用于在进行预校正的前提下重构比特串的装置和方法与流程
本发明属于密码学的领域,并且本发明的观点涉及一种用于重构特别是用于在电子芯片卡或射频识别设备(RFID)中使用的物理不可克隆函数(PUF)的装置和方法。
背景技术:
缩写PUF代表不可克隆函数,也称作物理散列函数。基本理念是将对象的物理特性数字化并且由此获得被分配给该对象的比特串。其中,值得期待的是,两个不同的物理对象的比特串彼此之间没有关联。为了进行说明,以一张纸作为简单的例子。如果在显微镜下进行观察,能够看到木屑或纤维素部分的一种特别的精密结构。对该结构进行测量并借助于合适的算法将其作为比特串示出。该比特串便是被分配给这张纸的PUF。一般而言,另外一张纸将会得出完全不同的比特串,即与第一张纸的比特串没有关联的比特串。“比特串”和“位串”这两个概念在后面同义地使用。从物理对象的特性中产生(PUF的)比特串的过程称为PUF生成。PUF的主要应用是生成用于完全电子化以及计算机化的加密方法的密钥。例如能够将PUF位串本身作为密钥使用。或者具有一定优势的是能够将PUF位串压缩为较短的位串并且将后者作为密钥使用。后一种方法通常应用在芯片卡中,其中,用于PUF生成的机制集成在卡的电子装置中。以这种方式并通过PUF生成和其用于密钥生成的应用而避免了必须将密钥本身存储在卡上,因为这可能带来安全风险。PUF机制的一种值得期待的特性是,同一物理对象、即例如同一芯片卡在新的PUF生成的过程中每次都得出同一比特串。特别是在不同的环境条件下,例如在不同的温度、空气湿度、亮度、电和磁场强度等条件下,也应如此。然而情况通常并非是这样。一般而言,对于同一物理对象的重复的PUF生成提供不同的比特串。虽然比特串彼此之间完全相似,但并不一定彼此相同。人们尝试用编码理论的方法(纠错)来平衡这种缺陷。其中,采取如下措施。已知一个物理对象。在开始时产生被分配给该对象的PUF比特串A。该比特串A即为第一次PUF生成的结果。比特串A被视为编码理论中的消息,消息应通过容易受到干扰的信道进行传输,其中可能发生的情况是,在传输过程中出现错误,即单个的比特记录突然发生改变,也就是说,零变成一或者反之。在编码理论中这样应对这种问题,即消息A备有冗余信息R并且传输码字(A,R)。如果在传输时出现错误,那么,由于该冗余信息R的存在便能够通过编码理论的方法校正这些错误。无误的消息字A在校正后重新出现。在PUF生成中利用的是同一理念。初始的PUF值A(在第一次PUF生成中产生的值)被称为真的PUF值。从真的PUF值A中计算出附属的冗余值R。R被称作辅助信息,并且借助于R应在后来的某一时间点上实现真的PUF值A的重构。为了简单起见,在这里假定,真的PUF值A是进行首次PUF生成时产生的那个位串。实际上,例如芯片卡的真的PUF值在制造时是在芯片-个人化的过程中确定的。其中常见的是,多次或者说频繁地相继产生PUF值,并且将例如中间值或最频繁产生的值定义为真的PUF值。另一种处理方式是将储备纳入计划内。假定需要长度为800比特的PUF值。然而产生的却是(例如)长度为1000比特的PUF值,以便拥有储备。随后在工厂中多次地、例如100次地产生1000比特的PUF值。每一个在这100 次产生1000比特的PUF值的期间不稳定的、即没有始终示出相同的比特值的比特-位置被宣布为无效。假定在100次PUF生成的期间每次出现相同比特值的位置有840个。则从这840个位置选择例如800个位置,并且由这800个位置定义真的PUF值。借助于编码算法而计算出的值R被存储。处于安全原因,PUF值A本身未被存储并且因此也并非始终都可供使用。原因在于,该PUF值A直接作为密钥使用,或者从其中推导出密钥。