
边缘计算设备每间隔一定时间读取台区变压器出口侧a,b,c相的电流数值,并基于a,b,c相的电流数值进行三相负荷不平衡边缘侧治理。图2是一实施例中三相负荷不平衡边缘侧治理方法的流程图。如图2所示,三相负荷不平衡边缘侧治理方法包括以下步骤:
步骤1,边缘计算设备读取变压器输出的三相电流数据。
步骤2,边缘计算设备计算此时的三相负荷不平衡度是否符合预设标准。如果符合预设标准,则不做处理。
实施例中,采用以下公式根据读取的三相电流数据计算三相负荷不平衡度ρ:
其中,ia,ib,ic为a,b,c相电流的大小,iav表示三相电流的平均值,表示为:
三相负荷不平衡度ρ为各相电流不平衡度最大值。
实施例中,预设标准是指根据国家电能质量标准gb/t15543-2008《电能质量三相电压允许不平衡度》低压台区三相负荷不平衡度,一般不超过10%。
步骤3,当三相负荷不平衡度不符合预设标准时,调用基于强化学习构建的强化学习模型依据三相电流数据计算得到智能换向开关调整策略。
当边缘计算设备计算得到的三相负荷不平衡度不符合预设标准时,则认为低压台区处于三相不平衡,此时将调用本地部署的强化学习模型来获取智能换向开关调整策略。边缘计算设备将观测到的三相电流数据传入强化学习模型中,强化学习模型根据训练好的策略生成对应的智能换向开关调整动作。调整动作生成后,边缘计算设备首先在本地模拟调整动作之后三相负荷状态,三相负荷要求后,则向各智能换向开关下发动作调整指令;如果三相负荷不符合要求,则进行远程上报,让模型重新对本次状态进行学习,并更新动作选择策略。
图3是一实施例中强化学习模型的训练流程图。如图3所示,强化学习模型的构建过程为:
s1、搭建深度强化学习模型框架,确定强化学习模型中的环境状态、智能体动作以及环境对动作的奖赏标准;
s2、采用dqn(deepqnetwork)算法对强化学习模型的框架进行细化;
s3、利用实际台区运行三相数据对dqn算法中的超参数进行训练;
s4、将训练收敛的dqn算法模型部署到边缘计算网关中,当台区出现三相负荷不平衡时,通过dqn算法模型获得最优调整策略。
优选地,s1中,搭建深度强化学习模型框架,确定强化学习模型中的环境状态、智能体动作以及环境对动作的奖赏标准的过程为:
s11、将低压配电台区中各智能换向开关a,b,c三相电流的大小作为强化学习中环境状态s,表示为:
s={ia1,ib1,ic1,ia2,ib2,ic2...ian,ibn,icn},
其中ian,ibn,icn代表第n个智能换向开关a,b,c三相的电流大小。
s12、将低压配电台区中各智能换相开关要切换的相电流作为强化学习中的动作a,表示为:
a={a10,a11,a20,a21,...an0,an1}
其中an0,an1=(0,0)组成的动作对代表第n个智能换向开关的动作,且an0,an1只能取值为0或1。
s13、根据强化学习模型输出的动作,完成换向开关的调整后,重新计算台区的三相不平衡度,并统计此次动作下调整换向开关的数量tn。根据实际治理的要求,将治理后的三相负荷不平衡度以及调整智能换向开关的个数作为强化学习模型中的奖惩标准。
具体地,三相负荷不平衡度作为治理的主要目标决定着给予奖励或者惩罚,智能换向开关的调整个数作为质量参考决定着奖励或惩罚的大小。当治理后的三相负荷不平衡度符合规定要求时,此时给予强化学习中的智能体奖励且调整的智能换向开关的数目越少,奖励越大;同样,当治理后的三相不平衡度未达到规定要求时,此时给予强化学习中的智能体惩罚且调整的智能换向开关数目越少,惩罚越大。因此,对于强化学习中的奖惩r可以定义为:
其中,β表示调整换向开关数量所占的权重,σ为常数,用来调整奖惩的大小,m为预设不平衡度标准范围,根据国家电能质量标准gb/t15543-2008《电能质量三相电压允许不平衡度》m一般设定为10。
优选地,s2中,利用实际台区运行三相数据对dqn算法中的超参数进行训练包括:
s21、在采用包含决策网络和目标网络的dqn算法对强化学习模型的框架进行细化时,决策网络和目标网络的神经网络层采用全连接的方式,激活函数选择relu函数,且在最后一层为保证输出的动作a只能取值为0或1,最后一层的激活函数选择sigmoid函数,当神经元输出的值小于0.5时,取值为0,大于等于0.5时,取值为1。
优选地,对于动作a={a10,a11,a20,a21,...an0,an1}对其进行如下定义:当(an0,an1)=(0,0)时,代表第n个智能换向开关保持当前相序;当(an0,an1)=(0,1)时,代表第n个智能换向开关切换到a相序;当(an0,an1)=(1,0)时,代表第n个智能换向开关切换到b相序;当(an0,an1)=(1,1)时,代表第n个智能换向开关切换到c相序;其他保持同理。
s22、更新动作选择策略:即采用dqn算法中的状态与动作对的值函数q(s,a)来作为动作选择指标,更新过程为:
q(s,a)=r+γmaxqtarget(s',a)π(s,a)
其中,s表示当环境状态,s'表示在动作a下s状态转移后的环境状态;q(s,a)和qtarget(s',a)表示决策网络和目标网络中的环境状态与动作对的值函数;r为决策网络当前环境状态下选择动作a获得的奖励值;γ为表示未来奖赏的重要程度的折扣引子,取值为(0,1)。
优选地,s3中,利用实际台区运行三相数据对dqn算法中的超参数进行训练包括以下过程:
s31、对强化学习模型进行初始化,搭建好决策网络和目标网络两个神经网络,并进行参数初始化,确定学习速率α,最大迭代训练次数k,折扣引子γ;
s32、根据动作选择策略π(s,a),对不同的台区状态s选择动作a进行探索尝试并获得奖励,并将每次探索的状态、动作、奖励当作经验存入经验池中,同时加入部分专家经验。
s33、智能体在训练过程中,会随机抽取记忆池中的经验来进行学习并跟新动作选择策略。
s34、在强化学习模型训练过程中,智能体需要经过大量的探索学习才能获得较好的动作选择策略,为加快智能体的学习过程,保证学习质量,采用半监督的训练方式,人为的在记忆池中加入部分比例的专家经验(部分状态下对应的最佳动作)来加快智能体的学习。通过这种半监督的训练方式,可以加快强化学习模型的收敛速度。训练好的强化学习将部署到台区中的边缘计算网关,当网关通过计算检测到三相不平衡时,则会将此时台区的状态传入强化学习模型中,模型自动计算出的智能换向开关调整策略。
步骤4,边缘计算设备将先对智能换向开关调整策略进行计算校验,计算调整后的三相负荷不平衡度是否符合要求,满足要求后,在将调整策略通过物联网通讯手段下发至各智能换向开关。
步骤5,调整后的三相负荷不平衡度不符合要求时,则进行情况上报,由相关人员进行远程操作调整,并将此次智能换向开关调整作为专家经验,加入到模型训练的经验池中,重新对模型进行训练,训练完成后,对模型进行重新线上部署。
调整策略下发完成后,智能换向开关根据策略规定进行调整后,需再次将自身状态上传至边缘计算设备,边缘计算设备对调整后的智能换向开关状态进行核验,并重新计算台区的三相不平衡度,完成对台区三相负荷不平衡边缘侧的治理。
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!