如果能够轻易地获取PUF值A,则不能再将相应的密钥视为机密。在后来的再次的PUF生成中获得新的PUF值B。虽然值B一般不同于A,但是仅细微地区别于A。目的是从可供使用的值B中重新获取真的PUF值B。这借助于R和编码理论的方法实现:B->(B,R)->(A,R)->A即:当前存在的PUF值B被扩展了辅助信息R的长度,其中,A,B和R是比特串。比特串(B,R)随后被视为编码理论的范畴内的有误的字并且随后借助于编码理论校正该错误。从而获得消除了错误的字(A,R)。此时特别地得到了真的PUF值A。只有当最后产生的并且当前存在的PUF值B与真的PUF值A的区别不是太大时,才能实现从B中重构A的目的。用编码理论的术语表述为:从相对于初始的真的PUF值A的角度来看,当在生成B的过程中没有发生过多的错误时,才能实现该目的。新生成的PUF值B典型地区别于真的PUF值A的程度、即典型地有待校正的错误的多少取决于PUF的技术实现。视PUF的技术实现而定,B可能在小于1%、例如在0.3%或者0.6%的位置上,或者在最高达25%的位置上区别于A。B平均地区别于A的程度越高,PUF重构算法的硬件 -实现的规模便越大并且费用便越高。这也意味着更高的制造成本、更大的空间需求,也可能意味着更高的能量消耗。对此存在多个原因。当应从PUF值中形成例如长度为128比特的密钥时,产生以下参数:错误率越高(即B区别于A的程度越高),位串A和B便必须越长,以便最终得出安全的128比特密钥。如果在B中出现了15%的相对于A的错误,那么A(并且B也由此同样)必须达到大约4000比特的长度,以便取得128比特的密钥(当错误率为25%时需要大约6000比特的长度)。当仅出现1%的错误时,A和B须为大约600比特的长度,以便同样地提供长度为128比特的密钥。上面说明的值和情况的计算借助于编码理论实施并且对于专业技术人员而言是已知的,因此不在这里赘述。当错误率更低并且待生成的密钥更短时,例如A和B各自为64比特的长度便已足够。出现的错误越多,所应用的错误校正-算法便必须越强,并且算法的实施的投入便越大并且因此越昂贵。在电子的芯片卡的领域内通常应用这些方法,即通过测量在硅中实施的电子电路、例如晶体管而产生PUF。集成电路在制造过程中存在差异,即便是生产者也不能完全控制这些差异,这些差异导致产生这样的情况,即两个不同的集成电路所产生的PUF串彼此没有关联。这被用于使得不同的集成电路自动地生成不同的PUF,而这从安全技术的角度来说是一个基本前提。对于该种电路而言,可以典型地估计其错误率为1%到10%之间。即:新生成的PUF串B将可能在大约p%的比特-位置上区别于真的PUF值A,其中,p为1到10之间的数字。根据通过试验确定的值p随后实施合适的PUF串-长度和必要的纠错算法。在一个例子中,应当从PUF串A中提取出长度为128比特的密钥。如果p等于1,那么PUF串A必须为此具有大约600比特的长度。如果p等于10,则PUF串A的长度必须约为3000比特。此外适用的是,与p等于10的情况相比,p等于1时所需要的、或者说能够满足p等于1时的情况的纠错算法更简单。如已经在前面说明的,该问题目前仅通过编码理论的方法解决:选择合适的代数编码,该代数编码几乎一贯是一种直线编码。从最初测量的PUF位-串A中通过所选择的编码计算出附属的冗余值R。随后将该冗余值R——代表PUF串A——存储在芯片卡的非易失性存储器(NVM-nichtflüchtigerSpeicher)中。出于安全性的原因没有存储A本身。在再次的后来的PUF生成中获得位-串B。随后借助于冗余值R和来自于纠错编码的理论(代数编码理论)的算法从B中计算出值A。换言之:即将B理解成是A的错误版本,并且借助于R和纠错算法校正错误。其中须注意,冗余值R必须短于A。由于R被存储在了NVM中,所以认为R是或多或少公开已知的。从A中提取出密钥。如果|A|是A的比特长度,并且|R|是R的比特长度。那么差|A|-|R|便是密钥的长度。并且从A中仅能够获得唯一的该长度的密钥。在一个例子中,PUF值A具有500比特的长度。冗余值R具有400比特。则能够从A中推导出长度为100比特的密钥。能做到这一点的一个相近的可能性在于,每次把A的5比特加上模数2——即进行XOR运算——以便获得密钥比特。
技术实现要素:
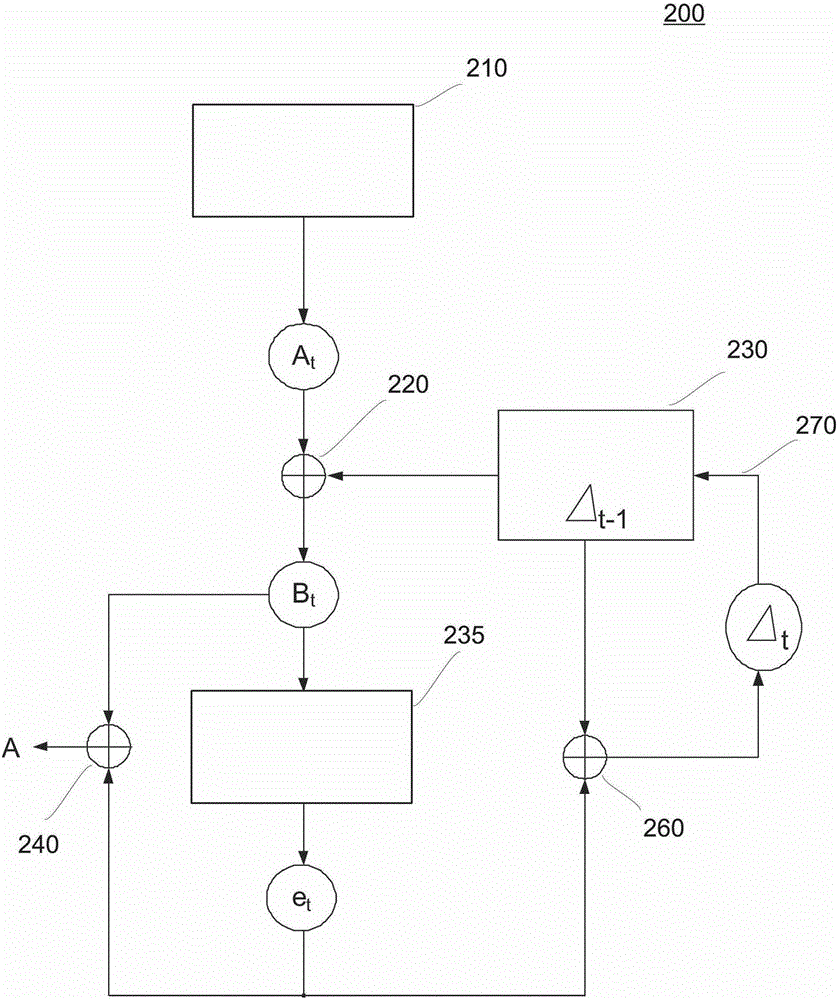
在这一背景之下存在对于能够改进PUF生成、例如使其更快速或者降低计算投入的方法和装置的需求。根据第一个实施例提出了一种用于重构在电子设备中使用的PUFA的方法。该方法包括生成可能带有错误的PUFAt;借助于存储的校正矢量Deltat-1对PUFAt进行预校正,以便获得经过预校正的PUFBt;和从经过预校正的PUFBt中借助于纠错算法、优选地借助于ECC算法(代数编码理论)重构PUFA。根据另一个实施例提出了一种装置。该装置包括用于产生可能带有错误的PUFAt的元件;用于存储校正矢量Deltat-1的存储器;和用于实施纠错算法的计算单元。附图说明此外,应通过在附图中示出的实施例说明本发明,从这些实施例中得出其它的优点和变体。图1示意性地示出了用于重构根据本发明的实施方式的PUF的方法;图2示出了根据本发明的实施方式的装置的示意图;图3示意性地示出了根据实施方式的装置。后面对本发明的不同的实施方式进行说明,这些实施方式中的某些实施方式也在附图中示例性地示出。在对于附图的以下说明中,相同的参考标号涉及相同的或相似的组件。一般仅对不同的实施方式之间的不同之处进行说明。在此也能够将被作为某一实施方式的部分而说明的特征任意地与其它的实施方式相关联地进行组合,以便产生其它的实施方式。具体实施方式正如已经提到的,从当前的位串B中重构真的PUF位串A是借助于冗余信息R并通过纠错算法实现的。在PUF生成以及PUF重构的问题这 一方面和通过易受干扰的通道传输消息以及校正所接收的消息的问题这一方面之间存在密切的关联。在进行PUF重构时最初生成了(真的)PUF位串A。在后来的某一时间点上,在新的PUF重构的过程中获得位串B。(随后)应从当前的B中重构不公开的A。在消息传输的过程中存在消息A,一贯也能够将该消息作为位串示出。A通过易受干扰的通道发送。可能出现一些传输错误。消息B被接收。随后通过纠错算法校正在B中出现的错误。作为结果而获得初始的消息A。在消息传输中通常假定通道为所谓的“二级制对称信道(BinarySymmetricChannel)”。这意味着,假定A中的单个的信息比特彼此独立地以相同的概率“突然发生改变(umkippen)”,即变成错误的比特。也就是说,对于具有参数p的二进制对称信道而言适用的是:单个的、受到观测的、然而却是任意的消息比特在传输时以概率p转化为它的补充比特(从0变成1,以及从1变成0)。消息比特以概率1-p无错误地传输。如果此时观察PUF情况,那么将会发现偏离于以上的对于消息传输的观察的情况,即其中并不是A的任一比特均以相同的概率在新的PUF生成的过程中转化为它的补充比特。相反地,观察表明,A中的单个的比特以不同的概率“突然发生改变”,即转化为它的相应的补充比特。结果是组中的非常频繁地突然发生改变的比特因此从一开始——即在集成电路在工厂里的制造过程中——便被确认、宣布为无效/不可使用并且在以后的时间里被忽略。但是在余下的可使用的比特中也发现,它们以不同的概率突然发生改变。甚至似乎存在从不突然发生改变的比特。这些是稳定的比特,这些比特始终具有正确的值。此外还有以下两种现象:第一种是:作为老化过程的结果,单个的可使用的比特(即最初仅极少地突然发生改变的比特)这样改变其行为,即它们越来越频繁地突然发 生改变。在极端情况下,它们在任一时刻持续地发生改变,即它们是稳定的,但提供的却始终是错误的值。第二种是:概率为此发生变化,即比特在受到环境条件的影响下突然发生改变。主要是在硅基的、即借助于基于晶体管的电路产生的PUF中存在对于温度的依赖性。因此存在这样的比特,即其在-20摄氏度时极少突然发生改变,但在+80摄氏度时却非常频繁地突然发生改变。通过这种方式,在某一环境条件下几乎稳定的比特在变化了的环境条件下、特别是当在旧的和新的环境条件之间存在较大的差异时变得非常不稳定。这意味着,(相对于真的PUF位串A的)新的PUF生成将会具有与通过二进制对称信道进行信息传输相同的表现的假定是错误的。相反地应当由此出发,即PUF生成具有一种记忆效应(MemoryEffect)。在进行PUF生成时在时间点t上出现的错误在多数情况下与在进行PUF生成时在时间点t-1上出现的错误相似。因此,(在相同的或至少相似的环境条件下),在几乎彼此相邻的时间点上实施的PUF生成的过程中出现的错误在统计学上并不是——像一般地在上述的、通过信道进行的消息传输时的情况一样——是彼此独立的,相反而是彼此近似的。在这里说明的根据实施例的方法中利用该效应:在较早的时间点t-1上进行PUF重构时计算出的错误被存储,并且用于在后来的、或者说当前的时间点t上进行的PUF重构。其中充分利用这种情况,即PUF生成在一定的程度上取决于环境条件。因此,一般说来,校正相对于从前一个PUF请求中生成的PUF值而出现的PUF错误比校正相对于(在集成电路的或者例如芯片卡的生命周期中)首次生成的PUF值而出现的PUF错误更容易。如果A为真的PUF值,即在工厂里制造集成电路时确定的首个PUF值。此外,如果At是在(后来的)时间点t上产生的PUF值。即:在时间点t上提出PUF请求,并且由此激活PUF模块。作为激活的结果是由模块产生当前的PUF值At。此外,如果Et是错误矢量。矢量Et表示真的(首个)PUF值A和当前产生的PUF值At之间的差别。对于上述内容的举例:A=(1111100011);At=(1011100011)则Et=(0100000000)即适用:A=At+Et注:在传统的(未在这里采用的)用于PUF重构的处理方式中进行如下处理:在PUF激活后获得At。借助于ECC纠错算法从At中计算出错误矢量Et。随后通过A=At+Et得出真的PUF值A。符号、确切地说算符“+”始终指的是按位运算的XOR算法。注意:错误矢量Et在实施例中说明的是A和At之间的差(Delta)。因此Et也称为Deltat。即适用:Deltat=Et不同于上述的传统的处理方式,在根据实施例的Delta校正方法中进行如下处理。在时间点t-1上产生的错误矢量et-1=Deltat-1未被丢弃,而是 在Delta目录中准备就绪,即存储在其中。当此时在时间点t上由PUF模块产生了当前的PUF值At时,不是立即尝试通过ECC纠错算法去校正At。而是计算Bt=At+Deltat-1该步骤由此表示的是一种预校正。在许多情况下,At中的一些比特错误已经通过该预校正得到了校正。因此和Bt表示的是比最初通过激活而产生的比特串更接近所寻求的真的PUF值A的近似值。现在对Bt进行ECC纠错算法。通过该纠错算法计算出Bt相对于A的错误et。一般而言,该错误et小于Et,即et所包含的一少于Et。随后从Bt和et中这样得出真的PUF值A:A=Bt+et最后如下地更新Delta-目录。Delta目录的当前内容是Deltat-1。将该值加上计算出的错误矢量et,即进行按位运算的XOR运算。结果:Deltat=Deltat-1+et被作为新的值写入Delta目录中。对于在其中由PUF模块产生At+1的下一次PUF生成而言,可重复使用该方法。在例子中说明上述内容:如果A=(1111100011)Deltat-1=(1010000001)At=(0100100011)(注意:At有三个错误)计算Bt=At+Deltat-1:Bt=(1110100010)(注意:Bt尚还有两个错误)现在通过ECC算法对Bt进行纠错。ECC产生错误矢量et:et=(0001000001)et和Bt相加得出真的PUF值A:Bt=(1110100010)+et=(0001000001)-------------------------------------A=(1111100011)最后通过将Deltat-1和et相加计算Deltat:Deltat-1=(1010000001)+et=(0001000001)-------------------------------------Deltat=(1011000000)一般而言,Delta预校正将会使随后的纠错算法变得容易一些。但是也可能存在这样的情况,即Delta(预)校正是不起积极作用的:假定时间点t-1和t彼此间隔很远并且在这些时间点上存在完全不同的环境条件,典型地是温度不同。那么差Deltat-1和Deltat极有可能也不再相似,而是显著地彼此相区别。那么At本身则是比矢量Bt更接近真的PUF值A的近似值。在该种情况下最好是抑制以及略去Delta校正的过程并按照传统的方式进行处理。这意味着,正如在上面描述的传统的处理方式一样,在进行PUF重构时将矢量At直接输入ECC纠错中。因此值得推荐的是,不是固定不变地实施Delta校正机制,而是这样来实施,即该机制也有可能(自动地)切断。其中,典型地有意义的是以下的处理方式。首先尝试进行上述的、具有Delta校正的PUF重构。如果失败,即如果ECC纠错随后得出的是在组中被判定为错误的值,那么便再尝试一次不具有Delta校正的、即以传统的方式进行的PUF重构。也可以考虑相反的顺序,即首先执行该方法的传统的变体,并且随后执行具有上述Delta校正的方法。图1示出了用于重构在根据实施例的电子设备中使用的PUFA的方法100。该方法包括在程序块110中产生(可能)带有错误的PUFAt;在程序块120中借助于存储的校正矢量Deltat-1对PUFAt进行预校正,以便获得经过预校正的PUFBt;以及在程序块130中从经过预校正的PUFBt中借助于纠错算法重构PUFA。在此,从PUFBt中借助于纠错算法对PUFA的重构典型地包括将ECC算法应用在比特串Bt上,以便作为结果而获得错误矢量et。随后实 施Bt和et的XOR运算(Verknüpfung)。由此获得新的校正矢量Delta的预备值。借助于存储的校正矢量Deltat-1和错误矢量et的XOR运算计算新的、确切的说是经过更新的校正矢量Deltat。Deltat此时作为新的校正矢量被存储在错误目录230中,如已经说明的,这一新的校正矢量在后来的再次的PUF重构中再次作为错误矢量使用。也就是说,它担任了之前的Deltat-1的角色。作为输入值将经过预校正的PUFBt和冗余值R输入ECC算法中。在上面较靠前的地方已对后者详细地进行了说明,因此在这里不再进行详细地处理。图2示意性地示出了根据实施例的方法200的流程图。在程序块210中产生了可能带有错误的PUFAt。在程序块220中将该PUFAt与存储在存储器230中的校正矢量Deltat-1进行XOR运算。结果即为经过预校正的比特串Bt。现在在步骤235中对该比特串Bt应用纠错算法,典型地是进行ECC算法。从中产生错误矢量et。该错误矢量在步骤240中通过XOR运算与经过预校正的比特串Bt绑定,从中得出真的PUFA。错误矢量et在程序块260中通过XOR运算与之前已经利用过的校正矢量Deltat-1通过XOR绑定,以便获得新的、确切地说是当前的(预)校正矢量Deltat。该校正矢量被作为新的校正矢量Deltat写入存储器230、即程序块270中,以供下一个PUF重构周期使用。其中,At的长度典型地为大约64比特至6000比特。其中,At的平均的比特错误率能够为大约0.3%至大约25%,例如为1%、3%、5%、10%、15%或20%。经过重构的真的PUFA的长度典型地为大约64比特至大约6000比特。根据实施例的、用于PUF重构的方法典型地在芯片卡的电子装置上实现。其中,带有错误的PUFAt的产生典型地通过基于晶体管的方法进行。校正矢量Deltat通常存储在只读存储器、例如电可擦除可编程只读存储器(EEPROM)上。正如已经提到的,在不利的环境条件下、例如在与上一次进行的PUF重构时相比电子装置存在较大的温差的情况下,根据实施例的Delta校正方法也可能对重构起到消极作用,从而使得在不利的情况下完全不能进行任何正确的重构。因此可以在实施例中根据标准来测试是否正确地重构了PUFA。在PUFA未正确重构的情况下,则有可能在不校正PUFAt的前提下借助于存储的校正矢量Deltat-1重新实施重构。为实现这一目的,例如应用在Bt上的ECC算法能够设有不同的强度,从而使得在标准情况(具有Delta预校正的情况)下应用较弱的校正算法。如果在如上所述的特殊情况下该方法失效,则能够放弃校正并应用较强的校正算法。校正矢量Delta的长度在实施例中与PUF值A的长度相同。在实际的应用中,A能够分解为等长的单段;相应地,Delta也能够分解为相同数量的等长的单段。例如,长度为1000比特的PUF能够分解为25个分别长40比特的段,等长的Delta也是如此。在这种情况下能够应用(以较小的码字长度运算的)较小的纠错算法,这是由于始终只校正相关的单段的错误,并且不是同时校正总的比特串的所有错误。通常从通过根据实施例的方法重构的PUFA中产生密钥。该密钥能够随后用于具有块加密或流加密的加密、典型地有高级加密算法(AES)或三重数据加密算法(Triple-DES)。图3示意性地示出了根据实施例的装置300,该装置设计用于实施根据实施例的方法。它例如能够是一种芯片卡或者一种嵌入在终端设备、例如像移动电话或RFID设备的移动终端设备中的密码模块。该装置包括用于产生可能带有错误的PUFAt的元件310,用于存储校正矢量Deltat-1的存储器320,以及用于实施纠错算法的计算单元340。另一个计算单元350用于实施所说明的XOR运算和所有其它的、部分地 在这里没有详细地说明的、对于专业技术人员而言已知的运算。装置300的两个计算单元以及所有的构部能够在实施例中集成地、例如在集成的电路360上实施。该电路也能够包括其它的构部,例如用于重构密钥的逻辑装置和集成电路以及密码模块的、对于专业技术人员而言已知的其它的典型的构件。对于专业技术人员而言完全可以理解的是,在这里说明的方法和装置也能够应用于不同于在这里所说明的目的,并且这些方法和装置能够在完全不同的电子设备中应用,只要在这些设备中是应当重构PUF的。此外对于不同于在这其中具体说明的情况的其它情况,能够通过属于专业技术人员的常识的方法而改变在这其中说明的密钥长度和比特串的长度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1